
- 1Ubuntu 配置共享文件夹_ubuntu共享目录设置
- 2paddle-OCRv2预测部署_ch_pp-ocrv2_det_slim_quant_infer
- 3代码战争关卡代码_代码对战中点关卡怎么过
- 4人工智能与游戏
- 5【粉丝福利社】区块链与金融科技(文末送书-完结)
- 6构建高效外卖系统:利用Spring Boot框架实现_springboot 外卖 小程序框架
- 7python 多分类情感_大神教程干货:使用BERT的多类别情感分析!(附代码)
- 8【InternLM 实战营笔记】LMDeploy量化internlm2-chat-20b模型
- 9【力扣hot100】1. 两数之和 49.字母异位词分组 128. 最长连续序列
- 10大数据Doris(二):Doris原理篇_doris数据库
python 自动化学习(四) pyppeteer 浏览器操作自动化
赞
踩
背景
之前我在工作中涉及到了很多地方都是重复性的页面点点点工作,又因为安全保密原则不开放接口和数据库,只有一个页面来提供点击进行操作,就想着用前面学的自动化来实现,但发现前面学的模拟操作对浏览器来说并没有那么友好,而后改用“selenium”,但是存在一个问题,我这里并不能直接访问外网,好不容易找到selenium的库文件,发现又需要相对应版本的浏览器引擎,导致我无法使用,在此期间我发现了另一个不需要浏览器引擎的库pyppeteer 成功实现了一部分功能,这里做一下笔记
介绍
- 1、selenium //跨浏览器,官方维护的比较好,资料也多,各个版本比较稳定,源码读起来舒服
- //缺点是配置时需要留心程序语言的版本和驱动版本以及浏览器版本,还有就是本身不支持步
- //需要重写源码或者利用grid分布式来实现异步
-
- 2、pyppeteer //是基于chrome官方为chromium定制的自动化测试框架puppeteer而
- //实现的一个python包装的非官方版本框架,最后一次更新是在2018年
- //优点就是速度比selenium快,支持异步,常被拿来做爬虫,
- //缺点就是兼容性很差,而且它没有跟随chromium以及puppeteer的迭代而更新
- //使用时会有很多问题。
安装
pip install pyppeteer==1.0.2入门案例
我们打开浏览器、输入、点击按钮什么的都是是耗时的操作,我们下面通过使用异步关键字
async和await,定义了一个异步函数main。通过在异步函数中使用await关键字,可以将耗时的操作转化为非阻塞的异步调用
- import asyncio # 导入 asyncio 模块,用于编写异步代码
- from pyppeteer import launch # 导入 pyppeteer 的 launch 函数,用于启动浏览器
-
- async def main(): # 定义一个异步函数 main
-
- asyncio.get_event_loop().run_until_complete(main()) # 运行 main 函数
一、定义浏览器并打开页面
- import asyncio
- from pyppeteer import launch
-
- async def main():
