
- 1dubbo负载均衡-RandomLoadBalance
- 2机器学习笔记(4)——多变量线性回归
- 3Android Studio App开发实战项目之实现淘宝电商App首页界面(附源码,可用于大作业参考)_android 淘宝代码
- 4鸿蒙harmonyOS 在DevEco Studio 安装应用时出现 INSTALL_PARSE_FAILED_USESDK_ERROR
- 5Tool-X 工具汇总
- 6STM32学习记录——光敏传感器的使用_stm32光敏传感器
- 7关于目标检测中按照比例将数据集随机划分成训练集和测试集
- 8yolov5 部署jetson nano(通用) 保姆级教学_yolov5部署到nano保姆级教程
- 9Android开发-网络请求框架okhttp3的使用_android okhttp3
- 10【物联网】液滴即信息:雨滴探测传感器实验解析降雨的密码_ps2操作杆实验目的
【python学习】利用python爬取B站视频并转化为字符视频_pycharm爬取b站视频封装注释
赞
踩
准备工作:
1、python3.x(我使用的是Windows下的python3.7)
2、编辑器(我用的是PyChram)
需要的第三方库和工具
1、PIL库(一个图形处理框架库)
2、cv2
3、FFmpeg,
4、you-get
5、beautifulsoup
第三方库和工具的安装
1、PIL库的安装:安装pillow库 使用命令 pip install pillow,如果之前同时安装了python2和python3的haunt,则使用pip3 install pillow来安装
2、FFmpeg的安装:在官网下载FFmpegffmpeg下载官网,将安装路径下的bin配置到环境变量如下图:
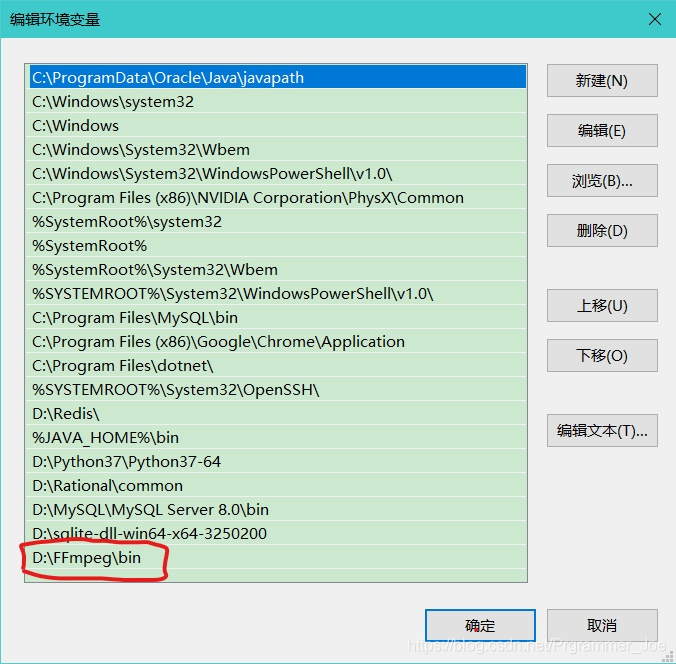
3、you-get安装:pip install you-get
4、cv2的安装:在python3下,cv2不能直接安装,需要安装OpenCV来做桥梁使用cv2。安装方式:pip install opencv
5、beautifulsoup安装:pip install beautifulsoup
整体思路
一、爬取B站视频:
-
分析:
首先用beautifulsoup试着爬了一下,失败,爬取不到自己想要的视频列表信息。最后一看,B站是动态加载的网页,不能通过这种方式爬取内容。 -
分析ajax:
打开B站,选着一个分类(我选的是宅舞,不要问我为什么,我也不知道),按下F12,选择js,然后在按下F5(部分可能会因为电脑护着浏览器的原因,需要按下Alt+F12还是FN+F12哦,我也记不清楚了,试一下就出来了),如下图: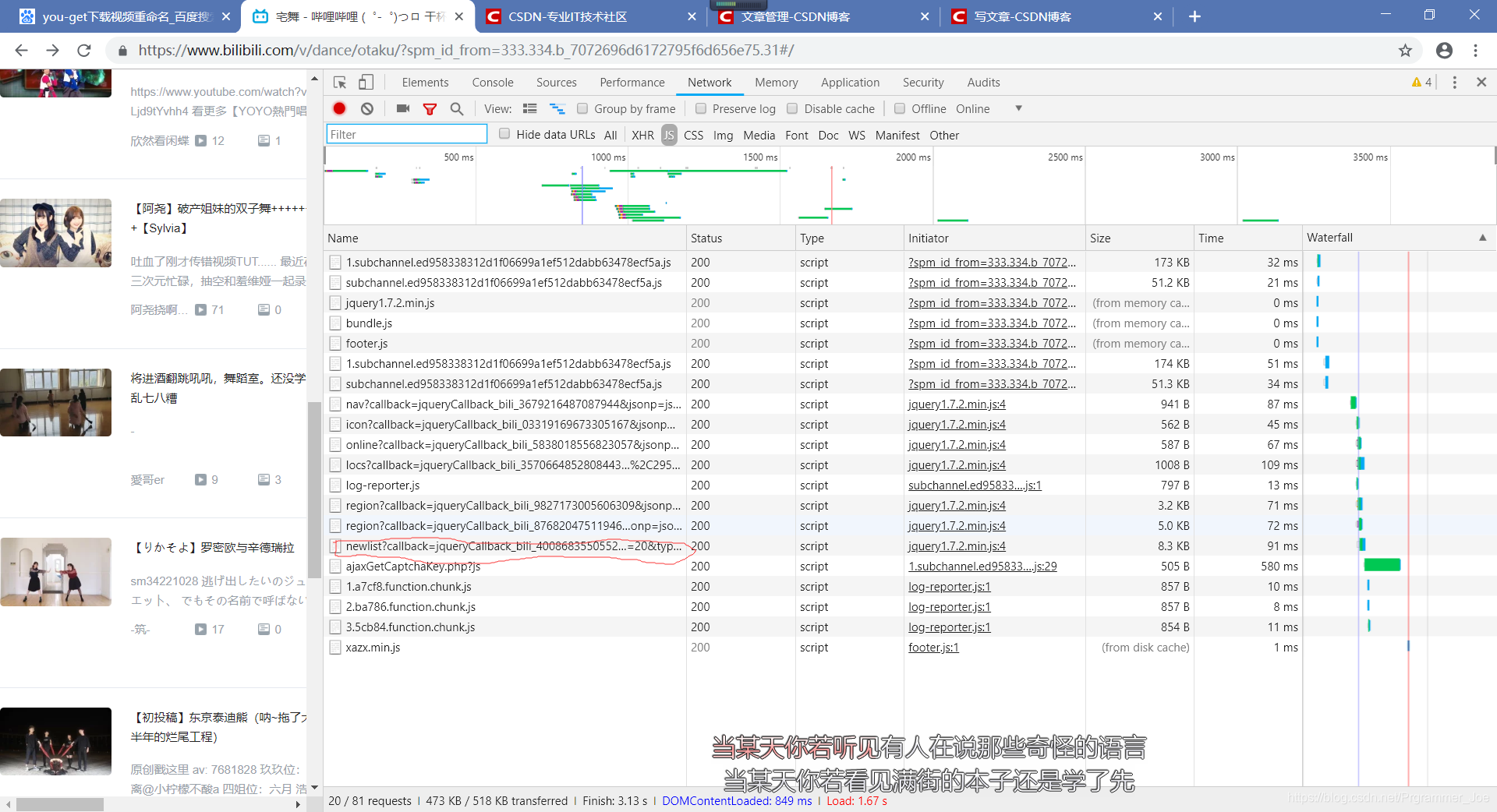 在这里可以看到有一个newlist?callback巴拉巴拉的东西,对,没错,就是这个,很关键。点进去一看,好家伙,信息量真不少:
