
- 1pg库删除数据释放表空间_pg删除数据后如何释放空间
- 2【ARM Linux 系统稳定性分析入门及渐进 13 -- gdb 反汇编 disassemble 命令详细介绍及举例】_gdb disassemble指令
- 3Android 之 三个绘图工具类详解_android 绘图
- 4android canvas 点击事件,android Canvas 画板 和 OnTouch 事件
- 5基于ChatGLM的微调实现_chatglm 微调
- 6vue 公众号h5分享功能 监听微信右上角..._vue3 公众号 微信引导用户右上角使用打开浏览器页面
- 7Gradle打jar包如何上传到maven本地库_将gradle缓存的jar包转移到maven本地仓库
- 8东南大学计算机考研信息汇总_东南大学计算机研究生
- 9对Java中各种锁的理解及死锁排查_java reentrantlock 排查死锁
- 10C#把内存里的utf8字符串转成C#内部使用的Unicode_c# 调用c语言库 utf8
论文阅读【自然语言处理-预训练模型3】XLM-R:Unsupervised cross-lingual representation learning at scale
赞
踩
Unsupervised cross-lingual representation learning at scale(ACL 2019)
【论文链接】:https://aclanthology.org/2020.acl-main.747.pdf
【代码链接】:https://github.com/facebookresearch/XLM
【来源】:由Facebook AI Research团队发表在ICLR 2019上的论文。
- 在XLM的基础上进⼀步分析了影响多语⾔预训练模型效果的因素,提出在100多种语⾔上预训练得到的XLM-R模型。下⾯列举了本⽂中的核⼼实验结论,揭示了不同的多语⾔训练⽅式对效果的影响。
- 图2显示了随着预训练过程引⼊语⾔种类的变化,low resource语⾔的效果先上升后下降。这是因为在模型capacity⼀定的情况下,引⼊多种语⾔⼀⽅⾯会让low resource语⾔获得可迁移的知识,另⼀⽅⾯过多的语⾔也稀释了模型的capacity,每种语⾔能够使⽤的capacity减少,导致效果下降。⽽high resource语⾔的效果随着引⼊语⾔数量的增加是持续下降的。图4显示,增加模型尺⼨可以缓解多语⾔稀释capacity的问题(7种语⾔和30种语⾔效果对⽐),但是引⼊100种语⾔后即使增加模型尺⼨效果仍然不佳。
- 图5展示了不同语⾔采样权重变化的效果影响,low resource和high resource语⾔之间存在⼀定的⽭盾性,因此随着采样偏向于high resource语⾔,low resource语⾔的效果越来越差。图6则展示了词典尺⼨⼤⼩对效果的影响,词典尺⼨增⼤,对应embedding层尺⼨增加,可以⽐较明显的提升多语⾔预训练模型效果
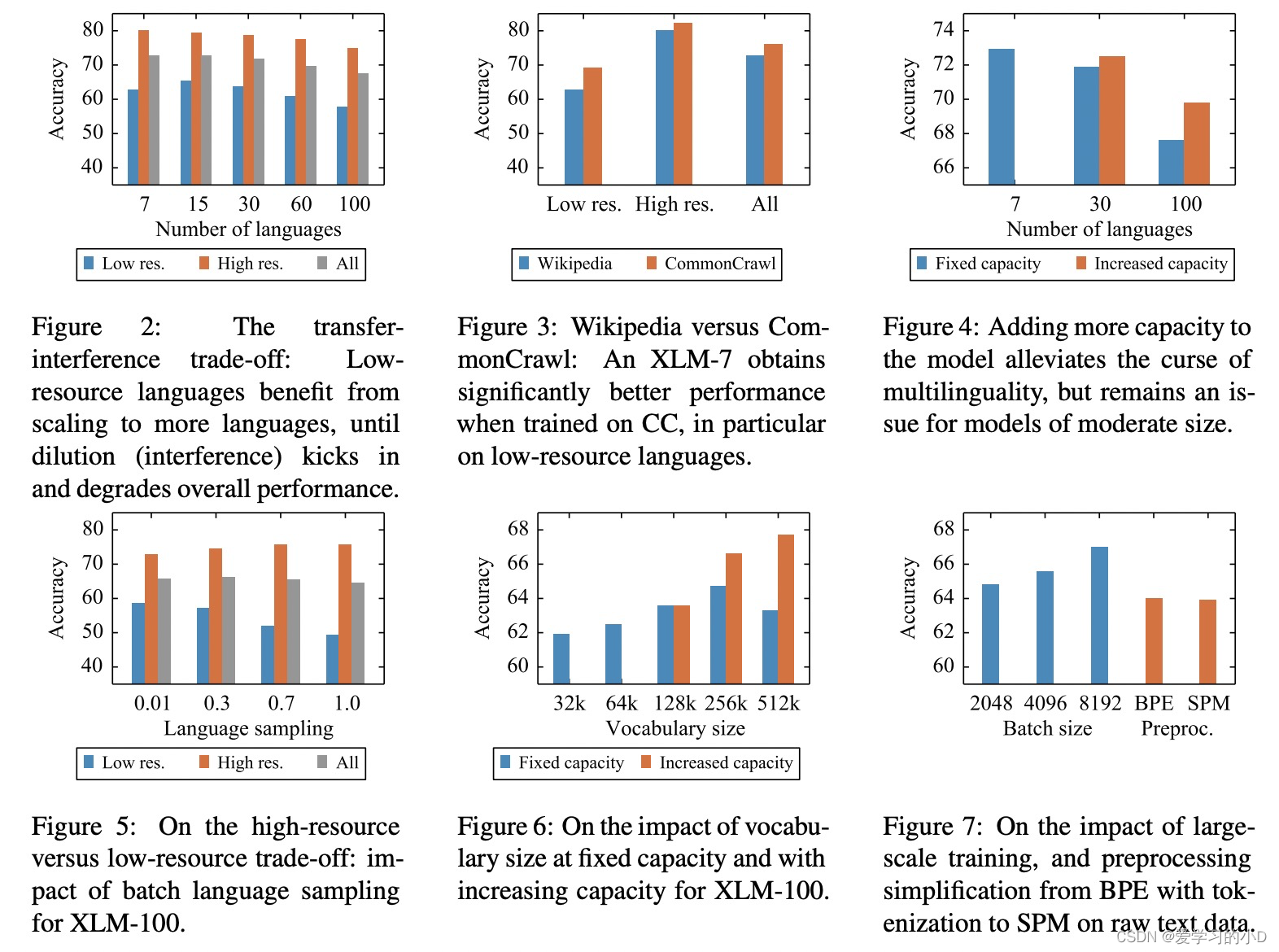
- 基于以上这些实验的分析,作者提出了基于RoBerta的XLM-R,在100余种语⾔、2.5T的数据上预训练,取得了在XNLI数据集上相⽐基础版XLM模型15%的效果提升。相⽐于XLM,XLM-R最⼤的区别之⼀是没有使⽤TLM这个预训练任务,所有预训练数据都是单语⾔的,不包括两个语⾔对⻬的数据。
名词解析
Adversarial training
解析
Adversarial Training (对抗训练) 是一种训练神经网络的方法,旨在提高模型的鲁棒性,使其能够在输入数据被添加扰动的情况下仍然能够正确地分类。该方法通过在训练期间向输入数据中添加对抗性扰动来实现。
- 具体而言,对于每个训练样本,Adversarial Training 都会生成一个与原始样本相似但略有不同的“对抗样本”,并将其与原始样本一起用于训练。这个“对抗样本”被构造为在最大化损失函数的同时最小化扰动,以使模型更难以被误导。换句话说,Adversarial Training 让模型在输入数据上学习更为鲁棒的特征,以对抗可能存在的对抗性攻击。
- Adversarial Training 方法的优点是能够提高模型的鲁棒性,使其能够在输入数据被添加扰动的情况下仍然能够正确地分类,从而增加了模型的实用性和安全性。然而,该方法的缺点是训练成本较高,需要更长时间的训练和更大的训练数据集。此外,Adversarial Training 也可能导致模型在原始数据上的准确率降低,因此需要在实际应用中进行权衡和优化。
应用
Adversarial Training已经被应用到很多领域中,下面列举几个常见的应用:
- 图像分类:Adversarial Training可以提高图像分类模型的鲁棒性,减少模型对于对抗性样本的敏感性,从而提高模型的泛化能力。
- 语言模型:Adversarial Training可以用于生成对抗性样本来提高语言模型的鲁棒性和泛化能力。
- 目标检测:Adversarial Training可以应用于提高目标检测模型对于对抗性样本的鲁棒性和检测能力,从而提高模型的鲁棒性和泛化能力。
- 生成对抗网络:Adversarial Training是生成对抗网络(GAN)中的一种核心训练方法,可以用于训练生成器和判别器,提高生成模型的生成能力和判别模型的鲁棒性。
- 强化学习:Adversarial Training可以用于提高强化学习模型的鲁棒性和泛化能力,使得模型更好地应对未知的环境变化和对抗性干扰。
优劣势
Adversarial Training的优势包括:
- 提高了模型的鲁棒性:通过训练具有对抗性的样本,模型能够更好地抵御对抗攻击,提高鲁棒性。
- 增加了数据的多样性:通过生成对抗性的样本,可以增加训练数据的多样性,从而提高模型的泛化能力。
- 适用于各种深度学习模型:Adversarial Training可以应用于各种深度学习模型,包括卷积神经网络、循环神经网络等。
Adversarial Training的劣势包括:
- 训练时间长:Adversarial Training需要生成对抗样本并重新训练模型,这会导致训练时间增加。
- 对抗攻击的样本数量有限:对抗攻击需要大量计算和数据支持,因此生成对抗性样本的数量是有限的。
- 可能会导致性能下降:Adversarial Training可能会导致模型性能下降,因为它强制要求模型将对抗样本作为常规样本进行训练,可能会使模型过度拟合对抗样本而导致性能下降。
Robert模型
Robert模型,全称Robustly Optimized BERT Pretraining Approach,是一种基于BERT模型的改进,旨在提高预训练模型的鲁棒性和泛化能力。与BERT模型类似,Robert模型也采用了Transformer模型结构,并在大规模语料库上进行预训练,然后在各种下游自然语言处理任务中进行微调。与BERT模型相比,Robert模型的主要改进点在于以下三个方面:
- 对抗性训练(Adversarial Training):在预训练阶段引入对抗性训练,使模型更加鲁棒,能够处理更加复杂的输入。
- 动态掩码(Dynamic Masking):动态地选择掩码位置,可以在预训练阶段充分利用语料库中的信息,从而提高模型的泛化能力。
- 前馈网络参数初始化(Parameter Initialization):采用较小的初始化范围初始化前馈网络的参数,可以使训练更加稳定,加快收敛速度。
Robert模型已经在各种NLP任务中取得了优秀的性能表现,并在不同语言和不同领域的数据集上进行了广泛的测试和验证。
论文解析
《Unsupervised Cross-lingual Representation Learning at Scale》是一篇由Facebook AI团队在2019年ACL会议上发表的论文,介绍了一种用于跨语言表示学习的新模型:XLM-R。该模型通过大规模的无监督多语言数据预训练,使得它可以在多种自然语言处理任务上达到最先进的效果,包括翻译、问答、文本分类等。
XLM-R模型的主要贡献
XLM-R模型主要的贡献可以总结如下:
- 在多种语言上实现了卓越的性能:XLM-R在近百种语言上进行了实验,取得了语言模型、句子分类、命名实体识别等任务上最先进的表现。
- 引入更强的自监督任务:XLM-R引入了两个新的自监督任务,其中一个是实体识别任务,另一个是Masked Span Prediction任务,这两个任务有助于提高模型在词汇丰富度和语义理解方面的能力。
- 引入更多的数据:XLM-R利用了超过2.5TB的跨语言语料库,相比于之前的模型使用的数据量有了显著的提升。
- 使用大规模的多语言预训练技术:XLM-R使用了更加高效的多语言训练策略,可以同时训练超过100种语言的语言模型。
综上所述,XLM-R的主要贡献是提出了一种高效、可扩展的跨语言表示学习方法,可以有效地处理来自不同语言的自然语言处理任务。
论文的主要思想
- 《Unsupervised Cross-lingual Representation Learning at Scale》这篇论文的主要思想是通过在大规模跨语言文本数据上进行无监督训练,学习到通用的跨语言文本表示。这种通用表示可以用于多种自然语言处理任务,如语言理解、语言生成等,从而使得我们可以更容易地将自然语言处理技术应用于跨语言场景。
- 为了实现这个目标,作者提出了一种名为XLM-R的模型,它是一种基于Transformer架构的跨语言语言模型。XLM-R利用了大量的跨语言数据,包括Wikipedia、Common Crawl等多种来源的数据,通过多任务学习的方式来训练模型,其中包括了语言模型预训练、跨语言翻译等多个任务。
- 在训练过程中,XLM-R模型采用了一种双向的训练方式,即同时对源语言和目标语言进行训练,使得模型可以学习到更加通用的跨语言表示。此外,XLM-R还采用了一种新的数据增强策略,即对输入的句子进行随机替换、随机交换、随机删除等操作,以增加训练数据的多样性。
- 最终,XLM-R模型在多项跨语言自然语言处理任务上取得了非常优秀的效果,证明了其学习到的跨语言表示的通用性和有效性。
论文的方法是什么?
Unsupervised Cross-lingual Representation Learning at Scale(XLM-R)是一个基于Transformer的跨语言预训练模型,主要分为两个部分:预训练和微调。:
- 预训练部分主要包括两个阶段:Masked Language Modeling(MLM)和Translation Language Modeling(TLM)。
- 在MLM阶段中,模型对输入的文本进行随机遮盖,并预测被遮盖的单词;
- 在TLM阶段中,模型输入一对平行语料(两种语言的翻译),并尝试通过最小化两种语言中的相应单词之间的距离来对其进行联合训练。
- 微调部分则根据具体的下游任务进行,比如情感分类、命名实体识别等。微调阶段的目标是在固定的预训练模型上,通过针对具体任务的微调来优化模型。
总的来说,该论文提出的XLM-R模型采用了一种跨语言表示学习的方法,可以在大规模跨语言文本语料库上进行无监督的训练,从而学习到高质量的跨语言表示,具有很强的泛化能力。
methodology是什么?