- browser = await launch(executablePath="C:\Program Files\Google\Chrome\Application\chrome.exe",headless=False,args=['--start-maximized'])
- page = await browser.newPage()
- await page.setViewport({'width':0,'height':0,'deviiceScaleFactor':1})
- await page.goto('https://www.baidu.com')
-
- await page.waitFor(10000)
- await browser.close()
-
- asyncio.get_event_loop().run_until_complete(main())
参数说明
- async def main():
- browser = await launch(executablePath="C:\Program Files\Google\Chrome\Application\chrome.exe",headless=False,args=['--start-maximized'])
- #launch 定义一个浏览器实例
- #executablePath 本地谷歌浏览器路径
- #headless=False 有界面的浏览器
- #args=['--start-maximized']浏览器窗口最大化
-
-
-
- //在浏览器上创建一个新页面
- page = await browser.newPage()
-
- //width 和height 自动匹配浏览器大小
- //deviiceScaleFactor 将页面的视口设置为浏览器的默认大小,并将设备像素比设置为 1
- await page.setViewport({'width':0,'height':0,'deviiceScaleFactor':1})
-
- //打开浏览器并跳转到指定地址
- await page.goto('https://www.google.com')
-
-
- //上面任务结束后等待10s
- await page.waitFor(10000)
-
- //关闭浏览器
- await browser.close()

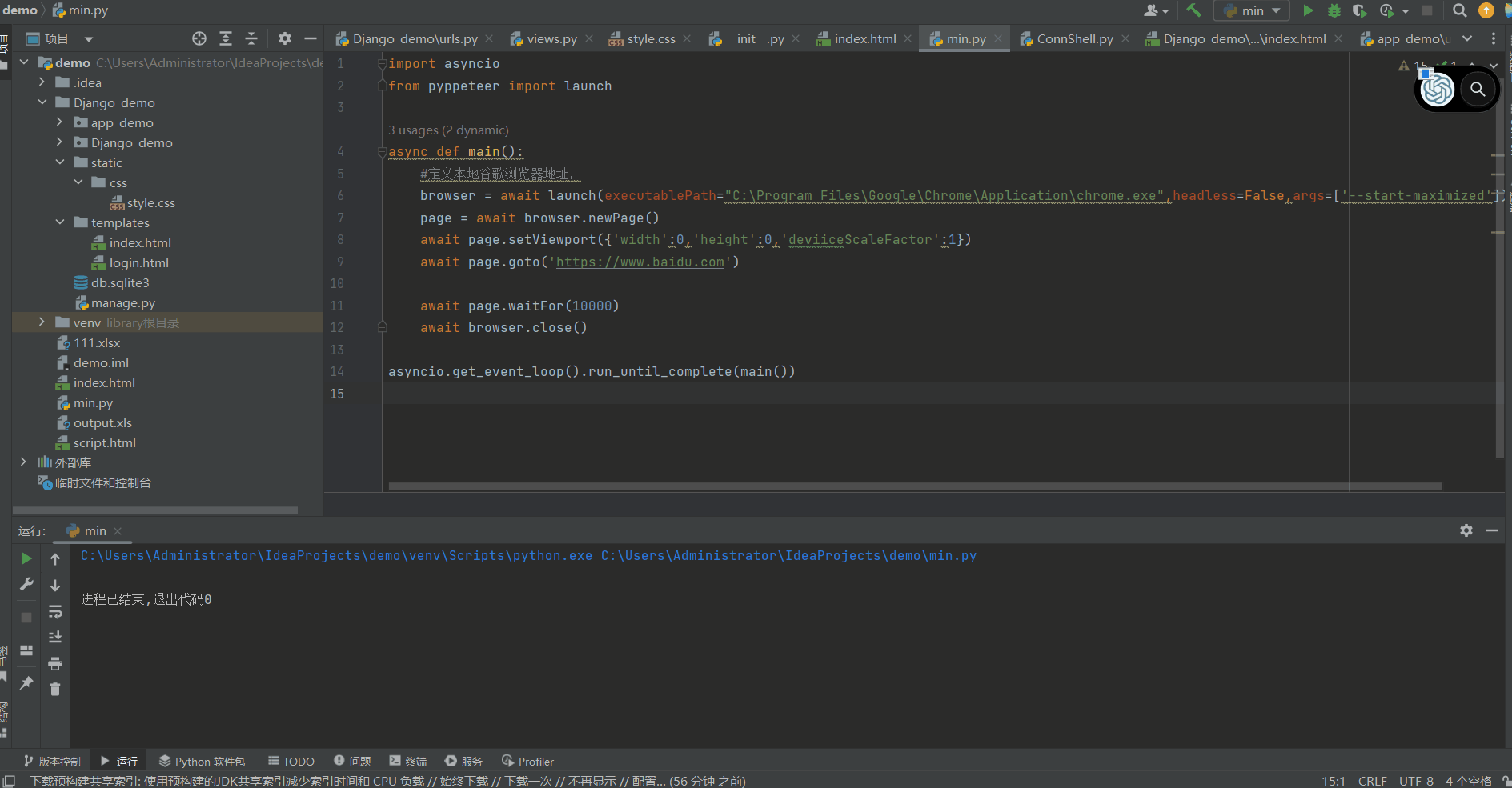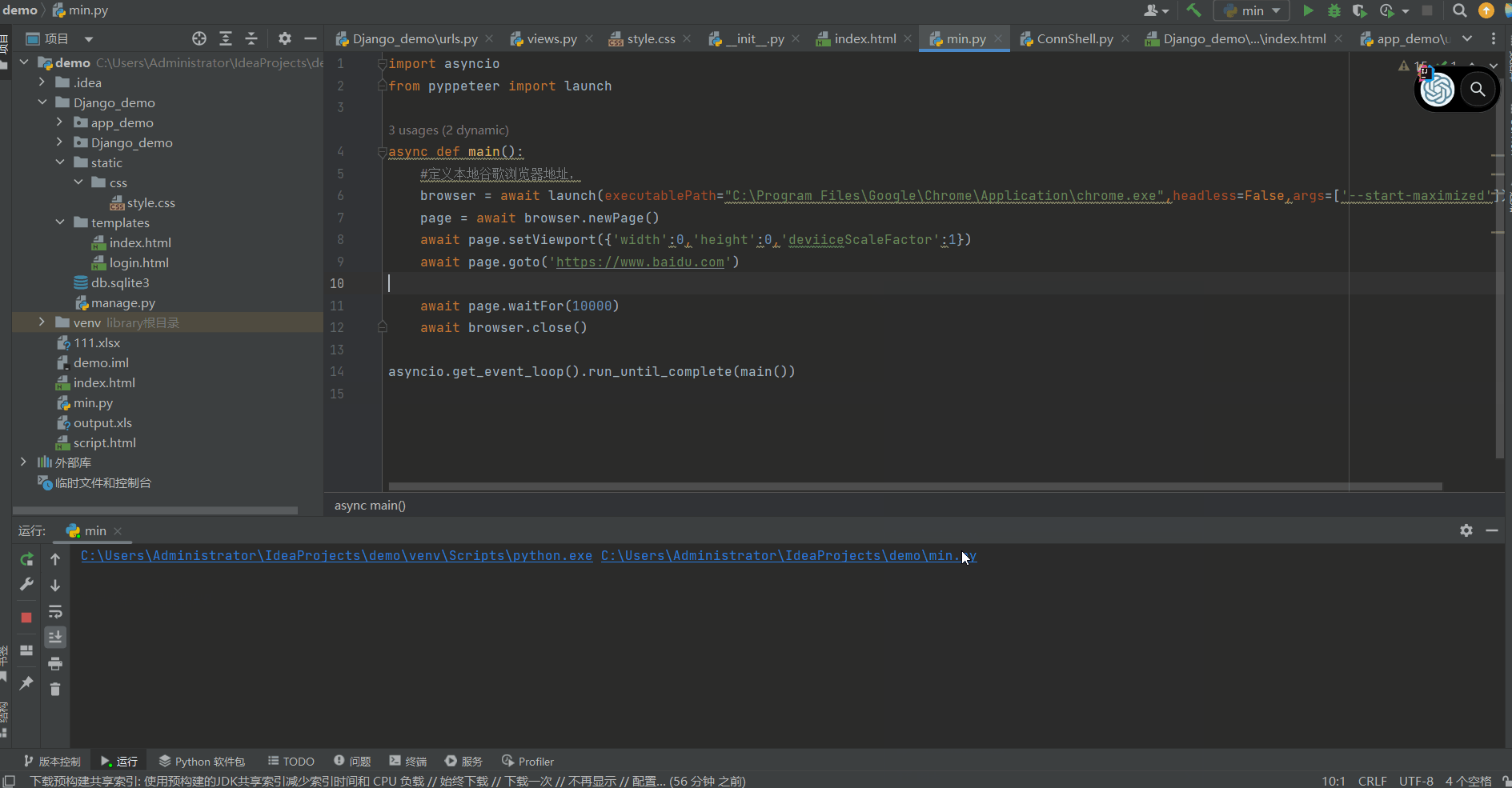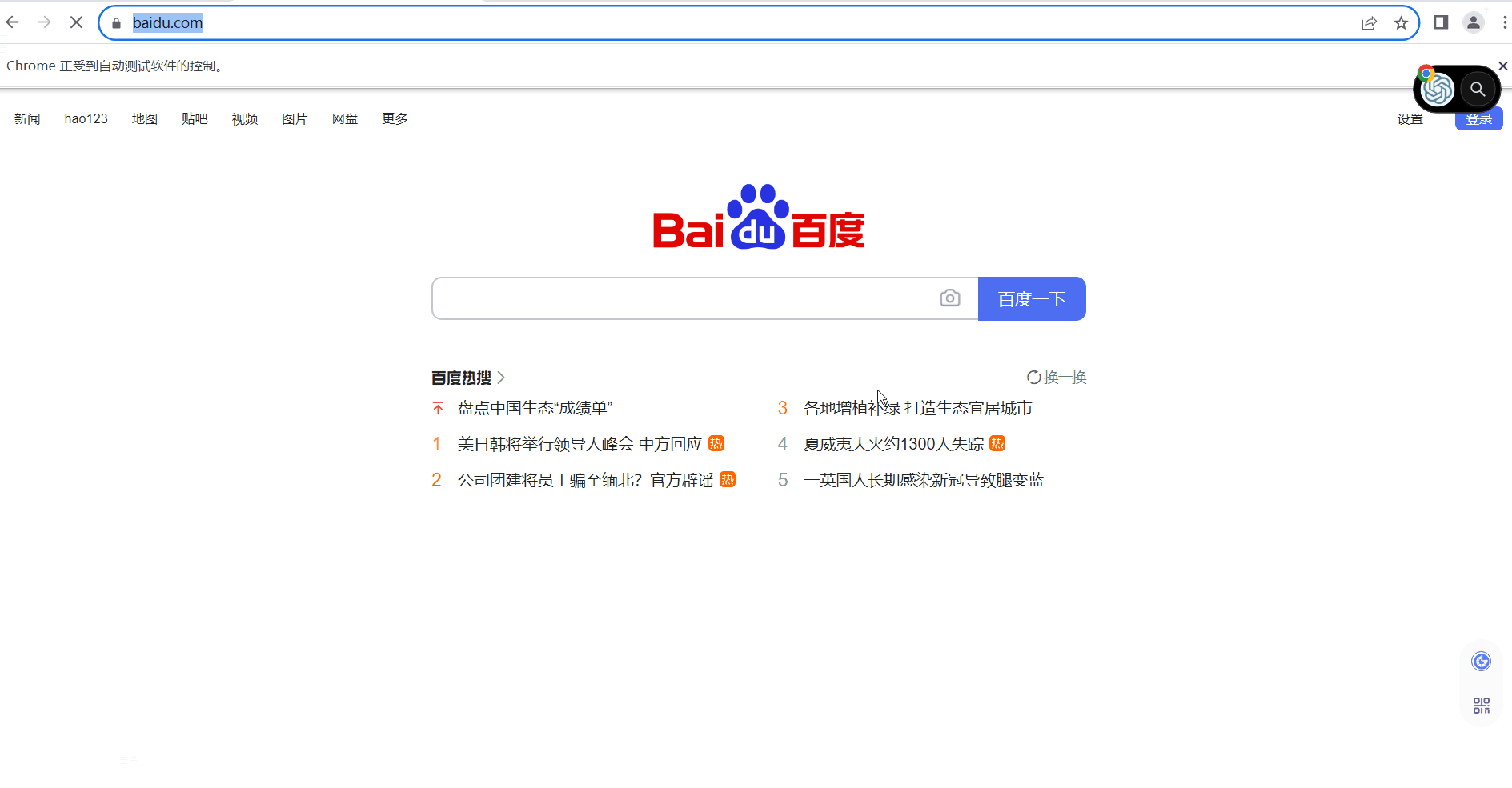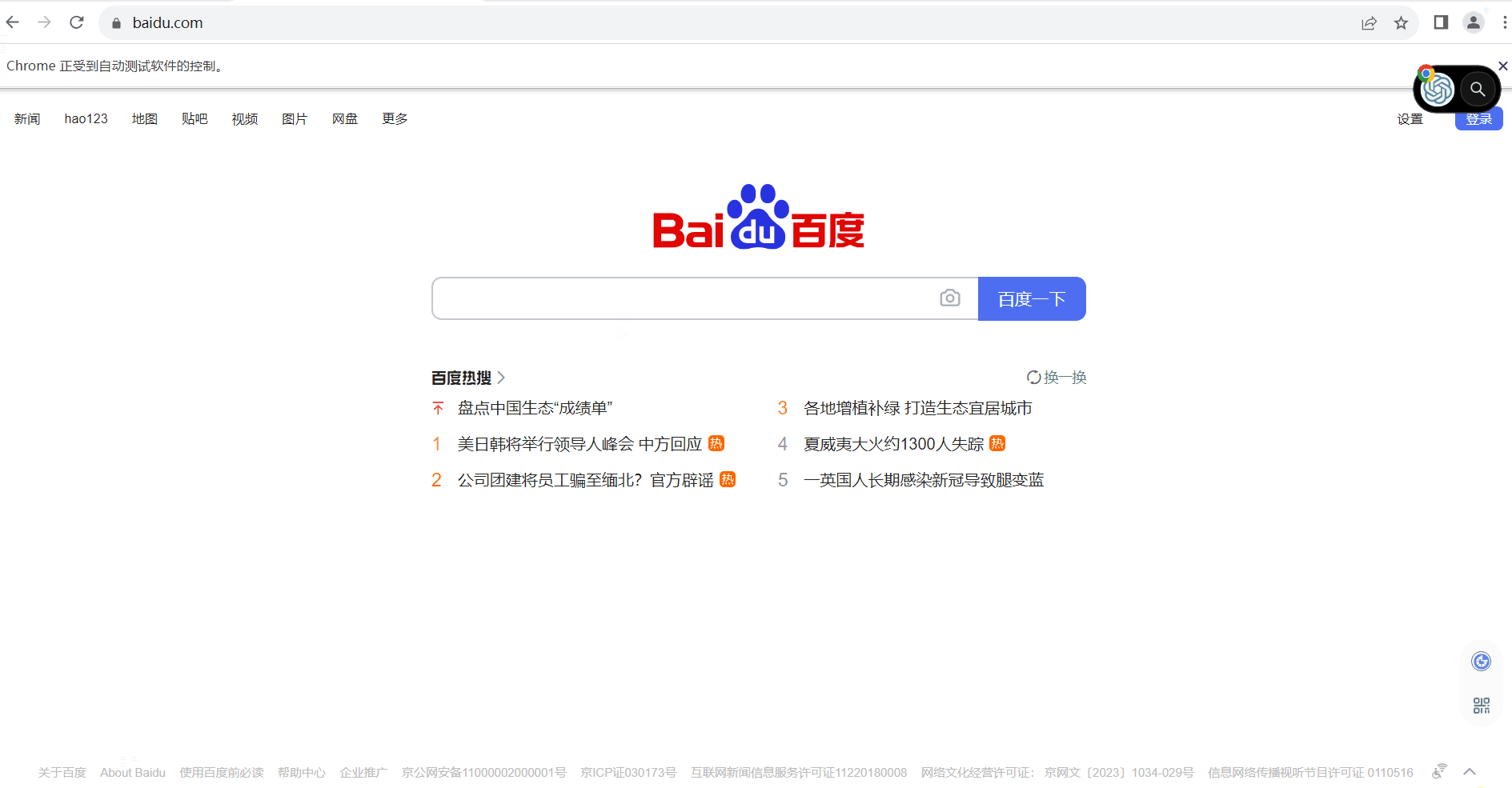
我们这里能打开浏览器并且跳转了,下面我们正常情况下需要做的就是模拟鼠标键盘的一些操作,我们这里以码云的登录注册平台来做测试
- #注册地址,可能有变动直接百度搜索
