
热门标签
热门文章
- 1【华为云技术分享】基于小熊派STM32芯片的通过MQTT上报JSON数据到华为物联网平台的自动售货机Demo解析_stm32 mqtt json post
- 2支付系统的防重设计
- 3arcmap中添加多个字段_arcgis批量添加字段
- 4Unity协程的定义、使用及原理,与线程的区别、缺点全方面解析_unity线程和协程有什么区别
- 5解决nRF Connect for PC无法连接网络的问题(非翻墙)_鈥減c-nrfconnect-programmer-1.4.4.tgz
- 6个人专属chatGpt使用,只需要2步_如何免费搭建使用chatgpt
- 7STM32F103通过ESP8266WIFI使用TCP透传协议连接至移动ONENET实现远程控制LED灯_stm32f103使用esp8266模块实现tcp透传
- 8nginx的初次学习_nginx 前缀dev-api
- 9Android第二讲笔记(约束布局ConstraintLayout)_layout_constrainttop_totopof
- 10Python小游戏自己动手编写,你能写出几个(分享版)_python编写的入门简单小游戏
当前位置: article > 正文
各维度 特征 重要程度 随机森林_机器学习技法10-(随机森林)
作者:2023面试高手 | 2024-03-15 05:53:01
赞
踩
随机森林特征选择重要性单位
一.Random Forest Algorithm
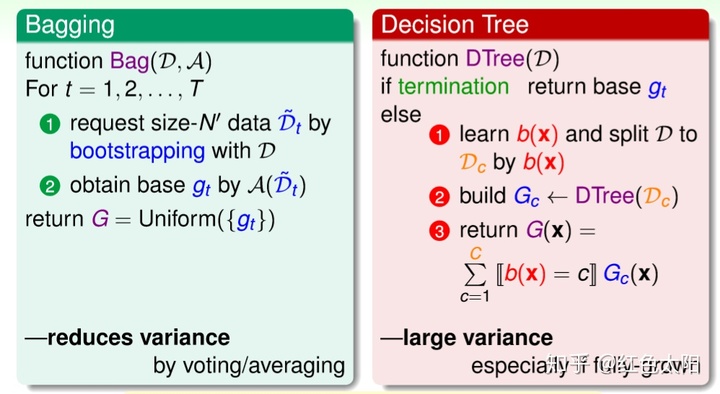
在Bagging中,我们采用bootstrapping来将原始数据集D生成一些不同的数据集,然后用基算法A来训练这些不同的数据集得到不同的g,然后采用投票的方式得到最后的模型G。
在决策树中,我们采用分切策略b(x)来切割数据集,然后构建许多小树,最终得到一颗大树。
在Bagging中,算法能减少不同g的方差;在决策树中,由于每次切割的方式不同,而且分支包含的样本数在逐渐减少,所以它对不同的数据集会比较敏感,从而不同的数据集会得到比较大的方差。
因此我们可以结合Bagging和决策树的特别将两个算法聚合起来,从而得到了随机森林。

随机森林的优点:
- 不同决策树可以由不同主机并行训练生成,效率很高;
- 随机森林算法继承了C&RT的优点;
- 将所有的决策树通过bagging的形式结合起来,避免了单个决策树造成过拟合的问题。
在Bagging中,我们通过操作数据集从而实现了数据的随机性,因此得到的g具有差异性。其实还有其他的做法,对样本的特征进行操作就是一个方法。
具体做法:随机抽取一部分特征。

假设原来样本维度是d,则只选择其中的
增强的随机森林算法是将决策树算法作为基算法,并且加入了随机子空间,最终得到了很多具有差异的g,最后将些g聚合,因此可以认为增强的随机森林算法是bagging加入了随机子空间。

另一种使得子特征具有多样性的方法,将原始特征x乘上一个投影矩阵

二.Out-Of-Bag Estimate

在Bagging中,我们采用bootstrapping来生成具有差异性的许多数据集ÿ
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/239171
推荐阅读
相关标签

