
- 1win10设置右键以管理员方式运行cmd_右键以管理员运行和设置管理员运行
- 2超级方便的多系统启动U盘_多系统u盘
- 3【開山安全笔记】文件上传漏洞_文件上传漏洞后缀白名单绕过
- 4第四章——运算符重载运算课后练习题_c++程序设计04737第四章运算符重载习题
- 52024 最新最全大数据毕业设计选题推荐 选题指导_大数据专业毕设选题
- 6Qt中使用RabbitMQ-c(一):使用CMake + MinGW编译RabbitMQ-c_qt rabbitmq-c
- 73年经验来面试20K的自动化测试岗,一问都不会,还不如去招应届生!_不会自动化测试可以投自动化测试岗位吗
- 8白盒测试代码总结
- 9win11 如何把微软账户切换成administrator_win11切换administrator账户
- 102021年高压电工考试APP及高压电工找答案_移动电气设备的电源线单相用三芯电缆,三相用四芯电缆
FLINK 与翼flink-StreamPark实例_翼-flink streampark
赞
踩
FLINK 与翼flink-StreamPark实例
介绍
Flink是一个大数据流处理引擎,可以为不同行业提供实时大数据处理解决方案。随着Flink的快速发展和改进,世界各地的许多公司现在都能看到它的存在。目前,北美、欧洲和金砖国家都是全球Flink应用的热门地区。当然,Flink在中国的知名度特别高,部分原因是一些互联网大厂的贡献和引领效应,也符合中国的反应与场景密切相关。想象一下,在中国,一个网站可能需要面对数以亿计的日活跃用户和每秒数亿的计算峰值,这对许多外国公司来说是难以想象的。Flink为我们提供了高速准确处理海量流媒体数据的可能性。
在目前的云原生时代,容器化、K8S等技术已经在各个互联网大厂中独占鳌头,大部分的应用已经实现了上云。对于大数据引擎家族中的一员,flink实现与K8S结合、实现云原生下的severless模式的需求日渐增加,。因此,在本文中,主要为实现面对云原生+flink进行讲解,希望能够给读者带来获得新知识的喜悦。
在这里,将会提供flink的使用方法,和一个flink可视化平台StreamPark中的使用方式。本实例实时更新,将依次介绍其中各个方式的使用方法。在这里将会涉及以下知识点:
- DataStreamApi的使用
- UDF的开发
- FlinkSql的使用
- Flink cdc功能
- 原生flink k8s application的使用
- 翼flink-StreamPark的使用要点
文章目录
基础环境
在本文中,将面向开发程序员、面向一线码农,带来最详细的flink教程。从基础环境搭建到最后的平台应用均会涉及。
对于flink而言,少不了对流式数据的处理,一般而言面对kafka、rabbitmq、cdc等消息为数据源主流,在这里,为简化基础环境搭建流程,将提供mysql数据源并开启binlog模式作为我们的数据源,实现流(CDC功能接入binlog)批(常规查询)一体的输入。
数据源搭建
在本文中,我们使用mysql作为数据源,并开启binlog作为流数据作为本实例中的数据源。在这里首先需要安装一个docker运行mysql容器,已实现统一基础环境。
# 移除掉旧的版本 sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-selinux \ docker-engine-selinux \ docker-engine # 删除所有旧的数据 sudo rm -rf /var/lib/docker # 安装依赖包 sudo yum install -y yum-utils \ device-mapper-persistent-data \ lvm2 # 添加源,使用了阿里云镜像 sudo yum-config-manager \ --add-repo \ http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo # 配置缓存 sudo yum makecache fast # 安装最新稳定版本的docker sudo yum install -y docker-ce # 配置镜像加速器 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["http://hub-mirror.c.163.com"] } EOF # 启动docker引擎并设置开机启动 sudo systemctl start docker sudo systemctl enable docker # 配置当前用户对docker的执行权限 sudo groupadd docker sudo gpasswd -a ${USER} docker sudo systemctl restart docker
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
完成docker的安装后,可以执行如下命令,实现mysql的安装
docker run -p 3307:3306 --name myMysql -v /mydata/mysql/log:/var/log/mysql -v /mydata/mysql/data:/var/lib/mysql -v /mydata/mysql/conf:/etc/mysql -e MYSQL_ROOT_PASSWORD=***** -d mysql:5.7.25
- 1
注意这里我们建议开启mysql的binlog功能,供我们后续的CDC功能的使用,因此在启动后需修改mysql的配置文件
修改my.cnf文件
[mysqld]
log-bin=/var/lib/mysql/mysql-bin
server-id=123654
expire_logs_days = 30
- 1
- 2
- 3
- 4
之后重启容器
docker restart myMysql
- 1
构键k8s集群
-
在这里,我们需要搭建一个K8S环境用于提供flink任务的运行时环境。在这里推荐使用kubeadm或者一些脚本工具搭建https://gitlab.ctyuncdn.cn/liuxy28/kube-minite/-/tree/x86_64。具体过程在这里省略,可以参考上述链接中的文档进行操作。
-
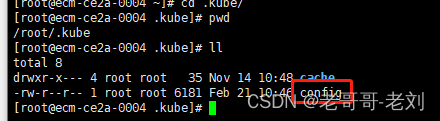
需要注意的是,我们需要在相应用户的目录下提供一个kubeconfig文件,如下图所示,通过该文件,StreamPark才能顺利地调用K8S客户端提交任务,该config的内容为与K8S的ApiServer进行连接时需要使用的信息。
下载flink客户端
flink客户端是控制flink的核心,需要下载并部署
wget https://archive.apache.org/dist/flink/flink-1.14.3/flink-1.14.3-bin-scala_2.12.tgz
tar -xf flink-1.14.3-bin-scala_2.12.tgz
- 1
- 2
提供flink运行任务的环境
-
将kubeconfig提供出来,供flink客户端调用,在这里要保证我们使用的客户端时,我们的用户下拥有kubeconfig文件
-
在这里主要提供一个供flink使用的命名空间、和SA。在K8S Application模式下,service acount(SA)是flink的jobmanager使用的服务账号,jobmanager以此来获得启动相应的taskamanager的权限
# 创建namespace kubectl create ns flink-dev # 创建serviceaccount kubectl create serviceaccount flink-service-account -n flink-dev # 用户授权 kubectl create clusterrolebinding flink-role-binding-flink --clusterrole=edit --serviceaccount=flink-dev:flink-service-account- 1
- 2
- 3
- 4
- 5
- 6
DataStreamApi
dataStreamApi是一切的基础,处于调度flink程序处理任务的起点。Flink 有非常灵活的分层 API 设计,其中的核心层就是 DataStream/DataSet API。由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。因此在这里我们统称为DataStream Api。
首先在这里我们需要新建一个项目,并使用maven管理版本、依赖。其中pom文件如下所示:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.ctyun</groupId> <artifactId>flink-demo-jar-job</artifactId> <version>1.0-SNAPSHOT</version> <properties> <flink.version>1.13.0</flink.version> <java.version>1.8</java.version> <scala.binary.version>2.12</scala.binary.version> <slf4j.version>1.7.30</slf4j.version> <flink.sql.connector.cdc.version>2.2.1</flink.sql.connector.cdc.version> </properties> <dependencies> <!-- 引入Flink相关依赖--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.bahir</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <!-- <dependency>--> <!-- <groupId>mysql</groupId>--> <!-- <artifactId>mysql-connector-java</artifactId>--> <!-- <version>8.0.27</version>--> <!-- </dependency>--> <!-- flink connector cdc --> <dependency> <groupId>com.ververica</groupId> <artifactId>flink-connector-mysql-cdc</artifactId> <version>${flink.sql.connector.cdc.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.80</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId> <version>1.13.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-csv</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-cep_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <!-- 引入日志管理相关依赖--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.14.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.5</version> <scope>provided</scope> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.0</version> <configuration> <source>${java.version}</source> <target>${java.version}</target> <encoding>UTF-8</encoding> </configuration> </plugin> </plugins> </build> </project>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
之后,我们可以在此基础上完成我们的flink任务的编码。
整套DataStream的流程无外乎以下几步,关于具体的使用,本章节会在代码中通过注释的方式标出来每一步的具体代码:
- 获取执行环境
- 读取数据源,一般称为source操作
- 定义数据转换流程,一般称之为transformations,我们经常听到的map reduce流程就是在这一步
- 定义结果输出,一般称为sink操作
- 最终触发程序的执行,一般称之为execute操作
MAP-REDUCE流程
Map-Reduce是大数据领域中十分传统的流程之一。和Hadoop MapReduce相似,flink中也需要对其中的Map、Reduce、Shuffle、Aggregate等接口进行实现,以供flink在运行时能够调用。
对于flink而言,其开发方法主要以实现各种Function接口为主来定义各种算子。对于Java 1.8后的版本,支持通过Lambda的方式进行代码,大量的代码使用函数式编程。
一般而言,map顾名思义代表了映射,是从一条数据到另一条或几条的映射操作,reduce代表了“减少”、“规约”是将数据从多条到一条的统计操作。通过两个操作的结合,即可实现简单的统计操作。以下将给出一个案例。