- https://gitee.com/signup?redirect_to_url=%2F%3Fchannel_utm_content%3D%25E5%25B9%25BF%25E5%2591%258A%25E8%2583%258C%25E6%2599%25AF%25E5%259B%25BE%26channel_utm_medium%3Dsem%26channel_link_type%3Dweb%26channel_utm_source%3D%25E7%2599%25BE%25E5%25BA%25A6%26sat_cf%3D2%26channel_utm_campaign%3D%25E5%2593%2581%25E4%25B8%2593%26channel_utm_term%3D%25E5%25B9%25BF%25E5%2591%258A%25E8%2583%258C%25E6%2599%25AF%25E5%259B%25BE%26_channel_track_key%3Du1BDg7fB%26link_version%3D1%26wl_src%3Dbaidu
二、寻找页面元素信息
浏览器页面根据我们分辨率大小和窗口大小,跳转浏览器的位置都会导致我们无法直接通过之前的方法获取坐标,这里我们依赖的是直接获取web页面的元素信息(span a dir id class等等)通过他们定位具体的元素坐标
登录页面查看元素
我们登录到注册页面按F12 进入开发者模式,点击查看栏能看到html的信息,点击左边的箭头,选择我们要查看的页面元素,下面图中是选择了第一个输入框的位置
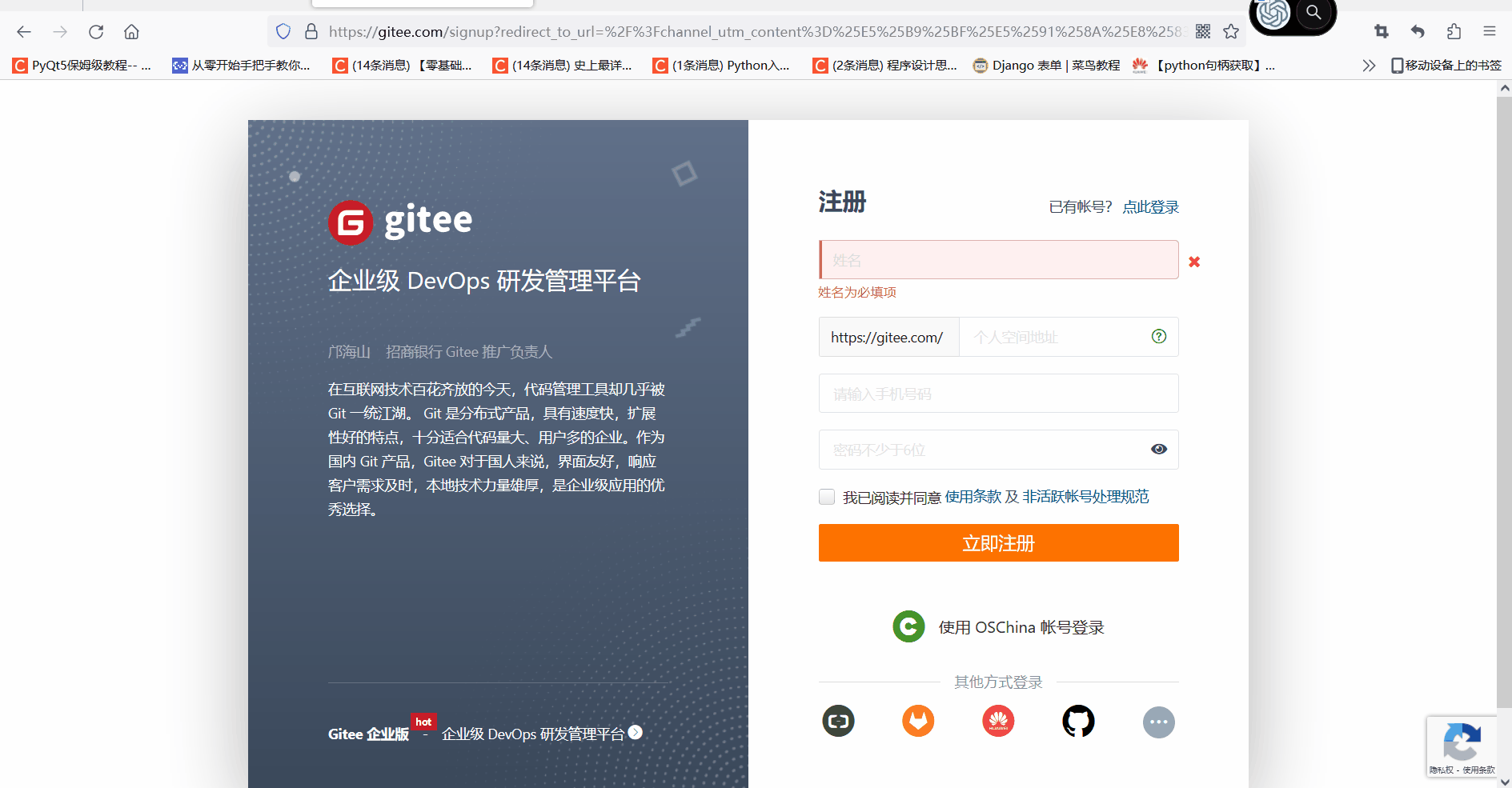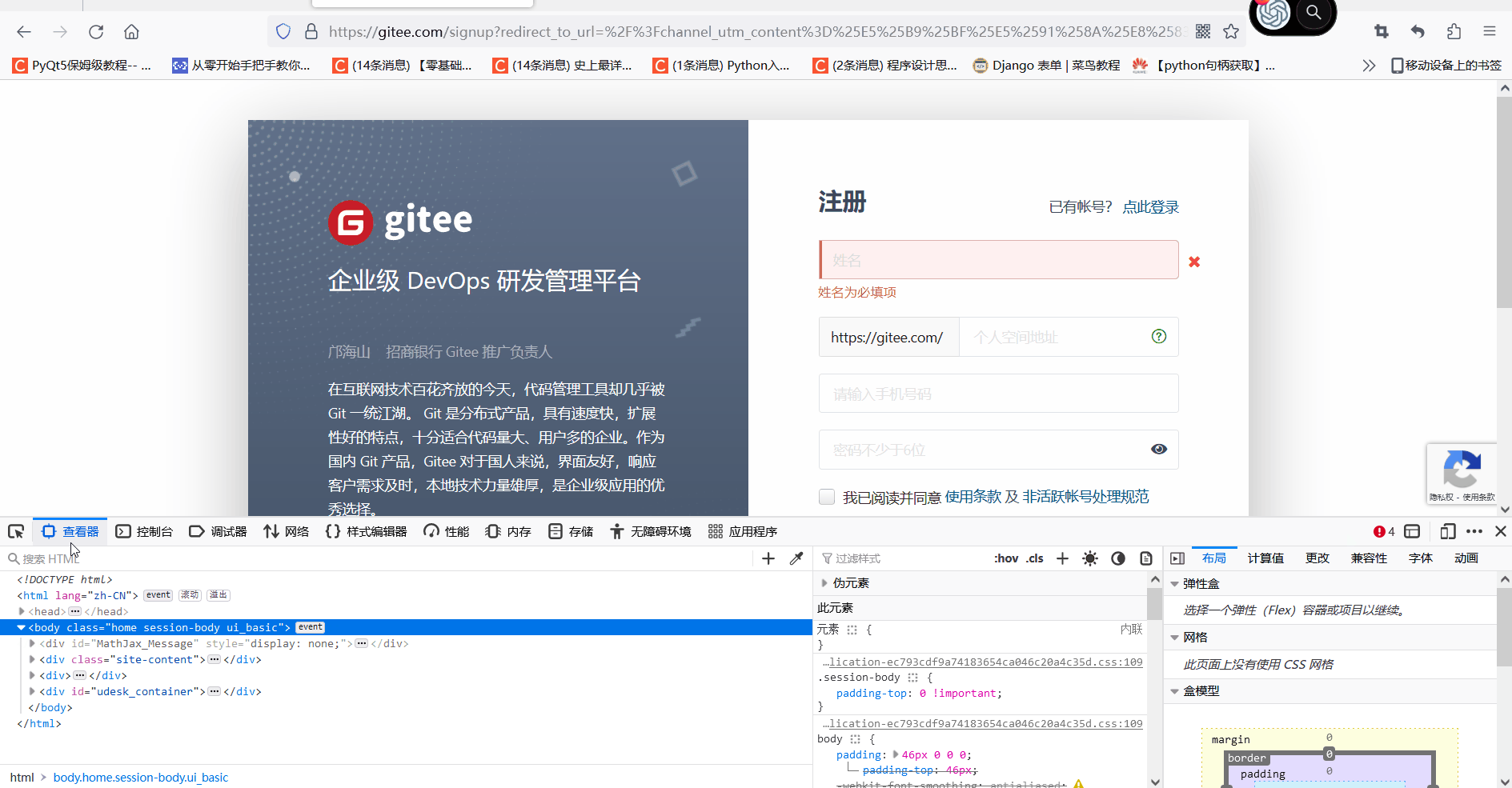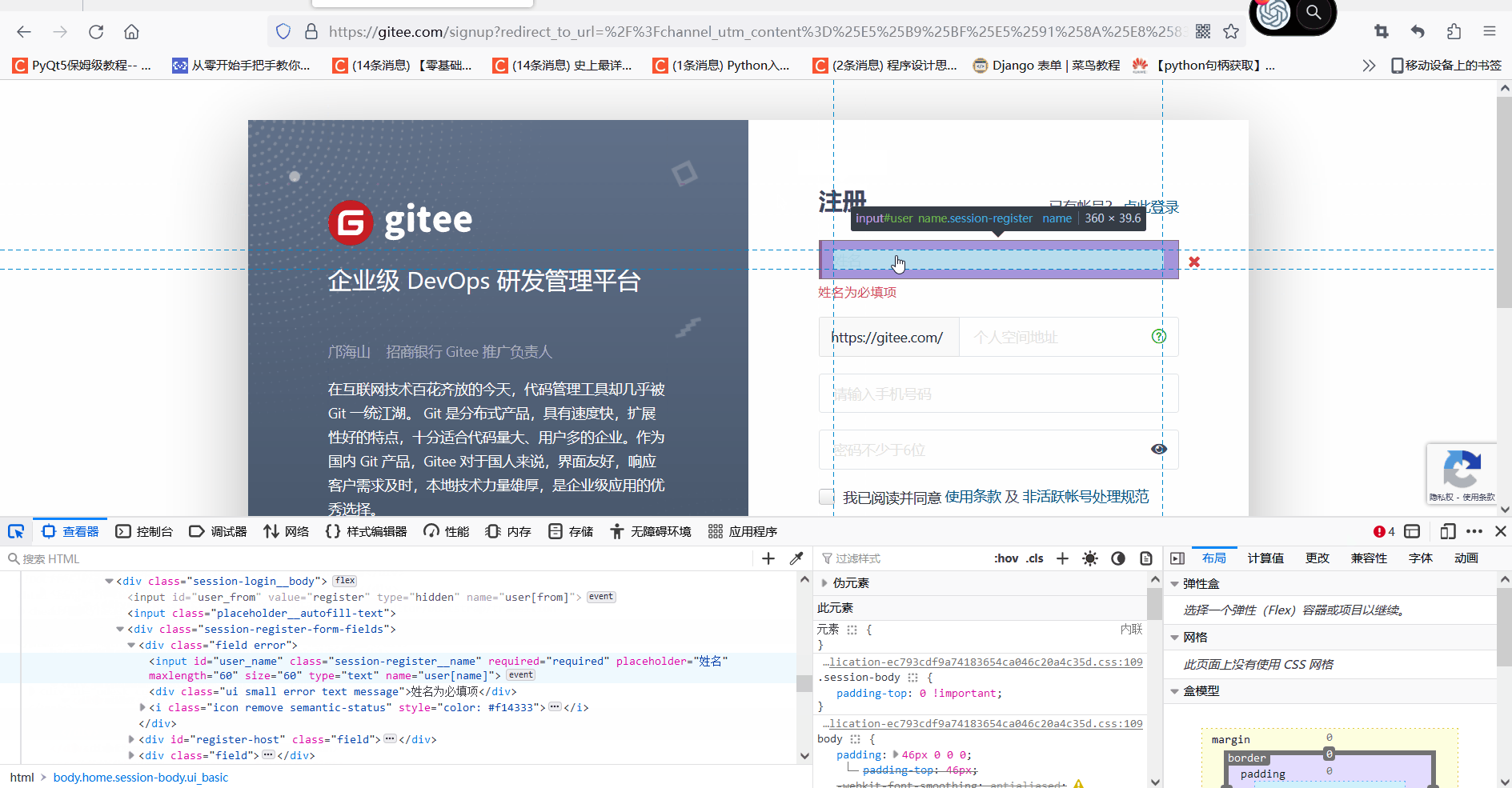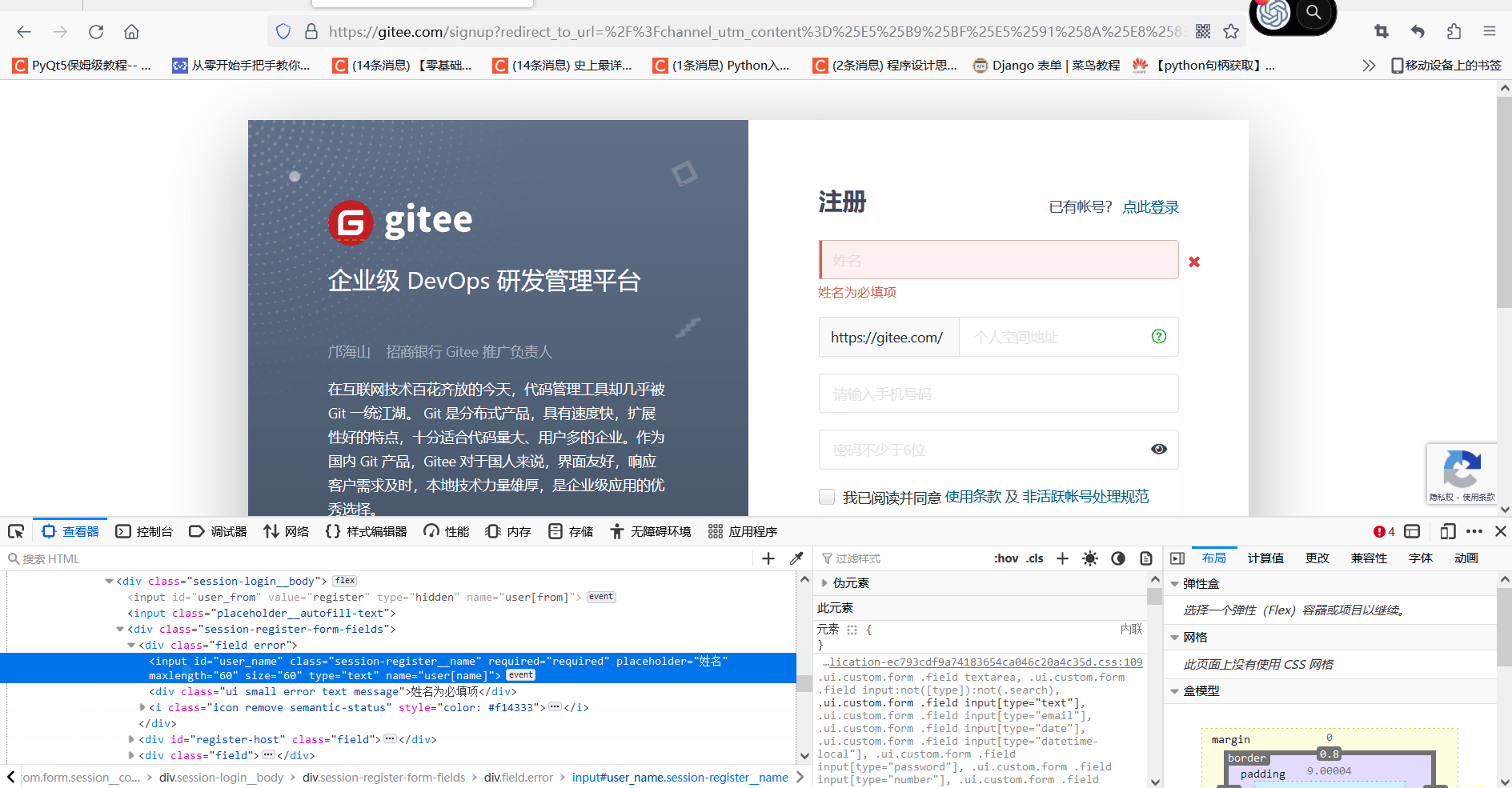
得到html信息
<input class="session-register__name" required="required" placeholder="姓名" maxlength="60" size="60" type="text" name="user[name]" id="user_name">三、常见的几种获取元素坐标方法
各个场景的html编写的不相同,同一种方法切换场景后很可能就不好使了,这里放几种我常用的方法
1、通过元素class或id获取坐标
- #基于class名称获取坐标
- async def click_radio(page,selector):
- await page.waitForSelector(selector) #等待元素出现
- element = await page.querySelector(selector) #查找指定的元素信息
- if element:
- box = await element.boundingBox() #获取元素坐标和尺寸
- x = box['x']
- y = box['y']
- widht = box['width']
- height = box['height']
-
- await page.mouse.move(x + widht / 2, y + height / 2)
-
- await page.mouse.down() #模拟鼠标点击一次
- await page.mouse.up()
- else:
- print("element not found")
-
-
-
调用函数
- async def main():
- ...