无监督跨语言表征规模学习(XLM-R)论文的方法包括以下步骤:
- 数据收集和预处理: 从各种语言中收集单语数据,并应用特定语言的预处理技术,如规范化和标记化。
- 语言模型的预训练: 在来自所有语言的预处理过的单语数据上训练一个掩蔽的语言模型。该模型的训练是为了根据周围的语境来预测被掩盖的标记。
- 多语言翻译预训练: 在来自不同语言对的平行数据上训练一个多语言翻译模型。该翻译模型被训练为在保持输入文本的语义的同时进行语言间的翻译。
- 无监督的跨语言语言模型预训练: 在来自所有语言的预处理的单语数据上训练一个跨语言的语言模型。该模型被训练成在任何一种支持的语言中预测被掩盖的标记,并给出其他任何一种支持的语言中的上下文。
- 评估和下游任务: 评估预训练的XLM-R模型在跨语言基准上的表现,并将其用于下游的自然语言处理任务,如情感分析、命名实体识别和机器翻译。
总的来说,XLM-R的方法包括在大量的单语和平行数据上进行预训练,然后在特定的下游任务上进行微调。关键的创新是使用无监督的预训练技术,即使在低资源环境下,也能实现跨语言的有效迁移学习。
创新点
- 数据集规模:该论文使用大规模多语言语料库进行预训练,覆盖了100多种语言的数据,训练集包含2,500亿个token,是当前规模最大的跨语言预训练模型之一。
- 训练策略:该论文使用两个训练策略来提高跨语言表示的质量。首先,使用单语语言建模和跨语言语言建模来预训练模型,这可以促进跨语言表示的学习。其次,采用动态掩码和语言过滤机制来调整训练数据,以确保模型在不同语言之间获得平衡的训练。
- 改进的跨语言表示:该论文提出了一种新的跨语言表示方法,称为“翻译语言模型”,可以将多语言语境映射到共享空间中。在这个共享空间中,同一语言的不同方言或不同语言之间的语义相似性可以得到更好的捕捉。
- 多语言下游任务表现:该论文在16个跨语言下游任务上评估了XLM-R模型,并与当前最先进的跨语言模型进行了比较,取得了最好的结果,证明了其优异的性能。
综上,XLM-R模型在数据集规模、训练策略、跨语言表示和跨语言下游任务表现等方面都有一定的创新点和优势。
应用
Unsupervised Cross-lingual Representation Learning at Scale(XLM-R)的主要应用是跨语言自然语言处理任务,如机器翻译、文本分类、命名实体识别等。由于该模型可以学习多语言之间的共享表示,因此可以在不同语言的任务之间进行迁移学习,减少了对标注数据的需求。另外,XLM-R也可以用于跨语言信息检索、跨语言信息聚合等应用场景。
局限性
- 语料库限制:XLM-R是在大规模语料库上进行训练的,但是并不是所有语言的大规模语料库都是可用的,因此可能需要使用较小的语料库来进行微调。
- 预训练阶段的资源消耗:XLM-R需要大量的计算资源来进行预训练,这限制了它的应用范围。此外,预训练阶段需要大量的内存,可能需要使用多个GPU来训练模型。
- 某些语言之间的跨度限制:XLM-R的词表是基于BPE(byte pair encoding)算法生成的,BPE是一种基于字节对的压缩算法,因此不能够处理所有语言之间的跨度。一些语言之间的相似度可能没有很好的捕捉到。
- 微调时的数据不平衡:在使用XLM-R进行跨语言任务微调时,不同语言之间的数据量可能不平衡,这可能导致模型在某些语言上表现不佳。
总之,尽管XLM-R在跨语言自然语言处理任务中表现出色,但仍需要更多的工作来解决其在应用过程中面临的局限性。
与XLM的区别
XLM-R和XLM都是针对跨语言表示学习的模型,但它们之间存在一些区别。以下是一些可能的区别:
-
训练数据规模:XLM-R使用更大规模的数据进行训练,可以处理更多的语言和更多的文本数据。
XLM-R模型是在大规模跨语言数据上进行训练的,包括了100种语言,总共约23TB的文本数据,其中包含了超过2.5亿个句子。这个规模远远超过了以往的跨语言预训练模型,使得XLM-R在跨语言任务上表现出色。
-
模型结构:XLM-R与XLM采用不同的模型结构,XLM-R使用了更深的神经网络结构。
XLM-R(Cross-lingual Language Model based on RoBERTa)是一个预训练的跨语言语言模型,其结构与 RoBERTa 模型非常相似,但是在训练数据和模型结构上有一些区别。XLM-R 模型采用了 RoBERTa 模型的基本结构,即由多层 Transformer 编码器组成,其中每个编码器由两个子层组成:多头自注意力机制和前馈神经网络。每个编码器的输出将被馈送到下一层编码器中,并经过一些额外的正则化和扰动技术进行改进。与 RoBERTa 不同的是,XLM-R 模型使用了两种额外的训练策略:1)跨语言数据的大规模无监督预训练;2)在训练过程中使用了多语言训练目标。此外,XLM-R 模型还采用了一种特殊的初始化方法,即通过对来自多个语言的训练数据的平均嵌入进行初始化,从而增强了跨语言信息的表示能力。
-
训练方式:XLM-R使用了更加高效的训练方法,如数据并行、半精度训练等,以加速训练过程。
XLM-R模型的训练方式是无监督预训练,采用了两个阶段的训练方式。在第一阶段,模型以单语数据作为输入,在不同语言的语料上进行预训练,以学习多语言表示。在第二阶段,模型以双语数据作为输入,在具有相同语义的句子对上进行对齐训练,以学习跨语言的表示。整个训练过程是端到端的,并在大规模的多语言语料库上进行,以提高泛化性能。
-
任务和性能:XLM-R在各种跨语言任务上都取得了优异的表现,如跨语言文本分类、机器翻译等。与XLM相比,XLM-R在某些任务上表现更好。
需要注意的是,XLM-R是在XLM的基础上进行改进和优化的,两者之间也存在很多共同点。
如何实现
Unsupervised Cross-lingual Representation Learning at Scale(XLM-R)是基于PyTorch实现的,并使用了Facebook AI Research(FAIR)的Fairseq工具包。具体来说,论文中的XLM-R模型是在预训练和微调阶段使用Fairseq实现的。预训练和微调的代码实现都可以在Fairseq的GitHub代码库中找到。
- 在预训练阶段,XLM-R模型使用了大规模的单语和多语数据集,包括Wikipedia、Common Crawl、ParaCrawl等。代码实现中使用了多线程数据加载器(multi-threaded data loader)来提高数据加载速度,使用PyTorch分布式训练(PyTorch Distributed Data Parallel)来支持多GPU训练。