数据输入
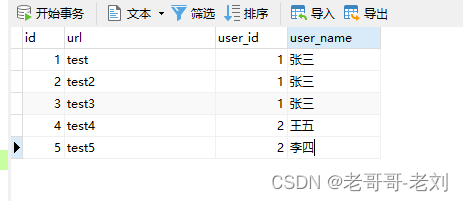
在这里我们首先创建一个数据源,通过和先前建立的mysql数据源取得交互后进行运行以下sql脚本
/* Navicat Premium Data Transfer Source Server : 原生mysql专用于cdc Source Server Type : MySQL Source Server Version : 50725 Source Host : ****** Source Schema : test_cdc_source Target Server Type : MySQL Target Server Version : 50725 File Encoding : 65001 Date: 24/04/2023 14:23:19 */ SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for view_content -- ---------------------------- DROP TABLE IF EXISTS `view_content`; CREATE TABLE `view_content` ( `id` int(11) NOT NULL, `url` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL, `user_id` int(11) NULL DEFAULT NULL, `user_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
在完成数据源初始化后,我们建立一个数据源的输入类,作为DataStreamApi格式的数据源输入,如下所示:
package cn.ctyun.demo.api.watermark; import cn.ctyun.demo.api.utils.TransformUtil; import com.alibaba.fastjson.JSONObject; import com.ververica.cdc.connectors.mysql.source.MySqlSource; import com.ververica.cdc.connectors.mysql.table.StartupOptions; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.time.Duration; /** * @classname: ViewContentStreamWithoutWaterMark * @description: 浏览记录数据源不包含水位线 * @author: Liu Xinyuan * @create: 2023-04-14 13:47 **/ public class ViewContentStreamWithoutWaterMark { public static DataStream<JSONObject> getViewContentDataStream(StreamExecutionEnvironment env){ // 1.创建Flink-MySQL-CDC的Source MySqlSource<String> viewContentSouce = MySqlSource.<String>builder() .hostname("******") .port(3306) .username("******") .password("******") .databaseList("test_cdc_source") .tableList("test_cdc_source.user_view") .startupOptions(StartupOptions.initial()) .deserializer(new JsonDebeziumDeserializationSchema()) .serverTimeZone("Asia/Shanghai") .build(); // 2.使用CDC Source从MySQL读取数据 DataStreamSource<String> mysqlDataStreamSource = env.fromSource( viewContentSouce, WatermarkStrategy.noWatermarks(), "ViewContentStreamNoWatermark Source" ); // 3.转换为指定格式 return mysqlDataStreamSource.map(TransformUtil::formatResult); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
这里有一个针对CDC的数据转换工具类,需要在您的项目中一同定义:
package cn.ctyun.demo.api.utils; import cn.ctyun.demo.api.enums.OpEnum; import com.alibaba.fastjson.JSONObject; /** * @classname: TransformUtil * @description: 转换工具类 * @author: Liu Xinyuan * @create: 2023-04-14 09:44 **/ public class TransformUtil { /** * 格式化抽取数据格式 * 去除before、after、source等冗余内容 * * @param extractData 抽取的数据 * @return */ public static JSONObject formatResult(String extractData) { JSONObject formatDataObj = new JSONObject(); JSONObject rawDataObj = JSONObject.parseObject(extractData); formatDataObj.putAll(rawDataObj); formatDataObj.remove("before"); formatDataObj.remove("after"); formatDataObj.remove("source"); String op = rawDataObj.getString("op"); if (OpEnum.DELETE.getDictCode().equals(op)) { // 新增取 before结构体数据 formatDataObj.putAll(rawDataObj.getJSONObject("before")); } else { // 其余取 after结构体数据 formatDataObj.putAll(rawDataObj.getJSONObject("after")); } return formatDataObj; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
完成如上操作后,我们即能够拥有一个标准的流式输入,之后的相关开发可以以此作为基础。
MapReduce流程UDF算子开发
上文中说到,flink中的开发主要是对各种编程接口进行实现,已达到自己的业务需求。对于一个mapreduce任务而言,自然需要实现如下几个接口的实现
- MapFunction接口:用于实现数据的转换,将一条数据进行一定规则的映射
- KeySelector接口:用于通过将数据按键统计,将相同的键值下的数据放到一块统计
- ReduceFunction接口:用于将多条数据合并成一条,一般用于将数据进行规约形成统计值
在这里,将提供一个用于统计用户访问量的案例,复用上文提供的数据源方案,进行用户的访问数据量统计。在这里,我们实现了以上一套接口的实现,达到了我们业务流程,整个接口的实现如下所示:
- 这里,我们首先实现了map接口,将一条数据的输入简单地将一条访问记录映射成了二元组(当前用户名, 1),这样表示为将一条用户登录信息映射成了一个人来了1次
- 之后我们实现了一个KeySelector接口,这个接口主要将不同数据进行分组处理,在本实例中,我们将相同用户名的数据分为一个组,供后续统计处理
- 最后地,实现了ReduceFunction接口,将多条数据映射成一条。
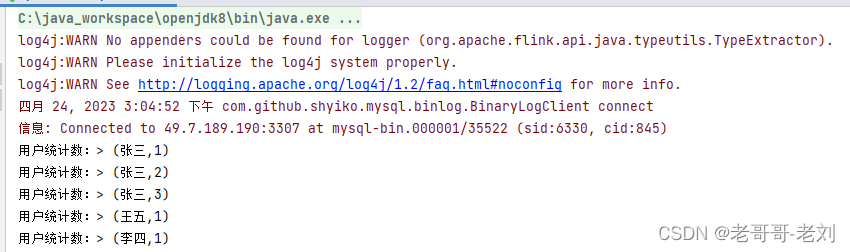
package cn.ctyun.demo.api; import cn.ctyun.demo.api.watermark.ViewContentStreamWithoutWaterMark; import com.alibaba.fastjson.JSONObject; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @classname: ApiNormalMapReduce * @description: 标准MapReduce流程 * @author: Liu Xinyuan * @create: 2023-04-24 14:29 **/ public class ApiNormalMapReduce { public static void main(String[] args) throws Exception { // 1.获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 2.读取数据源(source) DataStream<JSONObject> viewContentDataStream = ViewContentStreamWithoutWaterMark.getViewContentDataStream(env); // 3.定义数据转换操作(transformations) SingleOutputStreamOperator<Tuple2<String, Long>> reduce = viewContentDataStream.map(new CountUserToOneMap()) .keyBy(new CountUserKeySelector()) .reduce(new CountUserReduceFunction()); // 4.定义计算结果的输出(sink) reduce.print("用户统计数:"); // 5.最终程序的执行(execute) env.execute(); } public static class CountUserToOneMap implements MapFunction<JSONObject, Tuple2<String, Long>> { /** * * @param value 输入数据 * @return 转换后的数据 * @throws Exception 异常 */ @Override public Tuple2<String, Long> map(JSONObject value) throws Exception { return Tuple2.of(value.getString("user_name"), 1L); } } public static class CountUserKeySelector implements KeySelector<Tuple2<String, Long>, String>{ /** * * @param value 输入的数据样式 * @return 输入数据样式中的键 * @throws Exception 异常 */ @Override public String getKey(Tuple2<String, Long> value) throws Exception { return value.f0; } } public static class CountUserReduceFunction implements ReduceFunction<Tuple2<String, Long>>{ /** * * @param value1 上一条数据 * @param value2 新的数据 * @return 两条数据合并后的结果 * @throws Exception */ @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { return Tuple2.of(value1.f0, value1.f1 + value2.f1); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
按照如下步骤添加数据后,flink能够根据之前的统计值进行统计,当数据输入时,实时获取当前用户的访问数量。以此,我们实现了一个简单的MapReduce流程。
聚合函数的使用
直观地说,基本的转换运算符确实在“转换”——因为它们都是基于当前数据并经过处理的以及输出。在实际应用中,我们经常需要统计或整合大量数据,以提取更有用的数据信息。在之前的实例中,我们进行了统计用户的访问数量的操作,在程序运行时需要对每个访问记录进行叠加和计数。此操作计算结果不仅依赖于当前数据,还与以前的数据有关,这相当于将所有数据聚合并合并在一起–这被称为“聚合”,也对应于MapReduce中的reduce操作。
在先前的实例中,我们使用过KeyBy功能,将不同的数据按键进行分区。 KeyBy是一个运算符,必须在聚合之前使用。KeyBy可以通过指定一个键在逻辑上将流划分为不同的分区。这里提到的分区实际上是并行处理的一个子任务,它对应于一个任务槽(taskSlots)。根据不同的密钥,流中的数据将被分配到不同的分区;这样,所有具有相同密钥的数据都将被发送到同一个分区,之后,其对应的后续操作将会在特定的分区进行,实现对这一组数据的统一处理。