- #修改地址为码云
- await page.goto('https://gitee.com/signup?redirect_to_url=%2F%3Fchannel_utm_content%3D%25E8%25BF%259B%25E5%2585%25A5%25E5%25AE%2598%25E7%25BD%2591%26channel_utm_medium%3Dsem%26channel_link_type%3Dweb%26channel_utm_source%3D%25E7%2599%25BE%25E5%25BA%25A6%26sat_cf%3D2%26channel_utm_campaign%3D%25E5%2593%2581%25E4%25B8%2593%26channel_utm_term%3D%25E4%25B8%25BB%25E6%258C%2589%25E9%2592%25AE1%26_channel_track_key%3Dsee7zmAJ%26link_version%3D1%26wl_src%3Dbaidu')
-
- #调用自定义函数,传参page class名称前面要加点"."
- await click_radio(page,".session-register__name")
-
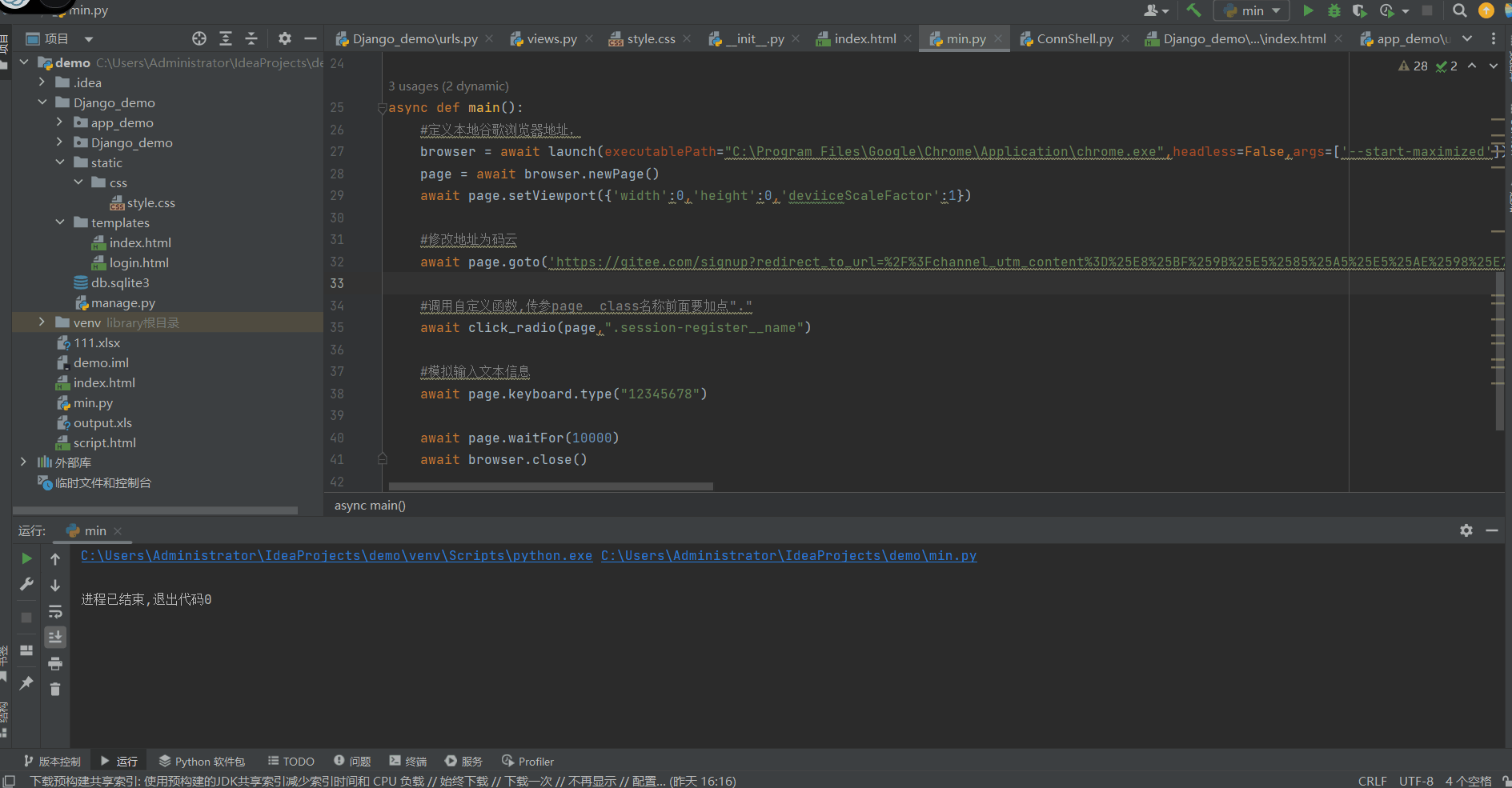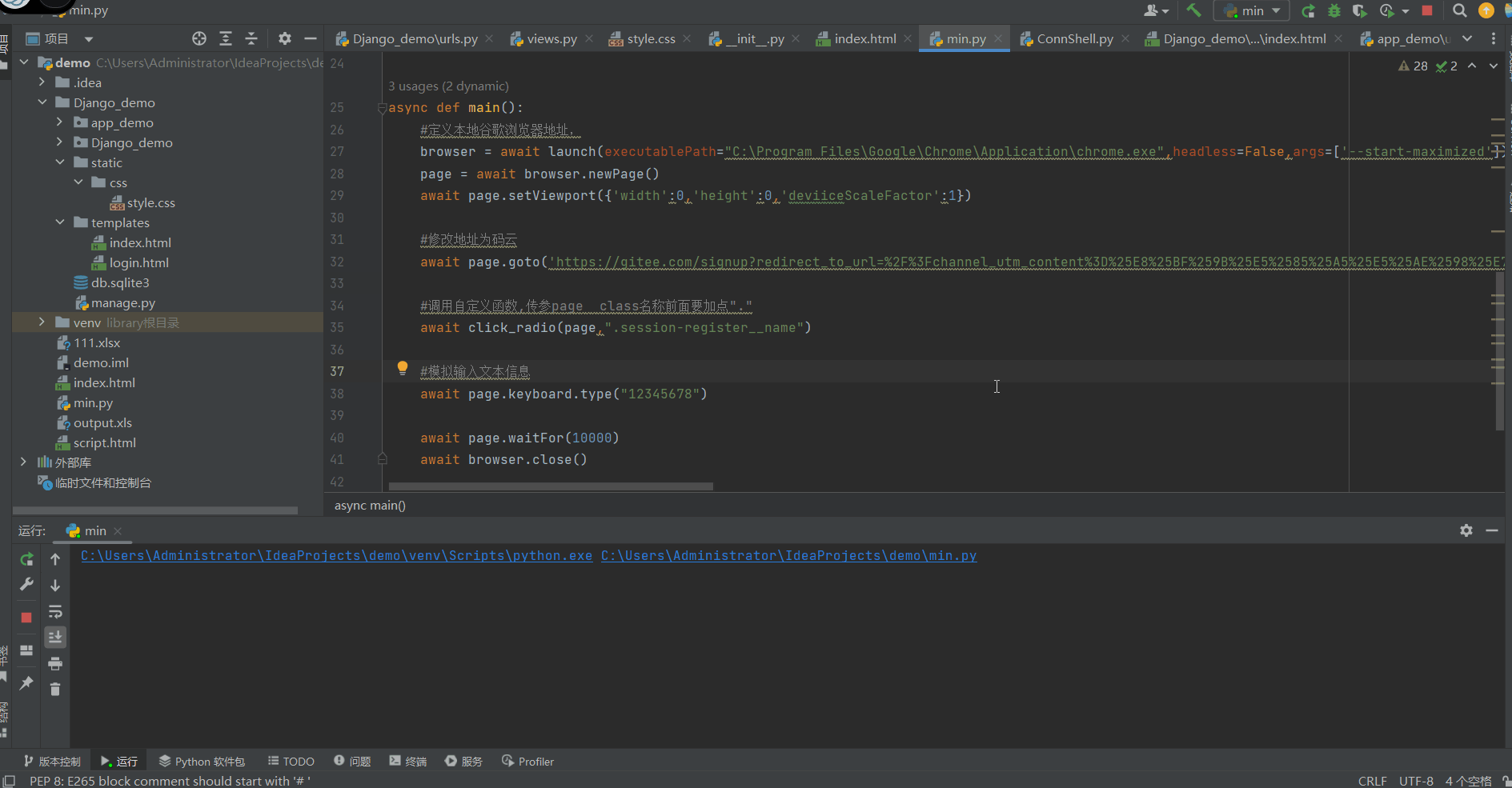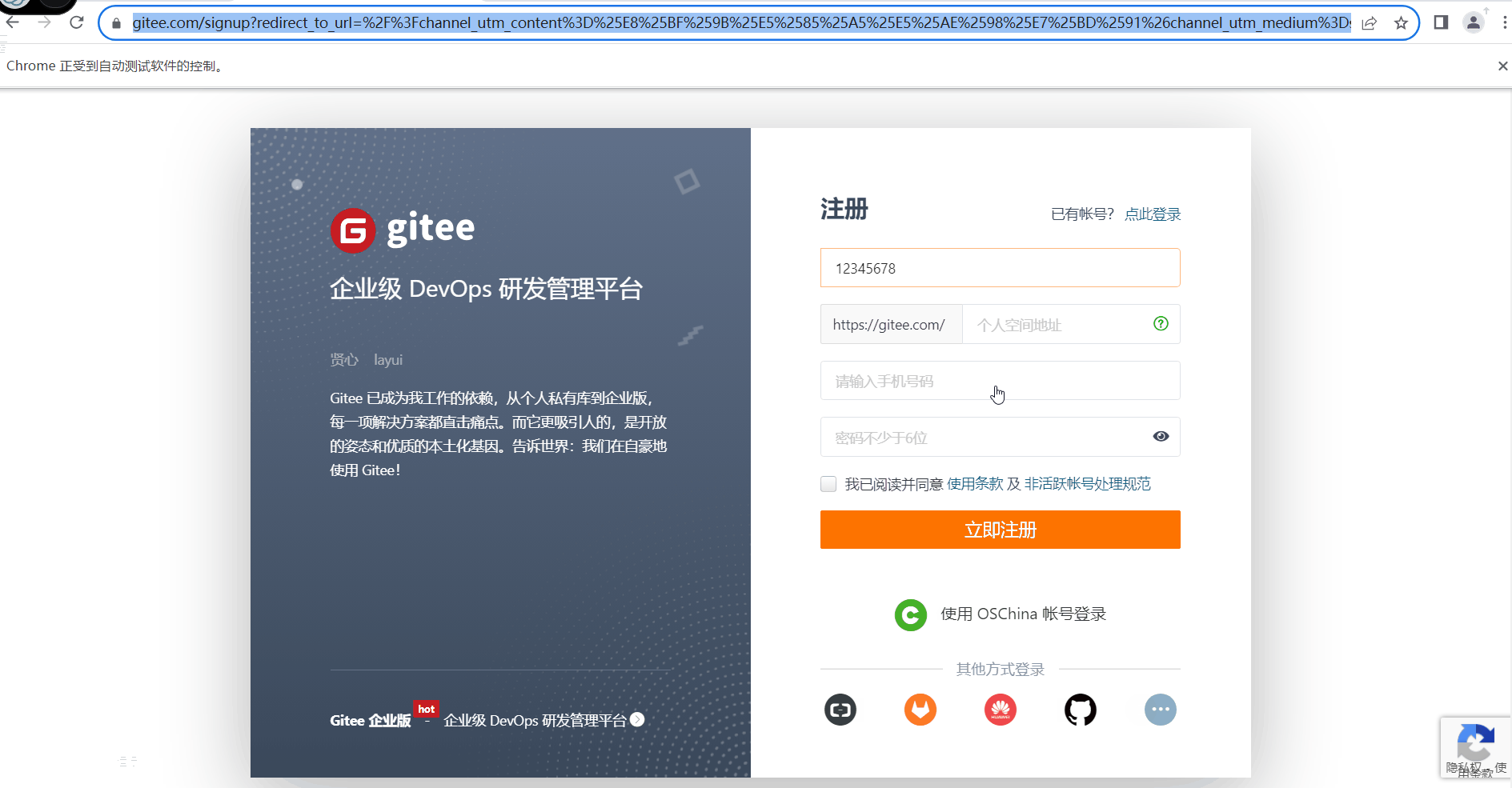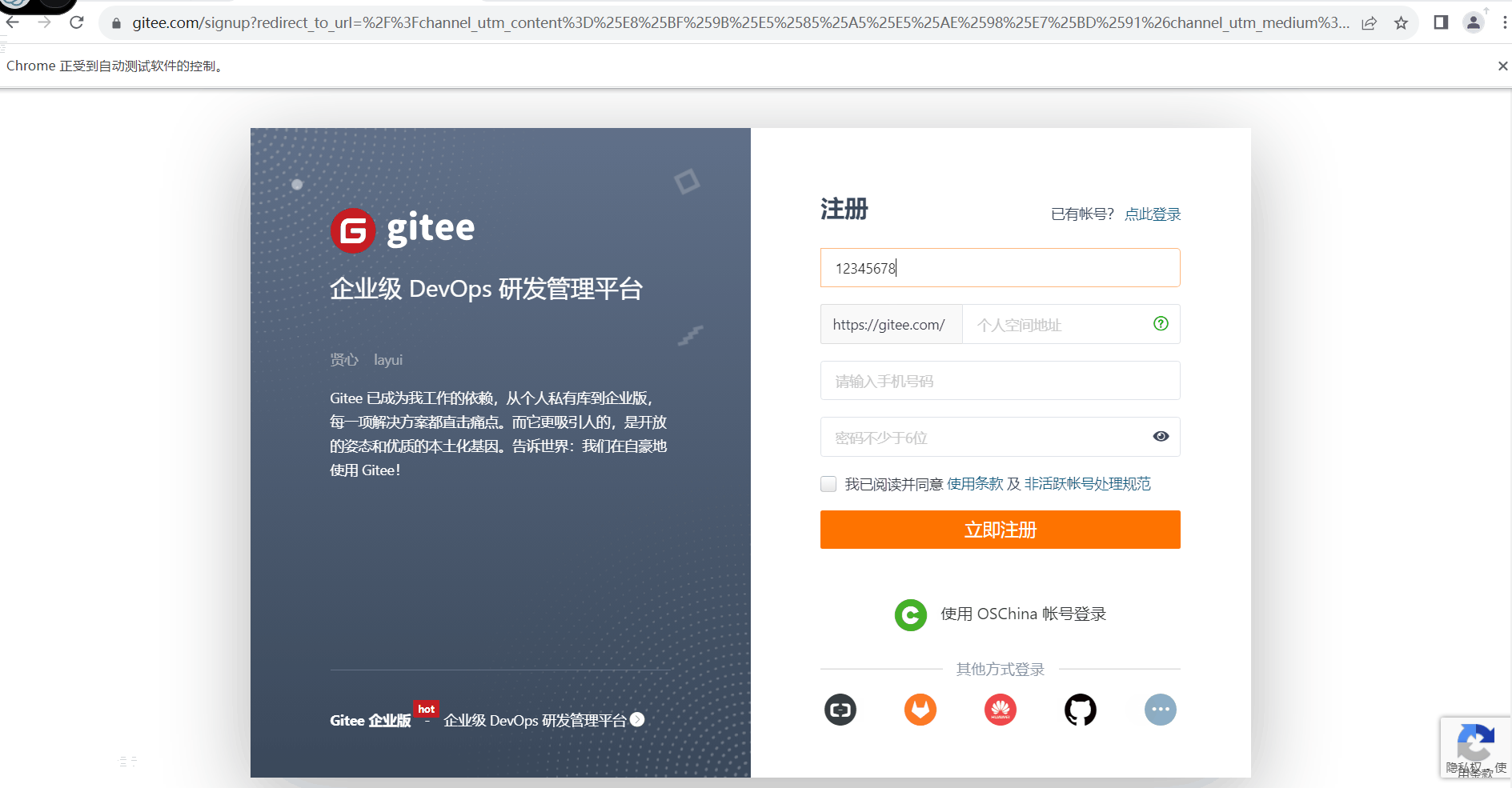
- #模拟输入文本信息
- await page.keyboard.type("12345678")
- ...
- asyncio.get_event_loop().run_until_complete(main())
注意
上面案例中使用的是class获取的坐标,如果没有定义class或者有多个相同的class时可以通过id获取,区别在于class传参是 "." 加class名称 而id传参是 "#" 加id名称
小知识
- //其实在遇到不是特别复杂的情况下,可以不用上面的方法,比如输入账户密码之类的
- await page.waitForSelector(#id名称/.类名)
2、通过文本获取坐标
这个在申请某些东西的时候可能会经常用到,比如申请云服务,某某产品,自研平台等等,会有大量需要挨个点击的图标,用上面第一个的时候不好使了就用这个方法
获取按钮html
<button name="button" type="submit" id="btn-submit" class="ui orange fluid submit button register-btn-submit large" sa_evt="click_GiteeCommunity_signup_signup">立即注册</button>向上面有文本内容显示的就可以用,我们获取到他的文本内容"立即注册" 和元素名称button