在这里可以看到有一个newlist?callback巴拉巴拉的东西,对,没错,就是这个,很关键。点进去一看,好家伙,信息量真不少: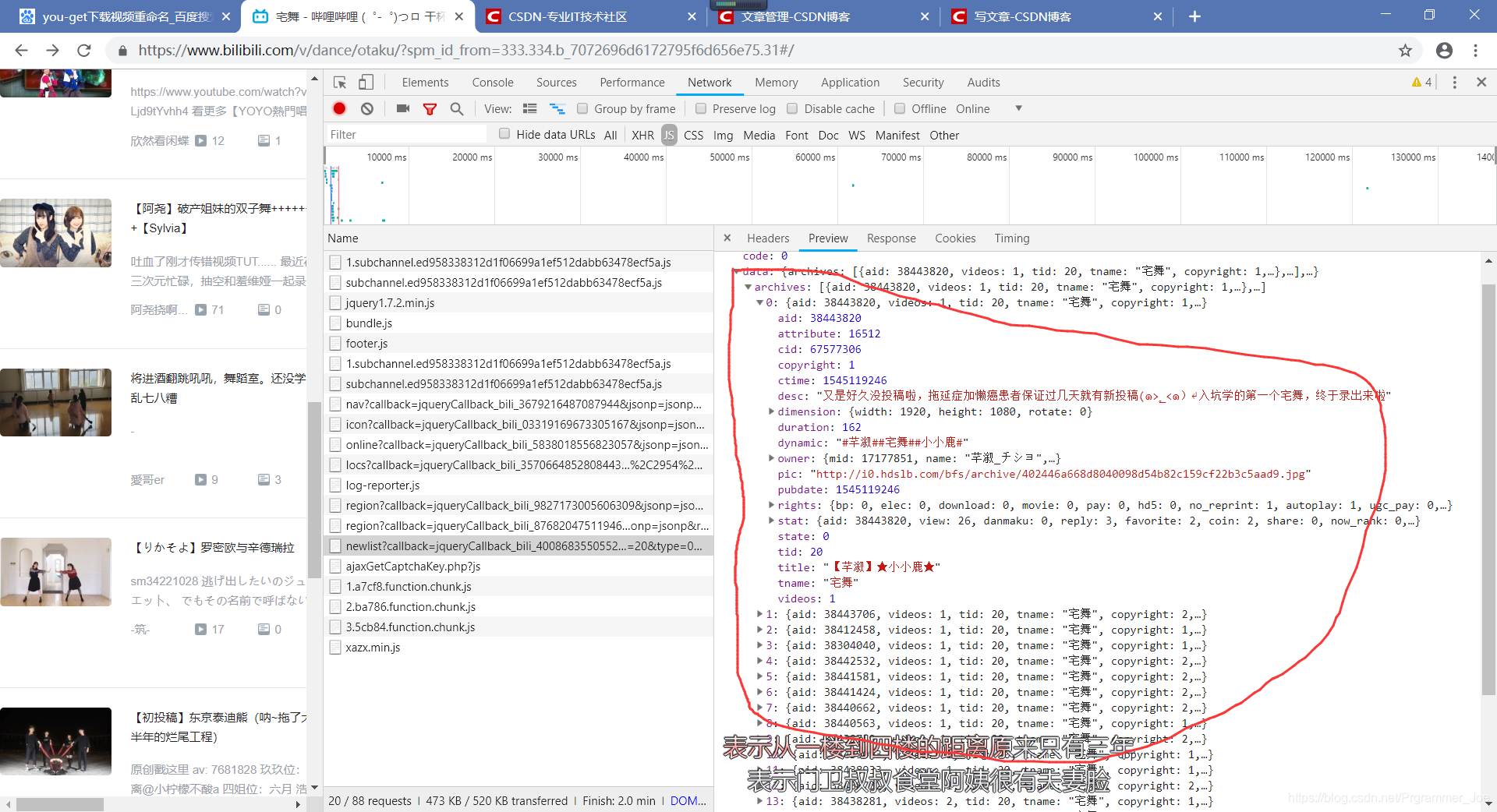
这里面的Jason信息居然就是我们所需要的视频列表,是不是很激动,感觉要成功了。不急,跟着我一步一步走: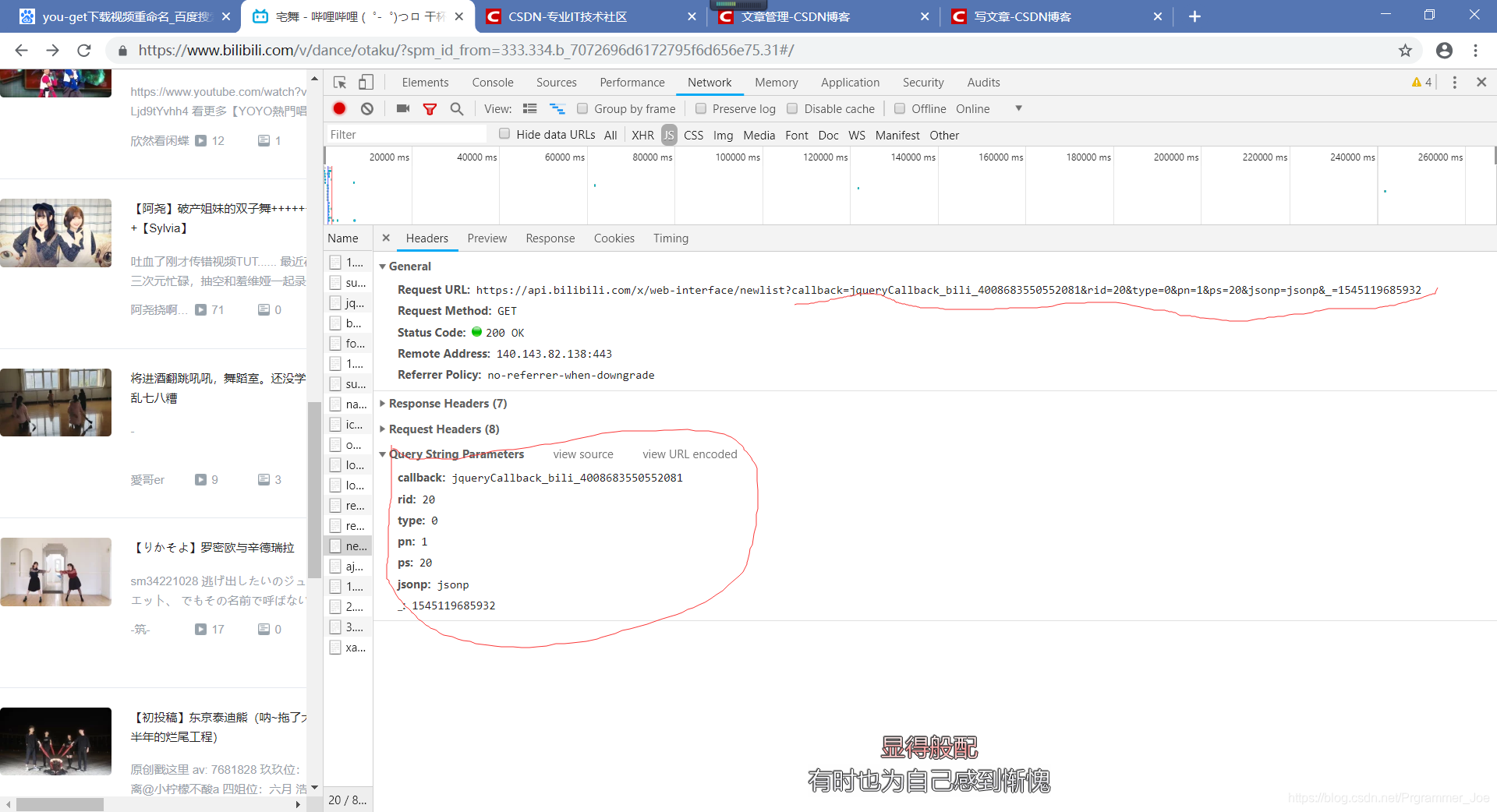
是不是发现了什么,对,这个URL后面的参数就是下面的参数合起来的,然后我们试着访问这个URL,发现403。这其实是一个坑,我们必须去掉jsonp这个参数才行。好了,可以访问了,访问结果如下: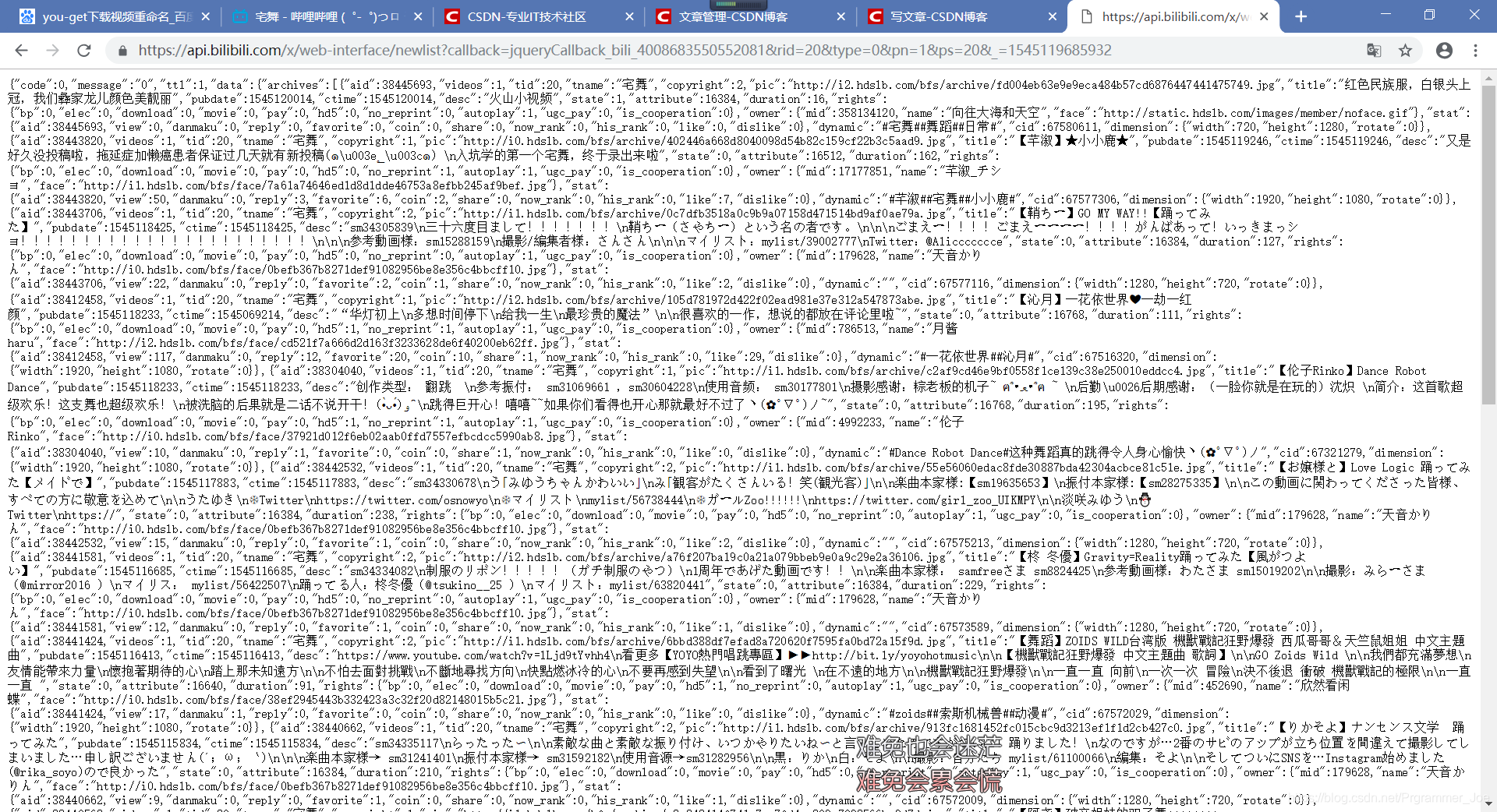
好了,这就是我们所需要的,那是不是快要成功了呢?是也不是,因为我在这里也遇见了问题,还没有解决,各位要是有解决的办法,可以提出来大家探讨一下,再次谢过。
{【问题】:无法动态获取rid的参数。}。没错,这里只需要rid的值,而仔细一看,每个类别的rid值都不一样,那我们就可以实现半动态自主获取的目标了 -
视频播放时的URL,我们很容易可以看出https://www.bilibili.com/video/av+aid号组成的,那就方便了,我们只需要aid号和每个视频的title就可以了
-
代码部分:
import requests class bilibili_urls(): def biliRequest(self,url): try: bili_request = requests.get(url) bili_request.raise_for_status() bili_request.encoding = 'utf-8' return bili_request.text except: return '' def vidio_Information(self,url): dic1 = eval(self.biliRequest(url)) aid = [] title = [] #video = {} for i in dic1.keys(): if i == 'data': dic2 = dic1[i] for j in dic2.keys(): if j == 'archives': lst = eval(str(dic2[j])) for i in lst: for j in i.keys(): if j == 'aid': aid.append("https://www.bilibili.com/video/av"+str(i[j])) if j == 'title': title.append(str(i[j]).replace(" ", "")) if j =='rights': break return aid,title def bili_urls(self): self.URLS = {'宅舞': '20','三次元舞蹈': '154','舞蹈教程': '156'} self.url = '' for i in self.URLS: print(i) a = input("请输入要选择的类别:") for