一般地,在经过按键聚合后,可以调用flink提供的内置简单聚合函数进行操作,如下所示:
-
sum():对指定的字段做叠加求和的操作。
-
min():对指定的字段求最小值。
-
max():对指定的字段求最大值。
-
minBy():对指定字段求最小值。不同的是,min()只计算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包
含字段最小值的整条数据。 -
maxBy():对指定字段求最大值。
在这里,我们提供一个案例,将上述代码进行验证,同样地,其输入数据源为mysql cdc
package cn.ctyun.demo.api; import cn.ctyun.demo.api.watermark.ViewContentStreamWithoutWaterMark; import com.alibaba.fastjson.JSONObject; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @classname: ApiNormalAggregate * @description: 简单聚合函数的使用 * @author: Liu Xinyuan * @create: 2023-04-25 15:24 **/ public class ApiNormalAggregate { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStream<JSONObject> viewContentDataStream = ViewContentStreamWithoutWaterMark.getViewContentDataStream(env); KeyedStream<Tuple2<String, Long>, String> tuple2StringKeyedStream = viewContentDataStream.map(new CountUserToOneMap()) .keyBy(new CountUserKeySelector()); tuple2StringKeyedStream.sum(1).print("按用户名进行sum"); tuple2StringKeyedStream.min(1).print("按用户名进行min"); tuple2StringKeyedStream.max(1).print("按用户名进行max"); tuple2StringKeyedStream.minBy(1).print("按用户名进行minBy"); tuple2StringKeyedStream.maxBy(1).print("按用户名进行maxBy"); env.execute(); } public static class CountUserToOneMap implements MapFunction<JSONObject, Tuple2<String, Long>> { /** * * @param value 输入数据 * @return 转换后的数据 * @throws Exception 异常 */ @Override public Tuple2<String, Long> map(JSONObject value) throws Exception { return Tuple2.of(value.getString("user_name"), 1L); } } public static class CountUserKeySelector implements KeySelector<Tuple2<String, Long>, String>{ /** * * @param value 输入的数据样式 * @return 输入数据样式中的键 * @throws Exception 异常 */ @Override public String getKey(Tuple2<String, Long> value) throws Exception { return value.f0; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
需要注意的是,其这些简单聚合函数只适用于Tuple类型、Scala事例类和基元类型或者是简单的POJO类,这就对我们输入这个算子的格式有一定的要求。在下一章节中,将会继续讲解如何自定义一个这样的聚合函数(AggregateFunction),面对复杂的应用场景。
富函数的使用
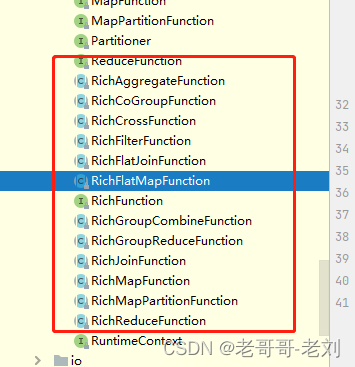
在flink中,对不同的算子提供了一个Rich的版本(富函数),比如RichMapFunction、RichReduceFunction等。这类函数一般比常规函数具有更多功能,比如其可以获取运行环境的上下文、拥有着自己的生命周期。一般地,其生命周期在与数据库连接、任务状态保持功能中非常重要,与数据库连接的数据源功能一般都会使用富函数对连接状态进行保持。
我们在富函数时,一般需要实现一系列的算子抽象类,如下所示,此类API对应为先前的非富类型的算子,并提供有状态编程模式:
我们假定一个场景,在这个场景中,我们需要在一个MAP方法使用时打印其分片名,如下所示:
package cn.ctyun.demo.api; import cn.ctyun.demo.api.watermark.ViewContentStreamWithoutWaterMark; import com.alibaba.fastjson.JSONObject; import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * @classname: ApiNormalRichFunction * @description: 富函数的使用 * @author: Liu Xinyuan * @create: 2023-04-25 16:02 **/ public class ApiNormalRichFunction { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(10); DataStream<JSONObject> viewContentDataStream = ViewContentStreamWithoutWaterMark.getViewContentDataStream(env); SingleOutputStreamOperator<String> map = viewContentDataStream.map(new TimeStampRichMapFunction()); map.print("用户访问的url为:"); env.execute(); } public static class TimeStampRichMapFunction extends RichMapFunction<JSONObject, String>{ /** * 该map方法和MapFunction的类似,使用方法一致 * @param value 输入的数据 * @return * @throws Exception */ @Override public String map(JSONObject value) throws Exception { return value.getString("url"); } /** * 这里重写了AbstractRichFunction方法的open方法,用于在方法启用时执行一定的功能 * @param parameters flink的配置项 * @throws Exception */ @Override public void open(Configuration parameters) throws Exception { super.open(parameters); System.out.println("索引为 " + getRuntimeContext().getIndexOfThisSubtask() + " 的任务开始"); } /** * 关闭时执行的方法 * @throws Exception */ @Override public void close() throws Exception { super.close(); System.out.println("索引为 " + getRuntimeContext().getIndexOfThisSubtask() + " 的任务结束"); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
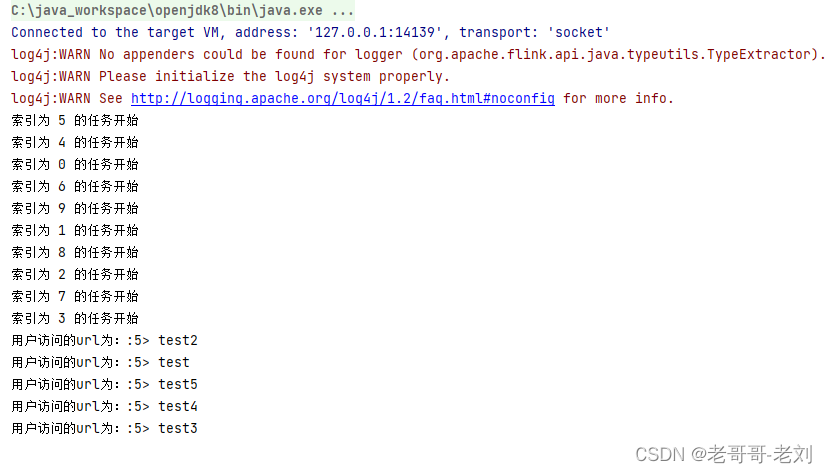
可知的是,富函数启动后,flink框架将首先调用open方法,在这里我们的open方法提供了打印索引号的功能,在这里一般可以感知到我们flink的启动配置项(flinkConfig)。其他的,map方法和普通的MapFunction方法类似。
水位线与窗口
对于流式数据,时间是一个重要的标识。在flink的事件时间语义下,我们不依赖系统时间,而是基于数据自带的时间戳去定义了一个时钟,用来表示当前时间的进展。于是每个并行子任务都会有一个自己的逻辑时钟,它的前进是靠数据的时间戳来驱动的。
但在分布式系统中,这种驱动方式又会有一些问题。因为数据本身在处理转换的过程中会变化,如果遇到窗口聚合这样的操作,其实是要攒一批数据才会输出一个结果,那么下游的数据就会变少,时间进度的控制就不够精细了。
所以我们应该把时钟也以数据的形式传递出去,告诉下游任务当前时间的进展;而且这个时钟的传递不会因为窗口聚合之类的运算而停滞。一种简单的想法是,在数据流中加入一个时钟标记,记录当前的事件时间;这个标记可以直接广播到下游,当下游任务收到这个标记,就可以更新自己的时钟了。由于类似于水流中用来做标志的记号,在 Flink 中,这种用来衡量事件时间(Event Time)进展的标记,就被称作“水位线”(Watermark)。
水位线设置
这里我们将通过mysql-cdc来生成一个水位线,我们在读取数据源的一侧进行设置。(代码请见cn/ctyun/demo/api/watermark/ViewContentStreamWithWaterMark.java)
package cn.ctyun.demo.api.watermark; import cn.ctyun.demo.api.utils.TransformUtil; import com.alibaba.fastjson.JSONObject; import com.ververica.cdc.connectors.mysql.source.MySqlSource; import com.ververica.cdc.connectors.mysql.table.StartupOptions; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.time.Duration; /** * @classname: ViewContentStreamWithWaterMark * @description: 拥有水位线的浏览信息源表 * @author: Liu Xinyuan * @create: 2023-04-14 09:50 **/ public class ViewContentStreamWithWaterMark { public static DataStream<JSONObject> getViewContentDataStream(StreamExecutionEnvironment env){ // 1.创建Flink-MySQL-CDC的Source MySqlSource<String> viewContentSouce = MySqlSource.<String>builder() .hostname("***") .port(3306) .username("***") .password("***") .databaseList("test_cdc_source") .tableList("test_cdc_source.user_view") .startupOptions(StartupOptions.initial()) .deserializer(new JsonDebeziumDeserializationSchema()) .serverTimeZone("Asia/Shanghai") .build(); // 2.使用CDC Source从MySQL读取数据 DataStreamSource<String> mysqlDataStreamSource = env.fromSource( viewContentSouce, WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(1L)).withTimestampAssigner( new SerializableTimestampAssigner<String>() { @Override public long extractTimestamp(String extractData, long l) { return JSONObject.parseObject(extractData).getLong("ts_ms"); } } ), "ViewContentStreamWithWatermark Source" ); // 3.转换为指定格式 return mysqlDataStreamSource.map(TransformUtil::formatResult); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