- 在微调阶段,XLM-R模型可应用于多种跨语言自然语言处理任务,例如机器翻译、命名实体识别、情感分析等。在微调过程中,可以使用不同的微调方法和技巧,例如任务特定的数据增强、批量大小调整、学习率调整等。这些微调方法和技巧可以根据不同的任务进行定制和优化。
总的来说,XLM-R模型的实现基于现有的深度学习框架和工具包,利用了大规模的单语和多语数据集,并使用了各种微调技巧来提高跨语言自然语言处理任务的性能。
输入输出是什么
这个论文中的XLM-R模型主要用于学习跨语言的文本表示,其输入和输出形式如下:
输入:
- 源语言句子:以源语言的方式表示的文本句子,如用原始文本或子词(subword)表示的语言句子。
- 目标语言句子:以目标语言的方式表示的文本句子,如用原始文本或子词表示的语言句子。
输出:
- 源语言句子的文本表示:由XLM-R模型生成的源语言句子的固定长度向量表示。
- 目标语言句子的文本表示:由XLM-R模型生成的目标语言句子的固定长度向量表示。
举例来说,对于英文和法语两种语言,给定一对源语言句子和目标语言句子(分别用原始文本表示),XLM-R模型将输出这两个句子的固定长度向量表示,这些向量可以用于各种下游自然语言处理任务,如机器翻译、文本分类等。
代码实现举例
pytorch实现
import torch from transformers import XLMRobertaTokenizer, XLMRobertaModel # 加载预训练的XLM-RoBERTa模型和tokenizer tokenizer = XLMRobertaTokenizer.from_pretrained('xlm-roberta-base') model = XLMRobertaModel.from_pretrained('xlm-roberta-base') # 输入文本 input_text = "Hello, how are you doing today?" # 使用tokenizer将输入文本转化为token ids和attention mask input_ids = torch.tensor([tokenizer.encode(input_text)]) attention_mask = torch.ones_like(input_ids) # 将token ids和attention mask输入模型 output = model(input_ids=input_ids, attention_mask=attention_mask) # 获取模型输出的last hidden state和pooler output last_hidden_state = output.last_hidden_state pooler_output = output.pooler_output # 输出模型的last hidden state和pooler output print("Last Hidden State Shape: ", last_hidden_state.shape) print("Pooler Output Shape: ", pooler_output.shape)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
tensorflow实现
此代码加载了预先训练好的XLM-R模型并使用Tensorflow Datasets加载了一个数据集(multi30k)。在训练函数中,它首先将输入序列编码为输入ID,然后使用XLM-R模型计算输出,并计算损失。最后,使用反向传播更新模型权重以最小化损失。
import tensorflow as tf import tensorflow_datasets as tfds import numpy as np from transformers import XLMRobertaTokenizer # 加载XLM-R模型和tokenizer xlmr = tf.keras.models.load_model("xlmr.h5") tokenizer = XLMRobertaTokenizer.from_pretrained('xlm-roberta-base') # 加载数据集 ds = tfds.load('multi30k', split='train[:1%]', shuffle_files=True) ds = ds.batch(32) # 定义优化器和损失函数 optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5) loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) # 定义训练函数 @tf.function def train_step(inputs, targets): with tf.GradientTape() as tape: # 获取模型输出 outputs = xlmr(inputs) # 计算损失 loss = loss_fn(targets, outputs) # 计算梯度 gradients = tape.gradient(loss, xlmr.trainable_variables) # 反向传播 optimizer.apply_gradients(zip(gradients, xlmr.trainable_variables)) return loss # 训练模型 for batch in ds: inputs = tokenizer(batch['en'], padding=True, truncation=True, return_tensors='tf')['input_ids'] targets = batch['de'] loss = train_step(inputs, targets) print(loss.numpy())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
论文翻译
摘要
本文表明,大规模预训练多语言语言模型可以显着提高各种跨语言迁移任务的性能。我们使用超过 2 TB 的过滤 CommonCrawl 数据,在一百种语言上训练基于 Transformer 的屏蔽语言模型。我们的模型称为 XLM-R,在各种跨语言基准测试中明显优于多语言 BERT (mBERT),包括 XNLI 的平均准确率 +14.6%,MLQA 的平均 F1 得分 +13%,NER 的 F1 得分平均 +2.4% . XLM-R 在低资源语言上表现特别出色,与之前的 XLM 模型相比,斯瓦希里语的 XNLI 准确度提高了 15.7%,乌尔都语的准确度提高了 11.4%。我们还对实现这些收益所需的关键因素进行了详细的实证分析,包括 (1) 正迁移和容量稀释与 (2) 大规模高资源语言和低资源语言的性能之间的权衡。最后,我们首次展示了在不牺牲每种语言性能的情况下进行多语言建模的可能性; XLM-R 在 GLUE 和 XNLI 基准测试中与强大的单语言模型相比非常有竞争力。我们将公开我们的代码、数据和模型。1
