
- 1大模型时代,5个最顶级的向量数据库_weaviate
- 2鸿蒙 IM 即时通讯开发实践,融云 IM HarmonyOS NEXT 版
- 3Redis--------java引入redis_java 引入redis
- 4mysql sql查询表分区
- 51. 数据结构——单链表的主要操作(考研专业课学习)
- 6使用Android Studio打包Module成jar包_android studio 怎么用moudle打jar包
- 7HTML作业天气预报界面_天气预报的html代码
- 8企业定制开发AI智能名片S2B2C商城系统小程序:提升用户存留率与复购率的有效手段_s2b2c商城小程序
- 9iframe父页面和子页面之间的交互_iframe 交互
- 10elasticsearch 使用 ik分词器_elasticsearch ik分词器
Wav2Vec 2.0:语音表示自监督学习框架_wav2vec2.0
赞
踩
Wav2Vec 2.0是目前自动语音识别的模型之一。
Wav2Vec 2.0 代表了无监督预训练技术在语音识别领域的重大进步。这些方法通过直接从原始音频中学习,无需人工标记,因此可以有效利用大量未标记的语音数据集。相比于传统的监督学习数据集通常只有大约几百小时的标记数据,这些新方法已经能够扩展到使用多达 1,000,000 小时的未标记语音进行训练。在标准基准测试上进行微调后,这种方法在低数据环境中特别显著地提升了现有技术的表现。
主要思想
如下图所示,模型分为两个阶段进行训练。
第一阶段是自我监督模式,使用未标记的数据完成,旨在实现最佳的语音表示。
可以用类似于单词嵌入的方式来理解这个问题。词嵌入也旨在实现自然语言的最佳表示。主要区别是Wav2Vec 2.0处理音频而不是文本。
训练的第二阶段是监督微调,在此期间,标记数据用于教模型预测特定的单词或音素。如果你不熟悉“音素”这个词,你可以把它看作是特定语言中最小的声音单位,通常由一两个字母表示。
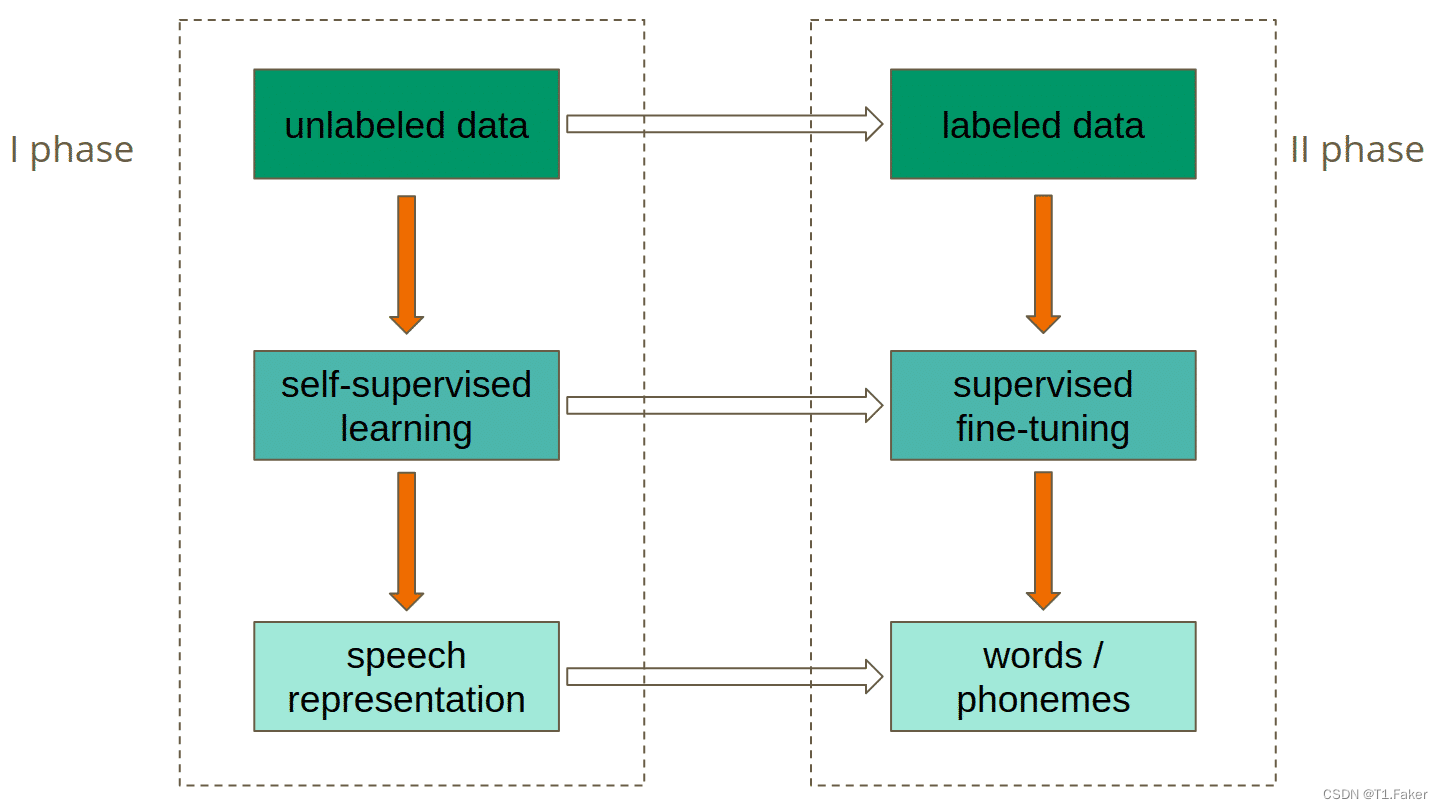
图1. Wav2Vec 2.0的训练阶段
第一阶段的训练是这种模式的主要优势:学习非常好的语音表示可以在少量标记数据上实现最先进的结果。例如,该论文的作者已经在一个巨大的LibriVox数据集上对模型进行了预训练。然后,他们使用了整个Libri Speech数据集进行微调,结果是测试干净子集的单词错误率(WER)为1.8%,测试其他子集的WER为3.3%。使用近10倍的数据,允许在测试清洁和测试其他上获得2.0%的WER。仅使用10分钟的标记训练数据(几乎没有数据),在Libri Speech的测试-干净/测试-其他子集上产生4.8% / 8.2%的WER。

