
- 1【linux基础(七)】Linux中的开发工具(下)--make/makefile和git_make linux
- 2使用element颜色选择器修改布局头部和导航栏颜色_element怎么调节导肮颜色
- 3keytool生成私钥、公钥、证书详解_keytool -genkeypair 生成密钥 长度限制
- 4React antd upload组件上传视频并实现视频预览_antd文件上传怎么预览mp4文件
- 5PyTorch张量
- 6网站安全维护之逻辑漏洞、越权漏洞的修复与加固服务_逻辑漏洞修复方法有哪些
- 7华为荣耀20和x10比较_荣耀V40:一个好消息,一个坏消息
- 8荣耀30pro系统_荣耀30pro和pro+的区别_荣耀30pro和pro+的区别对比详情 - 系统家园
- 9mysql JDBC的三种查询(普通、流式、游标)_流式查询
- 1028个炫酷的纯CSS特效动画示例(含源代码)_css图片特效大全
不要停止预训练实战(二)-一日看尽MLM_n-gram masking
赞
踩
欢迎大家访问个人博客: https://jmxgodlz.xyz
前言
本文在上文不要停止预训练实战-Roberta与Albert的基础上,进一步完成以下内容:
- keras预训练
- N-gram掩码任务
- Span掩码任务
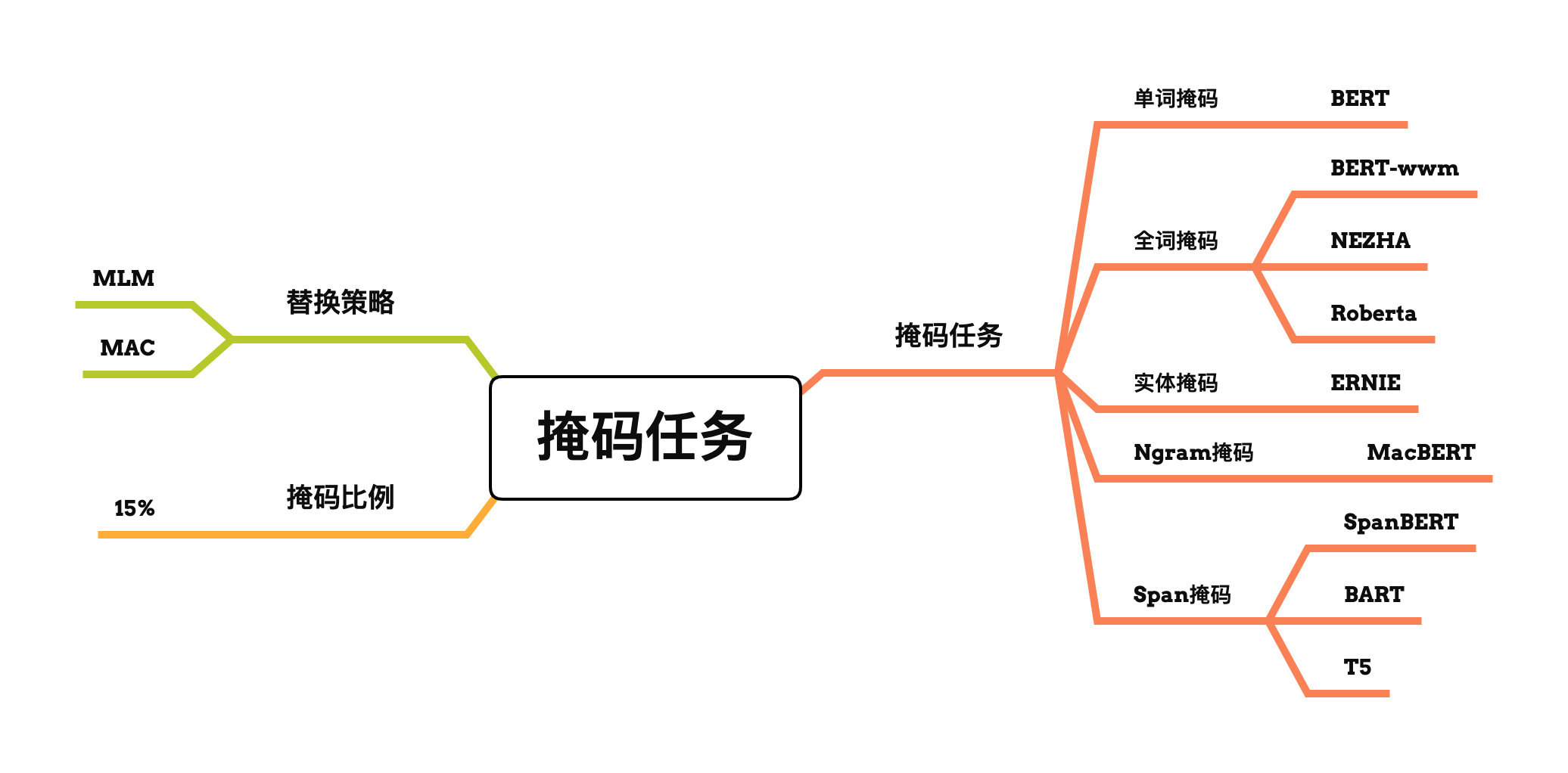
掩码任务
BERT等预训练模型中掩码任务主要涉及下列要素:
- 掩码比例
- 替换策略
- 掩码方式
掩码比例
常用掩码比例设置为15%,该比例经过许多研究,已证明该比例能够取得很好的效果。
从理论上来说,笔者从网上找到的说法为:“当取15%时,恰好大概7个词mask一个,正好就是CBOW中,长度为7的滑动窗口的中心词,因此会有比较好的效果”
而近日丹琦大佬等人的论文Should You Mask 15% in Masked Language Modeling?表明掩码40%能够取得与15%差不多的效果。
该论文表明**“所谓的optimal masking rate并不是一个一成不变的神奇数字,而是一个随着模型大小、mask策略、训练recipe、下游任务变化的函数。”**
替换策略
常用的替换策略如下:
- 80%词语替换为[MASK]
- 10%词语保持不变
- 10%词语随机替换为其他词语
这样做的目的在于强迫模型学习词语上下文的语义信息。任何一个词语都有可能被替换,不仅靠当前词语,还需要利用上下文的信息预测当前词语。
但是[MASK]标签并未出现在下游任务中,因此存在预训练与微调的不一致问题。
MacBERT提出MLM as correction的方法,替换策略如下:
- 80%词语替换为同义词