我们在cdc传来的数据中获取他的日志自带更新时间戳字段ts_ms时间戳作为我们的事件时间,并生成水位线,伺候此数据流将包含水位线进行后续地传递。
窗口设置
在窗口中,有着不同的设置,可以面对不同的场景。我们按照数据不同的分配规则,将窗口的具体实现分为了以下四种,如下所示:
-
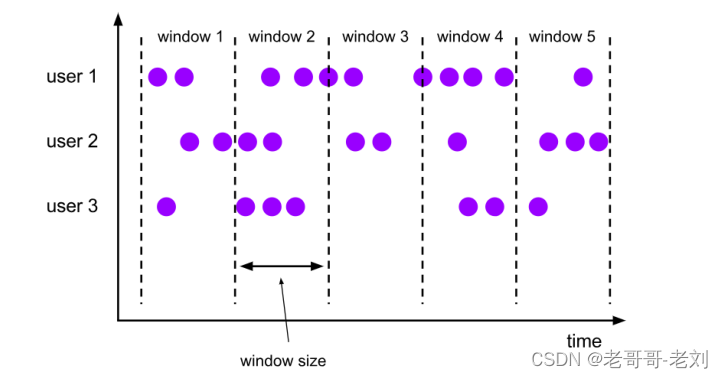
滚动窗口(Tumbling Windows):滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动,就好像它在不停地向前“翻滚”一样。这是最简单的窗口形式,我们之前所举的例子都是滚动窗口。也正是因为滚动窗口是“无缝衔接”,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。滚动窗口也是在BI分析中最常用的窗口类型之一。
-
滑动窗口(Sliding Windows ):与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。所以定义滑动窗口的参数有两个:窗口大小(window size)定义了窗口的大小,还有一个“滑动步长”(window slide),代表了窗口计算的频率。
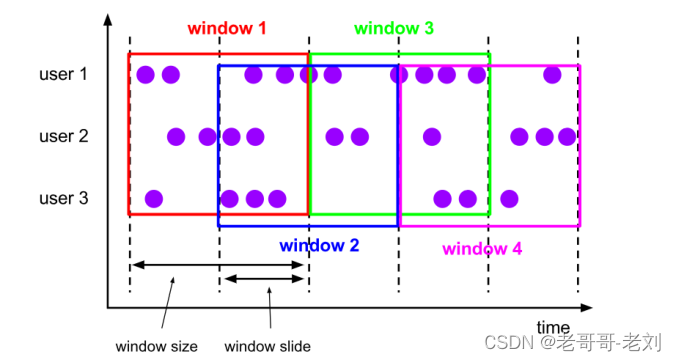
举个例子,比如我们定义的窗口长度为 1 小时、滑动步长为 30 分钟,那么对于 8 点 55 分的数据,应该同时属于[8 点, 9 点)和[8 点半, 9 点半)两个窗口;而对于 8 点 10 分的数据,则同时属于[8点, 9 点)和[7 点半, 8 点半)两个窗口。
-
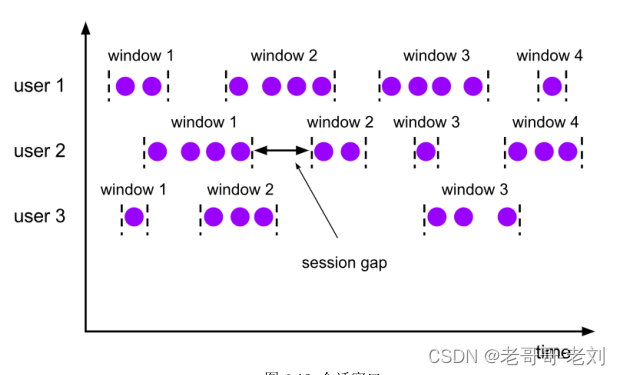
会话窗口(Session Windows):会话窗口顾名思义,是基于“会话”(session)来来对数据进行分组的。这里的会话类似Web 应用中 session 的概念,不过并不表示两端的通讯过程,而是借用会话超时失效的机制来
描述窗口。简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。一般而言将会给数据设置一个超时时间,如果两个数据间间隔过长并大于超时时间。在这里所有能够控制的就是超时时间(gap),其作为判定新窗口开启的一个重要指标。
- 全局窗口(Session Windows):这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中;无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。如果希望它能对数据进行计算处理,还需要自定义“触发器”(Trigger)。
窗口API
窗口操作主要有两个部分:窗口分配器(Window Assigners)和窗口函数(Window Functions)
窗口函数MapReduce
在这里,我们首先定义一个MapReduce过程,用来统计目前十秒内的用户访问统计数量,这里的水位线设定请参考代码ViewContentStreamWithWaterMark,具体的MapReduce如下所示
package cn.ctyun.demo.api; import cn.ctyun.demo.api.watermark.ViewContentStreamWithWaterMark; import com.alibaba.fastjson.JSONObject; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; /** * @classname: ApiTimeWindow * @description: 时间窗的使用 * @author: Liu Xinyuan * @create: 2023-04-17 20:39 **/ public class ApiTimeWindow { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStream<JSONObject> viewContentDataStream = ViewContentStreamWithWaterMark.getViewContentDataStream(env); viewContentDataStream.filter(new FilterFunction<JSONObject>() { @Override public boolean filter(JSONObject value) throws Exception { // 不将删除的数据考虑在内 return !value.getString("op").equals("d"); } }).map(new MapFunction<JSONObject, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(JSONObject value) throws Exception { return Tuple2.of(value.getString("user_name"), 1L); } }).keyBy(r -> r.f0) .window(TumblingEventTimeWindows.of(Time.seconds(10))) .reduce(new ReduceFunction<Tuple2<String, Long>>() { @Override public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception { // 设定一个累加规则,用于合并userid的用户信息统计数量,当窗口闭合后将发送累加结果 return Tuple2.of(value1.f0, value1.f1 + value2.f1); } }).print(); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
这里设定了一个时间窗口为10秒,最终的结果为每十秒钟将统计一个登录统计,并输出到控制台。使用时间窗口后和不加的唯一区别是计算的范围变为了时间窗内计算。
窗口函数Aggregate
对于窗口下的数据统计,可以通过aggregate方法进行时间窗内的数据统计,这里给出一个计算用户活跃度的一套代码,用于每三十秒统计用户的活跃度。这里就将实现AggregateFunction接口,自定义一个满足业务要求的聚合函数.
在这里需要实现一个接口AggregateFunction创建累加器用于记录信息。具体代码请见如下。
package cn.ctyun.demo.api; import cn.ctyun.demo.api.watermark.ViewContentStreamWithWaterMark; import com.alibaba.fastjson.JSONObject; import org.apache.flink.api.common.functions.AggregateFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import java.util.HashSet; /** * @classname: ApiTimeWindowAggregate * @description: 时间窗聚合函数,统计用户PV、UV实例, * @author: Liu Xinyuan * @create: 2023-04-19 13:49 **/ public class ApiTimeWindowAggregate { // 这里模拟一个场景,在时间窗口内将PV除以UV以获得用户粘度(平均用户活跃度) public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStream<JSONObject> viewContentDataStream = ViewContentStreamWithWaterMark.getViewContentDataStream(env); viewContentDataStream.print("输入数据"); viewContentDataStream.keyBy(data -> true) .window(TumblingEventTimeWindows.of(Time.seconds(30))) .aggregate(new AvgPv()) .print("30秒内用户活跃度"); env.execute(); } // 定义聚合函数,这里泛型中第一个JSONObject标志了输入数据,第二个Tuple2<Long, HashSet<String>>表示为累加器,第三个Double表示为最终输出的结果 public static class AvgPv implements AggregateFunction<JSONObject, Tuple2<Long, HashSet<String>>, Double>{ @Override public Tuple2<Long, HashSet<String>> createAccumulator() { return Tuple2.of(0L, new HashSet<>()); } @Override public Tuple2<Long, HashSet<String>> add(JSONObject value, Tuple2<Long, HashSet<String>> accumulator) { // 没来一条数据,pv个数加1,将user放入hashset accumulator.f1.add(value.getString("user_name")); return Tuple2.of(accumulator.f0 +1,accumulator.f1); } @Override public Double getResult(Tuple2<Long, HashSet<String>> accumulator) { // 窗口触发时,输出相应的结果,这里输出pv/uv return (double) (accumulator.f0 / accumulator.f1.size()); } @Override public Tuple2<Long, HashSet<String>> merge(Tuple2<Long, HashSet<String>> a, Tuple2<Long, HashSet<String>> b) { // 此一般用于累加器的合并,在这里可以不设置 return null; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
通过如上方法,可以实现对新增数据进行统计。每三十秒统计一次并输出,对于上面的代码的结果,其可以实现在时间窗口结束后,对将聚合函数的结果输出,能够实现。
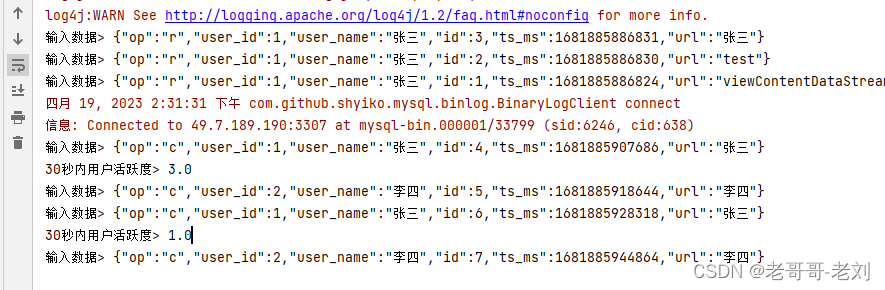
窗口处理函数
在有些情况下,计算必须基于所有的数据才有效,这种情况下再使用增量聚合的意义不大,此时输出的结果需要包含一些上下文信息。在这里可以定义自定义的窗口处理函数。这里的使用方法相当于全窗口的方法,即需要将窗口内的数据收集完成后需要进行的操作。
如下所示,需要实现一个抽象类ProcessWindowFunction,之后即可完成相应的窗口操作。对于该类而言,其主要作用为将时间窗口结束后,将该时间窗口中的用户数量进行统计(UV)。
package cn.ctyun.demo.api; import cn.ctyun.demo.api.watermark.ViewContentStreamWithWaterMark; import com.alibaba.fastjson.JSONObject; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.sql.Timestamp; import java.util.HashSet; /** * @classname: ApiTimeWindowsProcess * @description: 自定义时间窗函数实例 * @author: Liu Xinyuan * @create: 2023-04-19 14:43 **/ public class ApiTimeWindowsProcess { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStream<JSONObject> viewContentDataStream = ViewContentStreamWithWaterMark.getViewContentDataStream(env); viewContentDataStream.print("输入数据"); viewContentDataStream.keyBy(data -> true) .window(TumblingEventTimeWindows.of(Time.seconds(30))) .process(new CountUvTimeProcessWindow()) .print(); env.execute(); } // 实现抽象类,构建一个全窗口函数 public static class CountUvTimeProcessWindow extends ProcessWindowFunction<JSONObject, String, Boolean, TimeWindow>{ @Override public void process(Boolean aBoolean, ProcessWindowFunction<JSONObject, String, Boolean, TimeWindow>.Context context, Iterable<JSONObject> elements, Collector<String> out) throws Exception { HashSet<String> userSet = new HashSet<>(); for (JSONObject element : elements) { userSet.add(element.getString("user_name")); } Integer uv = userSet.size(); // 结合窗口信息进行输出 Long start = context.window().getStart(); Long end = context.window().getEnd(); out.collect("窗口" + new Timestamp(start) + "->" + new Timestamp(end) + "UV值为:" + uv); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