1 简介
- 本文的目标是通过仔细研究大规模无监督跨语言表示训练的效果来提高跨语言语言理解 (XLU)。我们展示了 XLM-R 一种基于 transformer 的多语言掩码语言模型,该模型在 100 种语言的文本上进行了预训练,在跨语言分类、序列标记和问答方面获得了最先进的性能。
- 多语言掩码语言模型 (MLM)像 mBERT(Devlin 等人,2018 年)和 XLM(Lample 和 Conneau,2019 年)一样,通过在多种语言上联合预训练大型 Transformer 模型(Vaswani 等人,2017 年),推动了跨语言理解任务的最新发展.这些模型允许有效的跨语言迁移,如在许多基准测试中所见,包括跨语言自然语言推理(Bowman 等人,2015 年;Williams 等人,2017 年;Conneau 等人,2018 年)、问答( Rajpurkar 等人,2016 年;Lewis 等人,2019 年)和命名实体识别(Pires 等人,2019 年;Wu 和 Dredze,2019 年)。然而,所有这些研究都在维基百科上进行了预训练,维基百科提供的规模相对有限,尤其是对于资源较少的语言。
- 在本文中,我们首先对多语言语言模型的大规模权衡和局限性进行了综合分析,其灵感来自最近的单语言扩展工作(Liu 等人,2019 年)。我们衡量了高资源语言和低资源语言之间的权衡,以及语言抽样和词汇量的影响。当我们为固定模型容量扩展语言数量时,实验揭示了一种权衡:更多语言会导致低资源语言上更好的跨语言性能,直到一个点,之后单语言和跨语言的整体性能基准降低。我们将这种权衡称为多语言的诅咒,并表明可以通过简单地增加模型容量来缓解它。然而,我们认为,这仍然是未来 XLU 系统的一个重要限制,该系统可能旨在通过更适度的计算预算来提高性能。
- 我们最好的模型 XLM-RoBERTa (XLM-R) 在跨语言分类方面优于 mBERT,在低资源语言上的准确率高达 23%。它在 XNLI 上的平均准确率为 5.1%,在命名实体识别上的平均 F1 分数为 2.42%,在跨语言问答上的平均 F1 分数为 9.1%,优于之前的技术水平。我们还评估了 GLUE 和 XNLI 基准的单语微调,其中 XLM-R 获得的结果可与包括 RoBERTa 在内的最先进的单语模型竞争(Liu 等人,2019)。这些结果首次表明,可以在不牺牲每种语言性能的情况下为所有语言建立一个大型模型。我们将公开我们的代码、模型和数据,希望这将有助于研究多语言 NLP 和低资源语言理解
2 相关工作
- 从预训练词嵌入(Mikolov 等人,2013b;Pennington 等人,2014 年)到预训练语境化表示(Peters 等人,2018 年;Schuster 等人,2019 年)和基于转换器的语言模型(Radford 等人., 2018; Devlin et al., 2018),无监督表示学习显着提高了自然语言理解的最新水平。跨语言理解的并行工作(Mikolov 等人,2013a;Schuster 等人,2019 年;Lample 和 Conneau,2019 年)将这些系统扩展到更多语言和以一种语言学习模型的跨语言环境并应用于其他语言。
- 最近,Devlin 等人 (2018) 和 Lample 和 Conneau (2019) 介绍了 mBERT 和 XLM——在没有任何跨语言监督的情况下,在多种语言上训练的掩码语言模型。 Lample 和 Conneau (2019) 提出翻译语言建模 (TLM) 作为一种利用并行数据并获得跨语言自然语言推理 (XNLI) 基准的最新技术水平的方法(Conneau 等人,2018 年)。他们进一步展示了对无监督机器翻译和序列生成预训练的强大改进。吴等。 (2019) 表明单语言 BERT 表示在不同语言之间是相似的,部分解释了瓶颈架构中多语言的自然出现。另外,Pires 等人。 (2019) 证明了 mBERT 等多语言模型在序列标记任务上的有效性。黄等。 (2019) 使用跨语言多任务学习显示了 XLM 的收益,Singh 等人。 (2019) 证明了跨语言 NLI 的跨语言数据增强的效率。然而,与我们的方法相比,就训练数据量而言,所有这些工作的规模都相对较小。
- 通过增加模型和训练数据的大小来扩展语言模型预训练的好处已在文献中得到广泛研究。对于单语案例,Jozefowicz 等人。 (2016) 展示了大规模 LSTM 模型如何在对数十亿个标记进行训练时在语言建模基准上获得更强的性能。 GPT(Radford 等人,2018 年)也强调了扩展数据量的重要性,而 RoBERTa(Liu 等人,2019 年)表明,在更多数据上训练 BERT 的时间更长可以显着提高性能。受 RoBERTa 的启发,我们表明 mBERT 和 XLM 是欠调谐的,并且对无监督 MLM 的学习过程进行简单的改进可以带来更好的性能。我们在经过清理的 CommonCrawls(Wenzek 等人,2019 年)上进行训练,这将低资源语言的数据量平均增加了两个数量级。类似的数据也被证明对于学习多种语言的高质量词嵌入是有效的(Grave et al., 2018)。
- 一些努力已经从大型并行语料库中训练了大规模多语言机器翻译模型。他们揭示了高低资源权衡和产能稀释问题(Johnson 等人,2017 年;Tan 等人,2019 年)。与我们最相似的工作是 Arivazhagan 等人。 (2019),它在超过 250 亿个平行句子上训练了 103 种语言的单一模型。 Siddhant 等人。 (2019) 进一步分析了大规模多语言机器翻译系统的编码器获得的表征,表明它在跨语言 NLI 上获得了与 mBERT 相似的结果。相比之下,我们的工作侧重于跨语言表征的无监督学习及其向判别任务的转移。
3.Model and Data
在本节中,我们介绍了训练目标、语言和我们使用的数据。我们尽可能地遵循 XLM 方法(Lample 和 Conneau,2019 年),只引入可大规模提高性能的更改。
-
