
- 1NEO dBFT共识机制分析与完善_dbft共识过程
- 2python爬虫 之 完整代码_python爬虫代码
- 3shardingsphere 自定义分片策略_shardingsphere自定义策略
- 4华为OD机试C卷 - 最小矩阵宽度(Java & JS & Python & C & C++)_java.sql.sqlexception: access denied for user 'roo
- 5用python编写用户登录界面,python编写登录窗口_python语言写个登录网页
- 6mybaits中<foreach>的使用
- 7Docker镜像拉取超时解决_群晖docker无法下载镜像
- 8会话跟踪技术——JWT令牌_会话跟踪技术 jwt
- 9Mac 搭建PHP虚拟主机环境_mac php 设置虚拟机
- 10【2020】明哥版-Mac配置PhpStorm/Apache/PHP7.4.10/配置安装使用教程_mac phpstrom配置apache
Kafka的分区分配策略_kafka的key均匀分发到所有partition
赞
踩
用过 Kafka 的同学应该都知道,每个 Topic 一般会有很多个 partitions。为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会启动一个或多个streams去分别消费 Topic 对应分区中的数据。我们又知道,Kafka 存在 Consumer Group 的概念,也就是 group.id 一样的 Consumer,这些 Consumer 属于同一个Consumer Group,组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。那么问题来了,同一个 Consumer Group 里面的 Consumer 是如何知道该消费哪些分区里面的数据呢?
1 分区在集群中的分配策略
- 将所有broker(n个)和partition排序
-
将第i个Partition分配到第(i mode n)个broker上
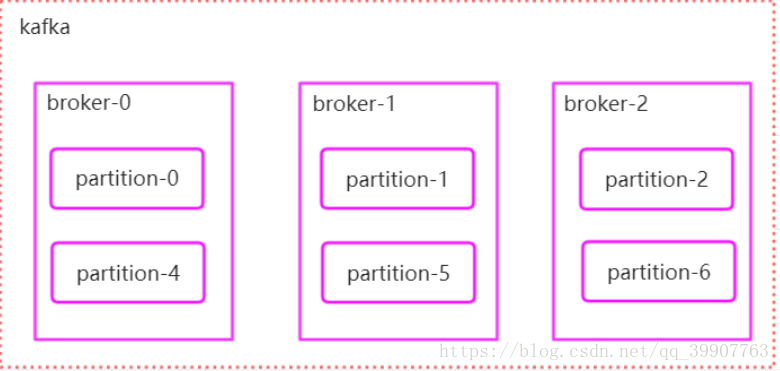
2 Producer如何把消息发送给对应分区
- 当key为空时,消息随机发送到各个分区(各个版本会有不同,有的是采用轮询的方式,有的是随机,有的是一定时间内只发送给固定partition,隔一段时间后随机换一个)
- 用key的ha’sh值对partion个数取模,决定要把消息发送到哪个partition上
3 消费者分区分配策略
3.1Range strategy[默认]
Range策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。在我们的例子里面,排完序的分区将会是0, 1, 2, 3, 4, 5, 6, 7, 8, 9;消费者线程排完序将会是C1-0, C2-0, C2-1。然后将partitions的个数除于消费者线程的总数来决定每个消费者线程消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。在我们的例子里面,我们有10个分区,3个消费者线程, 10 / 3 = 3,而且除不尽,那么消费者线程 C1-0 将会多消费一个分区,所以最后分区分配的结果看起来是这样的:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6 分区
C2-1 将消费 7, 8, 9 分区
假如我们有11个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 0, 1, 2, 3 分区
C2-0 将消费 4, 5, 6, 7 分区
C2-1 将消费 8, 9, 10 分区
假如我们有2个主题(T1和T2),分别有10个分区,那么最后分区分配的结果看起来是这样的:
C1-0 将消费 T1主题的 0, 1, 2, 3 分区以及 T2主题的 0, 1, 2, 3分区
C2-0 将消费 T1主题的 4, 5, 6 分区以及 T2主题的 4, 5, 6分区
C2-1 将消费 T1主题的 7, 8, 9 分区以及 T2主题的 7, 8, 9分区
可以看出,C1-0 消费者线程比其他消费者线程多消费了2个分区,这就是Range strategy的一个很明显的弊端。
3.2 RoundRobin strategy
使用RoundRobin策略有两个前提条件必须满足:
-
同一个Consumer Group里面的所有消费者的num.streams必须相等;
- 每个消费者订阅的主题必须相同。
所以这里假设前面提到的2个消费者的num.streams = 2。RoundRobin策略的工作原理:将所有主题的分区组成 TopicAndPartition 列表,然后对 TopicAndPartition 列表按照 hashCode 进行排序,这里文字可能说不清,看下面的代码应该会明白:(其实就是按分区名hash排序后平均分配给每一个消费者的线程)
|
|
最后按照round-robin风格将分区分别分配给不同的消费者线程。
在我们的例子里面,假如按照 hashCode 排序完的topic-partitions组依次为T1-5, T1-3, T1-0, T1-8, T1-2, T1-1, T1-4, T1-7, T1-6, T1-9,我们的消费者线程排序为C1-0, C1-1, C2-0, C2-1,最后分区分配的结果为:
C1-0 将消费 T1-5, T1-2, T1-6 分区;
C1-1 将消费 T1-3, T1-1, T1-9 分区;
C2-0 将消费 T1-0, T1-4 分区;
C2-1 将消费 T1-8, T1-7 分区;
多个主题的分区分配和单个主题类似,这里就不在介绍了。
根据上面的详细介绍相信大家已经对Kafka的分区分配策略原理很清楚了。不过遗憾的是,目前我们还不能自定义分区分配策略,只能通过partition.assignment.strategy参数选择 range 或 roundrobin。partition.assignment.strategy参数默认的值是range。
3.3 什么时候触发分区分配策略:
1.同一个Consumer Group内新增或减少Consumer
2.Topic分区发生变化
4 Rebalance的执行
kafka提供了一个角色Coordinator来执行。当Consumer Group的第一个Consumer启动的时候,他会向kafka集群中的任意一台broker发送GroupCoordinatorRequest请求,broker会返回一个负载最小的broker设置为coordinator,之后该group的所有成员都会和coordinator进行协调通信
整个Rebalance分为两个过程 jionGroup和sysncJion
joinGroup过程
在这一步中,所有的成员都会向coordinator发送JionGroup请求,请求内容包括group_id,member_id.protocol_metadata等,coordinator会从中选出一个consumer作为leader,并且把组成员信息和订阅消息,leader信息,rebanlance的版本信息发送给consumer
Synchronizing Group State阶段
组成员向coordinator发送SysnGroupRequet请求,但是只有leader会发送分区分配的方案(分区分配的方案其实是在消费者确定的),当coordinator收到leader发送的分区分配方案后,会通过SysnGroupResponse把方案同步到各个consumer中
转自: https://blog.csdn.net/qq_39907763/article/details/82697211

