
- 1布隆过滤器详解及java代码实现_java实现布隆过滤器
- 2轻量化网络总结[1]--SqueezeNet,Xception,MobileNetv1~v3_bottleneck结构的改进
- 3oracle中app文件夹下,Oracle Form开发之folder(文件夹)功能开发(一)
- 4如何利用IDEA将Git分支代码回退到指定历史版本_idea回滚到指定版本
- 5实战项目-微信购物商城小程序+【源码+数据库+文档】_微信小程序开发 商城数据库设计
- 6快速提高编码生产力——中国用户如何使用Jetbrains内置的AI助手_jetbrains ai
- 7收藏!这 50 道操作系统面试题,真牛!
- 8决策树理论_分析客户性别与购物偏好的关系数据挖掘
- 9pytorch学习笔记(八):softmax回归的从零开始实现_train_iter,test_iter=d2l.load_data_fashion_mnist(b
- 10springboot2.0如何使用PowerMockito模拟java方法中的new对象_powermockito模拟接口对象
【2019.05】NTLK安装与基本使用方法_ntlk下载
赞
踩
NLP(Natural language processing,自然语言处理)是一门涵盖语言学、计算机科学、人工智慧等多个领域的科学,研究人与计算机之间用自然语言进行有效通信的理论方法,简单来说,NLP 就是开发能够理解人类语言的应用程序或服务。自然语言处理是很大的一门范畴和学问,这里讨论一些自然语言处理的例子,如分词、分句、词性划分、理解匹配词的同义词,当然,这并不是 NLP 能做的所有事情,笔者并不是想让读者进行非常高深学问的学习,读者只需要掌握我们用到的可能性较大的方法。