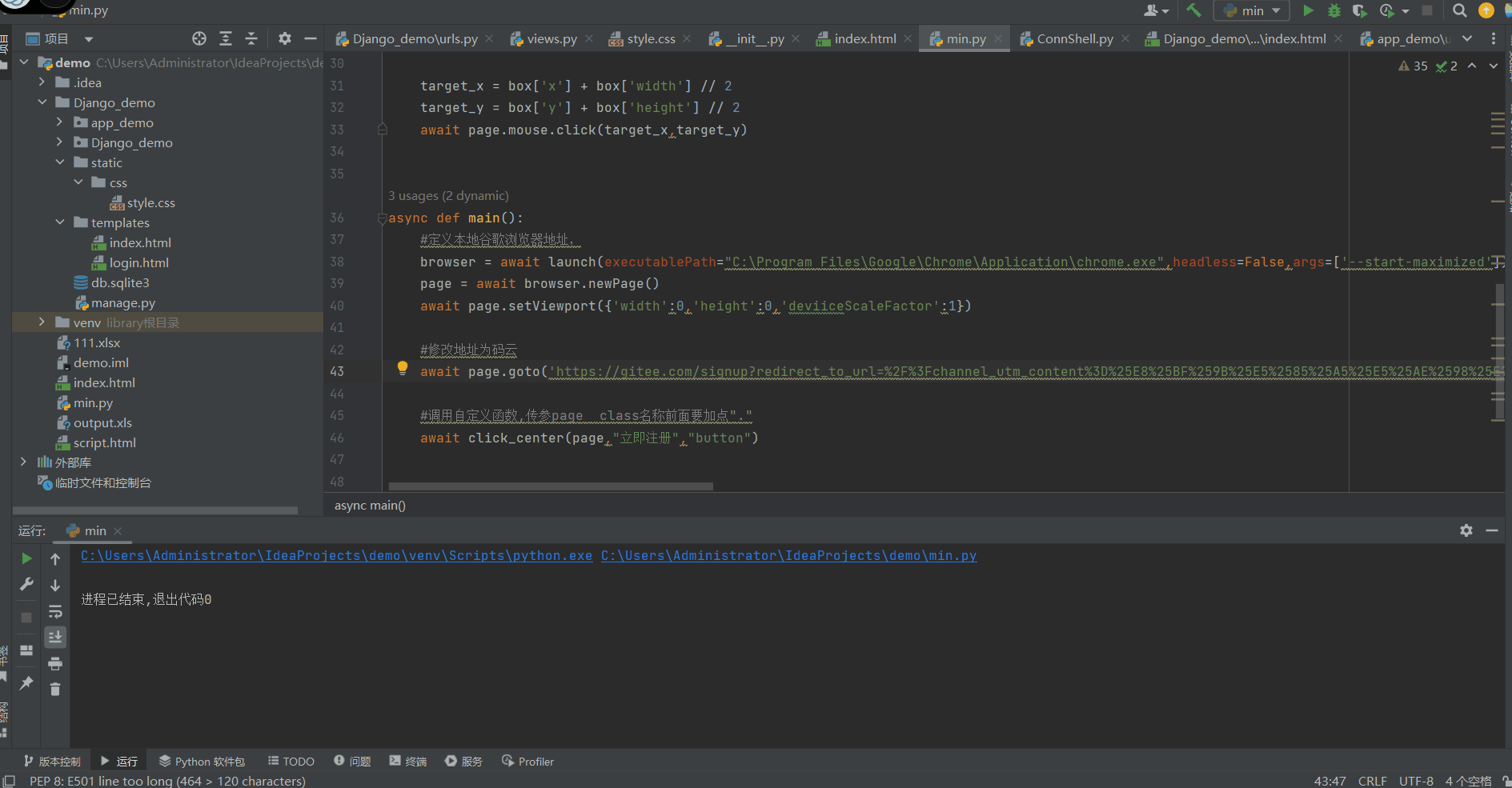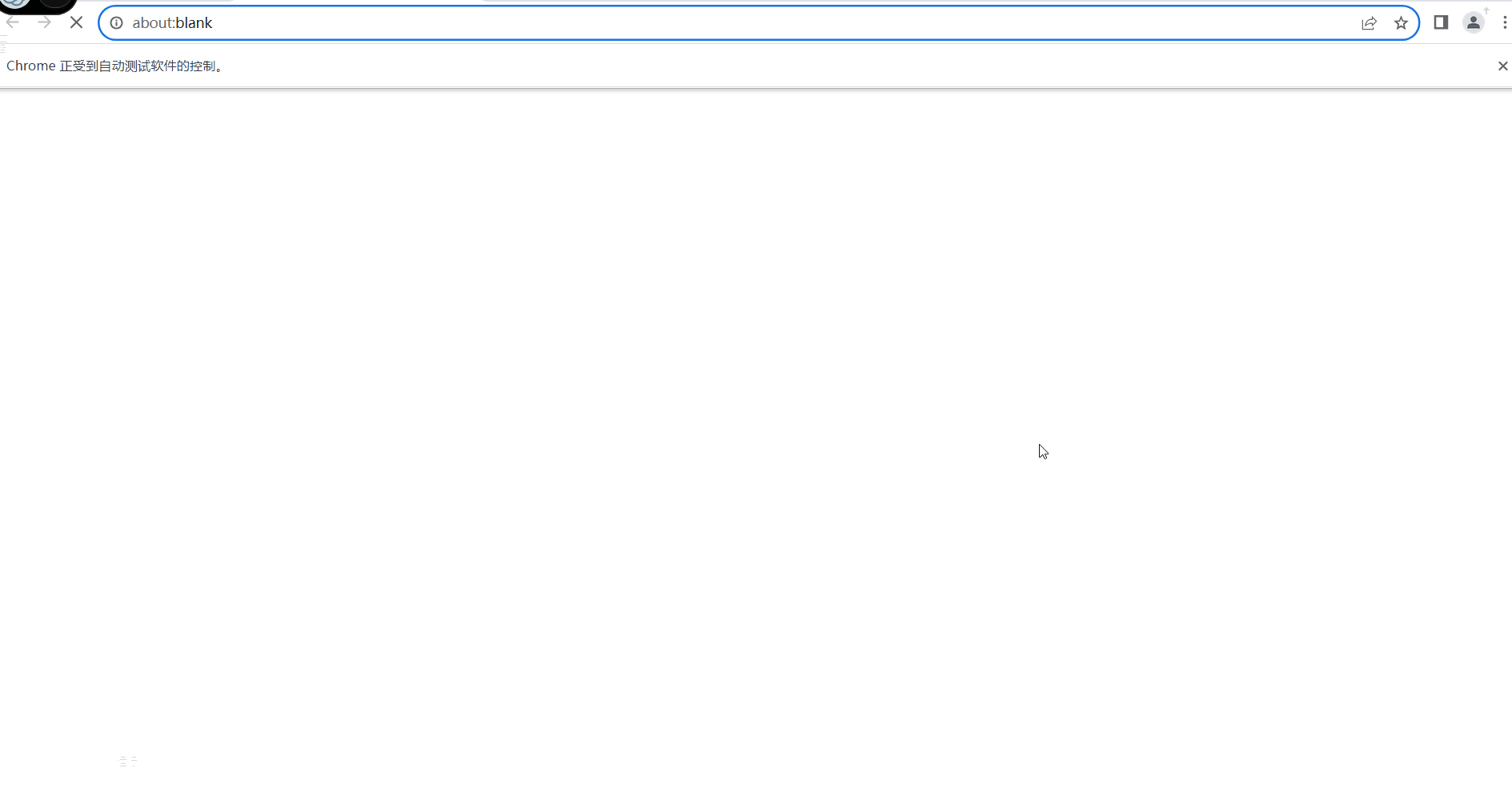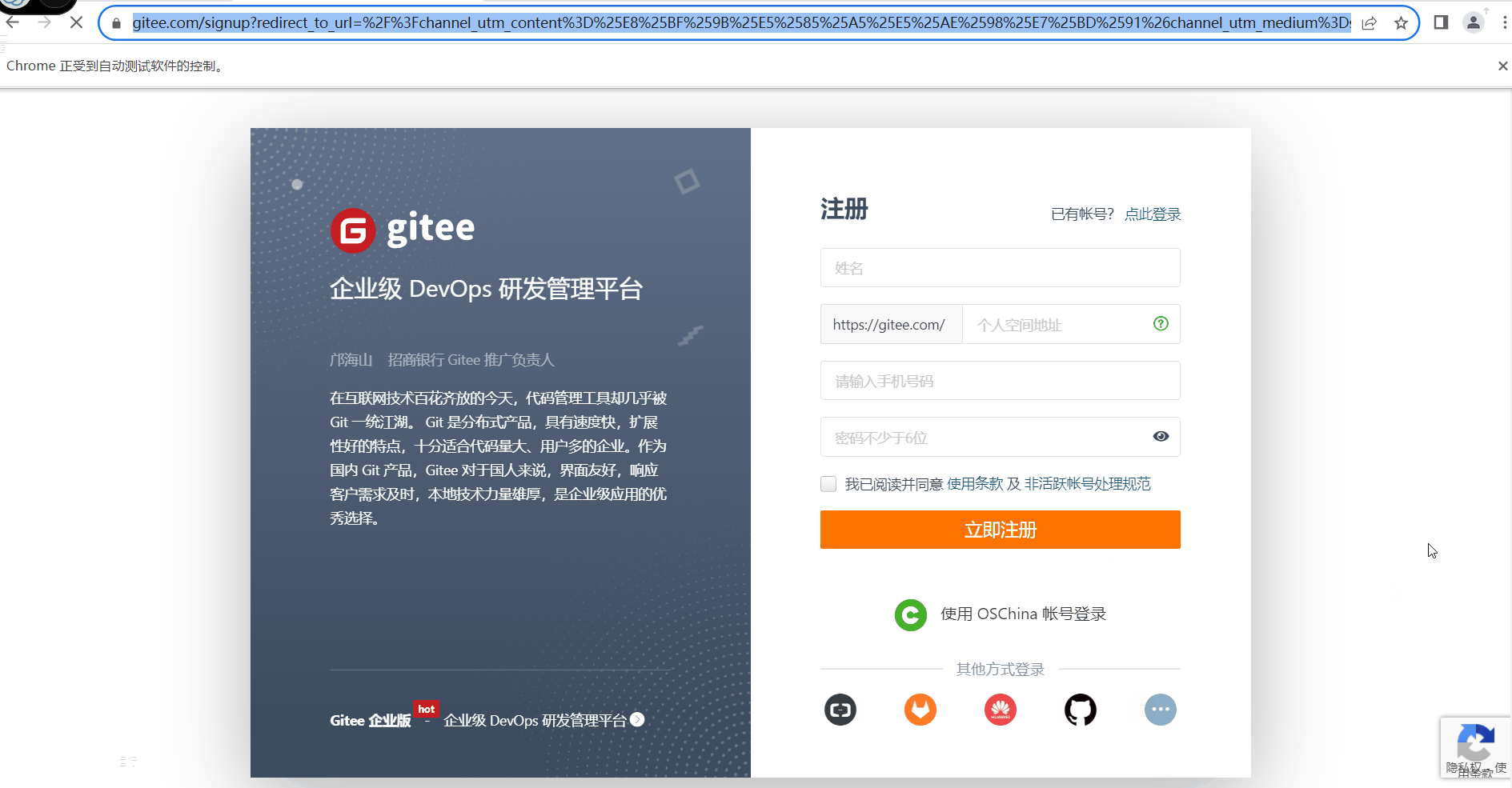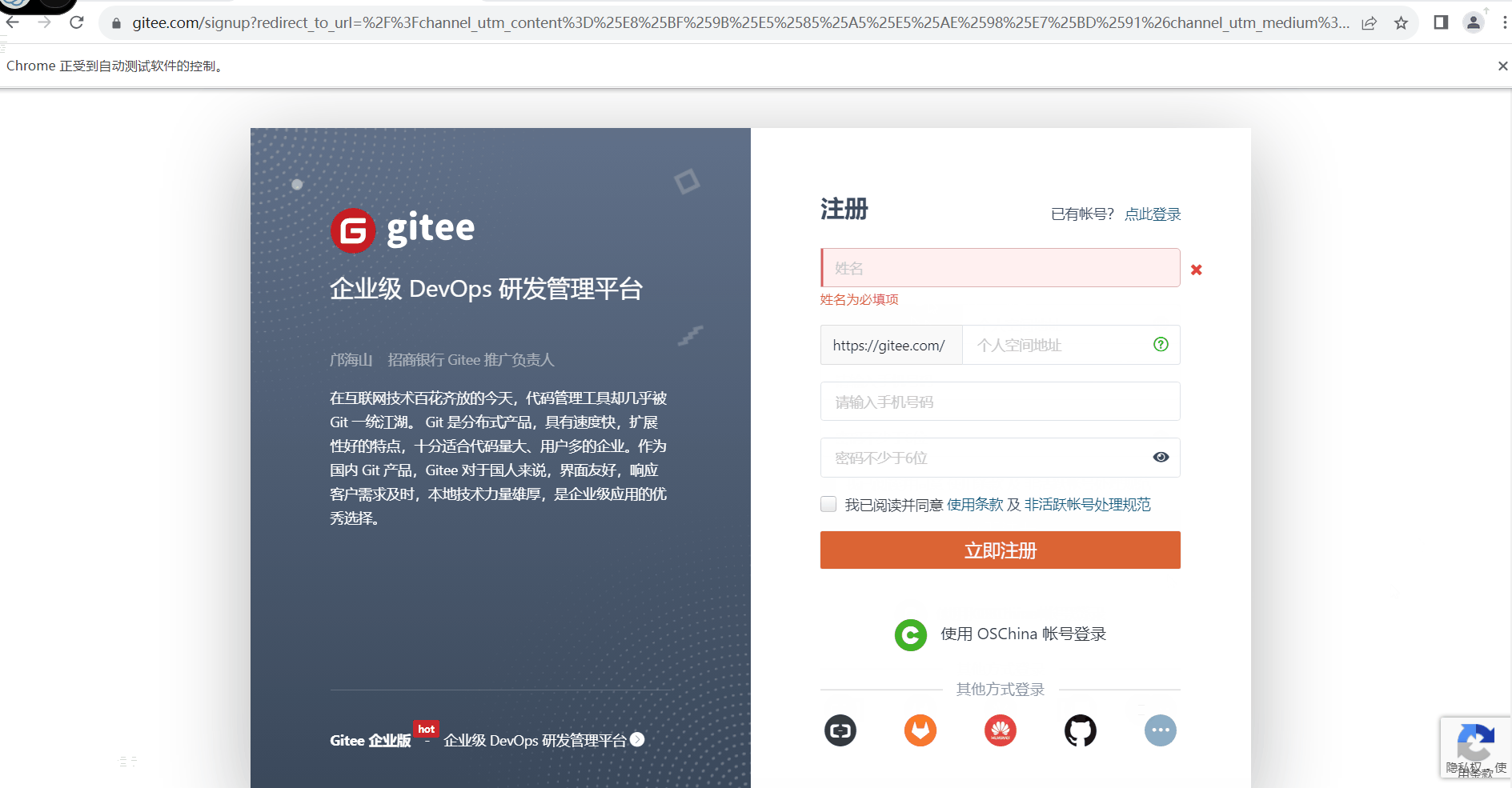
- async def click_center(page,selector,type):
- #定义检索元素格式
- test = "//" + type +"[text()=" + "\'" + selector + "\'" + "]"
- element = await page.waitForXPath(test) #获取对应元素
- box = await element.boundingBox() #获取坐标
-
- target_x = box['x'] + box['width'] // 2
- target_y = box['y'] + box['height'] // 2
- await page.mouse.click(target_x,target_y)
调用
- async def main():
-
- browser = await launch(executablePath="C:\Program Files\Google\Chrome\Application\chrome.exe",headless=False,args=['--start-maximized'])
- page = await browser.newPage()
- await page.setViewport({'width':0,'height':0,'deviiceScaleFactor':1})
-
- await page.goto('https://gitee.com/signup?redirect_to_url=%2F%3Fchannel_utm_content%3D%25E8%25BF%259B%25E5%2585%25A5%25E5%25AE%2598%25E7%25BD%2591%26channel_utm_medium%3Dsem%26channel_link_type%3Dweb%26channel_utm_source%3D%25E7%2599%25BE%25E5%25BA%25A6%26sat_cf%3D2%26channel_utm_campaign%3D%25E5%2593%2581%25E4%25B8%2593%26channel_utm_term%3D%25E4%25B8%25BB%25E6%258C%2589%25E9%2592%25AE1%26_channel_track_key%3Dsee7zmAJ%26link_version%3D1%26wl_src%3Dbaidu')
-
- #调用函数,定义文本+元素并点击
- await click_center(page,"立即注册","button")