图2. Wav2Vec 2.0的结果
WER
词错误率 (WER) :是语音识别或机器翻译系统性能的常用指标。
WER计算公式:
W
E
R
=
S
+
D
+
I
N
=
S
+
D
+
I
S
+
D
+
C
WER = \frac{S+D+I}{N}=\frac{S+D+I}{S+D+C}
WER=NS+D+I=S+D+CS+D+I
这里:
- S:替换错误的数量(Substitutions)。这是指识别结果中将一个正确的词错误地替换为另一个词的数量。
- D:删除错误的数量(Deletions)。这是指识别结果中遗漏了应该识别的正确词的数量。
- I:插入错误的数量(Insertions)。这是指识别结果中多识别了不应该存在的词的数量。
- N:参考文本中的总词数(Total number of words in the reference)。它等于替换错误、删除错误和正确词的总和,即 N = S + D + C N=S+D+C N=S+D+C。
- C:正确识别的词的数量(Correct words)。
简而言之,WER 是通过将所有错误(替换、删除和插入)相加,然后除以参考文本中的总词数来计算的。
在语音识别系统性能时,有时候会使用单词准确性(WAcc):
W
A
c
c
=
1
−
W
E
R
=
N
−
S
−
D
−
I
N
=
c
−
I
N
WAcc = 1 - WER =\frac{N - S -D - I}{N}=\frac{c - I}{N}
WAcc=1−WER=NN−S−D−I=Nc−I
请注意,由于N是参考文献中的单词数,因此单词错误率可能大于1.0,因此单词准确率可能小于0.0。
计算实例
假设参考文本是:“this is a test”
假设识别结果是:“this is test”
那么计算 WER 的步骤如下:
- 计算替换错误(S):0 (没有词被替换)
- 计算删除错误(D):1 (遗漏了一个词 “a”)
- 计算插入错误(I):0 (没有多余的词)
- 计算正确词数(C):3 (正确识别了 “this”, “is”, 和 “test”)
参考文本的总词数N是4。
于是:
W
E
R
=
S
+
D
+
I
N
=
0
+
1
+
0
4
=
1
4
=
0.25
WER = \frac{S+D+I}{N}=\frac{0+1+0}{4}=\frac{1}{4}=0.25
WER=NS+D+I=40+1+0=41=0.25
WER为0.25或25%
Wav2Vec 2.0模型架构
用于预测的最终模型的架构由三个主要部分组成:
- 处理原始波形输入以获得潜在表示的卷积层 - z,
- Transformer层,创建上下文化表示 - c,
- 线性投影到输出 - Y.