NLTK(Natural Language Toolkit,自然语言工具包)在用 Python 处理自然语言的工具中处于领先的地位,同时,它基于 Python 构建。它提供了 WordNet 这种方便处理词汇资源的接口(拥有超过 50 个语料库和词汇资源),还有分类、分词、除茎、标注、语法分析、语义推理等类库,最让人惊喜的一点是,它基于 Apache2.0 开源协议免费发放。NLTK 是一个第三方包,你需要通过 pip 或者其他的包管理器更或是源码进行安装,但仅仅是安装 NLTK 库,那么它的大部分方法你都无法使用。NLTK 库中,自带一个函数download(),会打开一个类似于下图的界面。
- 安装
pip install nltk
import nltk
nltk.download()
- 1
- 2
使用该命令可以打开这样一个界面,用来下载‘包’
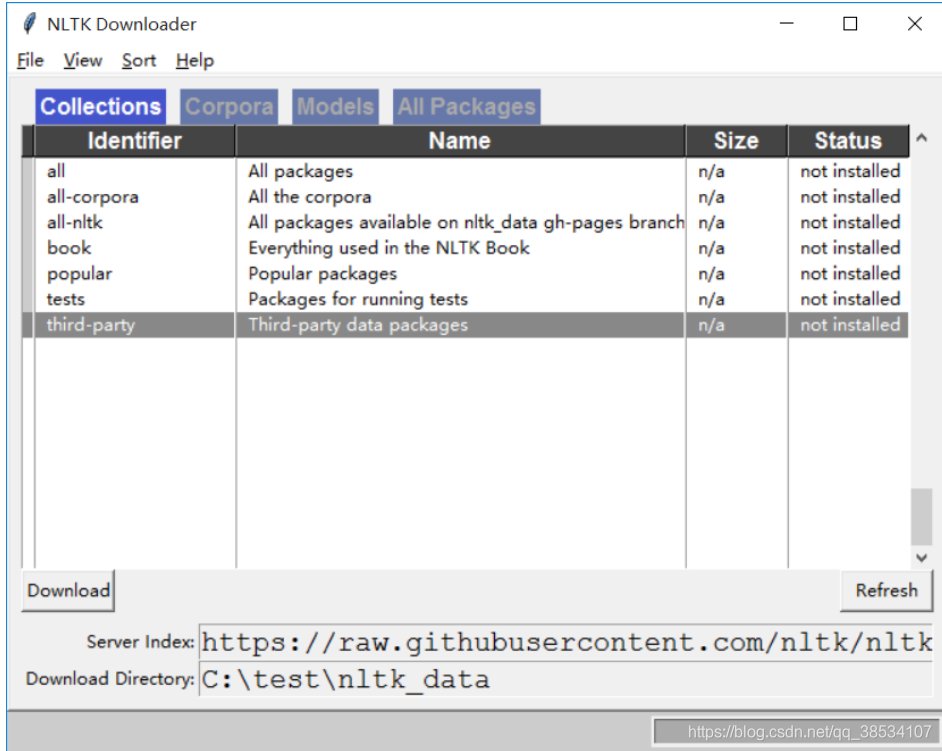
你也可以使用以下命令直接下载
nltk.download('[包名]')
- 1
下载完成之后,你需要将下载的内容存放在这些位置之一。
- ‘C:\Users\xxxxx/nltk_data’
- ‘C:\nltk_data’
- ‘D:\nltk_data’
- ‘D:\nltk_data’
#后三个盘符、目录随着你的 Python 安装目录而改变 - ‘F:\Python\nltk_data’
- ‘F:\Python\share\nltk_data’
- ‘F:\Python\lib\nltk_data’
- ‘C:\Users\xuyichenmo\AppData\Roaming\nltk_data’
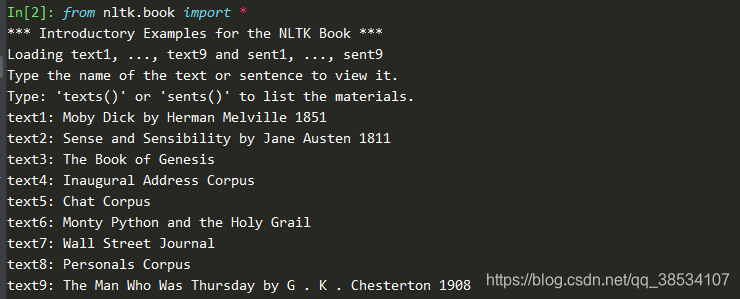
当你很自信的认为已经整理好 nltk_data,并且能够正常使用,那么你可以使用这个命令来确认
from nltk.book import *
- 1
返回结果:
文本统计
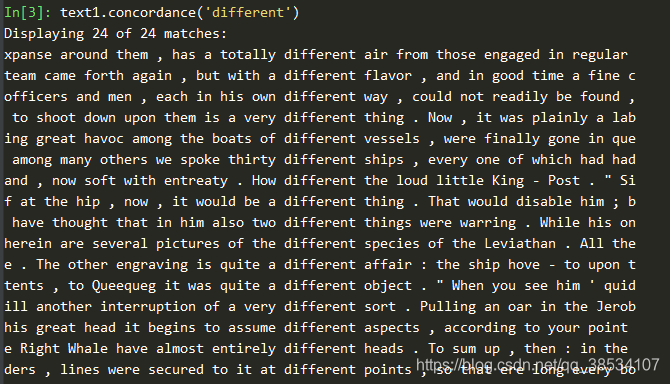
- 首先我们来看一个命令:
text1.concordance('different')
- 1
这句话实现的是从这一大串字符串中找寻出包含 different 这个单词的语句,返回的结果如下:
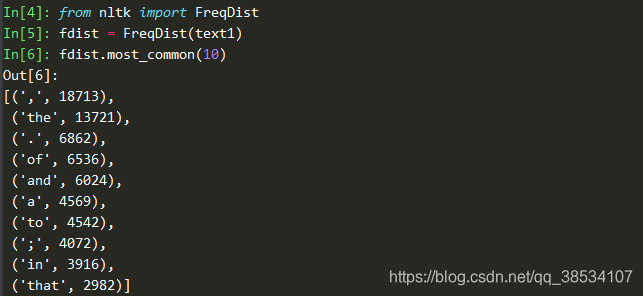