JOIN功能
这里主要通过两个表进行相互同步,其中包括一个登录信息表、一个浏览记录表。通过两个表的结合以实现对用户登录一段时间后访问记录的查询。这里的连接器选择使用mysql-cdc。相关的设置可参考后续章节的部分,在这里关于cdc不再详解。
对于JOIN功能,是对多流进行合并统计结果的重要方法。
时间窗Inner Join
Flink的状态
和其他大数据组件不太相同,flink是一种有状态的体系,在处理流式数据的时候,面对源源不断而来的数据,flink可以基于当前数据直接给出结果,也可以依赖先前的一些数据结合起当前数据进行计算。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态
算子状态
checkpoint和savepoint
FlinkSql功能
FlinkSql最简单地讲,就是将flink复杂的Flinkapi封装成为sql,供简易地调用、使用。目前由于sql的封装的便利化和一些相应的功能的提供,越来越多的工程师选择直接用FlinkSql进行开发从而对经典的DataStream Api开发方式束之高阁。
在代码中使用flinkSQL,可以添加如下依赖,这里的依赖是一个 Java 的“桥接器”(bridge),主要就是负责 Table API 和下层 DataStreamAPI 的连接支持,按照不同的语言分为 Java 版和 Scala 版,可以把他想象成一个翻译器。
对于本地运行,这里主要添加的依赖是一个“计划器”(planner),它是 Table API 的核心组件,负责提供运行时环境,并生成程序的执行计划。这里我们用到的是新版的 blink planner。由于 Flink 安装包的 lib 目录下会自带 planner,所以在生产集群环境中提交的作业不需要打包这个依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
FlinkSql与连接器(Connector)相结合
一般地,flink程序需要连接外部系统,进行一定的数据输入和输出。因此,最直观的创建表的方式,就是通过连接器(connector)连接到一个外部系统,然后定义出对应的表结构。一般地,可以将flinksql与connector依赖相结合以达到代码要求。对于一般官方提供的connector,flinksql支持通过sql字段with进行设置。
以mysql connector为例,需要首先引入如下依赖,能够使得flink感知到相应的连接器依赖。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
之后对于flinksql任务,只需要通过sql字段中的with即可实现,能够通过flinksql连接mysql 数据库作为数据源(数据输出端)
package cn.ctyun.demo.flinksql; import cn.ctyun.demo.flinksql.udf.HashScalarFunction; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; /** * @Author wangkeshuai * @Date 2023/4/14 14:50 * @Description 读取mysql数据使用UDF函数转换并输出到mysql */ public class FlinkSqlUdfMysql2Mysql { public static void main(String[] args) { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 1. 创建读取表,使用mysql进行 String source_ddl = "CREATE TABLE UserSource (" + " id INT, " + " name VARCHAR, " + " phone VARCHAR, " + " sex INT " + ") WITH (" + " 'connector.type' = 'jdbc', " + " 'connector.url' = 'jdbc:mysql://******:3306/flink_test_source?useSSL=false', " + " 'connector.table' = 'test_user_table', " + " 'connector.username' = '******', " + " 'connector.password' = '******'" + ")"; tableEnv.executeSql(source_ddl); // 中间步骤省略 tableEnv.executeSql(insertSql); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
sql与DataStream混合编码
flinksql使用的一般为Table类,与DataStream类算子相互转换亦是flinksql中编程的一个主要功能
SQL模式与原生Flink的关系与差异与适配
对于面向流式数据的flink而言,和主要针对于批处理的sql表而言,存在着很多不同点,我们可以将关系型表/SQL 与流处理做一个对比如下所示。
| SQL | 流式数据 | |
|---|---|---|
| 数据对象 | 字段元组的有界集合 | 字段元组的无限序列 |
| 查询数据方式 | 访问完整的数据输入 | 因为数据实时流动,无法访问所有的数据 |
| 查询结束条件 | 生成固定大小的结果集后终止 | 永不停止 |
由于和sql模式的不同,flinksql中亦存在着更多新的概念,如下介绍。
FlinkSql的动态表
动态表是Flink在Table API和SQL中的核心概念,它为流数据处理提供了表和SQL支持。当流中有新数据到来,初始的表中会插入一行;而基于这个表定义的 SQL 查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为“动态表”(Dynamic Tables)。动态表中的数据会随着时间发生变化。
FlinkSql的持续查询
动态表可以像静态的批处理表一样进行查询操作。由于数据在不断变化,因此基于它定义的 SQL 查询也不可能执行一次就得到最终结果。这样一来,我们对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。
由于每次数据到来都会触发查询操作,因此可以认为一次查询面对的数据集,就是当前输入动态表中收到的所有数据。这相当于是对输入动态表做了一个“快照”(snapshot),当作有限数据集进行批处理;流式数据的到来会触发连续不断的快照查询,像动画一样连贯起来,就构成了“持续查询”。
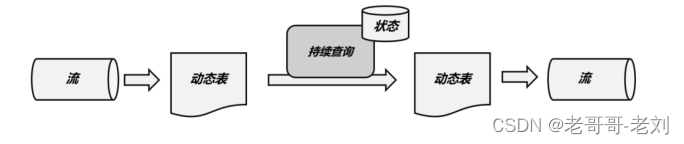
FlinkSql时间与窗口
对于流式数据,时间是划分数据的一个关键指标。通过水位线可以划分数据的事件时间,通过事件时间或处理时间结合时间窗口设置,能够使flinksql处理一段时间窗口内的数据,可以有效地划分时间区域,并且可以减少内存开销使得flink只处理、保留一段时间窗口内的数据。
FlinkSql UDF编写方式
有时,flink提供的处理方法不够使用,则可开发UDF函数参与操作目前。Flink 的 Table API 和 SQL 提供了多种自定义函数的接口,以抽象类的形式定义。当前 UDF
主要有以下几类:
- 标量函数(Scalar Functions):将输入的标量值转换成一个新的标量值;
- 表函数(Table Functions):将标量值转换成一个或多个新的行数据,也就是扩展成一个表;
- 聚合函数(Aggregate Functions):将多行数据里的标量值转换成一个新的标量值;
- 表聚合函数(Table Aggregate Functions):将多行数据里的标量值转换成一个或多个新的行数据。
标量函数
自定义标量函数可以把 0 个、 1 个或多个标量值转换成一个标量值,它对应的输入是一行数据中的字段,输出则是唯一的值。所以从输入和输出表中行数据的对应关系看,标量函数是“一对一”的转换。
以如下为例,可定义一个对字段进行md5加密的方法
package cn.ctyun.demo.flinksql.udf; import org.apache.flink.table.functions.ScalarFunction; import java.nio.charset.StandardCharsets; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; import java.util.Arrays; /** * @classname: HashScalarFunction * @description: 自定义hash函数 * @author: Liu Xinyuan * @create: 2023-04-13 15:01 **/ public class HashScalarFunction extends ScalarFunction { /** * 进行MD5加密 * @param str 输入字符串 * @return * @throws NoSuchAlgorithmException */ public String eval(String str) throws NoSuchAlgorithmException { MessageDigest md5 = MessageDigest.getInstance("MD5"); md5.update(str.getBytes(StandardCharsets.UTF_8)); return Arrays.toString(md5.digest()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
之后可以在sql中注册该函数,以便在sql中注册使用。
// 3.简单的数据清洗,将电话号码进行hash掩码
tableEnv.createTemporarySystemFunction("MyHASH", HashScalarFunction.class);
Table maskedTable = tableEnv.sqlQuery("SELECT id, name, MyHASH(phone) as phone, sex FROM UserSource");
- 1
- 2
- 3
表函数
跟标量函数一样,表函数的输入参数也可以是 0 个、1 个或多个标量值;不同的是,它可以返回任意多行数据。“多行数据”事实上就构成了一个表,所以“表函数”可以认为就是返回一个表的函数,这是一个“一对多”的转换关系。即一行数据生成多行数据,类似于api方式下的flatmap算子的作用。
在这里,需要定义一个表函数,如下所示
package cn.ctyun.demo.flinksql.udf; import org.apache.flink.table.functions.TableFunction; import org.apache.flink.api.java.tuple.Tuple2; /** * @classname: SplitTablFunction * @description: 分割数据表函数 * @author: Liu Xinyuan * @create: 2023-04-17 11:02 **/ public class SplitTablFunction extends TableFunction<Tuple2<String, Integer>> { /** * 自定义表函数,将字段进行分割,实现单个字段一对多,这里的返回需要和泛型对应 * @param str */ public void eval(String str){ String[] fields = str.split("\\?"); // 转义问号,以及反斜杠本身 for (String field : fields){ collect(Tuple2.of(field, field.length())); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