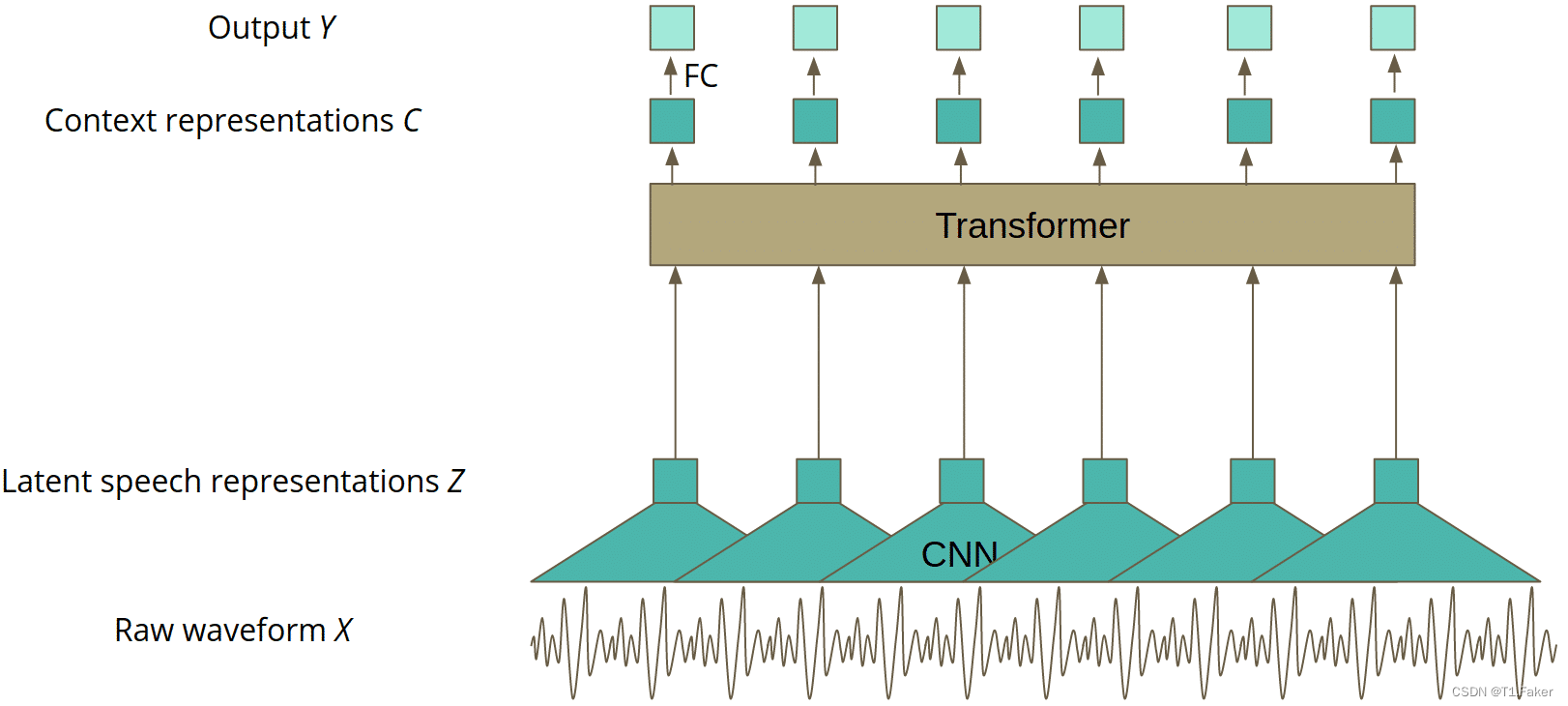
图3. 微调的Wav2Vec 2.0模型架构
这就是模型经过最终微调后的样子,准备在生产环境中进行开发。整个奇迹发生在训练的第一阶段,在自我监督模式下,当模型看起来有点不同时。该模型在没有线性投影的情况下进行训练,生成输出预测。
基本上,本文主要思想部分提到的语音表示对应于图4中的“上下文表示C”。预训练的主要思想与 BERT 类似:对 Transformer 的部分输入进行屏蔽,目标是是猜测屏蔽的潜在特征向量表示 z t z_t zt 。然而,作者通过对比学习改进了这个简单的想法.
