
- 1C# Groupby 按年龄段分组实现_c# 计算年龄段分组
- 2vue+element ui 走马灯添加图片+图片自适应_element ui 走马灯嵌套el-image 图片大小自适应
- 3Postgres 数据表文件存储位置_postgresql-15-setup指定数据库数据目录
- 4android studio gradle下载_android studio官网.gradle下载
- 5css画波浪线和齿状线_css 齿纹
- 6uncategorized SQLException; SQL state [99999]; error code [17059]; 无法转换为内部表示; nested exception is j
- 7鸿蒙系统怎么打开纯净模式,#手机[超话]##2021有点东西##OPP... - @安诺颜_ 的微博精选 - 微博国际站...
- 8android 8.0预装APK为可卸载_pms_sysapp_removable_vendor_list
- 9用egg.js实现⼀套⽤户系统的Restful接⼝(思维导图)_eggjs 思维导图
- 10kubernetes实践之八:TLS bootstrapping
学习Linux-4.12内核网路协议栈(2.3)——接口层数据包的接收(下半部)_static_key_false(&ingress_needed)
赞
踩
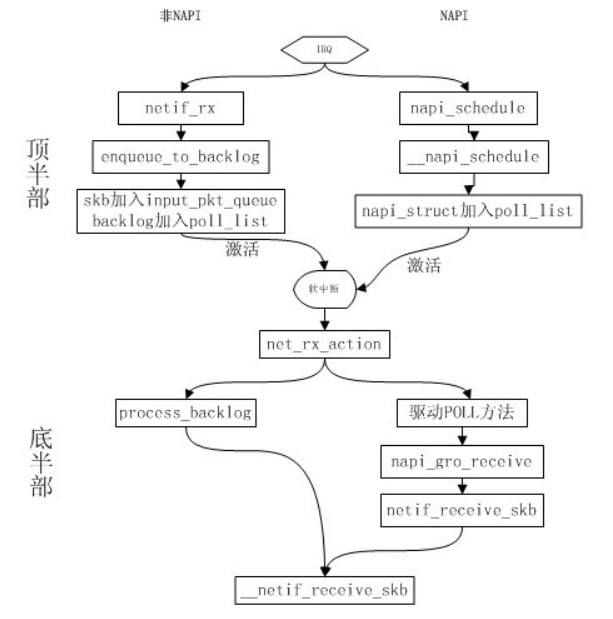
我们来继续分析net_rx_action:
- static __latent_entropy void net_rx_action(struct softirq_action *h)
- {
- struct softnet_data *sd = this_cpu_ptr(&softnet_data);
- unsigned long time_limit = jiffies +
- usecs_to_jiffies(netdev_budget_usecs);
- int budget = netdev_budget; //指定一次软中断处理的skb的数目,这里是300
- LIST_HEAD(list);
- LIST_HEAD(repoll);
-
- local_irq_disable();
- list_splice_init(&sd->poll_list, &list);
- local_irq_enable();
-
- for (;;) {
- struct napi_struct *n;
-
- if (list_empty(&list)) { //检查POLL队列(poll_list)上是否有设备在准备等待轮询
- if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
- goto out;
- break;
- }
-
- n = list_first_entry(&list, struct napi_struct, poll_list);
- budget -= napi_poll(n, &repoll); //调用poll函数从网卡驱动中读取一定数量的skb
-
- /* If softirq window is exhausted then punt.
- * Allow this to run for 2 jiffies since which will allow
- * an average latency of 1.5/HZ.
- */
- if (unlikely(budget <= 0 || //如果读取的数量超过300,则终止中断处理
- time_after_eq(jiffies, time_limit))) {
- sd->time_squeeze++;
- break;
- }
- }
-
- local_irq_disable();
-
- list_splice_tail_init(&sd->poll_list, &list);
- list_splice_tail(&repoll, &list);
- list_splice(&list, &sd->poll_list);
- if (!list_empty(&sd->poll_list)) //如果poll list中不为空,表示还有skb没有读取完成,则继续读取,触发下一次软中断
- __raise_softirq_irqoff(NET_RX_SOFTIRQ);
-
- net_rps_action_and_irq_enable(sd);
- out:
- __kfree_skb_flush();
- }
-

- static int napi_poll(struct napi_struct *n, struct list_head *repoll)
- {
- void *have;
- int work, weight;
-
- list_del_init(&n->poll_list);
-
- have = netpoll_poll_lock(n);
-
- weight = n->weight;
-
- /* This NAPI_STATE_SCHED test is for avoiding a race
- * with netpoll's poll_napi(). Only the entity which
- * obtains the lock and sees NAPI_STATE_SCHED set will
- * actually make the ->poll() call. Therefore we avoid
- * accidentally calling ->poll() when NAPI is not scheduled.