接着,在相应的代码中调用本功能
// 3. 使用表函数,这里使用的是lateral table(侧向表),笛卡尔积的方式
Table resultTable = tableEnv.sqlQuery("select id, word, length, length, user_id " +
"from ViewContentSource, LATERAL TABLE( MySplit(url) ) AS T(word, length)");
// 4. 输出到控制台
tableEnv.executeSql("create table output (" +
"id INT, " +
"url STRING, " +
"word STRING," +
"length INT, " +
"user_id INT) " +
"WITH (" +
"'connector' = 'print')");
resultTable.executeInsert("output");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
可知,当引入了新数据后,将原本的一条数据拆分成多个。

聚合函数
聚合函数对应着DataStreamApi的reduce步骤,是对多条数据的规约化,将多条数据合成一条的方法。同样地,该函数需要实现相关接口
一般而言,该函数的实现需要一个累加器(ACCumulator)来记录中间结果
FlinkSql JOIN功能
对于sql类型的交互方式,不能缺少的就是Join功能。而Flink与其他的离线数仓不同,其数据为流式数据,不同于批处理,其join功能有自己的特点。
Regular Join
这种 Join 方式需要去保留两个流的状态,持续性地保留并且不会去做清除。两边的数据对于对方的流都是所有可见的,所以数据就需要持续性的存在 State 里面,那么 State 又不能存的过大,因此这个场景的只适合有界数据流。该方法的数据来自两条流式数据,进行的一个批处理操作。
此种join方式相当于将两流数据全量保存
FlinkCDC功能
基本概念
flinkCDC功能是面向binlog进行同步、对数据的增删改进行同步的工具,能够实现对数据的动态监听。目前其实现原理主要为监听数据源的binlog对数据的变化有所感知。
在这里,我们只需引入相关依赖即可进行操作,如下所示
<!-- flink connector cdc -->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${flink.sql.connector.cdc.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
需要注意的是,flinkcdc关于flink的版本严格,在选择相应的cdc版本时,可查看相关官方的依赖表
https://ververica.github.io/flink-cdc-connectors/master/content/about.html,在本实例中,选择2.2.1版本的mysqlcdc进行演示
| Flink® CDC Version | Flink® Version |
|---|---|
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13., 1.14. |
| 2.3.* | 1.13., 1.14., 1.15.*, 1.16.0 |
Flink SQL CDC 内置了 Debezium 引擎,利用其抽取日志获取变更的能力,将 changelog 转换为 Flink SQL 认识的 RowData 数据。RowData 代表了一行的数据,在 RowData 上面会有一个元数据的信息 RowKind,RowKind 里面包括了插入(+I)、更新前(-U)、更新后(+U)、删除(-D),这样和数据库里面的 binlog 概念十分类似。通过 Debezium 采集的数据,包含了旧数据(before)和新数据行(after)以及原数据信息(source),op 的 u表示是 update 更新操作标识符(op 字段的值c,u,d,r 分别对应 create,update,delete,reade),ts_ms 表示同步的时间戳。
使用api进行操作
使用flink标准DataStreamApi进行开发,能够配合CDC功能对数据的动态输入进行获取。如下代码实现了一个从mysql进行动态CDC读取的样例,这里使用了相应的mysql-cdc的数据源依赖进行读取。
package cn.ctyun.demo.api.watermark; import cn.ctyun.demo.api.utils.TransformUtil; import com.alibaba.fastjson.JSONObject; import com.ververica.cdc.connectors.mysql.source.MySqlSource; import com.ververica.cdc.connectors.mysql.table.StartupOptions; import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema; import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.time.Duration; public class ViewContentStreamWithoutWaterMark { public static DataStream<JSONObject> getViewContentDataStream(StreamExecutionEnvironment env){ // 1.创建Flink-MySQL-CDC的Source MySqlSource<String> viewContentSouce = MySqlSource.<String>builder() .hostname("49.7.189.190") .port(3307) .username("root") .password("Adm@163.comCdc") .databaseList("test_cdc_source") .tableList("test_cdc_source.view_content") .startupOptions(StartupOptions.initial()) .deserializer(new JsonDebeziumDeserializationSchema()) .serverTimeZone("Asia/Shanghai") .build(); // 2.使用CDC Source从MySQL读取数据 DataStreamSource<String> mysqlDataStreamSource = env.fromSource( viewContentSouce, WatermarkStrategy.noWatermarks(), "ViewContentStreamNoWatermark Source" ); // 3.转换为指定格式 return mysqlDataStreamSource.map(TransformUtil::formatResult); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
使用flinksql进行操作
flinksql操作,能够简化大量操作,具体如下代码所示。在这里我们只需要提供简单的sql语句即可完成对mysql数据源的动态读取。通过指定连接器类型为'connector' = 'mysql-cdc',通过此配置项调用mysql cdc连接器。
package cn.ctyun.demo.flinksql; import cn.ctyun.demo.flinksql.udf.HashScalarFunction; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.TableResult; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; /** * @classname: ReadFromCdc * @description: 通过cdc获取数据变化进行输入 * @author: Liu Xinyuan * @create: 2023-04-12 15:09 **/ public class FlinkSqlReadFromCdc { public static void main(String[] args) throws Exception { ParameterTool parameterTool = ParameterTool.fromArgs(args); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env.disableOperatorChaining(); StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env); // 1. 创建读取表,使用mysql-cdc进行,注意此时应标记主键 String source_ddl = "CREATE TABLE UserSource (" + " id INT, " + " name VARCHAR, " + " phone VARCHAR, " + " sex INT, " + " primary key (id) not enforced" + ") WITH (" + " 'connector' = 'mysql-cdc'," + " 'hostname' = '*******'," + " 'port' = '3307'," + " 'username' = '" + parameterTool.get("user") + "', " + " 'password' = '" + parameterTool.get("passwd") + "'" + " 'database-name' = 'test_cdc_source'," + " 'table-name' = 'test_user_table'," + " 'debezium.log.mining.continuous.mine'='true',"+ " 'debezium.log.mining.strategy'='online_catalog', " + " 'debezium.database.tablename.case.insensitive'='false',"+ " 'jdbc.properties.useSSL' = 'false' ," + " 'scan.startup.mode' = 'initial')"; tableEnv.executeSql(source_ddl); // 2. 创建写出表,使用mysql进行 String sink_ddl = "CREATE TABLE UserSink (" + " id INT, " + " name VARCHAR, " + " phone VARCHAR, " + " sex INT, " + " primary key (id) not enforced" + ") WITH (" + " 'connector.type' = 'jdbc', " + " 'connector.url' = 'jdbc:mysql://******:3306/flink_test_sink?useSSL=false', " + " 'connector.table' = 'test_user_table', " + " 'connector.username' = '" + parameterTool.get("sinkUser") + "', " + " 'connector.password' = '" + parameterTool.get("sinkPasswd") + "'" + " 'connector.write.flush.max-rows' = '1'" + ")"; tableEnv.executeSql(sink_ddl); // 3.简单的数据清洗,将电话号码进行hash掩码 tableEnv.createTemporarySystemFunction("MyHASH", HashScalarFunction.class); Table maskedTable = tableEnv.sqlQuery("SELECT id, name, MyHASH(phone) as phone, sex FROM UserSource"); tableEnv.createTemporaryView("MaskedUserInfo", maskedTable); // 4.使用insert语句进行数据输出,在这里进行一定地清洗 String insertSql = "INSERT INTO UserSink SELECT * FROM MaskedUserInfo"; TableResult tableResult = tableEnv.executeSql(insertSql); tableResult.print(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
