
- 1stm32 SPI的从机中断接收_stm32f1 spi slave 中断接收 hal_nvic
- 2(18章)Python Flask 全流程全栈项目实战
- 3鸿蒙HarmonyOS-SDK管理使用指南_鸿蒙查看sdk
- 4【MySQL】学习如何通过DML更新数据库的数据
- 5.sh文件作用_.sh是什么脚本
- 6Docker 面试知识点_面试 docker
- 7python(django-vue3)项目win-win迁移_windows之间迁移python
- 8【RocketMQ】客户端报大量warn日志:No topic route info in name server for the topic:RMQ_SYS_TRACE_TOPIC、TBW102
- 9Ubuntu Linux 下安装和卸载cmake 3.28.2版本_cmake linux 卸载
- 10python实战项目电影推荐_7个Python实战项目代码,让你感受下大神是如何起飞的!...
《PyTorch深度学习实践》学习笔记:反向传播_深度学习forward能返回多少个值
赞
踩
一、反向传播
前馈计算:
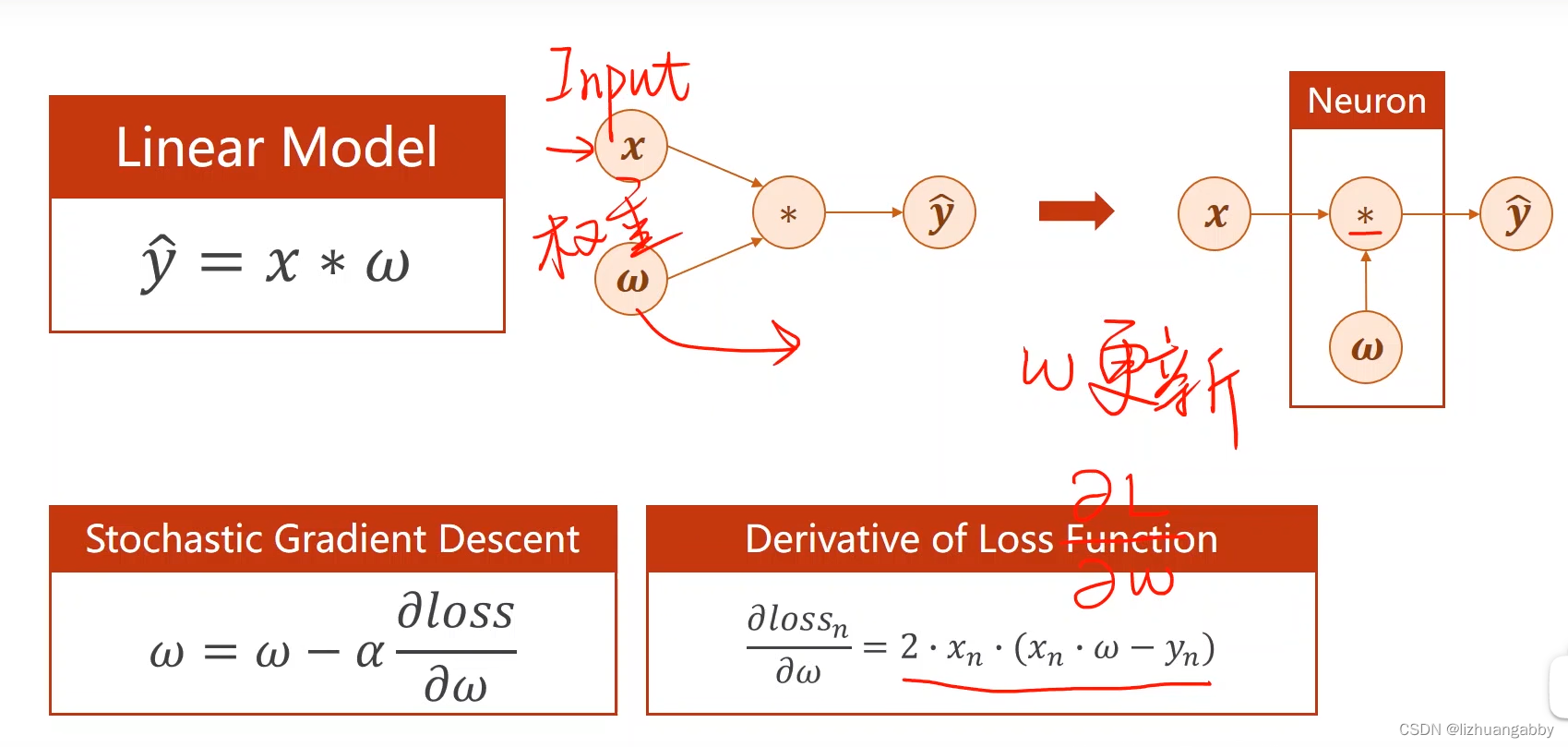
权重维度增加:
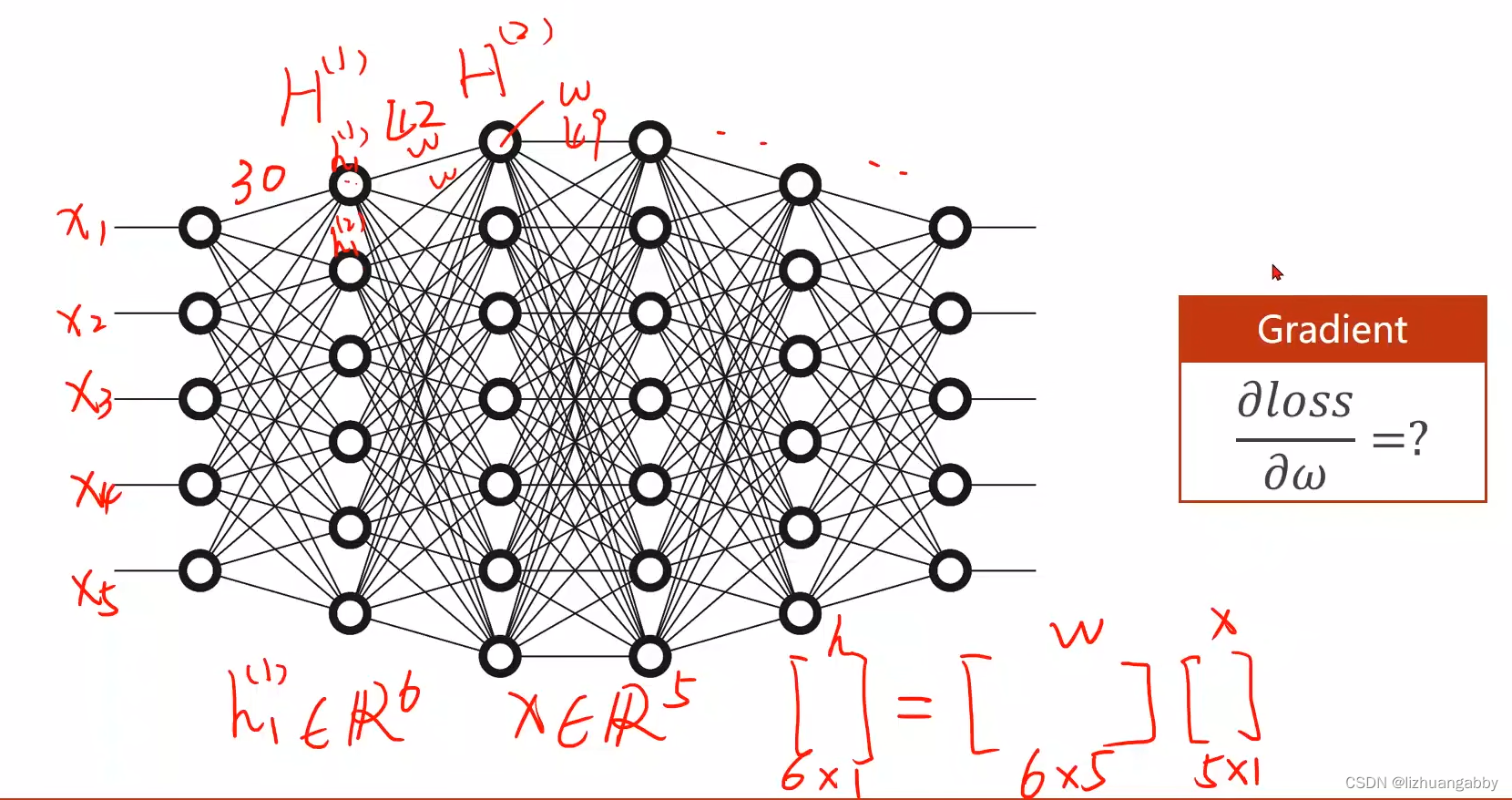
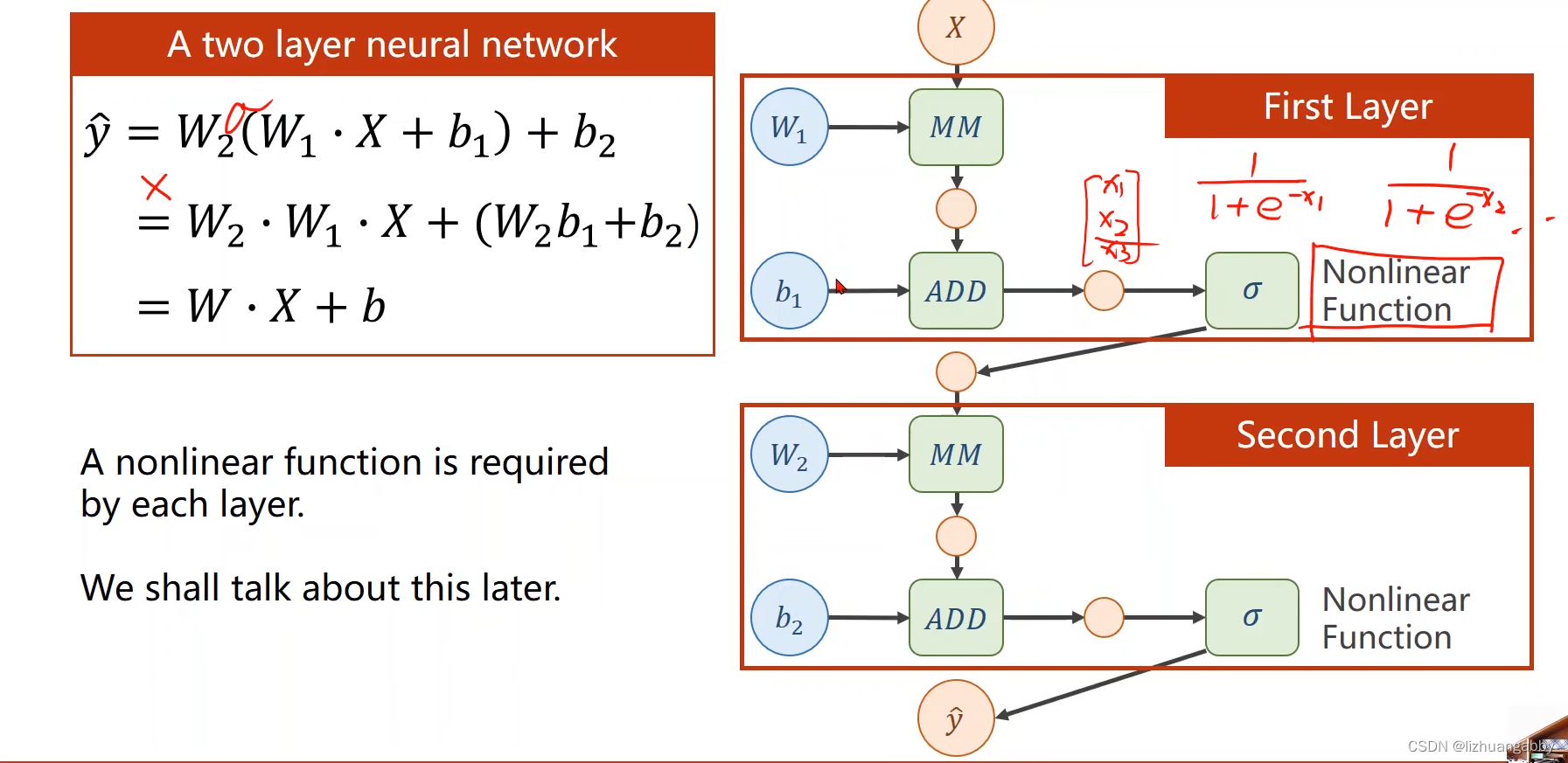
权重维度增加且增加多个层,但化简后还是线性的:

增加激活函数,从而增加非线性:
反向传播计算梯度,使用的是链式法则:
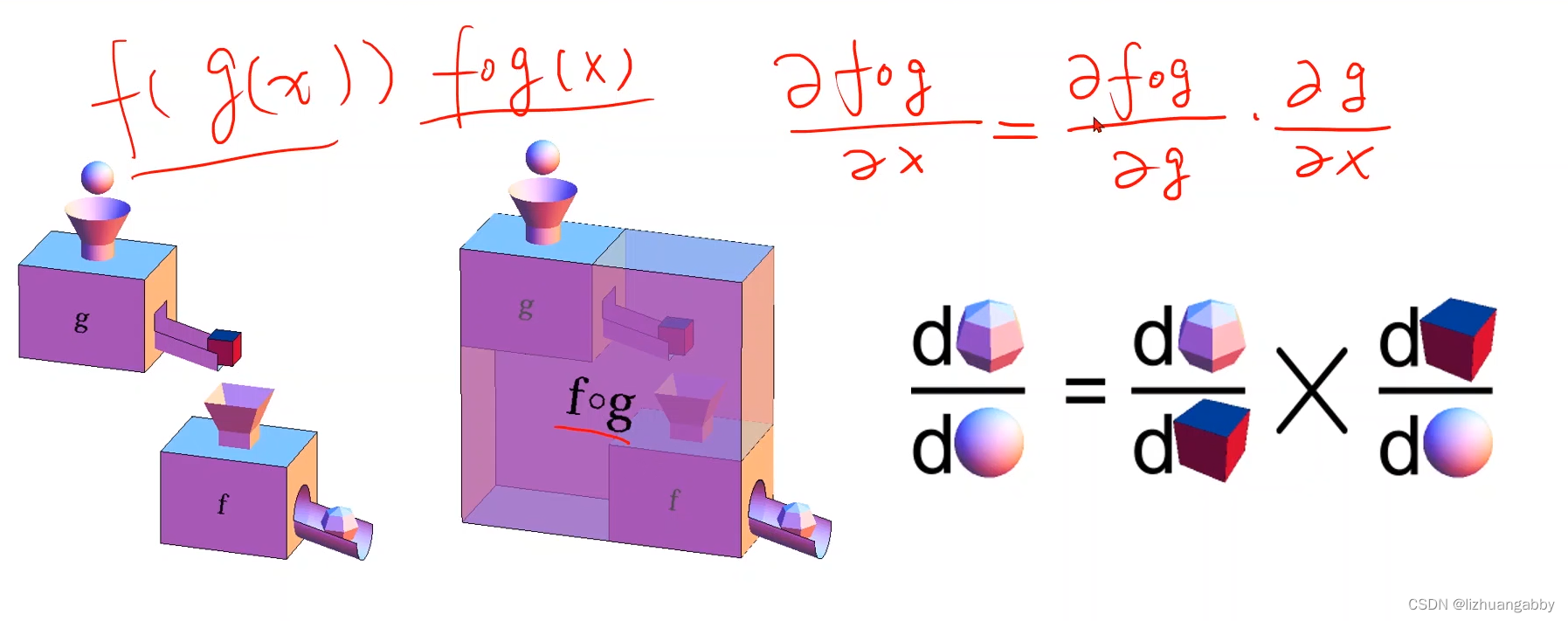
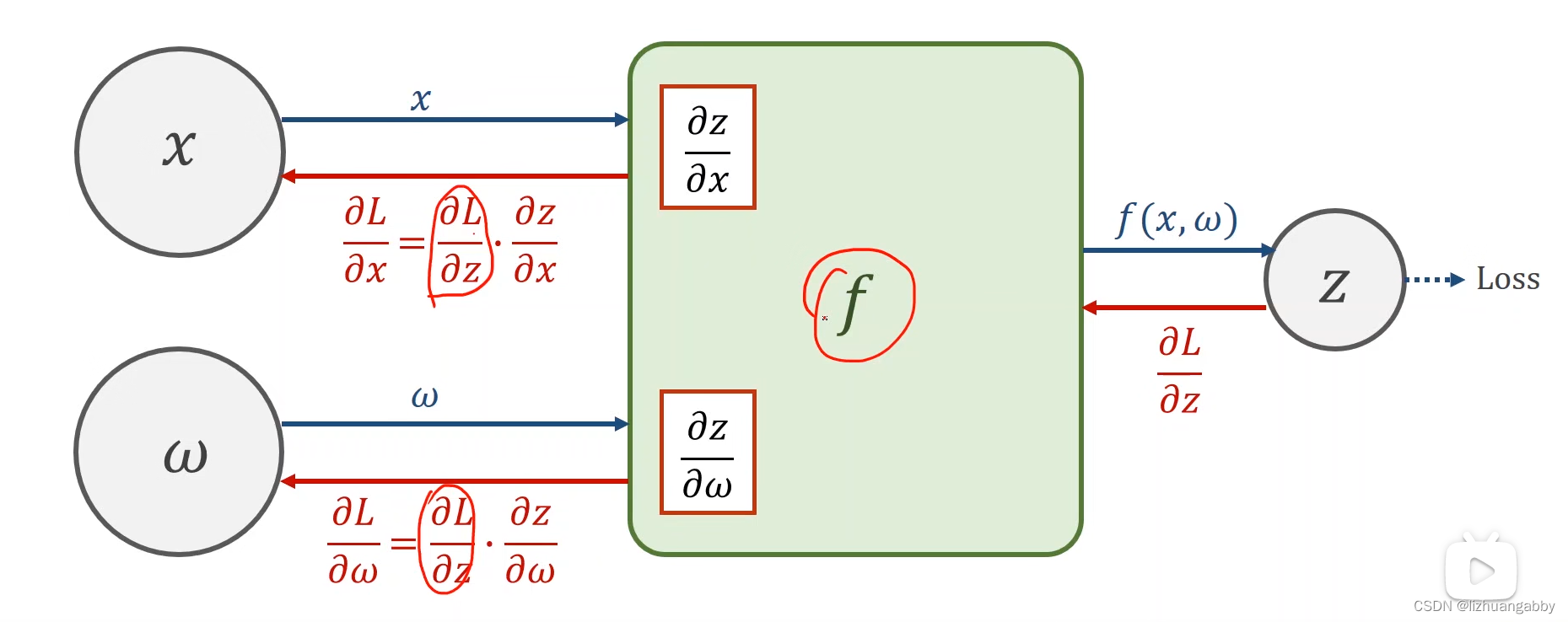
