
热门标签
热门文章
- 1国内外知名安全厂商防火墙默认登录地址、用户名、密码大全,建议收藏备用!_登录密码大全
- 2Linux Ubuntu搭建我的世界Minecraft服务器实现好友远程联机MC游戏
- 3K8S系列二:实战入门_kubectl 部署pod
- 4MYSQL解决“plugin caching_sha2_password could not be loaded”
- 5【Python】numpy矩阵运算大全_python 矩阵
- 6什么是云服务器ECS - 云服务器 ECS - 阿里云
- 7【Unity】AI实战应用——Unity接入GPT和对游戏开发实际应用的展望
- 8【区块链】区块链技术学习总结
- 9HarmonyOS 应用开发配置—Stage模型以及应用/组件级配置详解【鸿蒙专栏-18】
- 10【IDEA】瑞_IDEA模版注释设置_IDEA自动生成注释模版(详细图文步骤)
当前位置: article > 正文
【python】B站电影爬虫_python爬取b站付费视频
作者:二进制舞者2 | 2024-02-04 20:39:22
赞
踩
python爬取b站付费视频
有时我们苦于在线观看网络太慢
有时我们苦于大会员即将到期却没有时间看想看的电影
有时我们苦于付费电影只有三天的观看期限
有时我们苦于有想多次细细品尝的电影但B站却无法下载
… … -。- … …
为能更好地使用我们大会员的权利,这里提供一种下载B站电影的爬虫方法
一. 抓包
这里直接使用浏览器的开发者工具,选择 Network,在里面找属于音频和视频的数据包(B站的音频和视频传过来的时候是分开的)
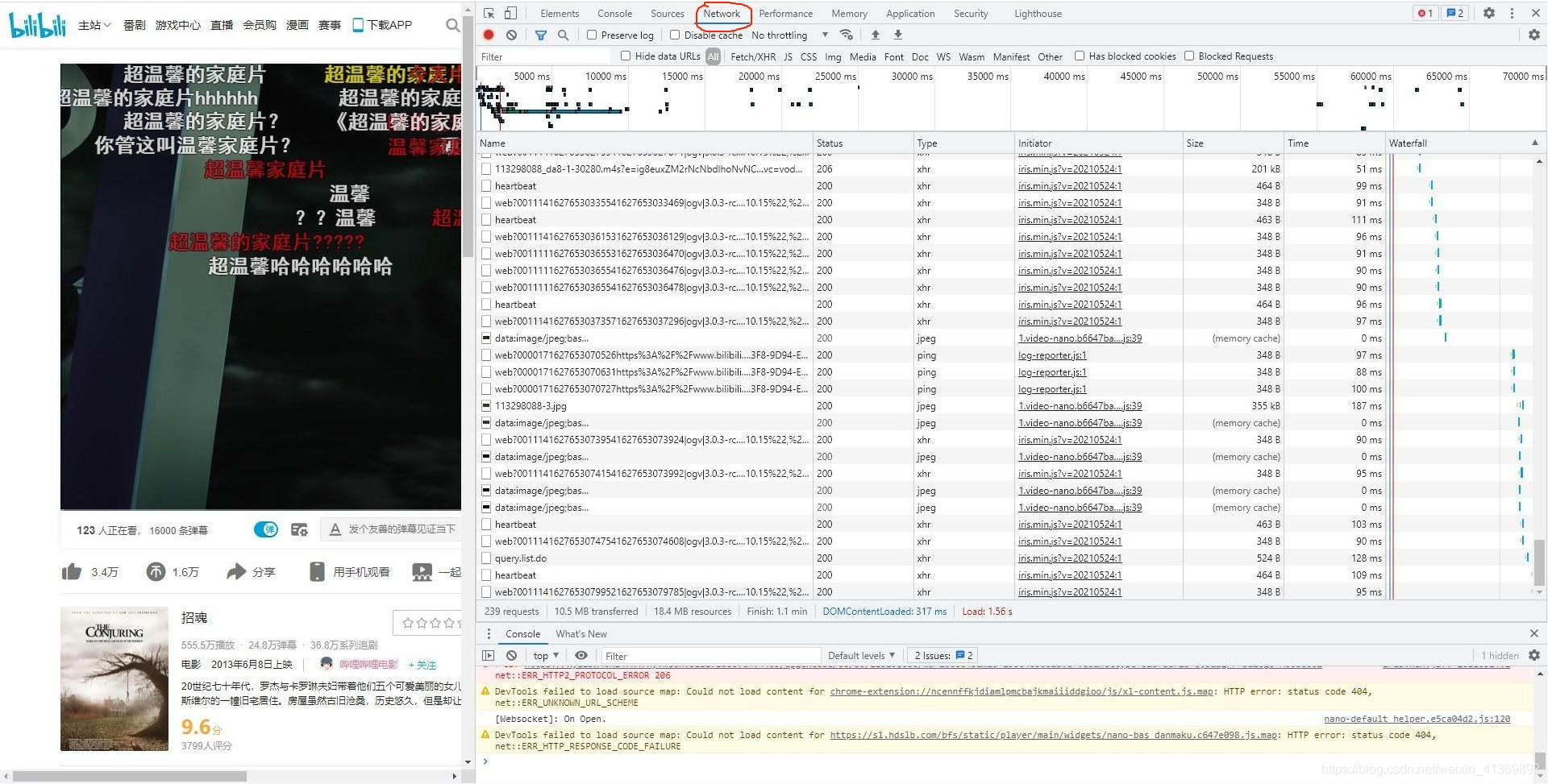
一般为这几个,视频一般为 “-1-30112”,音频为 “-1-30280”,不过这个也可以根据点开后看数据包的大小得知,一般视频比音频的比特数大得多

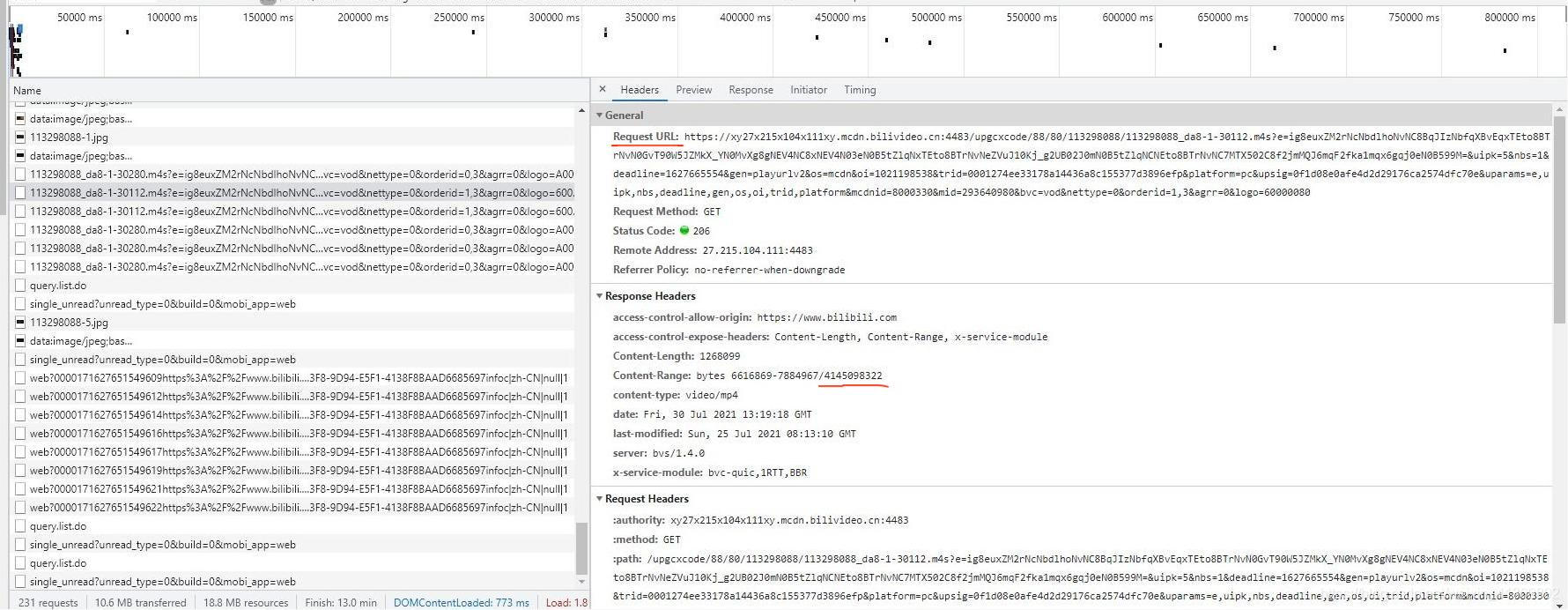