刚才的代码中定义了一套简单的数据同步+电话号码掩码的操作。这里重点看cdc相关的配置项,如下所示。这里有一个重点的配置项, 'scan.startup.mode' = 'initial'此处是cdc的关键所在,MySQL CDC 消费者可选的启动模式, 合法的模式为 “initial”,“earliest-offset”,“latest-offset”,“specific-offset” 和 “timestamp”。请查阅 官方文档启动模式了解更多详细信息。这里使用的initial模式为在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog,也就是先进行一次全表扫描后再进行后续的增量同步,由于测试数据较小可以如此进行,cdc的使用者可以根据个人情况进行选择。
String source_ddl = "CREATE TABLE UserSource (" + " id INT, " + " name VARCHAR, " + " phone VARCHAR, " + " sex INT, " + " primary key (id) not enforced" + ") WITH (" + " 'connector' = 'mysql-cdc'," + " 'hostname' = '******'," + " 'port' = '3307'," + " 'username' = '" + parameterTool.get("user") + "', " + " 'password' = '" + parameterTool.get("passwd") + "'" + " 'database-name' = 'test_cdc_source'," + " 'table-name' = 'test_user_table'," + " 'debezium.log.mining.continuous.mine'='true',"+ " 'debezium.log.mining.strategy'='online_catalog', " + " 'debezium.database.tablename.case.insensitive'='false',"+ " 'jdbc.properties.useSSL' = 'false' ," + " 'scan.startup.mode' = 'initial')";
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
启用后,整个流程为对其中的数据增量同步,由于我们使用的是initial模式,因此我们的数据在任务启动的时候,首先进行了一次全量同步,全量地将信息同步,并且进行了掩码操作。
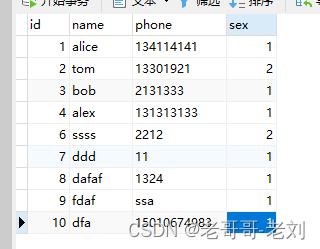
后续如果添加新的信息也会进行同步,删除亦然。
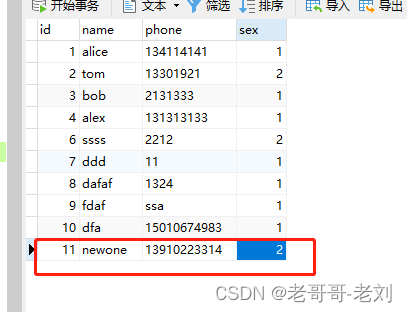
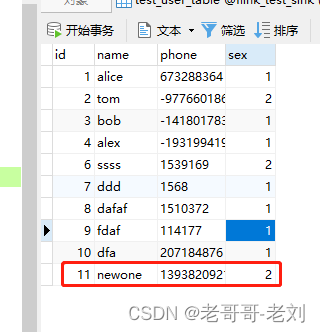
断点续传
断点续传功能是flink-cdc在2.0版本后逐渐推行的新功能。此功能能够支持使用savepoint、checkpoint等方式进行断点续传功能。意思为如果我们在中途保留一个保存点,那么任务如果重启的话将会从保存点开始同步cdc数据,中间不会遗失数据(除非手动删除binlog)。目前flink cdc如果需要实现断点续传则需要开启checkpoint功能。
K8s Application运行方式
对于K8S Application模式,其本质上是将任务运行时环境和我们的任务jar包打到一个镜像,供k8s调度。并且不需要提前启动JM、TM等。
任务jar生成
在这里,主要提供一个flink任务案例供flink k8s application进行调用
-
开发java代码,供使用,本示例项目较为简单,仅为将数据输出至mysql中,在这里提供一个用例,本代码为DataStream风格的mysql信息录入任务。
package cn.ctyun.demo; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.connector.jdbc.JdbcConnectionOptions; import org.apache.flink.connector.jdbc.JdbcSink; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class SinkToMySQL { public static void main(String[] args) throws Exception { // 从启动参数中获取连接信息 ParameterTool parameterTool = ParameterTool.fromArgs(new String[]{"url", "passwd", "user"}); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Event> stream = env.fromElements( new Event("Mary", "./home", 1000L), new Event("Bob", "./cart", 2000L), new Event("Alice", "./prod?id=100", 3000L), new Event("Alice", "./prod?id=200", 3500L), new Event("Bob", "./prod?id=2", 2500L), new Event("Alice", "./prod?id=300", 3600L), new Event("Bob", "./home", 3000L), new Event("Bob", "./prod?id=1", 2300L), new Event("Bob", "./prod?id=3", 3300L)); stream.addSink( JdbcSink.sink( "INSERT INTO clicks (user, url) VALUES (?, ?)", (statement, r) -> { statement.setString(1, r.user); statement.setString(2, r.url); }, new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl(parameterTool.get("url")) .withDriverName("com.mysql.jdbc.Driver") .withUsername(parameterTool.get("user")) .withPassword(parameterTool.get("passwd")) .build() ) ); env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
-
项目打包
防止一些依赖缺失,这里使用fatjar的方式进行打包,maven相关的设置如下所示,因为个人开发的项目中使用的某些依赖flink的运行时环境中不一定存在,可能会发生依赖缺失的严重异常。因此在此推荐使用fatjar的方式进行打包。
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
之后通过命令
mvn package进行打包
-
制作镜像,在这里通过官方的基础镜像进行打包
使用docker进行镜像生成,使用命令为docker build -t ****/flink-demo-jar-job:1.0-SNAPSHOT .
FROM apache/flink:1.14.3-scala_2.12 RUN mkdir -p $FLINK_HOME/usrlib COPY lib $FLINK_HOME/lib/ COPY flink-demo-jar-job-1.0-SNAPSHOT-jar-with-dependencies.jar $FLINK_HOME/usrlib/flink-demo-jar-job-1.0-SNAPSHOT-jar-with-dependencies.jar- 1
- 2
- 3
- 4
-
推送镜像到相应的镜像仓。注意!要求我们的K8S集群可从本镜像仓中拉取镜像!
docker push ****/flink-demo-jar-job:1.0-SNAPSHOT- 1
k8s Application运行flink任务
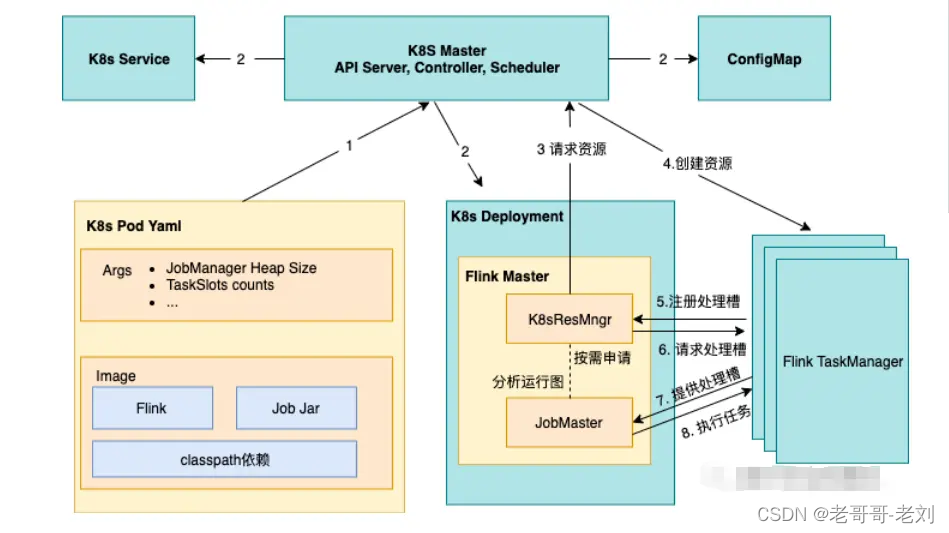
Application模式架构
在k8s application模式下,用户只需要通过 Flink Client/CLI 启动作业。首先通过 K8s 启动 JobManager(deployment)的同时启动作业,然后通过 JobManager 内部的 K8sResourceManager 模块向 K8s 直接申请 TaskManager 的资源并启动,最后当 TM 注册到 JM 后作业就提交到 TM。用户在整个过程无需指定 TaskManager 资源的数量,而是由 JobManager 向 K8s 按需申请的。
启动命令
这里我们可以指定一定的运行参数,相关的参数设定方案请参考官方文档https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/deployment/config/#kubernetes
./bin/flink run-application \ --target kubernetes-application \ -Dkubernetes.cluster-id=flink-cluster \ # 指定容器启动的镜像(与之前提交的保持一致) -Dkubernetes.container.image=****/flink-demo-jar-job:1.0-SNAPSHOT \ -Dkubernetes.jobmanager.replicas=1 \ # 指定容器运行的命名空间 -Dkubernetes.namespace=flink-dev \ -Dkubernetes.jobmanager.service-account=flink-service-account \ -Dkubernetes.taskmanager.cpu=1 \ -Dtaskmanager.memory.process.size=4096mb \ -Dkubernetes.jobmanager.cpu=1 \ -Djobmanager.memory.process.size=4096mb \ -Dkubernetes.rest-service.exposed.type=NodePort \ -Dclassloader.resolve-order=parent-first \ # yaml 模板,为解决hosts映射,后续可以通过编排此yaml文件,实现动态替换启动jar包、配置文件和持久化一些数据 # -Dkubernetes.pod-template-file=/opt/flink-1.14.2/flink-templeta.yaml \ # Main方法 -c cn.ctyun.demo.SinkToMySQL \ # 启动Jar包和启动配置文件的绝对路径(容器内部,不是宿主机) local:///usr/local/flink/lib/flink-realtime-1.0-SNAPSHOT.jar \ # 如下将提供mysql的连接信息,通过参数的方式传递给jar包 --passwd ****** \ --user ******\ --url ******
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
PodTemplate
PodTemplate主要是通过指定pod的启动样例,在podtemplate中可以指定域名、挂载路径、配置文件、初始化容器等信息,如下给出一个提供一个将保存点持久化的的podtemplate。
apiVersion: v1 kind: Pod spec: containers: # Do not change the main container name - name: flink-main-container volumeMounts: - mountPath: /opt/flink/Checkpoint name: Checkpoint - mountPath: /opt/flink/Savepoint name: Savepoint volumes: - name: Checkpoint persistentVolumeClaim: claimName: flink-checkpoint-pvc - name: Savepoint persistentVolumeClaim: claimName: flink-savepoint-pvc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
翼flink-StreamPark使用要点
概述
翼flink-StreamPark是简化flink标准流程的可视化界面工具,并且配合云原生技术实现真正的动态伸缩、按量计费,高可用地执行任务。目前翼flink使用自研的云原生底座运行flink任务。
常规使用
一般地,翼flink的使用流程分为全流程
依赖导入
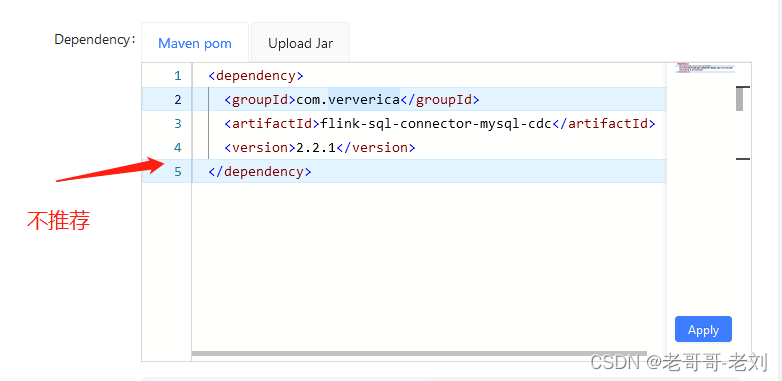
对于flink任务而言,需要一些UDF、connector等依赖项。而StreamPark支持导入jar包的方式进行需要用户提供完整的依赖(with-dependencies)的jar包,否则StreamPark可能会因为依赖缺失而导致无法启动任务。在这里一定要上传完整依赖!
