
热门标签
热门文章
- 115-3.自定义组件的生命周期函数_自定义组件的生命周期函数有哪些
- 2css 平均分布自动换行_grid布局自动换行
- 3Entity Framework Core 配置_efcore 特性实体默认值 允许为空
- 4realsense D455深度相机+YOLO V5结合实现目标检测(一)_d455 深度图
- 5SQL Serever学习16——索引,触发器,数据库维护
- 6TensorFlowIO操作(二)----读取数据
- 7Android编译过程详解
- 8【考证须知】IT行业高含金量的证书_各家厂商网络工程师证书含金量
- 902-Linux设备分类和设备编号学习_设备类型 设备节点 设备号
- 10基于机器学习(深度学习)的文本分类系统-毕业设计_文本分类机器学习深度学习
当前位置: article > 正文
python 爬虫编码(encoding和apparent_encoding)区别
作者:AllinToyou | 2024-03-13 10:37:43
赞
踩
python 爬虫编码(encoding和apparent_encoding)区别
一、代码案例(encoding)
1.相关代码:
- import requests
- # 发送GET请求到清华大学官网
- url = 'https://www.tsinghua.edu.cn/'
- response = requests.get(url)
- encoding = response.encoding
- # 获取并打印网页编码方式
- print(f"网页编码方式:{encoding}")
2.打印结果:
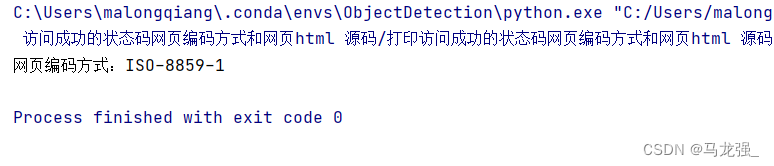 二、代码案例(apparent_encoding)
二、代码案例(apparent_encoding)
1.相关代码:
- import requests
- # 发送GET请求到清华大学官网
- url = 'https://www.tsinghua.edu.cn/'
- response= requests.get(url)
- encoding = response.apparent_encoding
- # 获取并打印网页编码方式
- print(f"网页编码方式:{encoding}")
2.打印结果

三、查看网页是什么编码方式

四、encoding和apparent_encoding两者表示的是什么以及区别
1.encoding和apparent_encoding的使用场景
requests.get() 函数在获取网页内容时,默认会尝试从HTTP响应头部的Content-Type字段中提取编码信息来设置response.encoding属性。然而,有时候服务器提供的编码信息可能不准确或者未提供,这时requests库会使用chardet库(如果已安装)来推测网页的实际编码,这推测出来的编码就是response.apparent_encoding。
2.encoding的使用
response.encoding 是根据HTTP响应头中的编码指示或者是通过chardet自动检测后赋给requests对象的编码属性。如果服务器报告的编码是ISO-8859-1,则response.encoding会被设置为ISO-8859-1。
3.apparent_encoding的使用
response.apparent_encoding 则是基于requests内部的字符集探测机制得出的编码,即使服务器没有明确指定或指定得不准确,它也会尽量给出一个最佳猜测的编码,这里推测出的是UTF-8-SIG。UTF-8-SIG是一种特殊的UTF-8编码,它前面带有一个BOM(Byte Order Mark),主要用于标记文本文件的开始,表明其采用UTF-8编码且字节顺序是标准的(对于UTF-8来说字节顺序无关紧要,因为它是字节序无关的编码,但BOM仍然可能被用于标识文件类型)。
4.两者之间的区别
response.encoding更倾向于直接使用服务器声明的编码,如果没有则可能依赖于自动检测的结果。response.apparent_encoding是requests库对实际内容做的更为直观的编码判断,通常用于解决服务器提供的编码信息不可靠的情况。
五、总结
如果两个属性返回不同的编码,通常建议优先考虑response.apparent_encoding,因为它可能是网页内容实际使用的编码。当然,在解析网页内容时,最好的做法是先检查和确认编码是否正确,必要时手动调整后再进行解析。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/AllinToyou/article/detail/228787
推荐阅读
相关标签

