
- 1C++虚函数表_c++ 获取虚函数表的大小
- 2idea使用指南_idea使用详解csdn
- 3vue实现轮播_轮播vue
- 4新唐NUC972 Linux(一):USB烧写linux出厂镜像
- 5App防止恶意截屏功能的方法:iOS、Android和鸿蒙系统的实现方案_uiscreencaptureddidchange通知
- 6【大厂AI课学习笔记NO.79】机器学习行业人才能力图谱
- 7【PyTorch][chapter 22][李宏毅深度学习]【无监督学习][ WGAN]【理论二】
- 8harmonyos应用开发者高级认证考试部分答案
- 9vue3使用element-plus 树组件(el-tree)数据回显_vue3 el-tree ref
- 10Pyhton自动化测试持续集成和Jenkins_python自动化测试 jenkins持续集成
2023 英特尔 oneAPI 人工智能黑客松竞赛--鸟类识别_鸟类识别api
赞
踩
项目背景:鸟类识别
鸟类数据集是自带了训练集和测试集的。训练集的label就是文件夹的名称。总共有25个分类。需要利用深度学习模型预测鸟儿的种类。

项目思路:鸟类识别
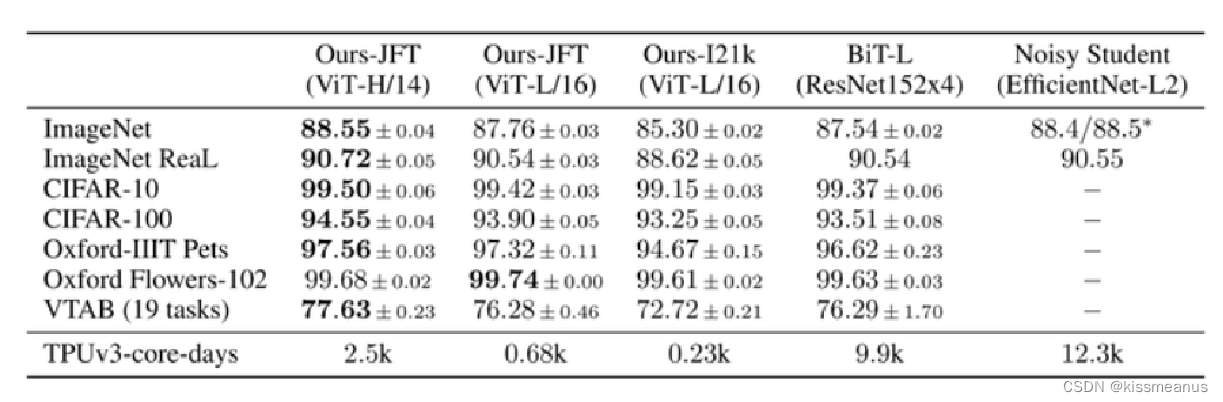
常规的思路就是采用CNN模型,常见的CNN有VGG,ResNet,DenseNet等,目前最流行的是采用Transformer注意力机制的ViT模型。ViT-H/14在JFT数据集上进行预训练之后,在ImageNet-1k上达到了最高的88.55的精度;在其他数据集上也达到了很好的效果;
ViT架构
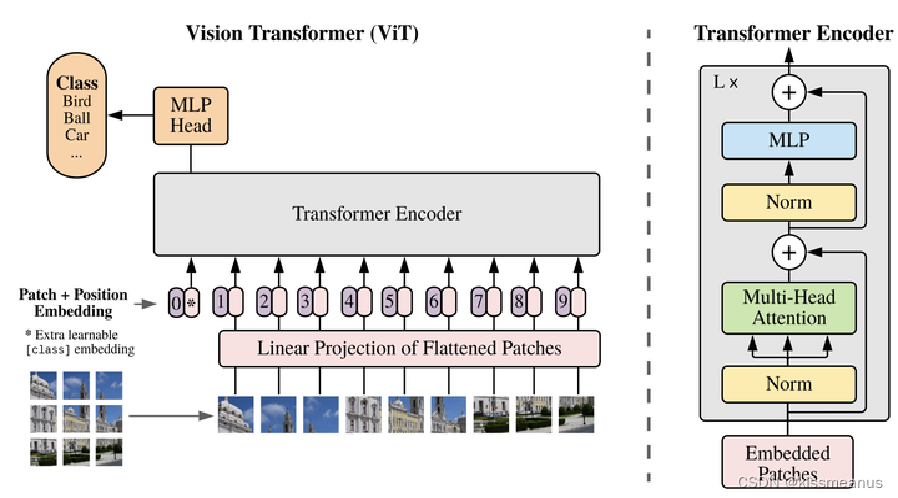
Vision Transformer(ViT)大致流程:
- 将原图分为多个patch
- 经过Linear Projection of Flattened Patches(Embedding层)生成特征
- Transformer Encode进一步编码
- MLP Head,进行最终的分类
项目难点
ViT模型,有三种模型(Base/ Large/ Huge)的参数,论文的源码中除了有Patch Size为16x16的外还有32x32;
Layers: Transformer Encoder中重复堆叠Encoder Block的次数
Hidden Size: 对应通过Embedding层后每个token的dim(向量的长度)
MLP size: Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍)
Heads: Transformer中Multi-Head Attention的heads数
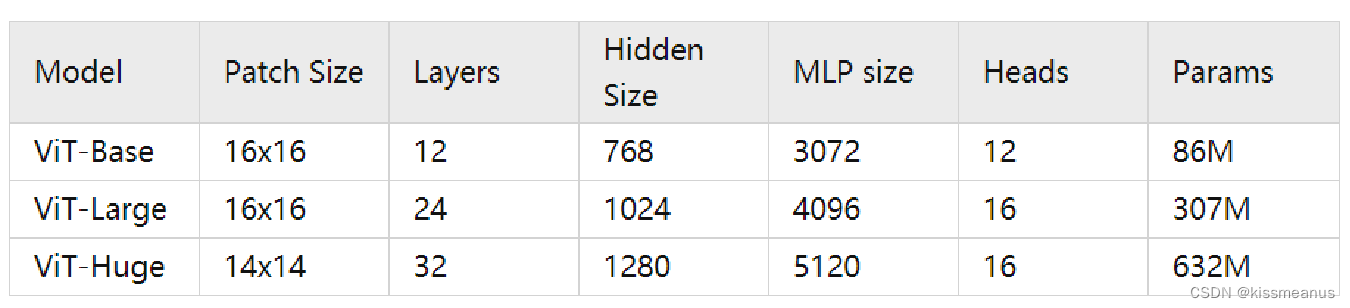
ViT-Huge 的参数量达到了恐怖了的632M,可怜我的小显卡只有8M显存,放入模型后就不能放入数据集了。只能在CPU上训练,但是CPU确实太慢了,有没有能加速CPU的统一工具呢? 还真有
Intel黑科技为CPU加速
