
- 1数据结构与算法名词解析总结_输入字符a至f,按输入字符的顺序建立一个字符结点(每个结点存储一个字符)的单向链
- 2弦图:图上求解多种复杂问题的简单情况_nflsoj npc问题 弦图
- 3急!很茫然,我是女生,本科美术系学艺术设计的今年7月份就毕业,软件专业也没学好,毕业之后不打算去公司里工作因为太勾心斗角太累了!现在天天都不开心我该怎么办怎么打算呢,有哪个好心人能给我讲解讲解!
- 4探秘机器学习核心逻辑:梯度下降的迭代过程 (图文详解)_梯度下降迭代
- 502_I.MX6ULL汇编LED驱动实验
- 6springboot+vue租房网站(源码+文档)_官网项目源码 vue+springboot
- 7大厂高频面试题复习JAVA学习笔记-JVM+GC解析
- 8腾讯云轻量服务器和云服务器区别12点不同之处_腾讯 轻量服务器 区别
- 9NLP任务中的文本预处理步骤、工具和示例_nlp如何处理btb文件
- 10Flink流计算之聚合函数_flink聚合函数
论文学习笔记——RAM_combining events and frames using recurrent asynch
赞
踩
Combining Events and Frames Using Recurrent Asynchronous Multimodal Networks for Monocular Depth Prediction
event camera:
- 将每像素的亮度变化作为一系列异步“事件”进行报告
- 高时间分辨率、高动态范围和缺乏运动模糊
本文提出RAM网络实现传统相机和事件相机的单目深度估计。传统相机对静止场景捕捉更加完全(低频完整)、事件相机只编码视觉信号的变化部分(高频稀疏),所以作者设计的Recurrent Asynchronous Multimodal (RAM) network兼顾了两者特性,最终功能得到了连续的、稠密的单目深度图。
RAM:
- 考虑异步性、事件和帧的无规律性
- 将多个传感器的时间信息结合起来

Recurrent Asynchronous Multimodal Networks
我们希望融合来自N个传感器的数据,这些传感器以稳定增加的时间戳
t
j
t_j
tj提供测量。在每个时间戳
t
j
t_j
tj时,传感器
k
j
k_j
kj
∈
\in
∈{1,2,…,N}提供的测量为
x
k
j
(
t
j
)
x_{kj}(t_j)
xkj(tj),我们因此要将一系列的测量
{
x
k
j
(
t
j
)
}
j
=
1
T
\{x_{kj}(t_j)\}_{j=1}^T
{xkj(tj)}j=1T融合起来。
- 每个时刻每个传感器的测量进行编码:
s k j s_{k_j} skj= E k j ( x k j , θ k j ) E_{k_j}(x_{k_j},\theta_{k_j}) Ekj(xkj,θkj)
因为不同传感器提供的测量有不同的形式,因此首先通过对传感器的编码器 E k j E_{k_j} Ekj,将这一系列的测量映射到一系列中间特征 s k j s_{k_j} skj(green)。
其中 θ \theta θ是RAM网络的参数。
本文在编码器的不同scale中提取中间特征。
提取到的中间特征 s k j s_{k_j} skj有以下性质:①从不同传感器提取到的特征可能以任何顺序出现在序列中(异步);②特征之间的时间间隔随时间会发生变化(data rates会变化)。
- 将j时刻得到的测量与j-1时刻的变量进行融合:
Σ j = h k j ( Σ j − 1 , s k j , θ ) \Sigma_j=h_{k_j}(\Sigma_{j-1},s_{k_j},\theta) Σj=hkj(Σj−1,skj,θ)
为保证正确融合特征,将传感器 k j k_j kj得到的特征 s k j s_{k_j} skj通过传感器特定状态组合器 h k j h_{k_j} hkj,更新 t j − 1 t_{j-1} tj−1时刻的潜在的变量 Σ j − 1 \Sigma_{j-1} Σj−1。
使用convGRU来将状态结合起来。
在每个传感器的每个scale都有。
更新方程:
f、g : 单个卷积+sigmoid ; ϕ \phi ϕ : 卷积+tanh
从不同传感器中首先映射到合适的空间以便于和 ∑ j \sum_j ∑j进行融合,之后状态组合器被顺序地应用,当某个传感器的测量可得的时候进行改变。
因此可以产生一系列 { Σ j } j = 1 T \{\Sigma_j\}_{j=1}^T {Σj}j=1T

- 在每个时间点
t
j
t_j
tj时将
Σ
j
Σ_j
Σj通过解码器
Γ
\Gamma
Γ解码,得到
y
j
y_j
yj