对比学习
对比学习是一个以两种不同方式转换输入的概念。然后,训练模型来识别输入的两个变换是否仍然是同一个对象。在 Wav2Vec 2.0 中,变压器层是第一种变换方式,第二种是通过量化实现的,这将在本文的后续部分中进行解释。更正式地说,对于掩码潜在表示 z t z_t zt,我们希望获得这样的上下文表示 c t 以便能够猜测正确的量化表示 c_t以便能够猜测正确的量化表示 ct以便能够猜测正确的量化表示q_t除其他量化表示之外。很好地理解前一句很重要,所以如果您需要的话,自监督训练的Wav2Vec 2.0 版本如图 4 所示。
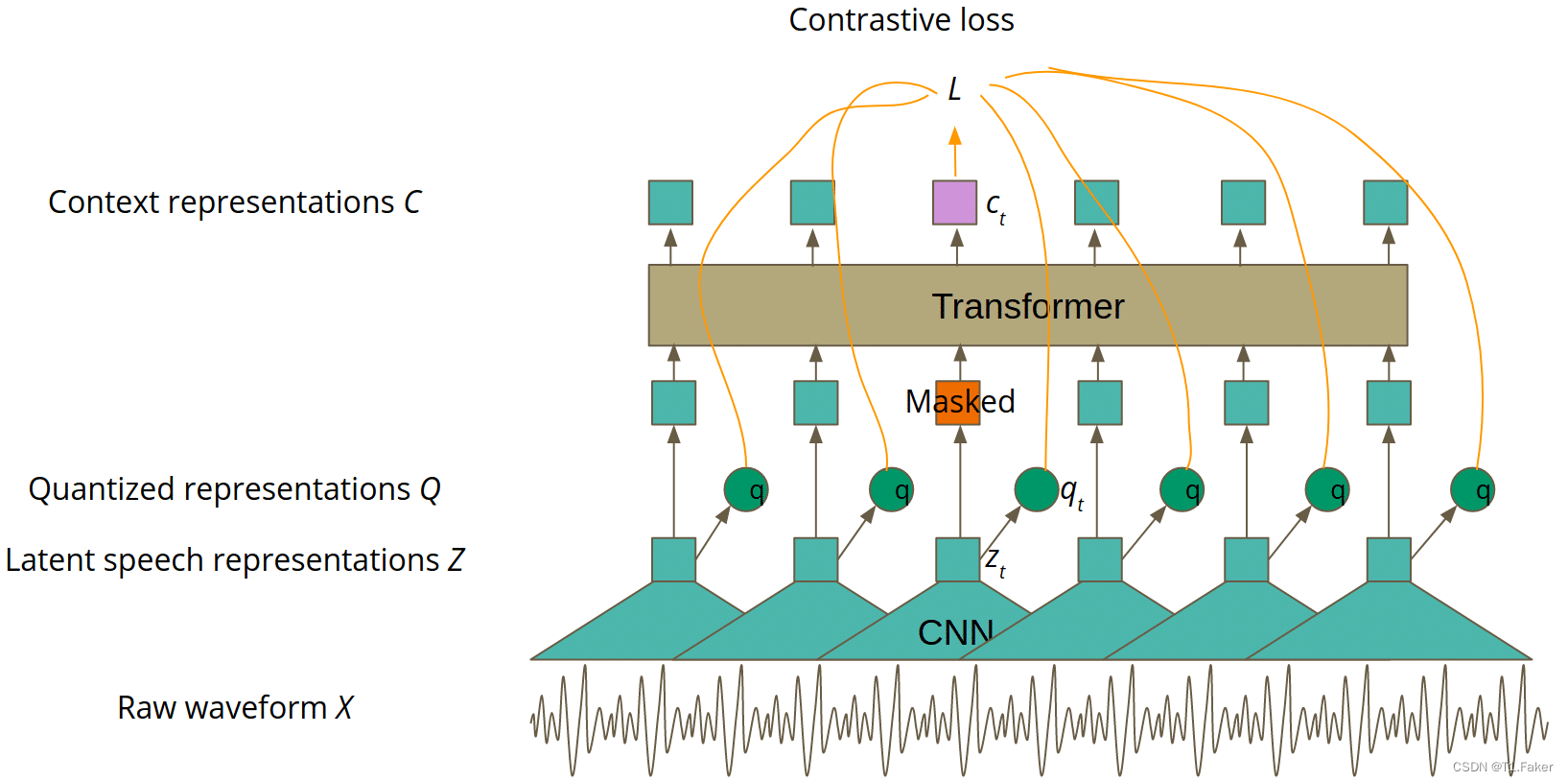
图4. 用于自监督训练的Wav2Vec 2.0模型架构
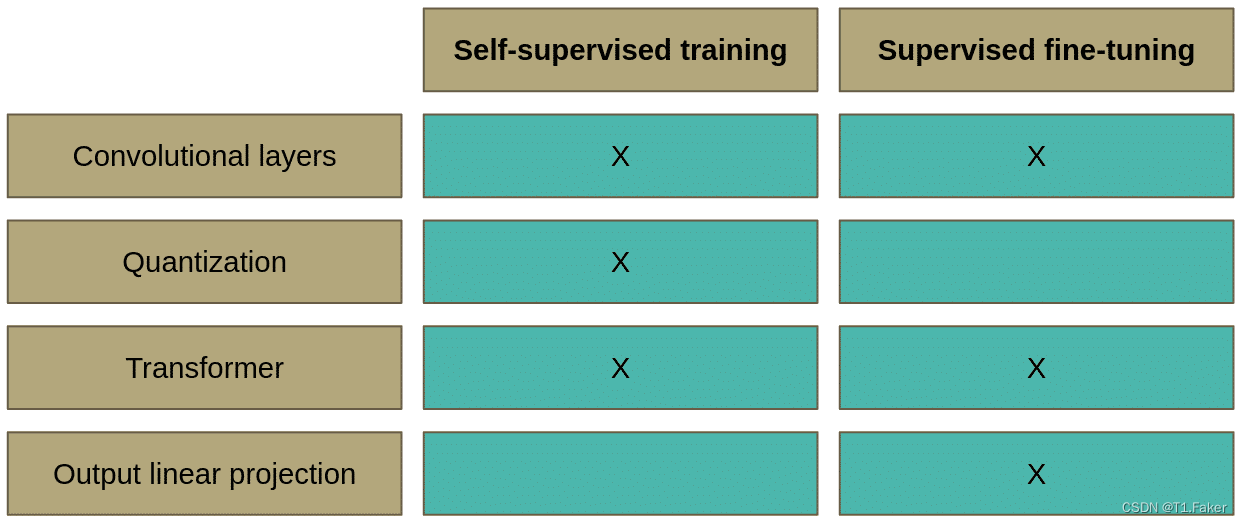
Wav2Vec 2.0自监督和监督学习的比较
量化
量化是将连续空间中的值转换为离散空间中的有限值集的过程。
如何在自动语音识别中实现这一点?假设一个潜在语音表示向量 z t z_t zt涵盖两个音素。语言中的音素数量是有限的。此外,所有可能的音素对的数量也是有限的。