- */
- work = 0;
- if (test_bit(NAPI_STATE_SCHED, &n->state)) {
- work = n->poll(n, weight); //在这里调用驱动的poll函数,如果驱动有支持NAPI,会定义并初始化这个poll函数,默认的poll函数是process_backlog
- trace_napi_poll(n, work, weight);
- }
-
- WARN_ON_ONCE(work > weight);
-
- if (likely(work < weight))
- goto out_unlock;
-
- /* Drivers must not modify the NAPI state if they
- * consume the entire weight. In such cases this code
- * still "owns" the NAPI instance and therefore can
- * move the instance around on the list at-will.
- */
- if (unlikely(napi_disable_pending(n))) {
- napi_complete(n);
- goto out_unlock;
- }
- if (n->gro_list) {
- /* flush too old packets
- * If HZ < 1000, flush all packets.
- */
- napi_gro_flush(n, HZ >= 1000);
- }
-
-
- /* Some drivers may have called napi_schedule
- * prior to exhausting their budget.
- */
- if (unlikely(!list_empty(&n->poll_list))) {
- pr_warn_once("%s: Budget exhausted after napi rescheduled\n",
- n->dev ? n->dev->name : "backlog");
- goto out_unlock;
- }
-
-
- list_add_tail(&n->poll_list, repoll);
-
-
- out_unlock:
- netpoll_poll_unlock(have);
-
-
- return work;
- }
到这里我们知道了poll函数是怎么被调用的,对于非NAPI来说,它的poll函数是process_backlog,最后调用__netif_receive_skb传送给网路层;
对于NAPI来说,它的poll函数是在驱动加载初始化的时候指定的,如果驱动支持GRO,则会在它的poll函数中调用napi_gro_receive()函数进行包的接收与组装,然后调用netif_receive_skb进一步时间戳和RPS的处理,最后调用__netif_receive_skb传送给网路层;
那么接下来分析一下这几个关键函数:
1. process_backlog
- static int process_backlog(struct napi_struct *napi, int quota)
- {
- struct softnet_data *sd = container_of(napi, struct softnet_data, backlog);
- bool again = true;
- int work = 0;
-
- /* Check if we have pending ipi, its better to send them now,
- * not waiting net_rx_action() end.
- */
- if (sd_has_rps_ipi_waiting(sd)) {
- local_irq_disable();
- net_rps_action_and_irq_enable(sd);
- }
-
- napi->weight = dev_rx_weight;
- while (again) {
- struct sk_buff *skb;
-
- while ((skb = __skb_dequeue(&sd->process_queue))) { //从队列头部读取一个skb
- rcu_read_lock();
- __netif_receive_skb(skb); //调用改函数将skb传给网路层
- rcu_read_unlock();
- input_queue_head_incr(sd); //将队列头部往后偏移一个单位
- if (++work >= quota)
- return work;
-
- }
- local_irq_disable();
- rps_lock(sd);
- if (skb_queue_empty(&sd->input_pkt_queue)) { //如果队列为空,表示skb读取完了
- /*
- * Inline a custom version of __napi_complete().
- * only current cpu owns and manipulates this napi,
- * and NAPI_STATE_SCHED is the only possible flag set
- * on backlog.
- * We can use a plain write instead of clear_bit(),
- * and we dont need an smp_mb() memory barrier.