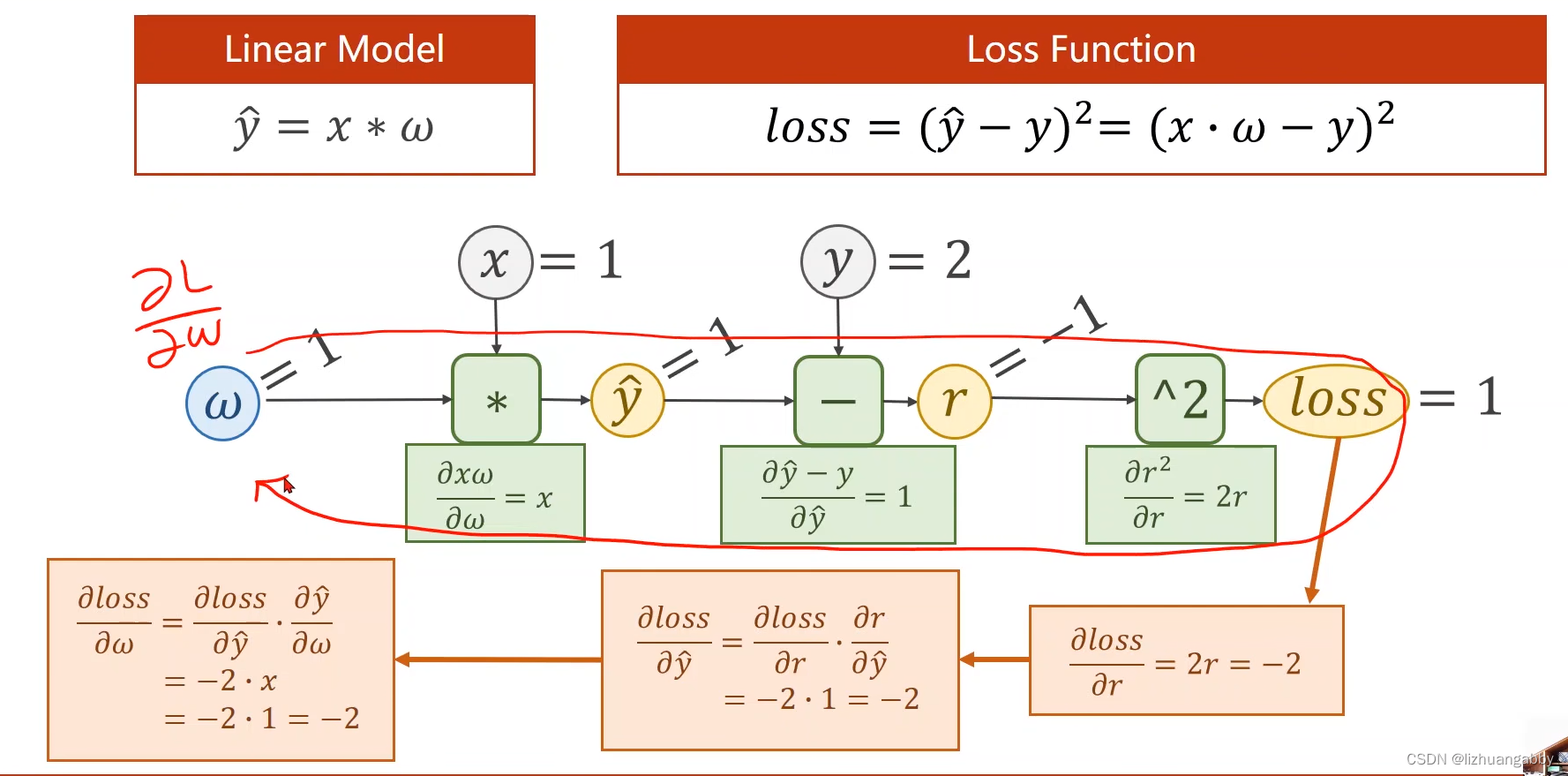
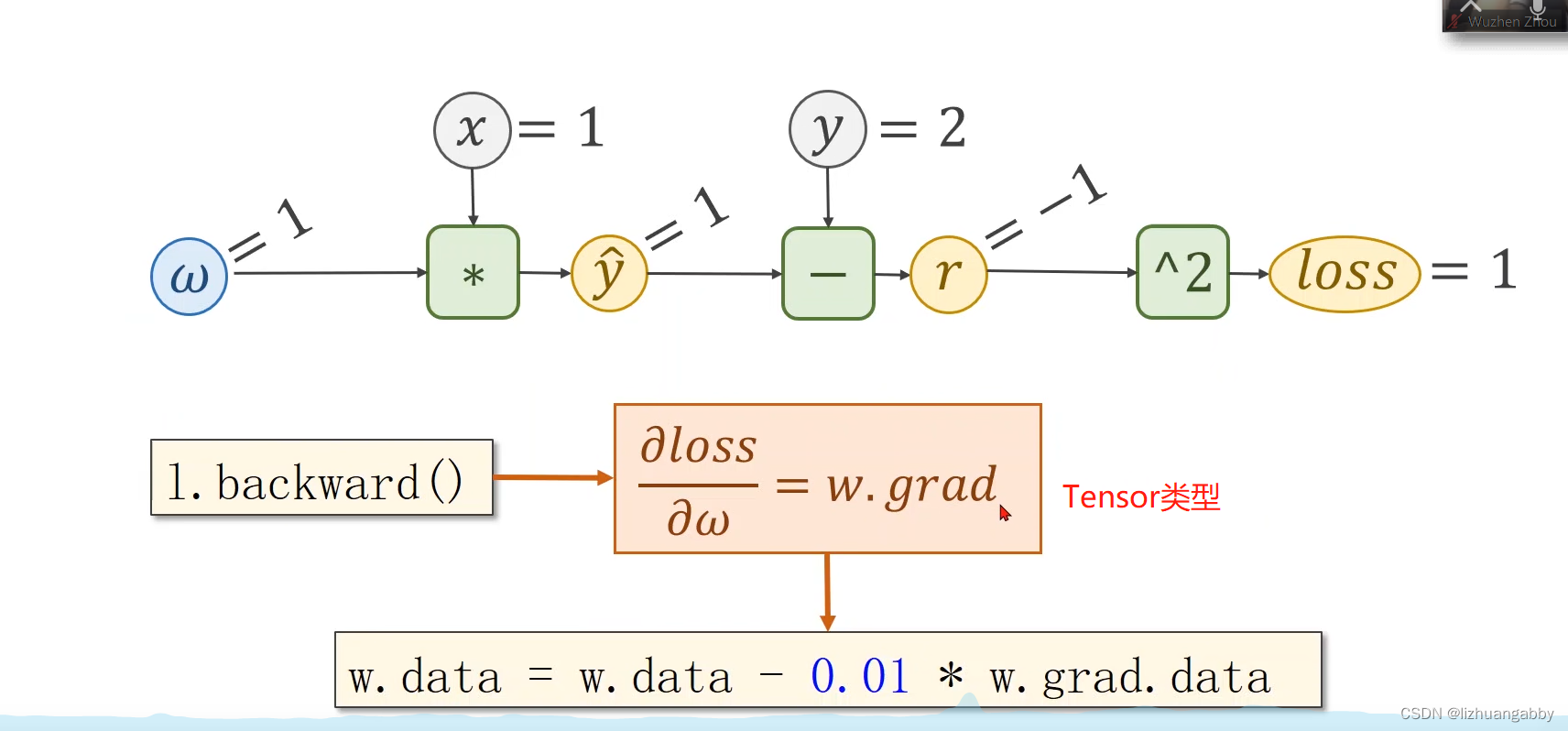
Pytorch里面数据类型Tensor,有两个属性一个data,一个grad:

-
w是Tensor(张量类型),Tensor中包含data和grad,data和grad也是Tensor。grad初始为None,调用l.backward()方法后w.grad为Tensor,故更新w.data时需使用w.grad.data。如果w需要计算梯度,那构建的计算图中,跟w相关的tensor都默认需要计算梯度。
-
w是Tensor, forward函数的返回值也是Tensor,loss函数的返回值也是Tensor。
-
本算法中反向传播主要体现在,l.backward()。调用该方法后w.grad由None更新为Tensor类型,且w.grad.data的值用于后续w.data的更新。
-
l.backward()会把计算图中所有需要梯度(grad)的地方都会求出来,然后把梯度都存在对应的待求的参数中,最终计算图被释放。
-
取tensor中的data是不会构建计算图的。
参考:https://blog.csdn.net/bit452/article/details/109643481
二、代码练习
import torch x_data = [1.0,2.0,3.0] y_data = [2.0,4.0,6.0] w =torch.tensor([1.0]) w.requires_grad = True # 能够计算梯度 # 前向传播 def forward(x): return x * w # w是一个tensor,所以此处x会自动进行类型转换 # 损失函数 def loss(x,y): y_pred = forward(x) return (y_pred-y)**2 print("predict (before training)",4,forward(4).item()) for epoch in range(100): for x,y in zip(x_data,y_data): l = loss(x,y) # l是一个张量,tensor主要是在建立计算图 forward, compute the loss l.backward() # 能够计算梯度 print("\tgrad:",x,y,w.grad.item()) w.data = w.data - 0.01 * w.grad.data # 权值更新 w.grad.data.zero_() print('progress:',epoch+1,l.item()) print("predict (after training)",4,forward(4).item())

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
输出结果:
predict (before training) 4 4.0
grad: 1.0 2.0 -2.0
grad: 2.0 4.0 -7.840000152587891
grad: 3.0 6.0 -16.228801727294922
progress: 1 7.315943717956543
grad: 1.0 2.0 -1.478623867034912
grad: 2.0 4.0 -5.796205520629883
grad: 3.0 6.0 -11.998146057128906
progress: 2 3.9987640380859375
grad: 1.0 2.0 -1.0931644439697266
grad: 2.0 4.0 -4.285204887390137
grad: 3.0 6.0 -8.870372772216797
progress: 3 2.1856532096862793
…
…
progress: 98 9.094947017729282e-13
grad: 1.0 2.0 -7.152557373046875e-07
grad: 2.0 4.0 -2.86102294921875e-06
grad: 3.0 6.0 -5.7220458984375e-06
progress: 99 9.094947017729282e-13
grad: 1.0 2.0 -7.152557373046875e-07
grad: 2.0 4.0 -2.86102294921875e-06
grad: 3.0 6.0 -5.7220458984375e-06
progress: 100 9.094947017729282e-13
predict (after training) 4 7.999998569488525
三、课后练习
1、手动推导线性模型y=w*x,损失函数loss=(ŷ-y)²下,当数据集x=2,y=4的时候,反向传播的过程。
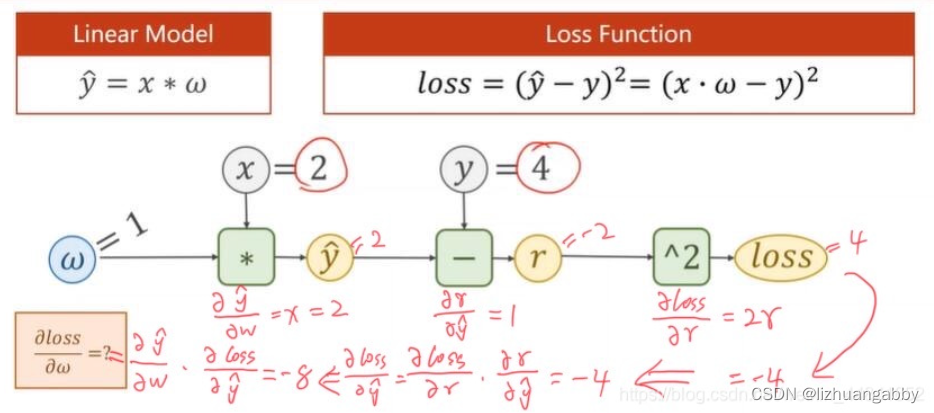
通过链式法则从后向前计算梯度,然后乘起来。
2、手动推导线性模型 y=w*x+b,损失函数loss=(ŷ-y)²下,当数据集x=1,y=2的时候,反向传播的过程。
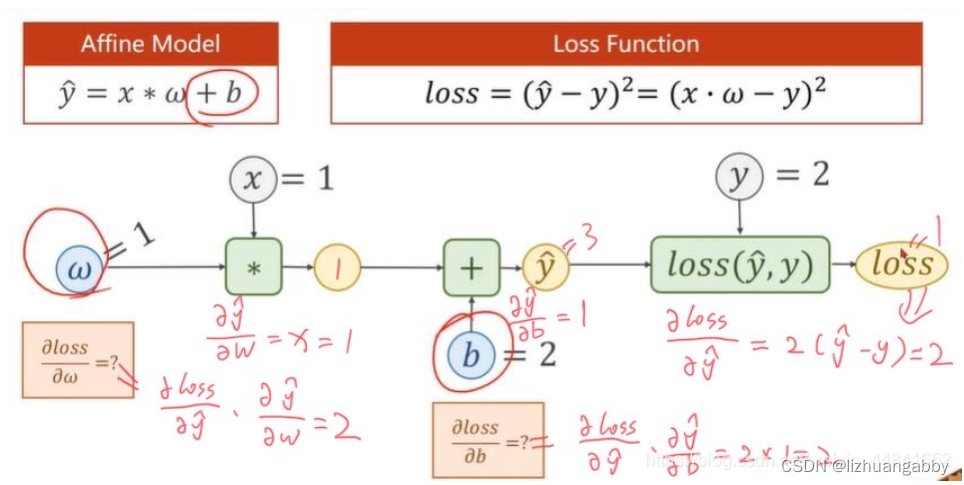