Masked Language Models.掩码语言模型:我们使用 Transformer 模型(Vaswani 等人,2017 年),该模型仅使用单语数据进行多语言 MLM 目标(Devlin 等人,2018 年;Lample 和 Conneau,2019 年)训练。我们对每种语言的文本流进行采样,并训练模型以预测输入中的屏蔽标记。我们使用 Sentence Piece (Kudo and Richardson, 2018) 和 unigram 语言模型 (Kudo, 2018) 将子词标记化直接应用于原始文本数据。我们使用与 Lample 和 Conneau (2019) 相同的抽样分布对不同语言的批次进行抽样,但 α = 0.3。与 Lample 和 Conneau (2019) 不同,我们不使用语言嵌入,这使我们的模型能够更好地处理语码转换。我们使用 250K 的大词汇量和完整的 softmax 并训练两个不同的模型: X L M − R B a s e XLM-R_{Base} XLM−RBase(L = 12,H = 768,A = 12,270M 参数)和 XLM-R(L = 24,H = 1024 , A = 16, 550M 参数)。对于我们所有的消融研究,我们使用 B E R T B a s e BERT_{Base} BERTBase架构和 150K 令牌的词汇表。附录 B 详细介绍了本文中引用的不同模型的架构。扩展到一百种语言。
-
Scaling to a hundred languages.:XLM-R 接受了 100 种语言的训练;我们在附录 A 中提供了完整的语言列表和相关统计数据。图 1 指定了 XLM-R 和 XLM-100 共享的 88 种语言的 iso 代码,Lample 和 Conneau (2019) 的模型在 100 种维基百科文本上进行了训练语言。
- 与之前的工作相比,我们将一些语言替换为更常用的语言,例如罗马化的印地语和繁体中文。在我们的消融研究中,我们总是包括 7 种我们有分类和序列标记评估基准的语言:英语、法语、德语、俄语、中文、斯瓦希里语和乌尔都语。我们之所以选择这个集合,是因为它涵盖了合适的语系范围,并且包括斯瓦希里语和乌尔都语等资源匮乏的语言。我们还考虑了 15 种、30 种、60 种和所有 100 种语言的更大集合。在报告高资源和低资源的结果时,我们分别参考英语和法语结果的平均值,以及斯瓦希里语和乌尔都语结果的平均值。
-
Scaling the Amount of Training Data:继 Wenzek 等人之后。 (2019) 2,我们构建了一个干净的 100 种语言的 CommonCrawl 语料库。我们将内部语言识别模型与来自 fastText 的模型结合使用(Joulin 等人,2017)。我们训练每种语言的语言模型,并使用它来过滤文档,如 Wenzek 等人所述。 (2019)。我们考虑一个用于英语的 CommonCrawl 转储和十二个用于所有其他语言的转储,这显着增加了数据集的大小,尤其是对于像缅甸语和斯瓦希里语这样的低资源语言。
图 1 显示了 mBERT 和 XLM100 使用的维基百科语料库与我们使用的 CommonCrawl 语料库在大小上的差异。正如我们在第 5.3 节中展示的那样,单语维基百科语料库太小而无法实现无监督表示学习。根据我们的实验,我们发现几百 MiB 的文本数据通常是学习 BERT 模型的最小尺寸。
4 评价
我们考虑四个评价基准。对于跨语言理解,我们使用跨语言自然语言推理、命名实体识别和问答。我们使用 GLUE 基准来评估 XLM-R 的英语性能,并将其与其他最先进的模型进行比较。
- **Cross-lingual Natural Language Inference (XNLI)**跨语言自然语言推理 (XNLI)。 XNLI 数据集带有 15 种语言的 groundtruth 开发和测试集,以及一个 ground-truth 英语训练集。训练集已被机器翻译成其余 14 种语言,也为这些语言提供了综合训练数据。我们评估了从英语到其他语言的跨语言迁移模型。我们还考虑了三个机器翻译基线:(i) 翻译测试:开发和测试集被机器翻译成英语,并使用单一英语模型 (ii) 翻译训练(按语言):英语训练集是机器-翻译成每种语言,我们在每个训练集上微调多语言模型 (iii) translate-train-all(多语言):我们在 translate-train 的所有训练集的串联上微调多语言模型。对于翻译,我们使用 XNLI 项目提供的官方数据。
- **Named Entity Recognition命名实体识别。**对于 NER,我们考虑英语、荷兰语、西班牙语和德语的 CoNLL-2002(Sang,2002)和 CoNLL2003(Tjong Kim Sang 和 De Meulder,2003)数据集。我们微调多语言模型(1)在英语集上评估跨语言迁移,(2)在每个集上评估每种语言的表现,或(3)在所有集上评估多语言学习。我们报告 F1 分数,并与 Lample 等人的基线进行比较。 (2016) 和 Akbik 等人。 (2018)。
- Cross-lingual Question Answering跨语言问答。我们使用 Lewis 等人的 MLQA 基准。 (2019),将英语 SQuAD 基准扩展到西班牙语、德语、阿拉伯语、印地语、越南语和中文。我们报告了 F1 分数以及从英语跨语言迁移的精确匹配 (EM) 分数。
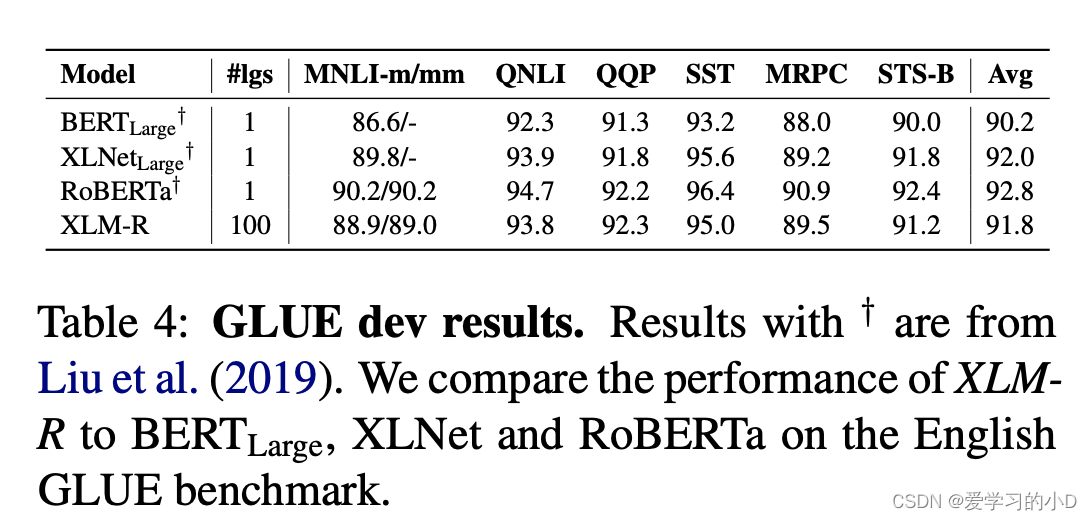
- **GLUE Benchmark:**最后,我们在 GLUE 基准测试(Wang et al., 2018)上评估了我们模型的英语性能,它收集了多个分类任务,例如 MNLI(Williams et al., 2017)、SST-2(Socher et al., 2013) ), 或 QNLI (Rajpurkar et al., 2018)。我们使用 BERTLarge 和 RoBERTa 作为基线。
5.分析和结果
在本节中,我们对多语言掩码语言模型进行了全面分析。我们对 XNLI 进行了大部分分析,我们发现它代表了我们在其他任务上的发现。然后我们展示 XLM-R 在跨语言理解和 GLUE 方面的结果。最后,我们比较了多语言和单语言模型,并展示了低资源语言的结果。
5.1 改进和理解多语言掩码语言模型
在理解 mBERT 或 XLM 的跨语言有效性方面所做的大部分工作(Pires 等人,2019 年;Wu 和 Dredze,2019 年;Lewis 等人,2019 年)侧重于分析修复了下游任务的预训练模型。在本节中,我们将全面研究对预训练大规模多语言模型很重要的不同因素。当我们扩展到一百种语言时,我们强调了这些模型的权衡和局限性。转移稀释权衡和多语言诅咒。