- 统计标点符号和单词的出现频率,这个命令可以说是在我们进行数据处理的时候相当常用了
from nltk import FreqDist
fdist=FreqDist(text1)
fdist.most_common(10)
- 1
- 2
- 3
fdist.plot(10)
- 1
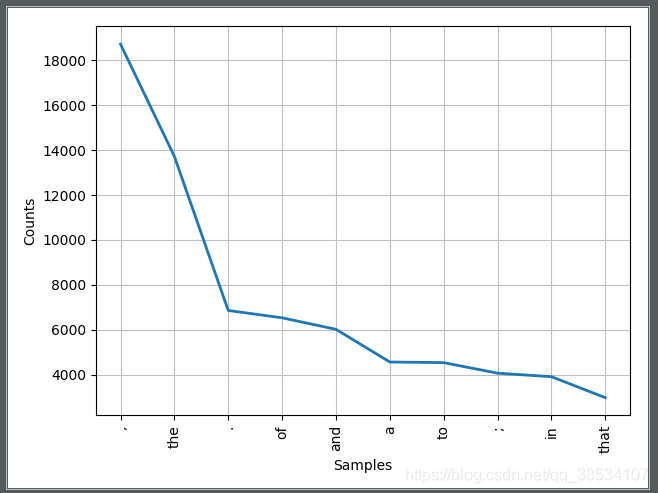
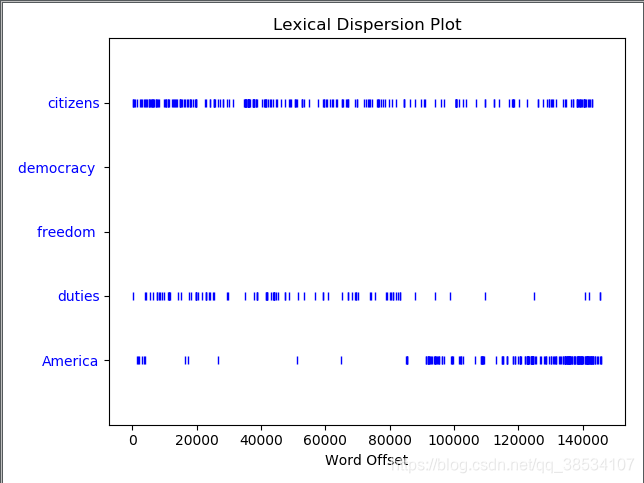
- 另外,如果你使用这个命令,可以查看这些单词在文本中分布位置,x 轴代表全部文本,每一个蓝色的短纵列都代表一次出现
text4.dispersion_plot(['citizens','democracy ', 'freedom ', 'duties', 'America'])
- 1
分析方法
除了简单的文本统计,NLTK 库还为我们提供了许多的分析方法
- 这个函数会给我们两个单词具有的相同上下文单词,给定的两个参数你必须首先用中括号括起来,然后再用小括号括起来。
text2.common_contexts(["monstrous", "very"])
- 1

- 还有一个功能很相像的函数:
text1.similar("different")
- 1
在这里插入图片描述
text1.similar([文字]),可以告诉我们和我们指定的字符具有相同作用(并不是它们的语义相同)的单词,比如说,我们经常使用 beautiful 来形容 girl,那么这个函数可能就会给我们返回 handsome(同样用来形容 girl)
- NLTK 库还有一个命令用于分句:
sent_tokenize(text)
- 1
可能 1 会疑问如果是很规范的文本,我们直接根据标点符号进行断句就可以了,为什么还要使用这个命令呢?
那么像"Hi Mr. Liu, how are you? Blessing for you"这种呢,称谓之间的标点符号很明显你是不可以把它单独分割成一个句子的,这时候 NLTK 库的分句用法就会展现出它的强大。