- 10%词语保持不变
- 10%词语随机替换为其他词语
MacBERT论文中与下列替换策略进行对比,对比结果如图所示:
- MacBERT:80%替换为同义词,10%替换为随机词语,10%保持不变;
- Random Replace:90%替换为随机词语,10%保持不变;
- Partial Mask:同原生的BERT一样,80%替换为[MASK],10%替换为随机词语,10%保持不变;
- ALL Mask:90%替换为[MASK],10%保持不变。
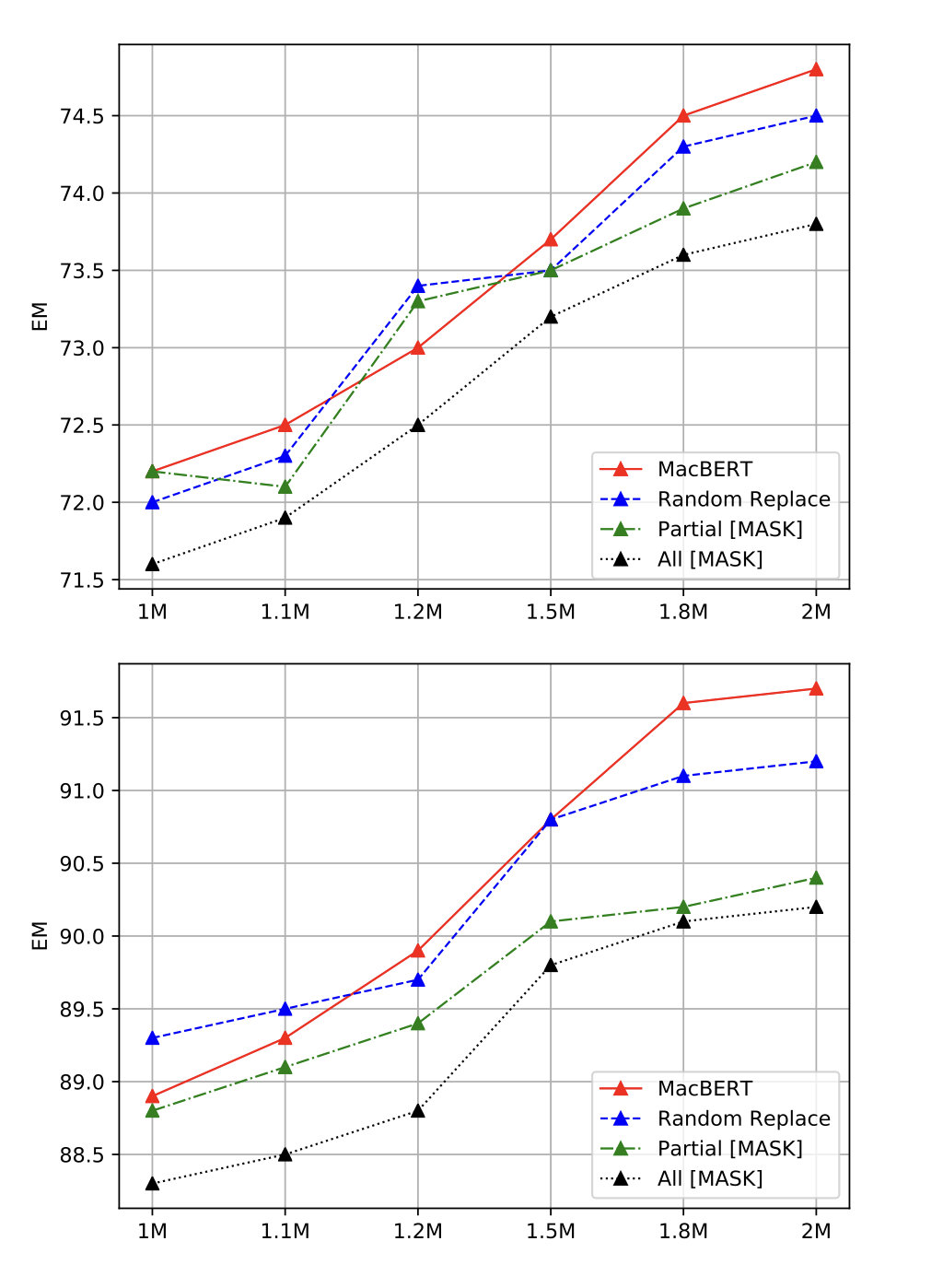
图中横坐标代表训练步数,纵坐标代表EM值。第一幅图是CMRC数据集结果,第二幅图是DRCD数据集结果。
掩码方式
目前的掩码方式主要分为以下几种:
- 单词掩码
- 全词掩码
- 实体掩码
- N-gram掩码
- Span掩码
| 中文 | 英文 | |
|---|---|---|
| 原句 | 使用语言模型来预测下一个词的概率。 | we use a language model to predict the probability of the next word. |
| 分词 | 使用 语言 模型 来 预测 下 一个 词 的 概率 。 | - |
| BERT Tokenizer | 使 用 语 言 模 型 来 预 测 下 一 个 词 的 概 率 。 | we use a language model to pre ##di ##ct the pro ##ba ##bility of the next word. |
| 单词掩码 | 使 用 语 言 [M] 型 来 [M] 测 下 一 个 词 的 概 率 。 | we use a language [M] to [M] ##di ##ct the pro [M] ##bility of the next word. |
| 全词掩码 | 使 用 语 言 [M] [M] 来 [M] [M] 下 一 个 词 的 概 率 。 | we use a language [M] to [M] [M] [M] the [M] [M] [M] of the next word. |
| 实体掩码 | 使 用 [M] [M] [M] [M] 来 [M] [M] 下 一 个 词 的 概 率 。 | we use a [M] [M] to [M] [M] [M] the [M] [M] [M] of the next word. |
| N-gram掩码 | 使 用 [M] [M] [M] [M] 来 [M] [M] 下 一 个 词 的 概 率 。 | we use a [M] [M] to [M] [M] [M] the [M] [M] [M] [M] [M] next word. |