-
-
- await page.waitFor(10000)
- await browser.close()
-
- asyncio.get_event_loop().run_until_complete(main())
测试通过上面俩方法能解决绝大部分问题,如果遇到的坐标有偏移,比如说我文本输入框在文本的右侧,我通常会用下面的方法
- target_x = box['x'] + box['width'] + 200
- target_y = box['y'] + box['height'] // 2
小知识
当你遇到点击某个按钮后会跳转到下一步的时候,最好按钮按下后面的第一个步骤中添加 await page.waitForNavigation() 这个是等等页面加载完成
3、修改页面元素,然后基于页面元素输入
特殊情况下,上面的方法都不适用,比如说我遇到过一个常见,需要申请两个文件系统/app1 和/app2 一个50G 一个100G ,但他的输入框上只有一个class,并且每个class都是完全已有的,没有id什么其他的元素,特征就是初始值为一个输入框,可以新增一个输入框,我的想法我把第一个输入框的元素class进行修改,第二个元素出现时class类就和第一个元素不同了,然后基于这个修改后的class名称在做具体的操作
- 我这里通过密码那一栏获取到下面的代码
- <input required="required" autocomplete="new-password" placeholder="密码不少于6位" data-password-regx="^(?=.*[0-9])(?=.*[a-zA-Z!@_#$%^&*()\-+=,.?]).{6,32}$" type="password" name="user[password]" id="user_password">
-
- 可以看到,他有一个id,但是没有做class我们用这个做实验
案例
- await page.evaluate('''() => {
- const elements = document.querySelectorAll('#user_password');
- elements.forEach(element => {
- element.classList.add("ddd");
- });
- }''')
-
-
- #我们需要等等元素出现后在进行下面的操作
- await page.waitForSelector(".ddd")
- ...
- #另外,单独说个事,如果切换页面后逻辑中存在多个等待页面加载完成,那么页面就不动了
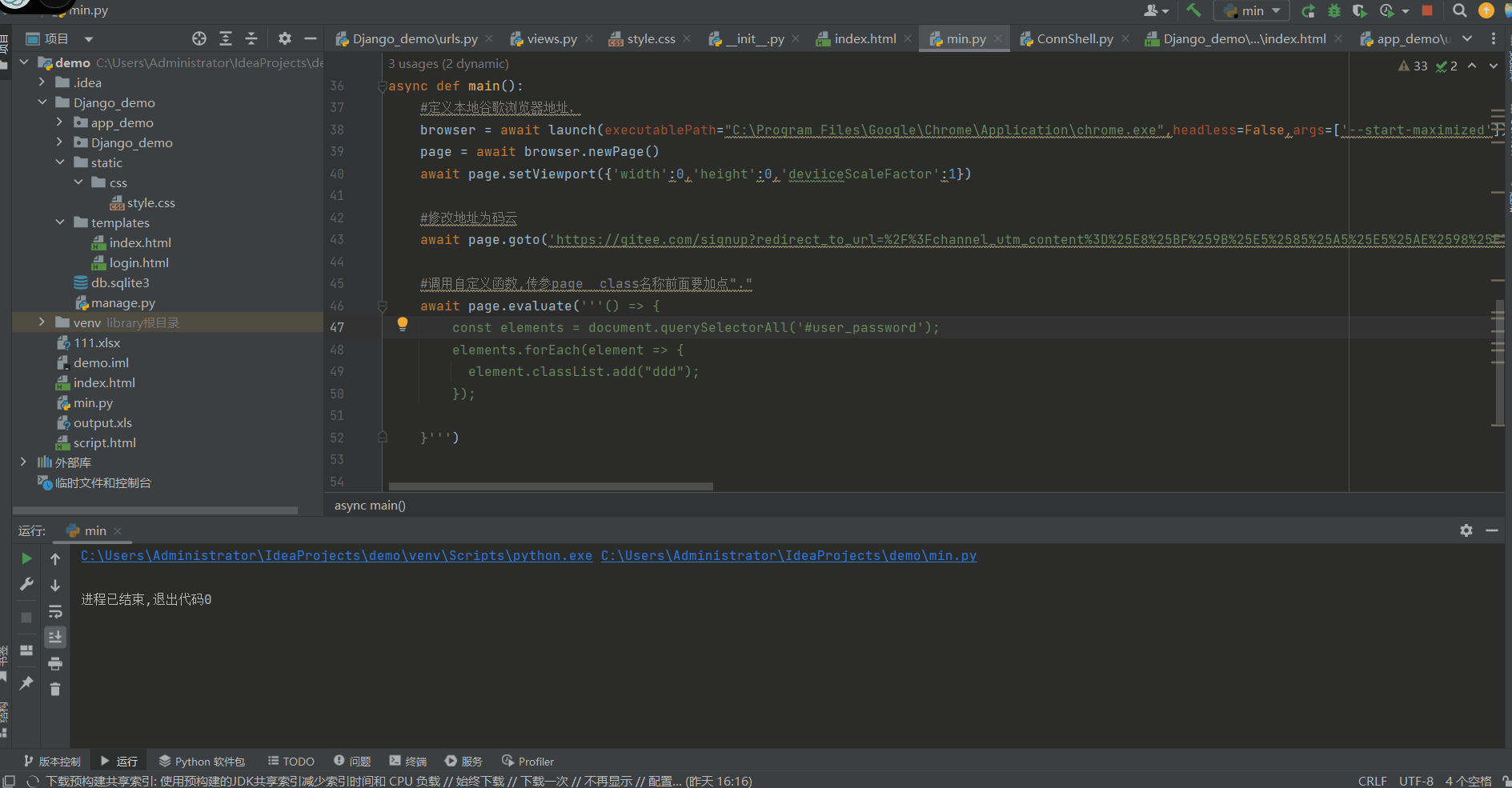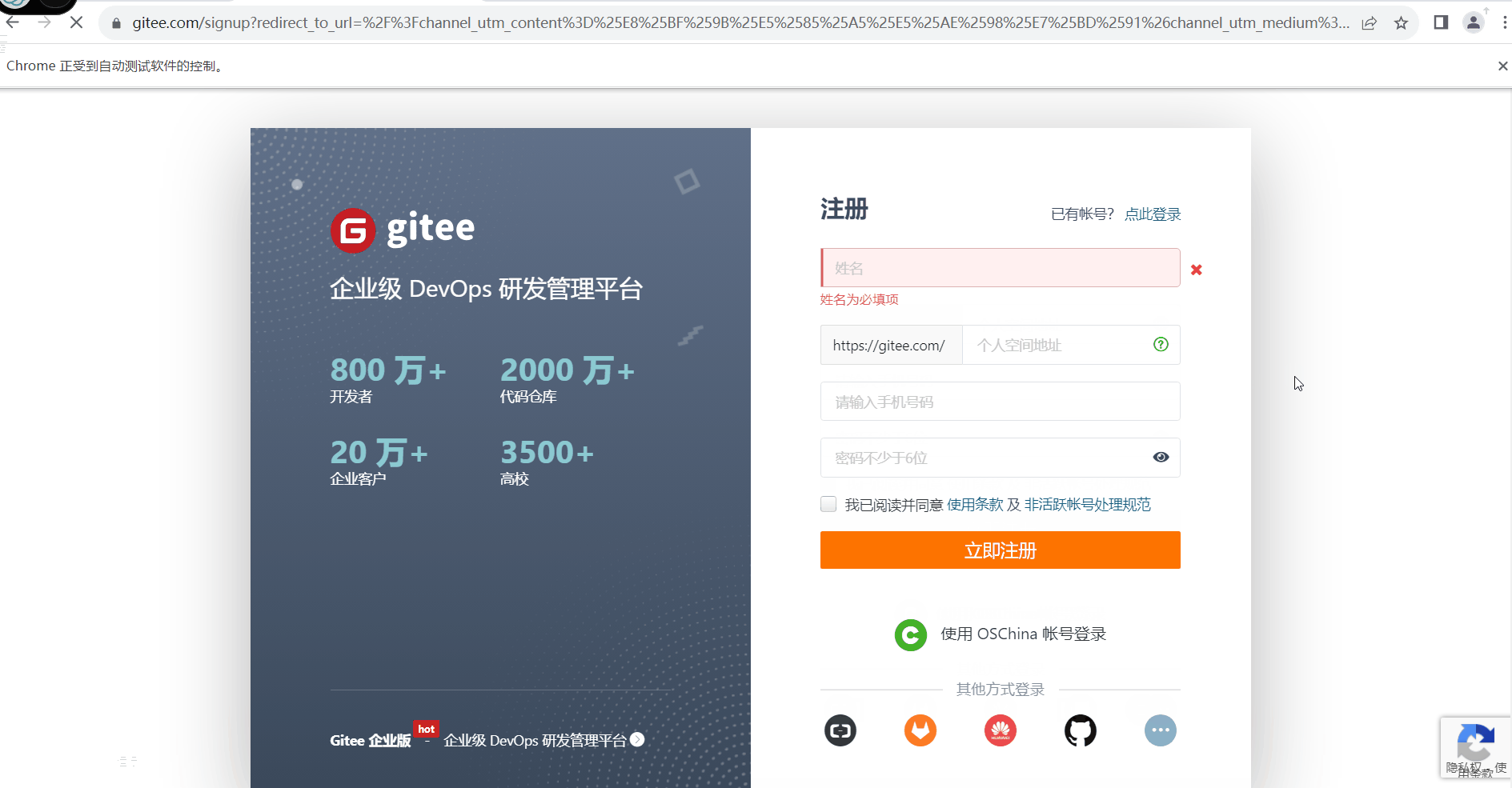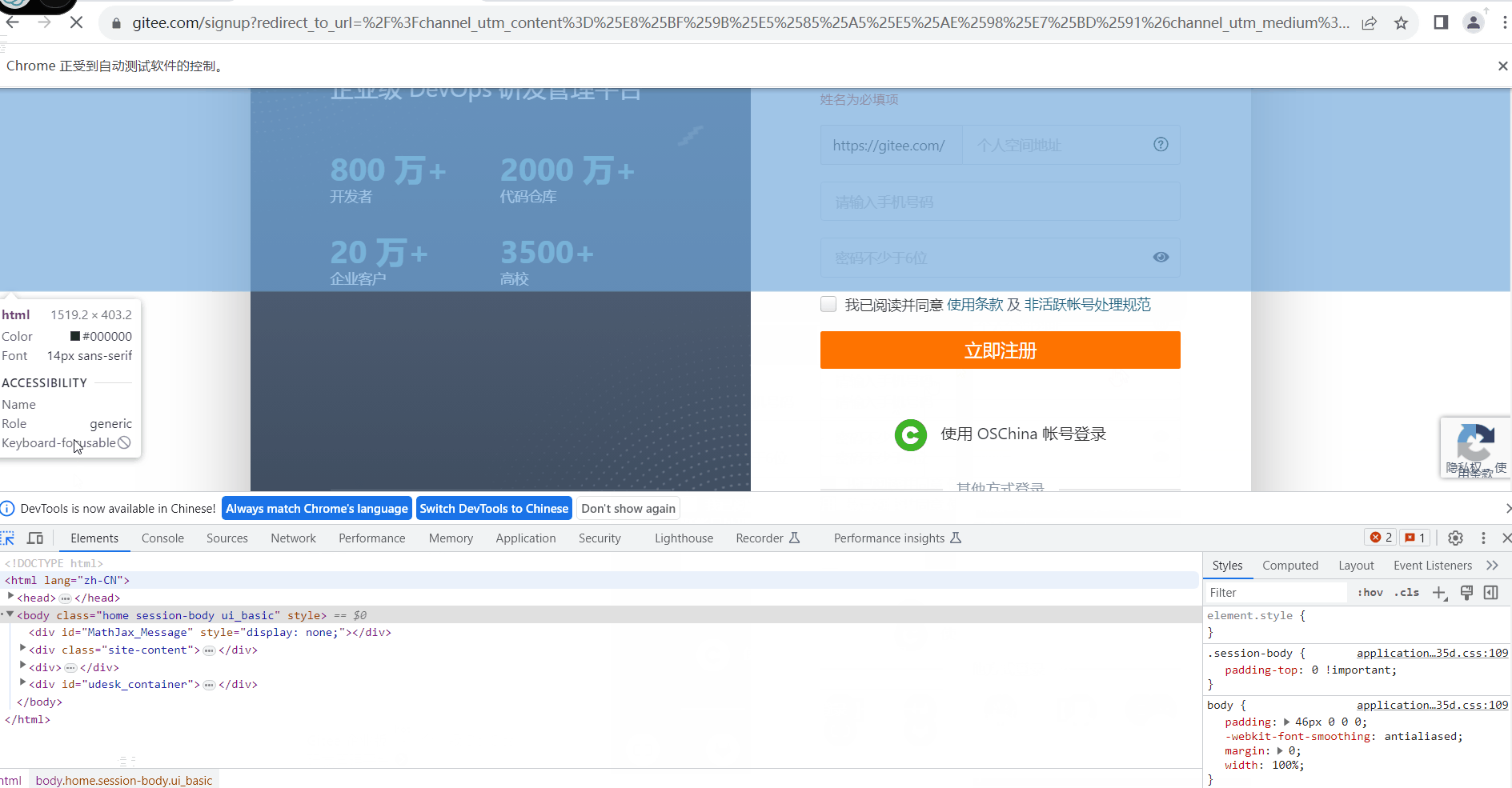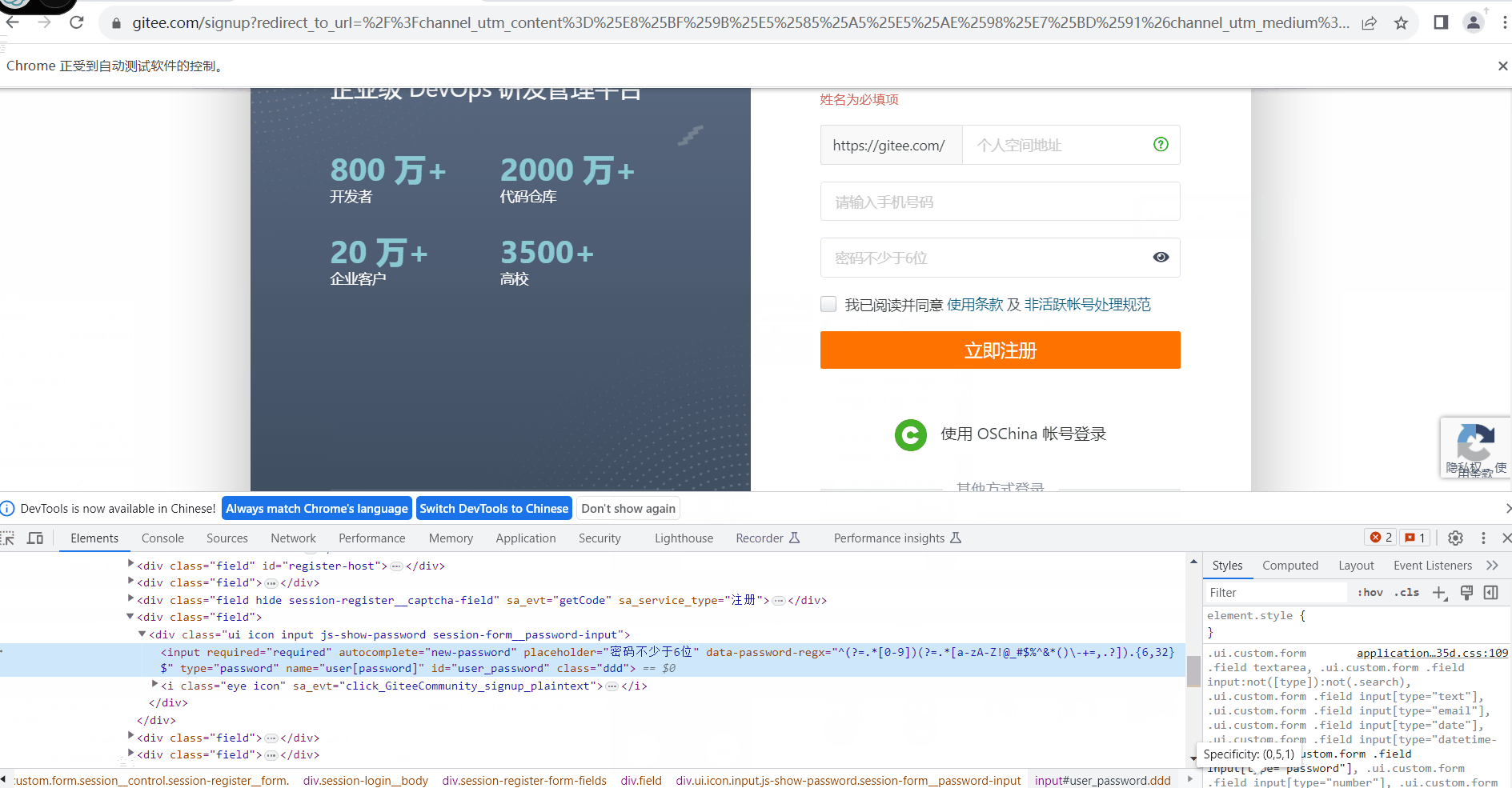