- Transfer-dilution Trade-off and Curse of Multilinguality,模型容量(即模型中的参数数量)受到限制。对于固定大小的模型,随着语言数量的增加,每种语言的容量会降低。虽然可以通过在预训练期间添加类似的高资源语言来提高低资源语言的性能,但总体下游性能会受到这种容量稀释的影响(Arivazhagan 等人,2019 年)。正转移和产能稀释必须相互权衡。
- 我们在图 2 中说明了这种权衡,其中显示了 XNLI 性能与模型预训练语言数量的关系。最初,当我们从 7 种语言发展到 15 种语言时,该模型能够利用正迁移来提高性能,尤其是在低资源语言上。超过这一点,多语言的诅咒就会开始并降低所有语言的性能。具体来说,随着我们从 XLM-7 到 XLM-100,整体 XNLI 准确率从 71.8% 下降到 67.7%。对于在更大的 CommonCrawl 语料库上训练的模型,可以观察到相同的趋势。
- 当模型的容量较小时,这个问题就更加突出。为了证明这一点,我们在维基百科数据上以 7、30 和 100 种语言预训练模型。随着我们添加更多语言,我们通过将隐藏大小从 768 增加到 960 再到 1152 来使 Transformer 更宽。在图 4 中,我们表明增加的容量使 XLM-30 与 XLM-7 相当,从而克服了诅咒的多语种。然而,XLM-100 增加的容量还不够,而且由于更高的词汇量稀释,它仍然落后(回想一下第 3 节,我们对所有模型使用了 150K 的固定词汇量大小)。
- **High-resource vs Low-resource Trade-off高资源与低资源权衡。:**跨语言的模型容量分配由几个参数控制:训练集大小、共享子词词汇表的大小以及我们从每种语言中采样训练示例的速率。对于在维基百科上训练的 XLM-100 模型,我们研究了抽样对高资源(英语和法语)和低资源(斯瓦希里语和乌尔都语)语言性能的影响(我们观察到类似的子词词汇构建趋势)。具体来说,我们研究了改变控制语言采样率指数平滑的 α 参数的影响。与 Lample 和 Conneau (2019) 类似,我们使用与每个语料库中的句子数量成比例的采样率。用更高的 α 值训练的模型更频繁地看到一批高资源语言。图 5 显示 α 的值越高,在高资源语言上的性能越好,反之亦然。在考虑整体性能时,我们发现 0.3 是 α 的最佳值,并将其用于 XLM-R。
- **Importance of Capacity and Vocabulary. **:在前面的部分和图 4 中,我们展示了随着语言数量的增加而缩放模型大小的重要性。与整体模型大小类似,我们认为扩展共享词汇表的大小(词汇表容量)可以提高多语言模型在下游任务上的性能。为了说明这种效果,我们在具有不同词汇量的维基百科数据上训练 XLM-100 模型。我们通过调整转换器的宽度来保持参数的总数不变。图 6 显示,即使容量固定,当我们将词汇量从 32K 增加到 256K 时,我们观察到 XNLI 平均准确度提高了 2.8%。这表明多语言模型可以受益于将更高比例的参数总数分配给嵌入层,即使这会减小 Transformer 的大小。
- 为简单起见并考虑到 softmax 计算约束,我们为 XLM-R 使用 250k 的词汇表。我们通过训练具有相同转换器架构 ( B E R T B a s e BERT_{Base} BERTBase) 但词汇量不同的三个模型来进一步说明此参数的重要性:128K、256K 和 512K。通过简单地将词汇量从 128k 增加到 512k,我们观察到 XNLI 的整体准确率提高了 3% 以上。
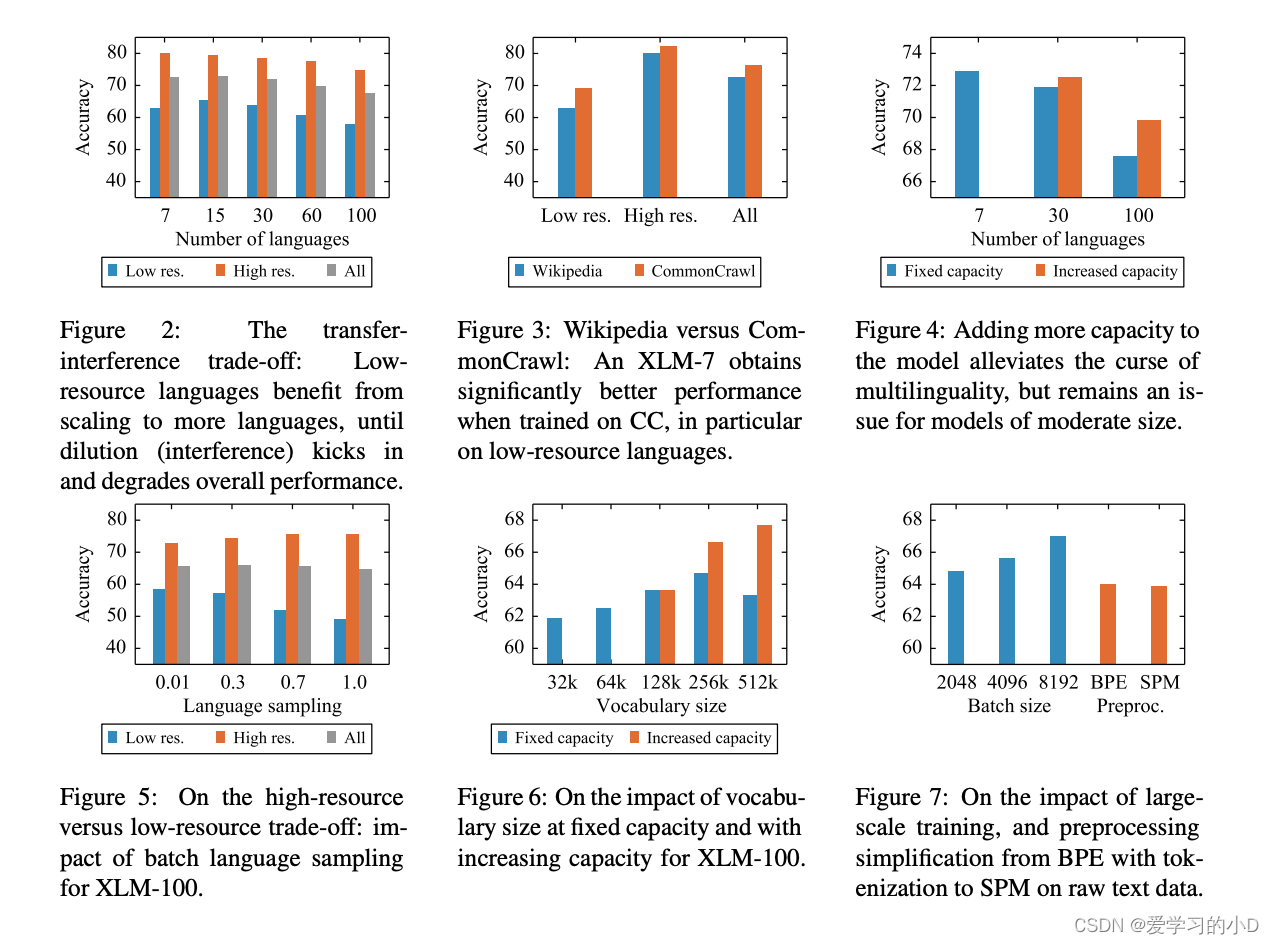
- **Larger-scale Datasets and Training更大规模的数据集和训练。**如图 1 所示,我们收集的 CommonCrawl 语料库比以前使用的维基百科语料库具有更多的单语数据。图 3 显示,对于相同的 BERTBase 架构,在 CommonCrawl 上训练的所有模型都获得了明显更好的性能。
- 除了缩放训练数据,Liu 等人。 (2019) 还展示了更长时间培训传销的好处。在我们的实验中,我们观察到大规模训练对模型性能的类似影响,例如增加批量大小(参见图 7)和训练时间。具体来说,我们发现使用验证困惑作为预训练的停止标准会导致 Lample 和 Conneau (2019) 中的多语言 MLM 调整不足。根据我们的经验,即使在验证困惑趋于稳定之后,下游任务的性能也会继续提高。将这一观察与我们对无监督 XLM-MLM 目标的实施相结合,我们能够将 Lample 和 Conneau (2019) 在 XNLI 上的平均准确率从 71.3% 提高到 75% 以上,这与他们的监督翻译语言相当建模 (TLM) 目标。基于这些结果,并考虑到我们对无监督学习的关注,我们决定不使用监督 TLM 目标来训练我们的模型。
- Simplifying Multilingual Tokenization with Sentence Piece用句子简化多语言标记化: mBERT 和 XLM-100 使用的不同语言特定标记化工具使这些模型更难用于原始文本。相反,我们训练句子片段模型 (SPM) 并将其直接应用于所有语言的原始文本数据。与使用特定语言预处理和字节对编码训练的模型相比,我们没有观察到使用 SPM 训练的模型有任何性能损失。
5.2 跨语言理解结果
基于这些结果,我们调整了 Lample 和 Conneau (2019) 的设置,并使用具有 24 层和 1024 个隐藏状态、250k 词汇量的大型 Transformer 模型。我们使用多语言 MLM 损失并训练我们的 XLM-R 模型在 500 个 32GB Nvidia V100 GPU 上进行 150 万次更新,批量大小为 8192。我们利用来自 CommonCrawl 的 100 种语言和示例语言的 SPM 预处理文本数据,α = 0.3。在本节中,我们展示了它在跨语言基准测试中优于所有以前的技术,同时在 GLUE 基准测试中获得与 RoBERTa 相当的性能。
- **XNLI:**表 1 显示了 XNLI 结果并添加了一些额外的细节:(i)该方法诱导的模型数量(#M),(ii)训练模型的数据(D),以及(iii)语言的数量模型在 (#lg) 上进行了预训练。正如我们在结果中所示,这些参数会显着影响性能。 #M 列指定模型选择是在每种语言的开发集(N 个模型)上单独完成,还是在所有语言的联合开发集(单个模型)上完成。当我们从 N 个模型到单个模型时,我们观察到整体准确度下降了 0.6——从 71.3 到 70.7。我们鼓励社区采用这种设置。对于跨语言迁移,虽然这种方法不完全是零样本迁移,但我们认为在实际应用中,通常有少量监督数据可用于每种语言的验证。