| Span掩码 | 使 用 [M] [M] [M] [M] [M] [M] [M] 下 一 个 词 的 概 率 。 | we use a [M] [M] [M] [M] [M] [M] the [M] [M] [M] [M] [M] next word. |
| MAC掩码 | 使 用 语 法 建 模 来 预 见 下 一 个 词 的 几 率 。 | we use a text system to ca ##lc ##ulate the po ##si ##bility of the next word. |
全词掩码
以分词结果为最小粒度,完成掩码任务。
N-gram掩码
同样以分词结果为最小粒度,以n-gram取词语进行掩码。
例如MacBERT采用基于分词的n-gram masking,1-gram~4gram Masking的概率分别是40%、30%、20%、10%。
实体掩码
代表模型为:ERNIE
引入命名实体信息,将实体作为最小粒度,进行掩码。
Span掩码
代表模型为:SpanBERT
以上做法让人认为,或许必须得引入类似词边界信息才能帮助训练。但前不久的 MASS 模型,却表明可能并不需要,随机遮盖可能效果也很好,于是就有SpanBERT的 idea:
根据几何分布,先随机选择一段(span)的长度,之后再根据均匀分布随机选择这一段的起始位置,最后按照长度遮盖。文中使用几何分布取 p=0.2,最大长度只能是 10,利用此方案获得平均采样长度分布。
代码实现
相关代码实现可见:https://github.com/447428054/Pretrain/tree/master/KerasExample/pretraining
Span掩码核心代码如下:
def __init__( self, tokenizer, word_segment, lower=1, upper=10, p=0.3, mask_rate=0.15, sequence_length=512 ): """参数说明: tokenizer必须是bert4keras自带的tokenizer类; word_segment是任意分词函数。 """ super(TrainingDatasetRoBERTa, self).__init__(tokenizer, sequence_length) self.word_segment = word_segment self.mask_rate = mask_rate self.lower = lower self.upper = upper self.p = p self.lens = list(range(self.lower, self.upper + 1)) self.len_distrib = [self.p * (1-self.p)**(i - self.lower) for i in range(self.lower, self.upper + 1)] if self.p >= 0 else None self.len_distrib = [x / (sum(self.len_distrib)) for x in self.len_distrib] print(self.len_distrib, self.lens) def sentence_process(self, text): """单个文本的处理函数 流程:分词,然后转id,按照mask_rate构建全词mask的序列 来指定哪些token是否要被mask """ word_tokens = self.tokenizer.tokenize(text=text)[1:-1] word_token_ids = self.tokenizer.tokens_to_ids(word_tokens) sent_length = len(word_tokens) mask_num = math.ceil(sent_length * self.mask_rate) mask = set() spans = [] while len(mask) < mask_num: span_len = np.random.choice(self.lens, p=self.len_distrib) # 随机选择span长度 anchor = np.random.choice(sent_length) if anchor in mask: # 随机生成起点 continue left1 = anchor spans.append([left1, left1]) right1 = min(anchor + span_len, sent_length) for i in range(left1, right1): if len(mask) >= mask_num: break mask.add(i) spans[-1][-1] = i spans = merge_intervals(spans) word_mask_ids = [0] * len(word_tokens) for (st, ed) in spans: for idx in range(st, ed + 1): wid = word_token_ids[idx] word_mask_ids[idx] = self.token_process(wid) + 1 return [word_token_ids, word_mask_ids]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57