y j = Γ ( Σ j , θ ) y_j = \Gamma (Σ_j, θ) yj=Γ(Σj,θ)
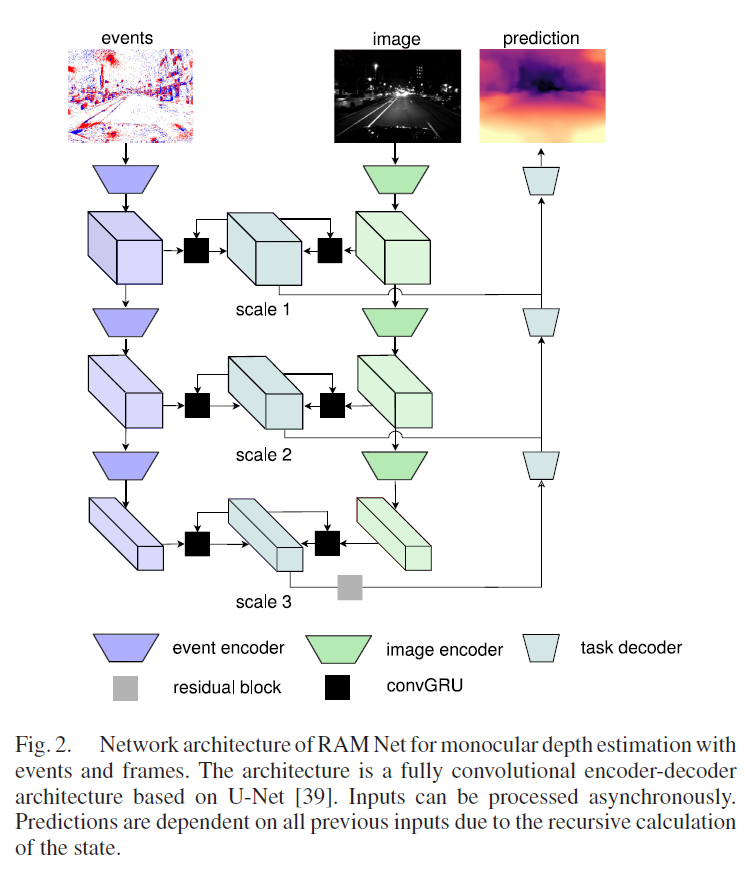
Network Architecture for Monocular Depth Estimation
- 在每个scale上,使用skip connection作为中间特征 s k j s_{k_j} skj
- 通过ConvGRU层将 s k j s_{k_j} skj与 Σ j − 1 \Sigma_{j-1} Σj−1结合得到 Σ j \Sigma_{j} Σj
- lowest scale的 Σ j \Sigma_{j} Σj直接通过残差块(grey),之后通过3个decoder
- 注意decoder层的input,因为skip connection
- 每个encoder包括一个下采样的卷积:kernel size=5, stride=2
- 残差块由2个卷积层组成:kernel size=3
- decoder使用双线性插值(bilinear)上采样,之后通过kernel size=5的卷积层
- 所有层后都跟随ReLU激活函数
Event Generation Model
Event相机包括独立的像素u,这个像素对log brightness signal L(u, t)作出反应。如果和上一个event相比,log brightness的变化超过阈值C,在像素点 u = ( x k , y k ) T u=(x_k, y_k)^T u=(xk,yk)T一个新的event e k = ( x k , y k , t k , p k ) e_k = (x_k, y_k, t_k, p_k) ek=(xk,yk,tk,pk)会被触发。其中 p k ∈ { − 1 , + 1 } p_k \in \{−1, +1\} pk∈{−1,+1}, 具体取值决定于亮度变化的方向。故一个polarity为 p k p_k pk的事件在像素点 u k u_k uk,时间 t k t_k tk被触发 ⟺ \iff ⟺ Δ L ( u k , t k ) = p k ( L ( u k , t k ) − L ( u k , t k − Δ t k ) ) ≥ C ΔL(u_k, t_k) = p_k (L(u_k, t_k) − L(u_k, t_k − Δt_k)) ≥ C ΔL(uk,tk)=pk(L(uk,tk)−L(uk,tk−Δtk))≥C
Event Representation
events被转换为固定大小的tenser。
在时间
Δ
T
=
t
N
−
1
−
t
0
ΔT =t_{N−1} − t_0
ΔT=tN−1−t0中的输入events
ε
=
{
e
i
}
i
=
0
N
−
1
\varepsilon =\{e_i\}_{i=0}^{N-1}
ε={ei}i=0N−1 被转换为voxel grid: dimensions:H × W,以及B个temporal bins(给定固定数量的 bin B,原始事件序列被分成 B 个连续的窗口
![]()
![]()
实验中设置B=5
Depth Representation
- 将深度矩阵 D ^ m , k \hat{D}_{m,k} D^m,k转换到归一化的log depth map D ^ k \hat{D}_{k} D^k
- log depth计算:
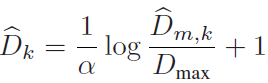
EventScape: α \alpha α=5.7, D m a x D_{max} Dmax=1000 m
MVSEC: α \alpha α=3.7, D m a x D_{max} Dmax=80 m
Training
- 全监督
- 损失函数:结合scale-invariant loss和multi-scale scale-invariant
gradient matching loss
(1)scale-invariant loss:
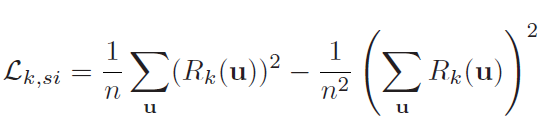
其中n是有有效ground truth的像素点的个数
(2)multi-scale scale-invariant gradient matching loss:
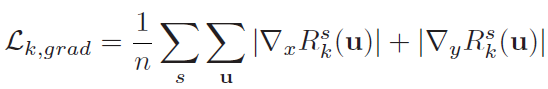
s表示scale
(3)对序列长度为L的总损失:
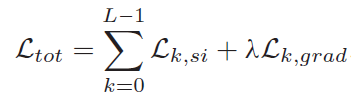
λ \lambda λ=0.25。 - 输入数据归一化,并随机裁剪为224*224,并进行随机水平翻转
- voxel grid中的非零条目归一化