3、画出二次模型y=w1x²+w2x+b,损失函数loss=(ŷ-y)²的计算图,并且手动推导反向传播的过程。
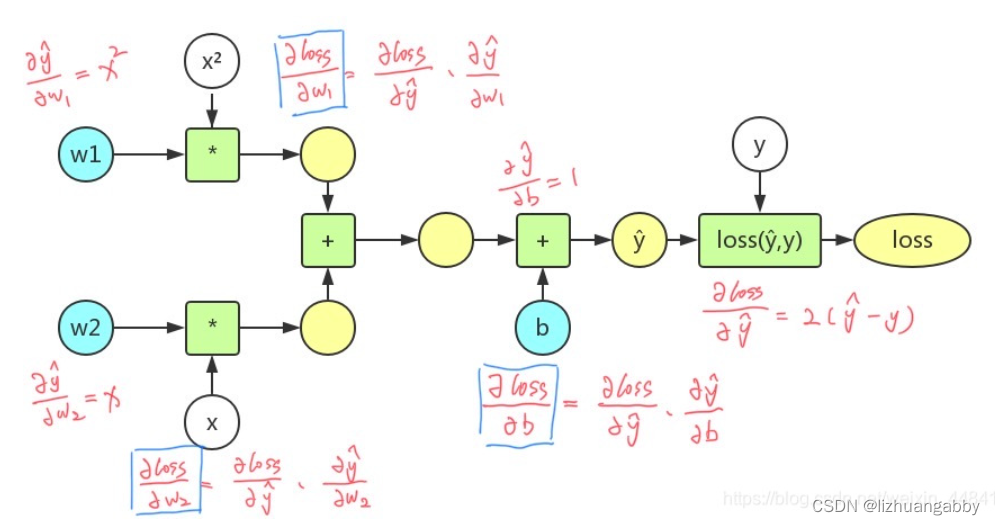
代码实现:
import torch import matplotlib.pyplot as plt x_data = [1.0,2.0,3.0] y_data = [2.0,4.0,6.0] w1 =torch.tensor([1.0]) w1.requires_grad = True # 能够计算梯度 w2 = torch.tensor([1.0]) w2.requires_grad = True b = torch.tensor([1.0]) b.requires_grad = True # 前向传播 def forward(x): return x * w1 + x * w2 + b # w是一个tensor,所以此处x会自动进行类型转换 # 损失函数 def loss(x,y): y_pred = forward(x) return (y_pred-y)**2 print("predict (before training)",4,forward(4).item()) epoch_list = [] l_list = [] for epoch in range(100): for x,y in zip(x_data,y_data): l = loss(x,y) # l是一个张量,tensor主要是在建立计算图 forward, compute the loss l.backward() # 能够计算梯度 print("\tgrad:",x,y,w1.grad.item(),w2.grad.item(),b.grad.item()) w1.data = w1.data - 0.01 * w1.grad.data # 权值更新 w2.data = w2.data - 0.01 * w2.grad.data b.data = b.data - 0.01 * b.grad.data w1.grad.data.zero_() w2.grad.data.zero_() b.grad.data.zero_() epoch_list.append(epoch+1) l_list.append(l.item()) print('progress:',epoch+1,l.item()) print("predict (after training)",4,forward(4).item()) # 画图 plt.plot(epoch_list,l_list) plt.xlabel("epoch") plt.ylabel("loss") plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
运行结果:
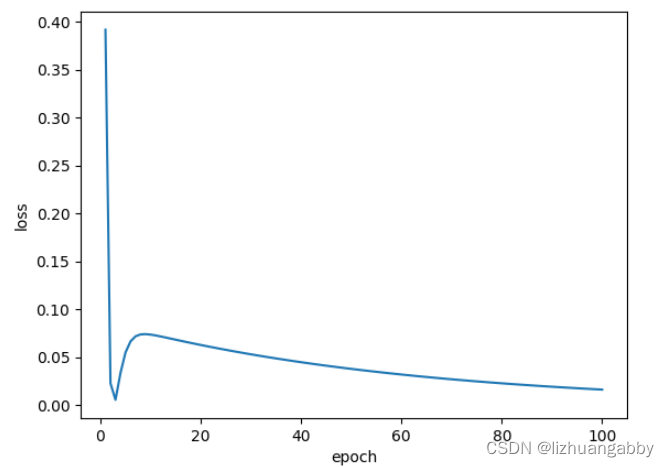
predict (before training) 4 9.0
grad: 1.0 2.0 2.0 2.0 2.0
grad: 2.0 4.0 3.6000003814697266 3.6000003814697266 1.8000001907348633
grad: 3.0 6.0 3.7559995651245117 3.7559995651245117 1.251999855041504
progress: 1 0.3918759226799011