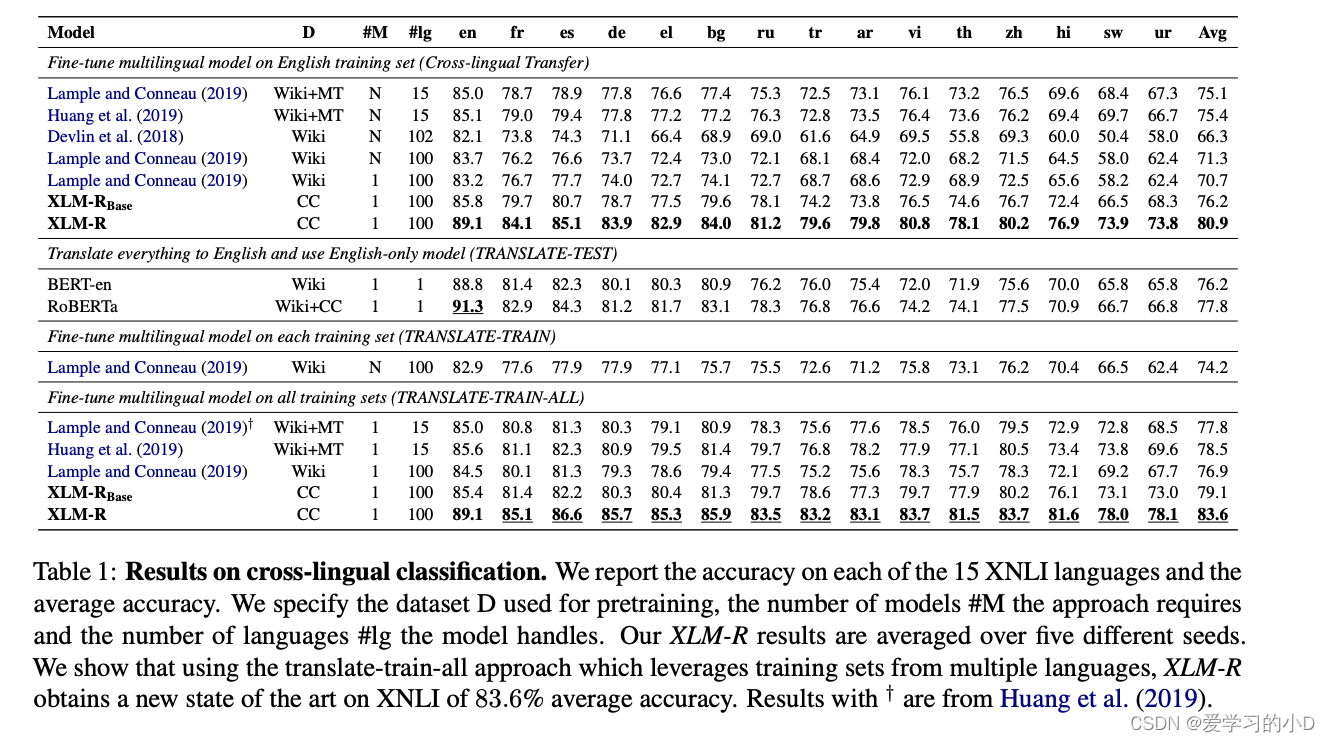
- XLM-R 在 XNLI 上树立了新的技术水平。在跨语言迁移中,XLM-R 获得了 80.9% 的准确率,比 XLM-100 和 mBERT 开源模型分别高出 10.2% 和 14.6% 的平均准确率。在斯瓦希里语和乌尔都语低资源语言上,XLM-R 比 XLM-100 高出 15.7% 和 11.4%,比 mBERT 高出 23.5% 和 15.8%。虽然 XLM-R 可以处理 100 种语言,但我们还表明它比以前最先进的 Unicoder(Huang 等人,2019 年)和 XLM(MLM+TLM)仅处理 15 种语言,平均高出 5.5% 和 5.8%准确度分别。使用 translate-train-all 的多语言训练,XLM-R 进一步提高了性能并达到了 83.6% 的准确率,这是 XNLI 的一个新的整体技术水平,比 Unicoder 高出 5.1%。多语言训练类似于实际应用,其中针对同一任务提供多种语言的训练集。就 XNLI 而言,数据集已经过翻译,translate-trainall 可以看作是某种形式的跨语言数据增强(Singh 等人,2019 年),类似于回译(Xie 等人,2019 年)。
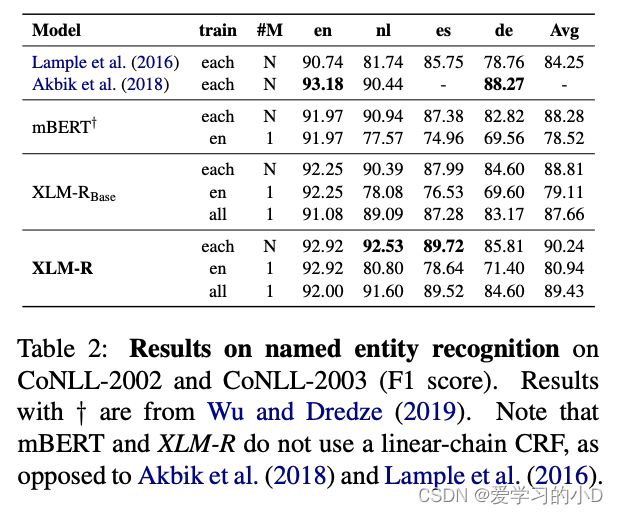
- **Named Entity Recognition:**在表 2 中,我们报告了 XLM-R 和 mBERT 在 CoNLL2002 和 CoNLL-2003 上的结果。我们考虑 Lample 等人的 LSTM + CRF 方法。 (2016) 和 Akbik 等人的 Flair 模型。 (2018)作为基线。我们在三种不同的设置下评估模型在每种目标语言上的性能:(i)仅对英语数据进行训练(en)(ii)对目标语言的数据进行训练(每种)(iii)对所有语言的数据进行训练(全部)。 mBERT 的结果来自 Wu 和 Dredze (2019)。请注意,我们不在 XLM-R 和 mBERT 表示之上使用线性链 CRF,这为 Akbik 等人提供了优势。 (2018)。在没有 CRF 的情况下,我们的 XLM-R 模型仍然与最先进的技术水平相当,优于 Akbik 等人。 (2018) 对荷兰语 2.09 分。在这项任务中,XLM-R 在跨语言迁移方面的平均 F1 也比 mBERT 高出 2.42,在对每种语言进行训练时,F1 也比 mBERT 高出 1.86。所有语言的训练导致平均 F1 得分为 89.43%,比跨语言迁移方法高出 8.49%。
- **Question Answering:**我们还在 Lewis 等人介绍的 MLQA 跨语言问答基准上获得了最新的最新结果。 (2019)。我们按照他们的程序对英语训练数据进行训练并对数据集的 7 种语言进行评估。我们在表 3 中报告了结果。XLM-R 获得 F1 和准确度分数分别为 70.7% 和 52.7%,而之前的技术水平为 61.6% 和 43.5%。 XLM-R 的 F1 分数和准确率也优于 mBERT 13.0% 和 11.1%。它甚至在英语上的表现优于 BERT-Large,证实了其强大的单语性能。
5.3 多语言与单语言
在本节中,我们将展示多语言 XLM 模型与单语言 BERT 模型的对比结果。
- **GLUE: XLM-R versus RoBERT:**我们的目标是获得一个多语言模型,在跨语言理解任务和每种语言的自然语言理解任务上都有很强的表现。为此,我们在 GLUE 基准上评估 XLMR。我们在表 4 中显示,XLM-R 获得的平均开发性能比 B E R T L a r g e BERT_{Large} BERTLarge 高 1.6%,并且达到与 X L N e t L a r g e XLNet_{Large} XLNetLarge 相当的性能。 RoBERTa 模型平均仅比 XLM-R 高出 1.0%。我们相信未来的工作可以通过减轻多语言和词汇稀释的诅咒来进一步缩小这一差距。这些结果证明了为多种语言学习一种模型同时在每种语言的下游任务上保持强大性能的可能性。
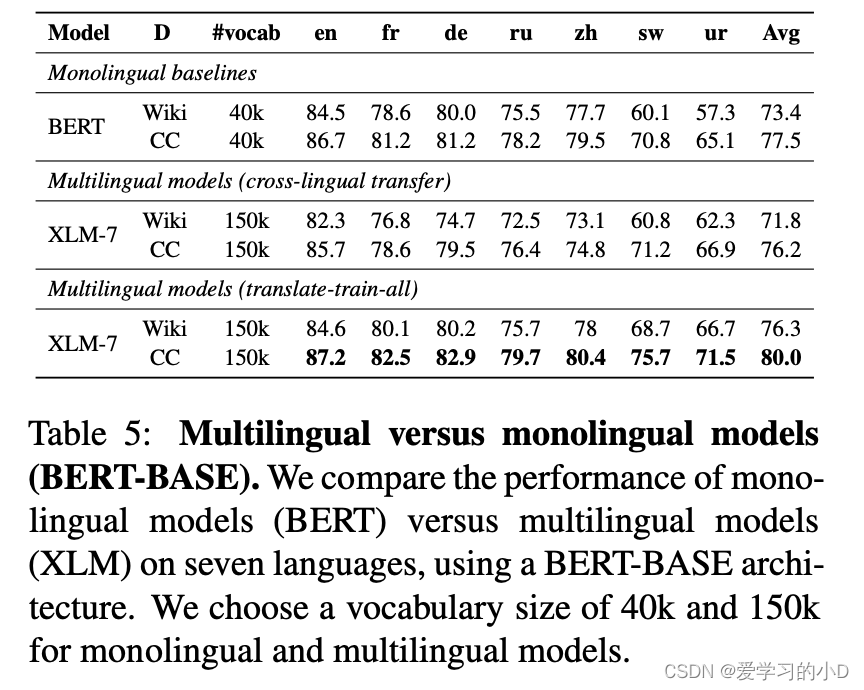
- XNLI: XLM versus BERT:对多语言模型的反复批评是,它们的性能比单语言模型差。除了 XLM-R 和 RoBERTa 的比较之外,我们还提供了第一个综合研究来评估 XNLI 基准上的这一说法。我们扩展了 7 种语言的多语言 XLM 模型和单语言 BERT 模型之间的比较,并在表 5 中比较了性能。我们在维基百科和 CommonCrawl(上限为 60 GiB)和两个 XLM-7 模型上训练了 14 个单语言 BERT 模型。我们增加了多语言模型的词汇量以进行更好的比较。我们发现多语言模型可以胜过单语言 BERT 模型。具体来说,在表 5 中,我们表明对于跨语言迁移,维基百科和 CC 的单语言基线的平均准确度均优于 XLM-7 1.6% 和 1.3%。然而,通过使用多语言训练 (translate-trainall) 和利用来自多种语言的训练集,XLM-7 可以胜过 BERT 模型:我们在 CC 上训练的 XLM-7 在 7 种语言上获得了 80.0% 的平均准确率,而在 CC 上训练的 BERT 模型的平均性能为 77.5%。这是一个令人惊讶的结果,它表明多语言模型利用来自多种语言的训练数据来完成特定任务的能力可以克服容量稀释
5.4 低资源语言的表示学习
我们在表 5 中观察到,维基百科上斯瓦希里语和乌尔都语的预训练与随机初始化模型的表现相似;很可能是因为这些语言的数据量很小。另一方面,在 CC 上进行预训练可将性能提高多达 10 个百分点。这证实了我们的假设,即 mBERT 和 XLM-100 严重依赖跨语言迁移,但不像 XLM-R 那样对低资源语言建模。具体来说,在 translate-train-all 设置中,我们观察到在 CC 上训练的 XLM 模型与其维基百科对应物相比的最大收益是在低资源语言上;斯瓦希里语和乌尔都语分别提高了 7% 和 4.8%。
6 结论
- 在这项工作中,我们介绍了 XLM-R,这是我们最先进的多语言掩码语言模型,在 2.5 TB 新创建的 100 种语言的干净 CommonCrawl 数据上进行了训练。我们表明,它在分类、序列标记和问答方面比之前的多语言模型(如 mBERT 和 XLM)提供了强大的收益。我们揭示了多语言 MLM 的局限性,特别是通过揭示高资源与低资源的权衡、多语言的诅咒和关键超参数的重要性。我们还揭示了多语言模型相对于单语言模型的惊人有效性,并展示了对低资源语言的强大改进。