以cdc的依赖为例子,如果单纯的以maven依赖pom声明的方式进行导入,则会导致依赖缺失。这是因为在此过程中StreamPark只会从maven仓库中下载本jar包导入至flink运行时lib,而该jar所使用的下级依赖一律不会下载。
而对于本jar包的导入,这里推荐自主编译全依赖的jar包。比如cdc,可以去github下载源码后再添加一个maven插件,手动进行package后生成完整jar包后再进行导入。这样即可完美地运行jar包。
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
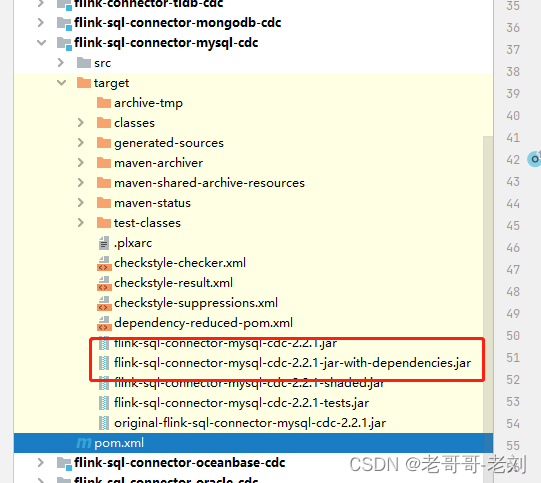
添加此插件后,可使用mvn clean package -DskipTests重新进行打包,打包后将生成依赖如下所示。此依赖就是我们在StreamPark中的完整cdc依赖,StreamPark可顺利运行,不会因为底层依赖缺失而报错。同样地,该方法可以作为参考,对需要导入第三方依赖或自研UDF时,可按照此方法进行。
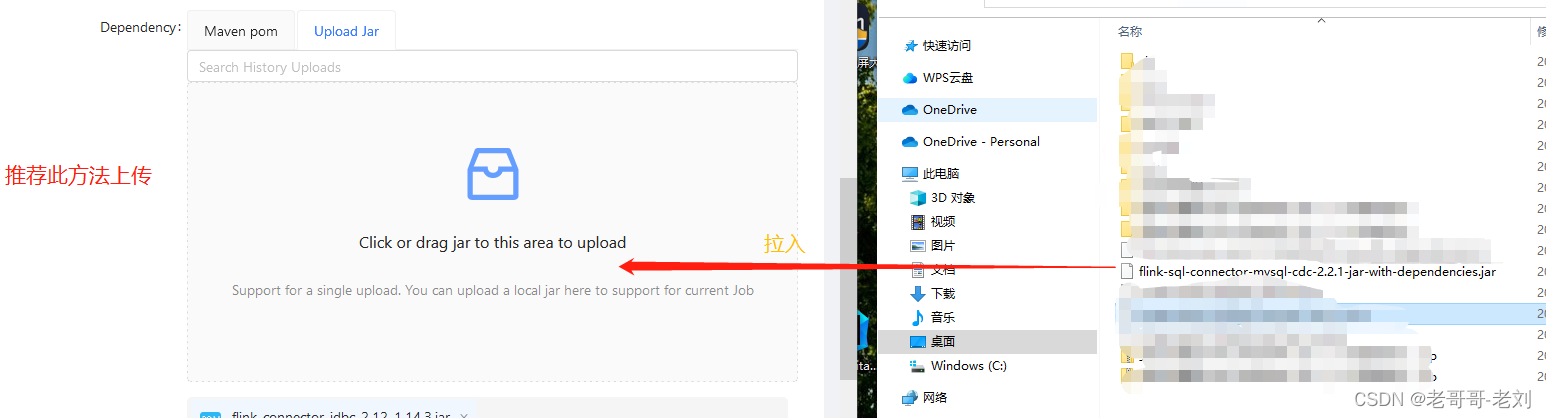
依赖加载规则
对于StreamPark而言,所使用的依赖引入为底层flink的类加载方法导入。具体而言,其需要进行相应的类加载配置。
- parent-first 类加载策略:和jvm的双亲委派规则相同。
- child-first 类加载策略:我们已经了解到,双亲委派模型的好处就是随着类加载器的层次关系保证了被加载类的层次关系,从而保证了 Java 运行环境的安全性。但是在 Flink App 这种依赖纷繁复杂的环境中,双亲委派模型可能并不适用。例如,程序中引入的 Flink-Cassandra Connector 总是依赖于固定的 Cassandra 版本,用户代码中为了兼容实际使用的 Cassandra 版本,会引入一个更低或更高的依赖。而同一个组件不同版本的类定义有可能会不同(即使类的全限定名是相同的),如果仍然用双亲委派模型,就会因为 Flink 框架指定版本的类先加载,而出现莫名其妙的兼容性问题,如 NoSuchMethodError、IllegalAccessError 等。child-first 策略避开了“先把加载的请求委托给父加载器完成”这一步骤,只有特定的某些类一定要“遵循旧制”。
在StreamPark中,仍然可以使用这一规则加载我们依赖包,比如当使用mysql的jdbc连接的时候,我们选用的依赖与flink自带mysql驱动冲突,则可选择使用该方法进行依赖加载方式的指定
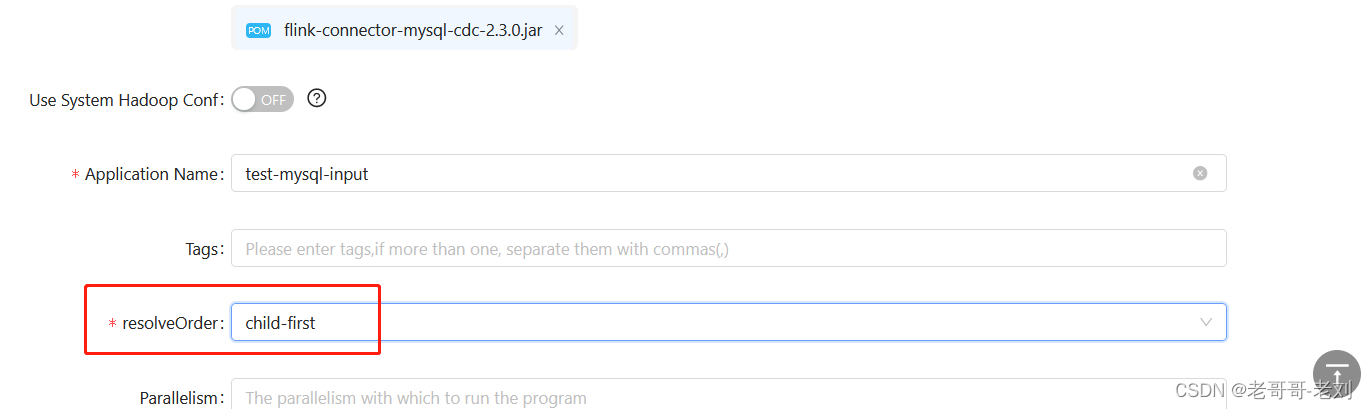
生成完整jar包后再进行导入。这样即可完美地运行jar包。
[外链图片转存中…(img-9XzDwVQV-1703493220560)]
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
添加此插件后,可使用mvn clean package -DskipTests重新进行打包,打包后将生成依赖如下所示。此依赖就是我们在StreamPark中的完整cdc依赖,StreamPark可顺利运行,不会因为底层依赖缺失而报错。同样地,该方法可以作为参考,对需要导入第三方依赖或自研UDF时,可按照此方法进行。
[外链图片转存中…(img-Tje8VBrJ-1703493220561)]
[外链图片转存中…(img-zPtQwRWo-1703493220561)]
依赖加载规则
对于StreamPark而言,所使用的依赖引入为底层flink的类加载方法导入。具体而言,其需要进行相应的类加载配置。
- parent-first 类加载策略:和jvm的双亲委派规则相同。
- child-first 类加载策略:我们已经了解到,双亲委派模型的好处就是随着类加载器的层次关系保证了被加载类的层次关系,从而保证了 Java 运行环境的安全性。但是在 Flink App 这种依赖纷繁复杂的环境中,双亲委派模型可能并不适用。例如,程序中引入的 Flink-Cassandra Connector 总是依赖于固定的 Cassandra 版本,用户代码中为了兼容实际使用的 Cassandra 版本,会引入一个更低或更高的依赖。而同一个组件不同版本的类定义有可能会不同(即使类的全限定名是相同的),如果仍然用双亲委派模型,就会因为 Flink 框架指定版本的类先加载,而出现莫名其妙的兼容性问题,如 NoSuchMethodError、IllegalAccessError 等。child-first 策略避开了“先把加载的请求委托给父加载器完成”这一步骤,只有特定的某些类一定要“遵循旧制”。
在StreamPark中,仍然可以使用这一规则加载我们依赖包,比如当使用mysql的jdbc连接的时候,我们选用的依赖与flink自带mysql驱动冲突,则可选择使用该方法进行依赖加载方式的指定
![[外链图片转存中...(img-SNTOaoDF-1703493220561)]](https://img-blog.csdnimg.cn/direct/38194f197f134f77b1931e319b001901.png)