grad: 1.0 2.0 1.5247201919555664 1.5247201919555664 1.5247201919555664
grad: 2.0 4.0 1.9960155487060547 1.9960155487060547 0.9980077743530273
grad: 3.0 6.0 0.9098911285400391 0.9098911285400391 0.3032970428466797
progress: 2 0.02299727313220501
grad: 1.0 2.0 1.2909746170043945 1.2909746170043945 1.2909746170043945
grad: 2.0 4.0 1.2208232879638672 1.2208232879638672 0.6104116439819336
grad: 3.0 6.0 -0.4541959762573242 -0.4541959762573242 -0.1513986587524414
progress: 3 0.0057303886860609055
…
…
grad: 1.0 2.0 0.4869418144226074 0.4869418144226074 0.4869418144226074
grad: 2.0 4.0 0.22666168212890625 0.22666168212890625 0.11333084106445312
grad: 3.0 6.0 -0.7815885543823242 -0.7815885543823242 -0.2605295181274414
progress: 98 0.01696890778839588
grad: 1.0 2.0 0.4828662872314453 0.4828662872314453 0.4828662872314453
grad: 2.0 4.0 0.22476577758789062 0.22476577758789062 0.11238288879394531
grad: 3.0 6.0 -0.7750482559204102 -0.7750482559204102 -0.2583494186401367
progress: 99 0.016686106100678444
grad: 1.0 2.0 0.47882509231567383 0.47882509231567383 0.47882509231567383
grad: 2.0 4.0 0.2228851318359375 0.2228851318359375 0.11144256591796875
grad: 3.0 6.0 -0.7685623168945312 -0.7685623168945312 -0.25618743896484375
progress: 100 0.016408000141382217
predict (after training) 4 7.762168884277344
总结
本节学习了反向传播,主要使用的pytorch的l.backward(),通过保存中间运算结果的梯度值。在用y=w1x²+w2x+b的模型训练100次后可以看到当x=4时,y=7.762168884277344,与一次函数相比存在一定的差距。原因可能是数据集本身是一次函数的数据,模型是二次函数。所以模型本身就不适合这个数据集,所以才导致预测结果和正确值相差比较大的情况。
参考:https://blog.csdn.net/weixin_44841652/article/details/105046519