i in self.URLS.keys(): if i == a: self.url = "https://api.bilibili.com/x/web-interface/newlist?rid="+str(self.URLS[i]) return self.url if __name__ == '__main__': #url = "https://api.bilibili.com/x/web-interface/newlist?rid=20" #bilibili_urls().vidio_Information(url) url = bilibili_urls().bili_urls() #bilibili_urls().biliRequest(url) bilibili_urls().vidio_Information(url)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 通过you-get下载视频:
import subprocess
def vedio_download(self,path,url,rename):def vedio_download(self,path,url,rename):
getVideo = 'you-get -o '+path+' '+'-O '+rename+' '+url
download = subprocess.call(getVideo,shell=True)
- 1
- 2
- 3
- 4
二、处理视频:
- 提取音频:
def frequency(self,video_path,frequency_path):
getfrequency = 'ffmpeg -i '+video_path+' -f mp3 '+ frequency_path
subprocess.call(getfrequency,shell=True)
- 1
- 2
- 3
- 字符处理:字符处理有点麻烦。
但是步骤都很简单:但是步骤都很简单:
-
首先:自定义一个列表,里面就是要转化的字符
-
. 其次:将图片按照一定的比例缩小,根据像素读取RGB,保存RGB,根据RGB转化为不同的灰度。
-
. 然后:将灰度值通过映射的方法转化为字符,然后重新绘制图片并保存
3.合成视频:合成需要图片和音频,直接调用ffmpeg竟合成:
def compound(self,picture_path,frequency_path,video_path,fps):
getmp4 = 'ffmpeg -y -r ' + fps + ' -i ' + picture_path + '\\framed%d.jpg' + ' -i ' + frequency_path + ' -absf aac_adtstoasc ' + '' + video_path
compound = subprocess.call(getmp4,shell=True)`
- 1
- 2
- 3
三、所有代码
video_cut.py (视频剪切的完整代码):