这意味着它们可以由相同的潜在语音表示完美地表示。由于它们的数量是有限的,可以创建一个包含所有可能的音素对的码本。量化归结为从码本中选择正确的码字。然而,可以想象所有可能的声音的数量是巨大的。为了更容易训练和使用,Wav2Vec 2.0 的作者创建了 G G G码本,每个码本由 V V V码字组成。要创建量化表示,应从每个码本中选择最佳单词。然后,将所选向量连接起来并通过线性变换进行处理以获得量化表示。该流程如图5所示。
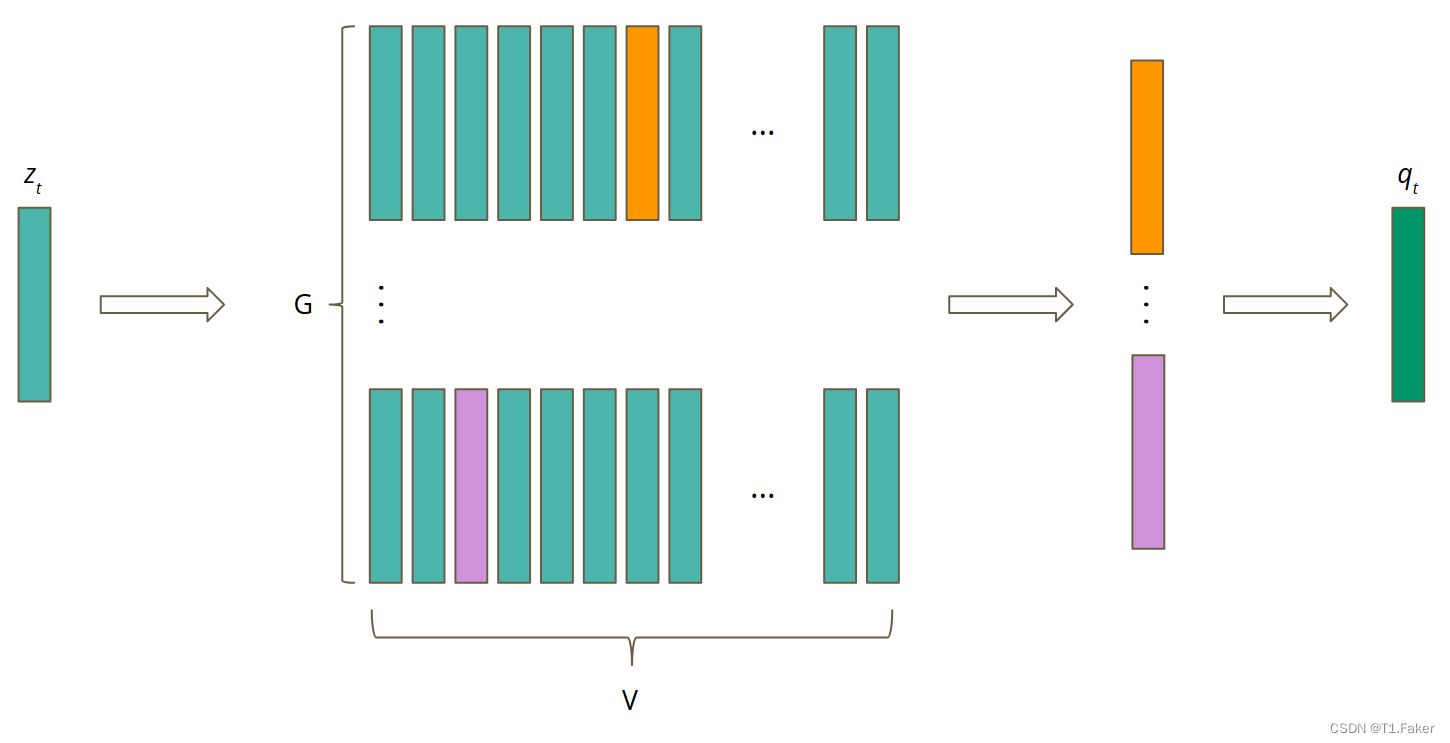
图5. 量化
如何从每个密码本中选择最好的码字?
答案是用Gumbelsoftmax:
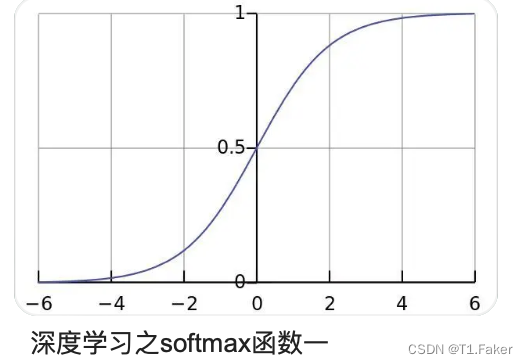
Gumbel-Softmax 是一种用于生成离散样本的连续近似方法。传统的 Softmax 输出是连续的概率分布,而 Gumbel-Softmax 通过引入噪声,使得在反向传播过程中可以对离散分类变量进行微分,从而能够端到端地训练模型。这对于需要离散化输出的任务非常有用。
可以对比softmax和Gumbel-Softmax图一看便知
p g , v = e x p ( s i m ( l g , v + n v ) / τ ) ∑ k = 1 V e x p ( ( l g , k + n k ) / τ ) p_{g,v}=\frac{exp(sim(l_{g,v}+n_v)/\tau)}{\sum_{k=1}^Vexp((l_{g,k}+n_k)/\tau)} pg,v=∑k=1Vexp((lg,k+nk)/τ)exp(sim(lg,v+nv)/τ)
这里:
- sim – 余弦相似度
- l ϵ R G × V l \epsilon R^{G \times V} lϵRG×V - 根据z计算的对数
- n k = − l o g ( − l o g ( u k ) ) n_k = -log(-log(u_k)) nk=−log(−log(uk))
- u k u_k uk 从均匀分布 U(0, 1) 中采样
- 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/949911
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