- */
- napi->state = 0; //状态置0并退出读取循环
- again = false;
- } else {
- skb_queue_splice_tail_init(&sd->input_pkt_queue,
- &sd->process_queue);
- }
- rps_unlock(sd);
- local_irq_enable();
- }
-
-
- return work;
- }
2. napi_gro_receive()
它主要是将分片的skb进行组装,然后形成一个skb,请自行了解
linux kernel 网络协议栈之GRO(Generic receive offload)
3. netif_receive_skb()
这个函数没什么内容,主要检测一下时间戳,并对时间戳进行更新,然后确认一下有没有开启RPS功能,如果有则将skb交给对应的cpu处理,他最终还是会调用__netif_receive_skb(skb)将skb传送给网路层
下面用e100网卡来总结一下流程:
neif_rx会调用enqueue_to_backlog 将skb存入softnet_data,并调用____napi_schedule函数。
netif_rx===>netif_rx_internal===>enqueue_to_backlog===>____napi_schedule===>net_rx_action===>process_backlog===>__netif_receive_skb
e100网卡的NAPI调用流程入下:
e100_intr===>__napi_schedule===>net_rx_action===>e100_poll===>e100_rx_clean===>e100_rx_indicate===>netif_receive_skb===>__netif_receive_skb
最后我们来看看接口层数据输入的最后一站:__netif_receive_skb(skb)
它封装了__netif_receive_skb_core
- static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
- {
- struct packet_type *ptype, *pt_prev; //用于操作包类型
- rx_handler_func_t *rx_handler;
- struct net_device *orig_dev; //存放报文的原始设备
- bool deliver_exact = false; //默认接收失败
- int ret = NET_RX_DROP; //默认返回失败
- __be16 type;
-
- net_timestamp_check(!netdev_tstamp_prequeue, skb); //check时间戳,并且会更新skb的时间戳,skb->tstamp
-
- trace_netif_receive_skb(skb);
-
- orig_dev = skb->dev; //将原始的dve做一个备份
-
- skb_reset_network_header(skb); //重置network header,此时skb已经指向IP头(没有vlan的情况下)
- //把L3、L4的头都指向data数据结构,到这里的时候skb已经处理完L2层的头了
- if (!skb_transport_header_was_set(skb))
- skb_reset_transport_header(skb);
- skb_reset_mac_len(skb); //重置mac len
- if (skb_skip_tc_classify(skb)) //是否跳过流量控制分类 ?
- goto skip_classify;
-
-
- if (pfmemalloc)
- goto skip_taps;
-
-
- list_for_each_entry_rcu(ptype, &ptype_all, list) { //把包交给特定协议相关的处理函数前,先调用ptype_all中注册的函数
- //最常见的为tcpdump,该工具就是从这里拿到所有收到的包的,例如raw socket和tcpdump实现
- if (pt_prev)
- ret = deliver_skb(skb, pt_prev, orig_dev); //将包直接传给应用层
- pt_prev = ptype; //pt_prev的加入是为了优化,只有当找到下一个匹配的时候,才执行这一次的回调函数
- }
-
-
- list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) { //设备上注册ptype_all,做相应的处理,更加精细的控制,ptype_all里面包括IP和arp等
- if (pt_prev)
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = ptype;
- }
-
-
- skip_taps:
- #ifdef CONFIG_NET_INGRESS
- if (static_key_false(&ingress_needed)) {
- skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev);
- if (!skb)
- goto out;
-
-
- if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0)
- goto out;
- }
- #endif
- skb_reset_tc(skb);
-
- pt_prev = NULL;
-
- another_round:
- skb->skb_iif = skb->dev->ifindex;
-
- __this_cpu_inc(softnet_data.processed);
-
- if (skb->protocol == cpu_to_be16(ETH_P_8021Q) ||
- skb->protocol == cpu_to_be16(ETH_P_8021AD)) {
- skb = skb_vlan_untag(skb); //去除vlan tag