import cv2 import os class video_cut(): def cut(self,video_path,picture_path): vidcap = cv2.VideoCapture(video_path) count = 0 success = True while success: success, image = vidcap.read() cv2.imwrite(picture_path +'\\'+ "{}.jpg".format(count), image) if cv2.waitKey(10) == 27: break count += 1 os.remove(picture_path+'\\'+"{}.jpg".format(count-1)) return count-1 if __name__ == '__main__': video_path = r'G:\1234\1234\山职净土.flv' picture_path = r'G:\1234\1234\2' m = video_cut() count = m.cut(video_path,picture_path) print(count)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
char_deal.py (字符处理完整代码):
from PIL import Image from PIL import ImageDraw from PIL import ImageFont import os ascii_char = list("MNHQ$OC67+>!:-. ") class char_deal(): def get_char(self,r, g, b, alpha=256): if alpha == 0: return '' length = len(ascii_char) gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b) unit = (256.0 + 1) / length return ascii_char[int(gray / unit)] # 将txt转换为图片 def txtjpg(self,path, savepath): os.mkdir(savepath) filelist = os.listdir(path) for file_name in filelist: im = Image.open(path + '\\' + file_name).convert('RGB') # gif拆分后的图像,需要转换,否则报错,由于gif分割后保存的是索引颜色 raw_width = im.width raw_height = im.height width = int(raw_width / 6) height = int(raw_height / 15) im = im.resize((width, height), Image.NEAREST) txt = "" colors = [] for i in range(height): for j in range(width): pixel = im.getpixel((j, i)) colors.append((pixel[0], pixel[1], pixel[2])) if (len(pixel) == 4): txt += self.get_char(pixel[0], pixel[1], pixel[2], pixel[3]) else: txt += self.get_char(pixel[0], pixel[1], pixel[2]) txt += '\n' colors.append((255, 255, 255)) im_txt = Image.new("RGB", (raw_width, raw_height), (255, 255, 255)) dr = ImageDraw.Draw(im_txt) font = ImageFont.load_default().font x = y = 0 font_w, font_h = font.getsize(txt[1]) # 获取字体的宽高 font_h *= 1.37 # 调整后更佳 # ImageDraw为每个ascii码进行上色 for i in range(len(txt)): if (txt[i] == '\n'): x += font_h y = -font_w dr.text([y, x], txt[i], colors[i]) y += font_w name = file_name.split('.')[0] + '-txt' + '.jpg' print(name) im_txt.save(savepath + '\\' + name) if __name__ == '__main__': path = r'G:\1234\1234\11' savapath = r'G:\1234\1234\12' char_deal().txtjpg(path,savapath)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
bilibili_urls.py (B站视频播放URL):
import requests class bilibili_urls(): def biliRequest(self,url): try: bili_request = requests.get(url) bili_request.raise_for_status() bili_request.encoding = 'utf-8' return bili_request.text except: return '' def vidio_Information(self,url): dic1 = eval(self.biliRequest(url)) aid = [] title = [] #video = {} for i in dic1.keys(): if i == 'data': dic2 = dic1[i] for j in dic2.keys(): if j == 'archives': lst = eval(str(dic2[j])) for i in lst: for j in i.keys(): if j == 'aid': aid.append("https://www.bilibili.com/video/av"+str(i[j])) if j == 'title': title.append(str(i[j]).replace(" ", "")) if j =='rights': break return aid,title def bili_urls(self): self.URLS = {'宅舞': '20','三次元舞蹈': '154','舞蹈教程': '156'} self.url = '' for i in self.URLS: print(i) a = input("请输入要选择的类别:") for i in self.URLS.keys(): if i == a: self.url = "https://api.bilibili.com/x/web-interface/newlist?rid="+str(self.URLS[i]) return self.url if __name__ == '__main__': #url = "https://api.bilibili.com/x/web-interface/newlist?rid=20" #bilibili_urls().vidio_Information(url) url = bilibili_urls().bili_urls() #bilibili_urls().biliRequest(url) bilibili_urls().vidio_Information(url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
folder_mkdir.py(文件夹创建的完整代码):
import os class folder_mkdir(): def mkdir(self,path): isExists = os.path.exists(path) if not isExists: os.mkdir(path) else: print("该文件夹已存在,是否继续操作:") print("1:是") print("2:否") while True: bool1 = eval(input()) if bool1 == 1: newPath = input("请输入新的路径名:") os.mkdir(newPath) return newPath elif bool1 == 2: return path else: print("抱歉,请输入正确操作") if __name__ == '__main__': path = input() folder_mkdir().mkdir(path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