可以看到上面图里他帮忙添加了一个class的名称,我们可以在后面去调用他,需要注意的是,如果你要添加的元素的id不唯一那么所有的元素都会去添加相同的class,如果碰到了多个class名称,如 app1 app2 app3 class的名称则需要设置为 .app1 .app2 .app3 如果是id则是 #app1 #app2 #app3
4、查找特定文本元素并点击
我又碰到一个特殊的案例,我没找到演示用的页面,当记录下笔记了,这个是应用于li的一个下拉选项的场景,和第二步类似
- async def click_multiple(page,selector):
- elements = await page.JJ('li')
- for element in elements:
- text_content = await element.getProperty("textContent")
- text_content = await text_content.jsonValue()
- if selector in text_content:
- box = await element.boundingBox()
- coordinates = {
- 'x': box['x'],
- 'y': box['y'],
- 'width': box['width'],
- 'height': box['height']
- }
- await element.click()
上面的函数是查找页面所有的
li元素,并检查每个元素的文本内容中是否包含给定的选择器。如果找到了匹配的元素,则对该元素执行点击操作。
参数说明
- async def click_multiple(page, selector):
- elements = await page.JJ('li') # 查找页面中所有的 <li> 元素并保存在 elements 变量中
- for element in elements: # 遍历 elements 中的每个元素
- text_content = await element.getProperty("textContent") # 获取元素的文本内容
- text_content = await text_content.jsonValue() # 将文本内容转换为 JSON 格式
- if selector in text_content: # 检查文本内容是否包含给定的选择器
- box = await element.boundingBox() # 获取元素的位置和大小
- coordinates = {
- 'x': box['x'], # 元素的 x 坐标
- 'y': box['y'], # 元素的 y 坐标
- 'width': box['width'], # 元素的宽度
- 'height': box['height'] # 元素的高度
- }
- await element.click() # 点击元素
四、读取excel表数据并使用
- def open_xlsx():