接下来点开其中一个,复制下 Request URL 中的内容和视频文件的比特数(对于音频文件也一样)
这是视频的:
这是音频的:
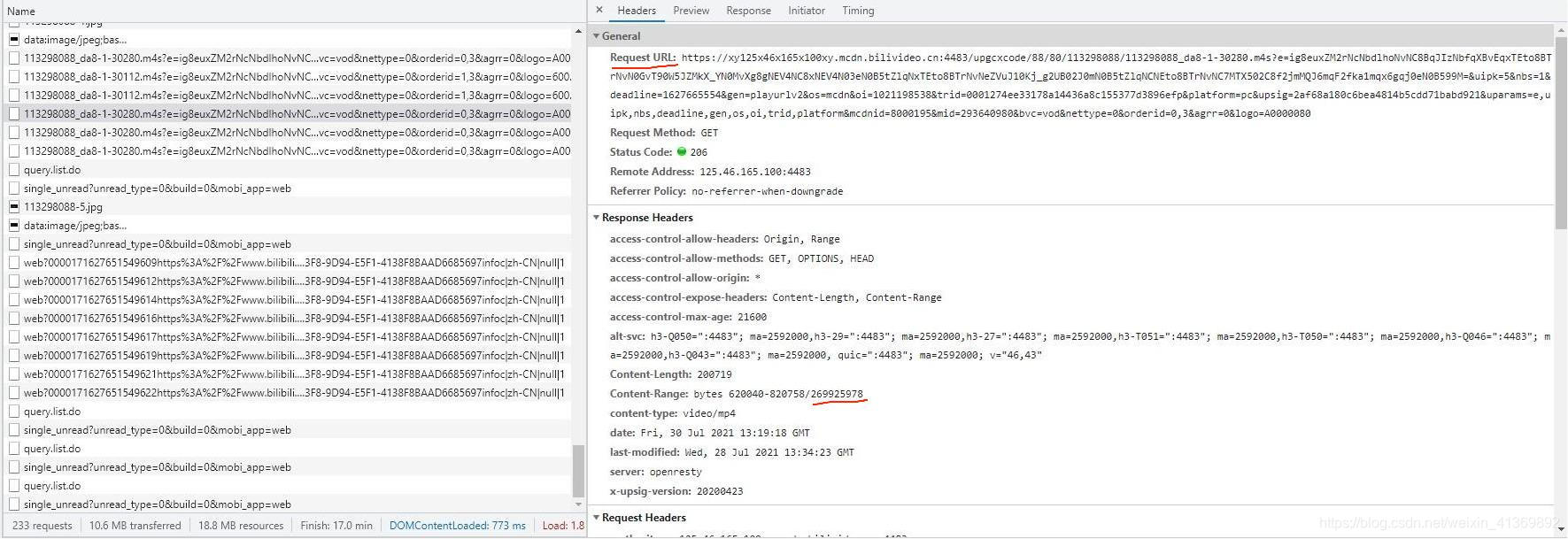
二. 爬取
在代码相应位置填入刚才复制的四条信息(位置在代码注释中有标注)
code:
import requests import os class Spider: def __init__(self, urls: dict, video_bits: int, sound_bits: int): self.video_header = { 'accept-language': 'zh-CN,zh;q=0.9', 'range': 'bytes=0-{}'.format(str(video_bits - 1)), 'referer': 'https://www.bilibili.com', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36', } self.sound_header = { 'accept-language': 'zh-CN,zh;q=0.9', 'range': 'bytes=0-{}'.format(str(sound_bits - 1)), 'referer': 'https://www.bilibili.com', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36' } self.urls = urls def get_video(self, filename): url = self.urls['video'] r = requests.get(url, headers=self.video_header) print(r.status_code) with open(filename, 'wb') as file: file.write(r.content) return 0 def get_sound(self, filename): url = self.urls['sound'] r = requests.get(url, headers=self.sound_header) print(r.status_code) with open(filename, 'wb') as file: file.write(r.content) return 0 def merge(self, filename, videofile, soundfile, ffmpeg_path): os.system('{} -i {} -i {} -vcodec copy -acodec copy {}'.format( ffmpeg_path, videofile, soundfile, filename )) return 0 if __name__ == '__main__': urls = { 'video': "", # 这里是抓包到的视频的url 'sound': "" # 这里是抓包到的音频的url } sider = Spider(urls, None, None) # 这里两个 None 分别是视频的比特数和音频的比特数 sider.get_sound('./_sound.mp4') sider.get_video('./_video.mp4') # sider.merge('./_.mp4', './_video.mp4', './_sound.mp4', 'ffmpeg.exe')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
三. 整合音频和视频
在代码最后注释一段有使用 ffmpeg 进行整合的方法,也可以使用其他工具整合。
大功告成了,接下来好好享受电影吧
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/59842
推荐阅读


相关标签