video_deal.py(视频处理的完整代码):
import subprocess class video_deal(): def compound(self,picture_path,frequency_path,video_path,fps): getmp4 = 'ffmpeg -y -r ' + fps + ' -i ' + picture_path + '\\%d-txt.jpg' + ' -i ' + frequency_path + ' -absf aac_adtstoasc ' + ' ' + video_path compound = subprocess.call(getmp4,shell=True) def vedio_download(self,path,url,rename): getVideo = 'you-get -o '+path+' '+'-O '+rename+' '+url download = subprocess.call(getVideo,shell=True) def frequency(self,video_path,frequency_path): getfrequency = 'ffmpeg -i '+video_path+' -f mp3 '+ frequency_path subprocess.call(getfrequency,shell=True) def getTime(self,filename): conmand = ["ffprobe.exe", "-loglevel", "quiet", "-print_format", "json", "-show_format", "-show_streams", "-i", filename] result = subprocess.Popen(conmand, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) out = result.stdout.read() temp = str(out.decode('utf-8')) # return temp data = eval(temp) a = data["format"]['duration'] b = float(a) time = round(b) return time if __name__ == '__main__': picture_path = "G:\\1234\\python\\0\\diealpictures" frequency_path = "G:\\1234\\python\\0\\五毛钱大头特效,超强吸睛翻跳《恋爱循环》.mp3" fps = str(20) video_path = "G:\\1234\\python\\0\\1.mp4" video_deal().compound(picture_path,frequency_path,video_path,fps)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