英特尔搞了一个基于Intel的硬件设备(CPU,GPU)的PyTorch的 扩展工具,可以加快PyTorch 在英特尔 CPU 上的运行速度。它基于PyTorch的扩展机制实现,通过提供额外的软件优化极致地发挥硬件特性,帮助用户在原生PyTorch的基础上更最大限度地提升英特尔 CPU 上的深度学习推理计算和训练性能。

内存布局
内存布局是优化视觉相关运算符的基础,而且使用适合的内存格式来处理输入张量可以显著地提高 PyTorch CNN 模型的性能。Channels Last 内存格式通常有利于多个硬件后端,包括英特尔 CPU。
英特尔® oneDNN 库针对模型权重引入了块状内存布局,以实现更出色的向量化和缓存复用。为避免运行时转换,在执行 oneDNN 运算符之前,我们将权重转换为预定义的最佳块格式。这种技术被称为权重预封装,当用户调用扩展提供的 ipex.optimize 前端 API 时,它可以用于模型推理和训练。
model = model.to(memory_format=torch.channels_last)
input = input.to(memory_format=torch.channels_last)
- 1
- 2
BF16 自动混合精度
英特尔将原生 BF16 支持引入第三代英特尔® 至强® 可扩展处理器,并支持 BF16→ FP32 FMA 和 FP32→BF16 转换,相比 FP32 FMA 相比,理论计算吞吐量翻了一番。
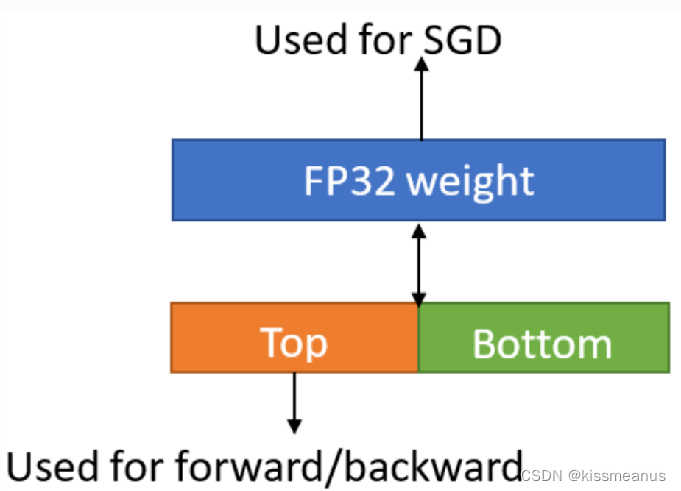
BF16 混合精度训练可通过加速计算、降低内存带宽压力和减少内存消耗显著提升性能然而,随着训练后期不断积累,权重更新会太小而导致精度问题,Intel做法是在 FP32 中保留权重的主副本,这样 BF16 模型权重内存占用会增大 2 倍。
将 FP32 参数拆分成“Top half”和“Bottom half”。“Top half”是前 16 位,用于前向/后向传播计算,“Bottom half”是后 16 位,其作用是更新参数避免出现精度损失。
优化器(Optimizer)优化
优化器的性能在训练性能中发挥着不可忽视的作用,我们在面向 PyTorch* 的英特尔® 扩展中提供优化器的优化版本。
支持面向优化器 Lamb、Adagrad 和 SGD 的融合内核,这些融合优化器将用于通过 ipex.optimize 前端优化来替换相应的优化,因此用户无需更改模型代码即可应用这些融合优化器。内核在权重更新步骤中融合模型参数的内存受限操作链及其梯度,以便数据驻留在高速缓存中,无需再从内存中加载。
import intel_extension_for_pytorch as ipex
...
model = Model()
model = model.to(memory_format=torch.channels_last)
criterion = ...
optimizer = ...
model.train()
model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.bfloat16)
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
INT8 量化