- if (unlikely(!skb))
- goto out;
- }
- skip_classify:
- if (pfmemalloc && !skb_pfmemalloc_protocol(skb))
- goto drop;
-
-
- if (skb_vlan_tag_present(skb)) { //如果需要将vlan的信息提供给上层,则执行下面的代码
- if (pt_prev) {
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = NULL;
- }
- if (vlan_do_receive(&skb))
- goto another_round;
- else if (unlikely(!skb))
- goto out;
- }
-
-
- rx_handler = rcu_dereference(skb->dev->rx_handler); //设备rx_handler,加入OVS时会注册为OVS的入口函数
- if (rx_handler) {
- if (pt_prev) {
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = NULL;
- }
- switch (rx_handler(&skb)) { //执行rx_handler处理,例如进入OVS,OVS不支持报头中携带vlan的报文
- case RX_HANDLER_CONSUMED:
- ret = NET_RX_SUCCESS;
- goto out;
- case RX_HANDLER_ANOTHER:
- goto another_round;
- case RX_HANDLER_EXACT:
- deliver_exact = true;
- case RX_HANDLER_PASS:
- break;
- default:
- BUG();
- }
- }
-
-
- if (unlikely(skb_vlan_tag_present(skb))) {
- if (skb_vlan_tag_get_id(skb))
- skb->pkt_type = PACKET_OTHERHOST;
- /* Note: we might in the future use prio bits
- * and set skb->priority like in vlan_do_receive()
- * For the time being, just ignore Priority Code Point
- */
- skb->vlan_tci = 0;
- }
-
-
- type = skb->protocol;
-
-
- /* deliver only exact match when indicated */
- if (likely(!deliver_exact)) {
- deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, //根据全局定义的协议处理报文
- &ptype_base[ntohs(type) &
- PTYPE_HASH_MASK]);
- }
-
-
- deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, //根据设备上注册的协议进行处理
- &orig_dev->ptype_specific);
-
-
- if (unlikely(skb->dev != orig_dev)) {
- deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, //如果设备发生变化,那么还需要针对新设备的注册协议进行处理
- &skb->dev->ptype_specific);
- }
-
-
- if (pt_prev) {
- if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC)))
- goto drop;
- else
- ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev); //调用协议处理
- } else {
- drop:
- if (!deliver_exact)
- atomic_long_inc(&skb->dev->rx_dropped);
- else
- atomic_long_inc(&skb->dev->rx_nohandler);
- kfree_skb(skb);
- /* Jamal, now you will not able to escape explaining
- * me how you were going to use this. :-)
- */
- ret = NET_RX_DROP;
- }
-
-
- out:
- return ret;
- }
上面的代码可能看着不是很清晰,可能会有疑问:就这几个指针是怎么实现将数据包从接口层往网络层传递的呢?其实主要原因是对ptype_base和ptype_all这两个对象的印象不够直观,我们接下来着看这两个对象的组成就明白了:
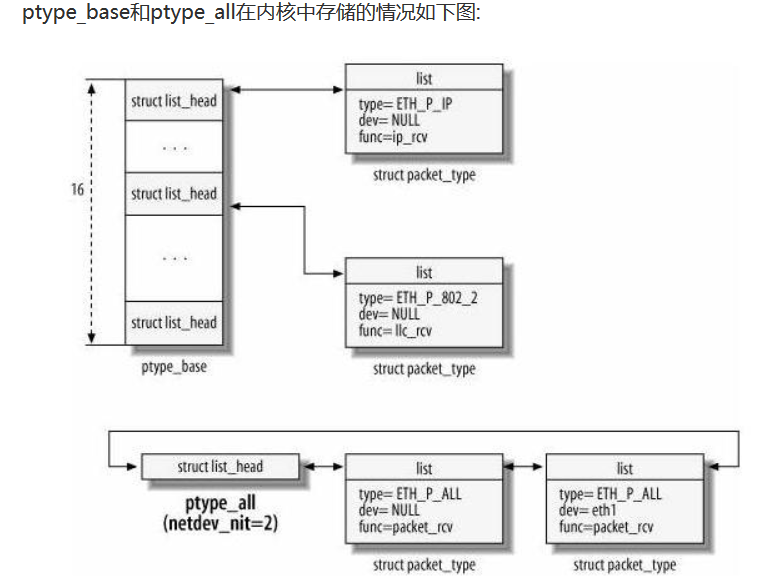
从图中可以看到,ptype_all是一个链表,这个链表里面最大的区别是func=packet_rcv,也就是说,这个链表往往是提供给一些抓包程序使用的,比如tcp_dump,它可以不区分包的类型而将所有的包的抓取过来,它的统一处理函数都是packet_rcv,在这里面可以对一些过滤选项进行处理。对象中的type一般使用的是以太网类型,而dev表示在哪个接口上抓包。
但是ptype_base则是一个哈希表,注意这个表是以type来进行分类的,比如ip协议可以指定不同的dev接口,但是他们都在同一张表上。不同的协议类型对应了不同的接收函数,比如IP报文的接收函数是ip_rcv, 802.2对应的是llc_rcv等。总的来说,报文从网卡驱动里面上来以后,第一次在这里进行分流,不同的报文类型交给不同的协议处理函数进行处理(我们这里暂时先不考虑桥接)。
到这里就结束了数据包从驱动接收,然后通过接口层传送给网路层的过程。后面的文章将介绍一个报文怎么在网络层通过接口层传送给网卡驱动。