- from openpyxl import load_workbook
-
- wb = load_workbook("111.xlsx")
- ws = wb["Sheet1"]
- data = []
- for row in ws.iter_rows(min_row=2): #从第二行开始算
- row_values = []
- for cell in row:
- row_values.append(cell.value)
- data.append(row_values)
- wb.close()
-
- return data
-
- data = open_xlsx()
-
- #这里的user_list取出来的是表中每一行的数据,下面的0-1-2-3是每一列的数据
- for user_list in data:
- print(user_list[0])
-
-
-
说明
- def open_xlsx():
- from openpyxl import load_workbook
-
- # 打开 Excel 文件
- wb = load_workbook("111.xlsx")
-
- # 选择要读取的工作表
- ws = wb["Sheet1"]
-
- # 创建一个空的列表用于存储读取的数据
- data = []
-
- # 从第二行开始遍历每一行
- for row in ws.iter_rows(min_row=2):
- row_values = []
-
- # 遍历当前行的每一个单元格
- for cell in row:
- # 将单元格的值添加到行值列表中
- row_values.append(cell.value)
-
- # 将该行的值列表添加到数据列表中
- data.append(row_values)
-
- # 关闭 Excel 文件
- wb.close()
-
- # 返回读取的数据
- return data
-
-
- # 调用 open_xlsx 函数并获取数据
- data = open_xlsx()
-
- # 遍历数据列表的每一行,并打印出每行的第一列数据
- for user_list in data:
- print(user_list[0])
隔壁有个写的不错的收藏下
https://blog.csdn.net/qq_27648991/article/details/105329455?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EOPENSEARCH%7ERate-1-105329455-blog-132301111.235%5Ev38%5Epc_relevant_anti_t3&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EOPENSEARCH%7ERate-1-105329455-blog-132301111.235%5Ev38%5Epc_relevant_anti_t3&utm_relevant_index=1