量化是指通过降低权重和/或激活的数值精度来压缩深度网络中的信息。将用于参数信息的 FP32 数字转换为 INT8 之后,模型会变小,并显著节省内存和降低计算需求。英特尔自第二代英特尔至强可扩展处理器(代号“Cascade Lake”)起开始引入 AVX512 VNNI 扩展指令集,从而支持更快地计算 INT8 数据并提高吞吐量。
第一步:准备数据和标签
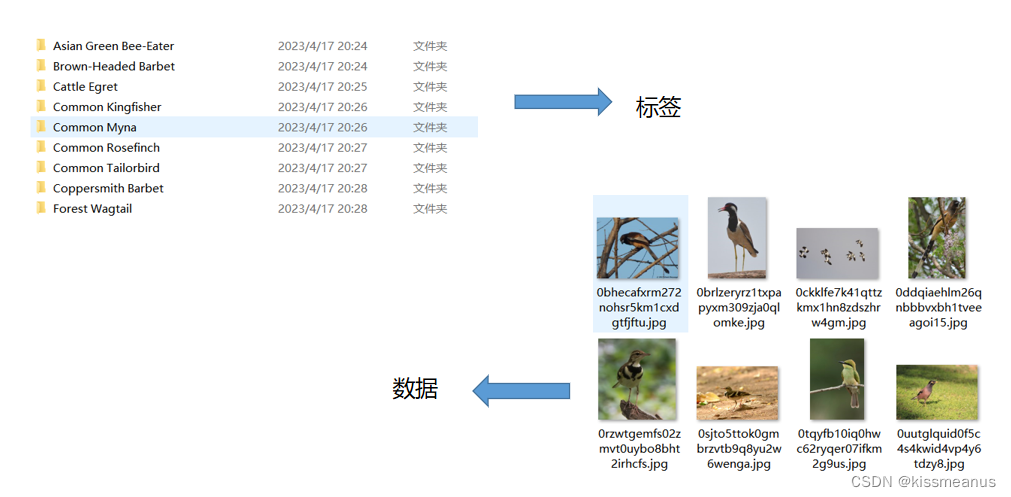
第二步:自定义dataset
class BirdDataset(Dataset): # 第一步:准备features 和 labels,已经完成 def __init__(self, root, train="train", transform=None): self.root_dir = root self.train = train self.img = [] self.label = [] self.transform = transform def __len__(self): return len(self.img) # 读取单条数据 def __getitem__(self, idx): image = Image.open(self.img[idx]) if image.mode != 'RGB': # rg image = image.convert("RGB") if self.transform: image = self.transform(image) if self.train=="train": label = self.label[idx] label = torch.from_numpy(np.array(label)) label = label.to(torch.int64) return image, label else: return image,self.img[idx]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
第三步:数据增强

还可以加入
裁剪(Crop)
transforms.CenterCrop( ):中心裁剪;
transforms.RandomCrop( ):随机裁剪
翻转和旋转(Flip and Rotation)
transforms.RandomHorizontalFlip( ):随机水平翻转;
transforms.RandomVerticalFlip( ):随机垂直翻转;
transforms.RandomRotation( ):随机旋转;
第五步:训练模型
下载代码:https://github.com/google-research/vision_transformer
下载 imagenet21k pre-train预训练模型
wget https://storage.googleapis.com/vit_models/imagenet21k/{MODEL_NAME}.npz
MODEL_NAME填写模型的类型名字,有这些可选:ViT-B_16, ViT-B_32, ViT-L_16, ViT-L_32, ViT-H_14
训练模型
python train.py --name bird --dataset …/dataset --model_type ViT-B_16 --pretrained_dir checkpoint/ViT-B_16.npz
–name 项目的名字,保存的模型也和之个值有关
–dataset 数据集路径
–model_type 有这些可选:ViT-B_16, ViT-B_32, ViT-L_16, ViT-L_32, ViT-H_14
–pretrained_dir 预训练模型的地址
第六步: intel_extension_for_pytorch 改造
import intel_extension_for_pytorch as ipex
...
model = VisionTransformer(config, args.img_size, zero_head=True, num_classes=num_classes) model_np = np.load(args.pretrained_dir)
model.load_from(model_np) #加载预训练模型
...
optimizer = torch.optim.SGD(model.parameters(), lr=args.learning_rate,
momentum=0.9,weight_decay=args.weight_decay)
#需要第三代英特尔® 至强® 可扩展处理器
model, optimizer = ipex.optimize(model, optimizer=optimizer, dtype=torch.bfloat16)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
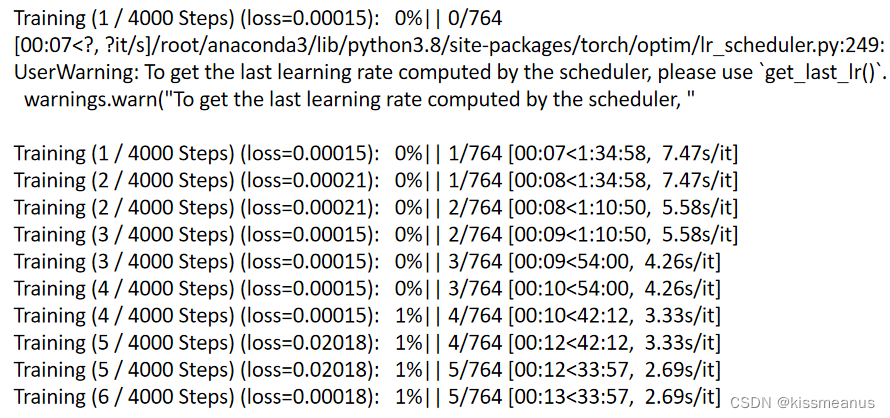
第七步:注意力 可视化
ViT 共有12层,通过可视化每一层注意力的softmax的输出。可以看出注意力的执行过程。
最后2层的注意力特别明显,注意力是集中在鸟儿身上,特别鸟头和爪子部分。

第八步: 推理
推理也需要做ipex改造
import intel_extension_for_pytorch as ipex
...
model = VisionTransformer(config, args.img_size, zero_head=True, num_classes=num_classes) #建立模型
state_dict = torch.load(args.pretrained_dir, map_location=torch.device('cpu')) model.load_state_dict(state_dict)model = model.to(memory_format=torch.channels_last)
model.eval()
model = ipex.optimize(model, dtype=torch.bfloat16)
- 1
- 2
- 3
- 4
- 5
- 6

总结:
Intel提供的intel_extension_for_pytorch 可以IntelCPU提供加速的能力,为广大的无显卡或者弱显卡用户,提供了另一种选择。