main.py (运行的py文件):
from codes import bilibili_urls, video_cut,video_deal,folder_mkdir,char_deal path = [] url = bilibili_urls.bilibili_urls().bili_urls() aid, title = bilibili_urls.bilibili_urls().vidio_Information(url) #根据视频数创建文件夹 for i in range(len(aid)): path1 ="G:\\1234\\python\\"+str(i) folder_mkdir.folder_mkdir().mkdir(path1) path.append(path1) #下载视频,这里只有第一个 video_deal.video_deal().vedio_download(path[0], aid[0], title[0]) picture_path = path[0]+'\\'+"pictures" #创建保存图片的文件夹 folder_mkdir.folder_mkdir().mkdir(picture_path) video_path = path[0]+'\\'+title[0]+'.flv' frequency_path = path[0]+'\\'+title[0]+'.mp3' #提取音频 video_deal.video_deal().frequency(video_path,frequency_path) #拆分视频 count = video_cut.video_cut().cut(video_path, picture_path) deal_path = path[0]+'\\'+'diealpictures' #字符化处理 char_deal.char_deal().txtjpg(picture_path,deal_path) #计算fps time = video_deal.video_deal().getTime(frequency_path) fps = str(round(count/time)) #合成视频 savepath = path[0]+'\\'+title[0]+'char'+'.mp4' video_deal.video_deal().compound(deal_path,frequency_path,savepath,fps)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
main由于本人电脑的原因,没有爬取并处理所有的视频,你们稍微改一下就可以下载所有的。
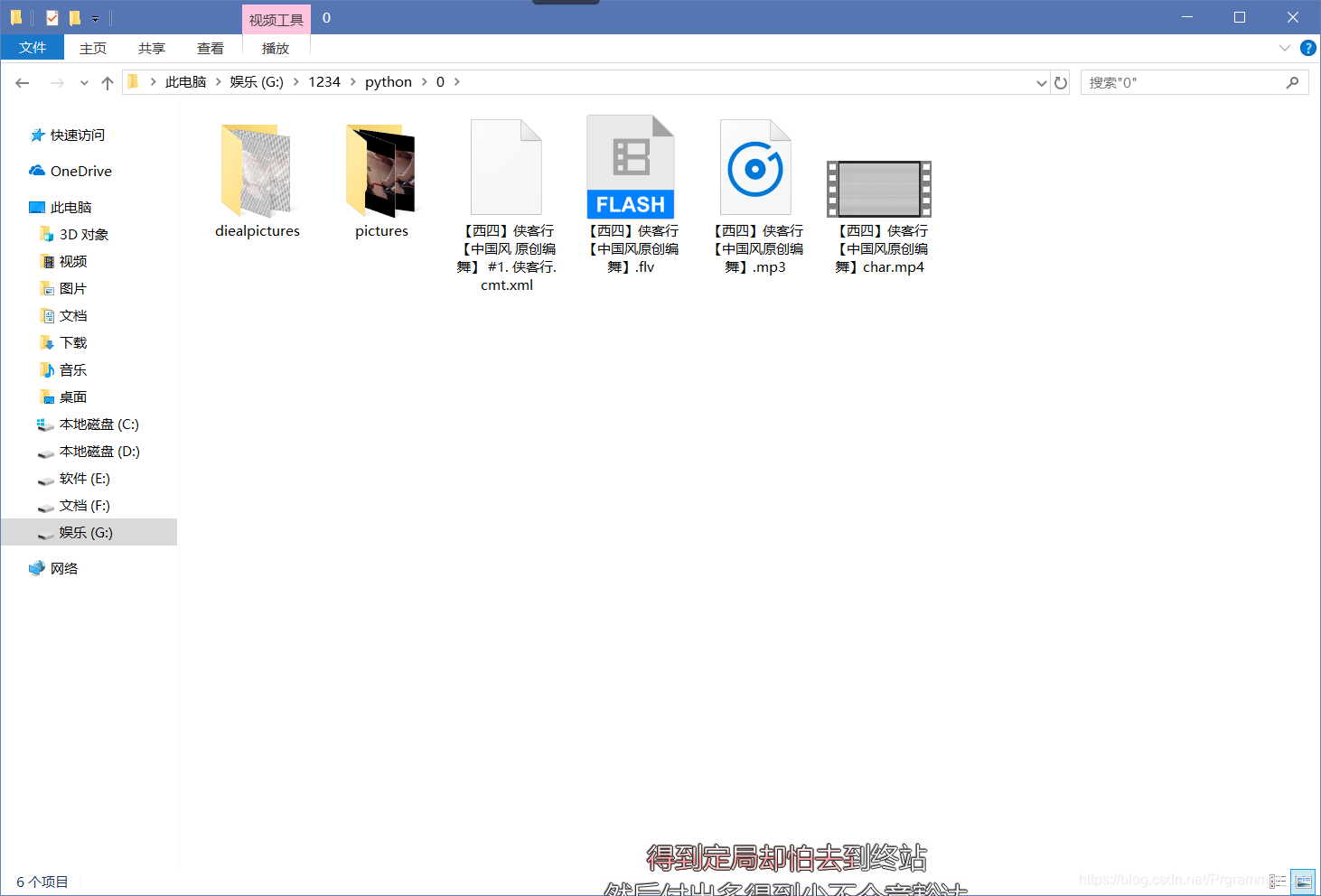
运行效果如下: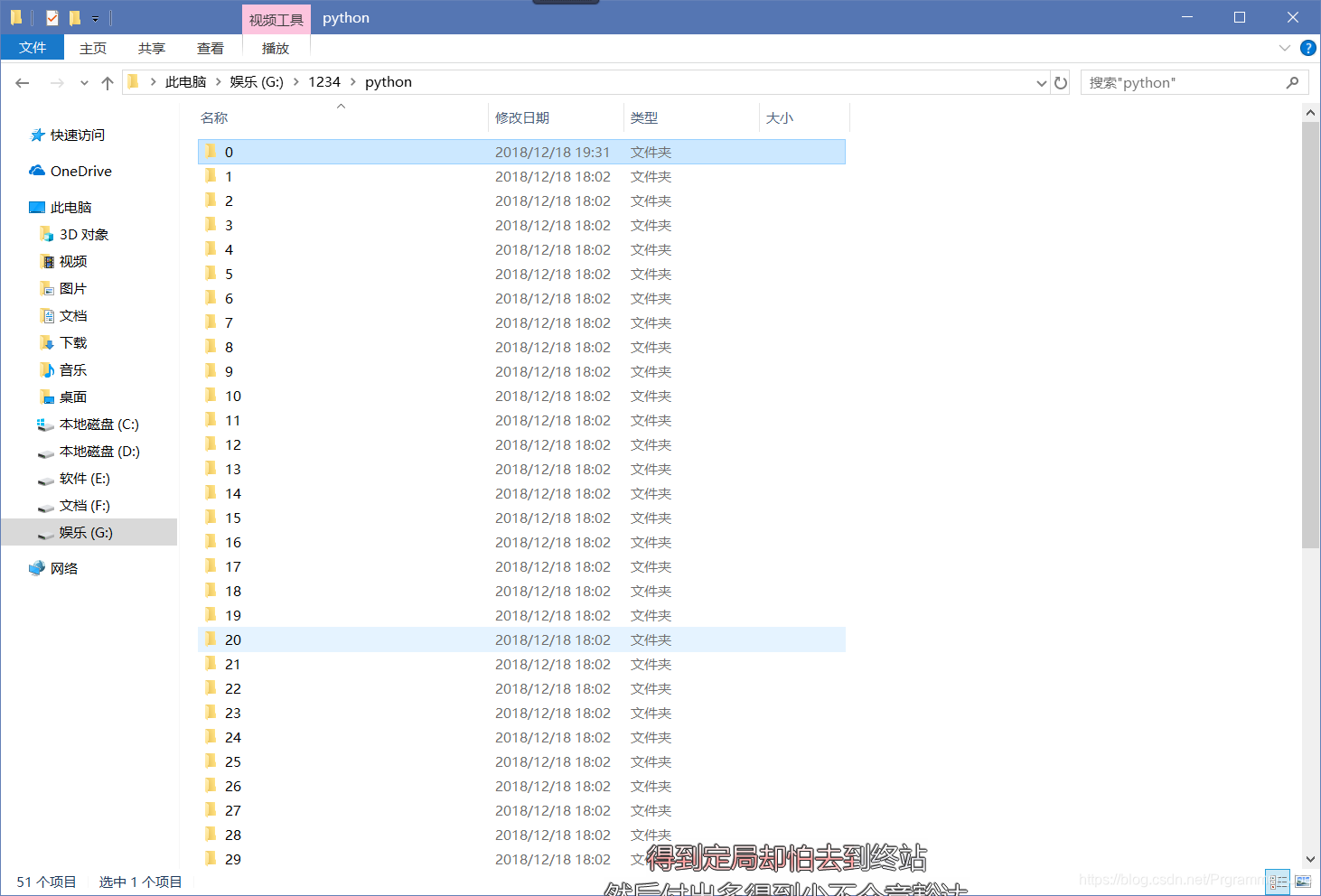
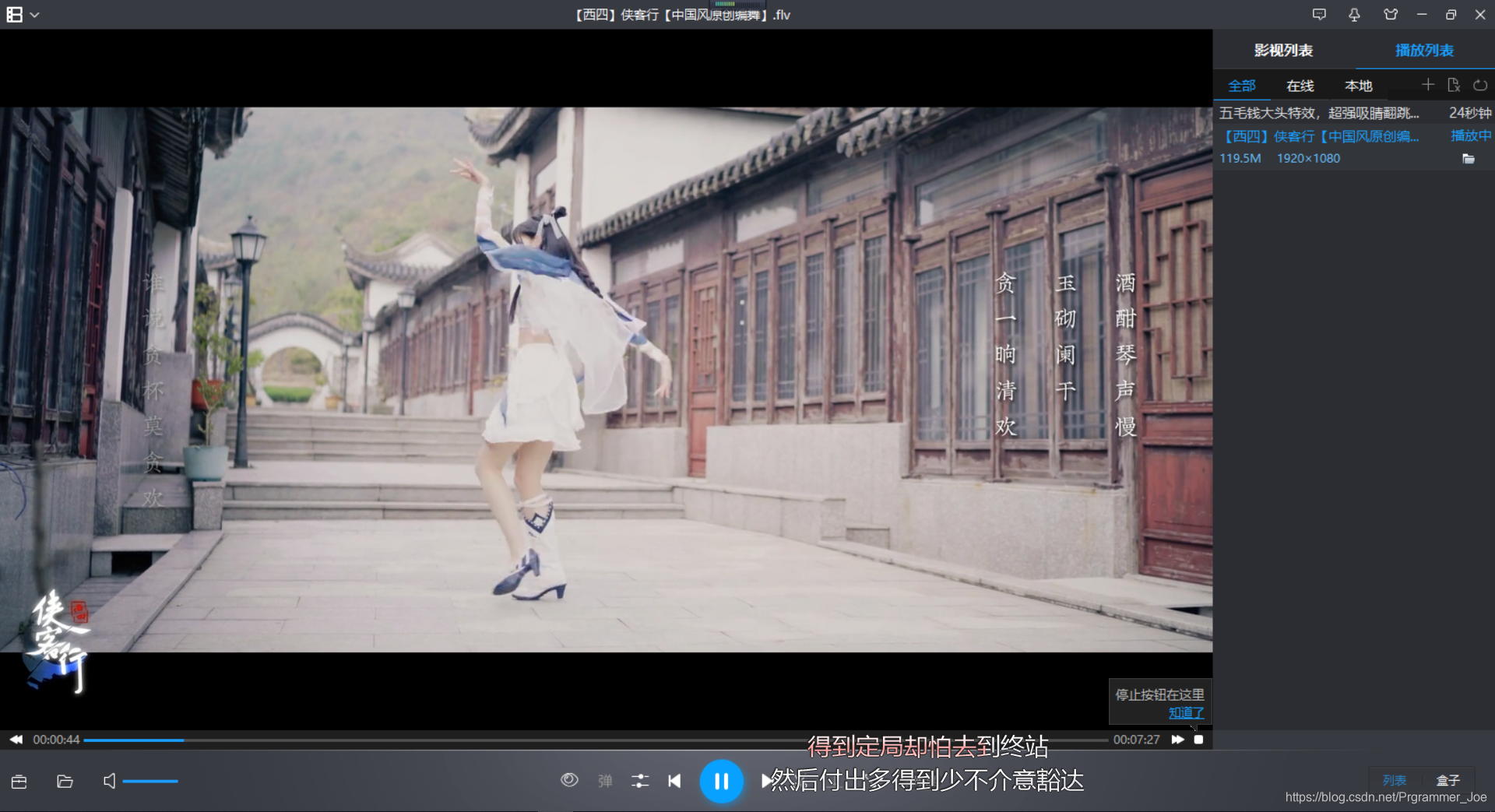
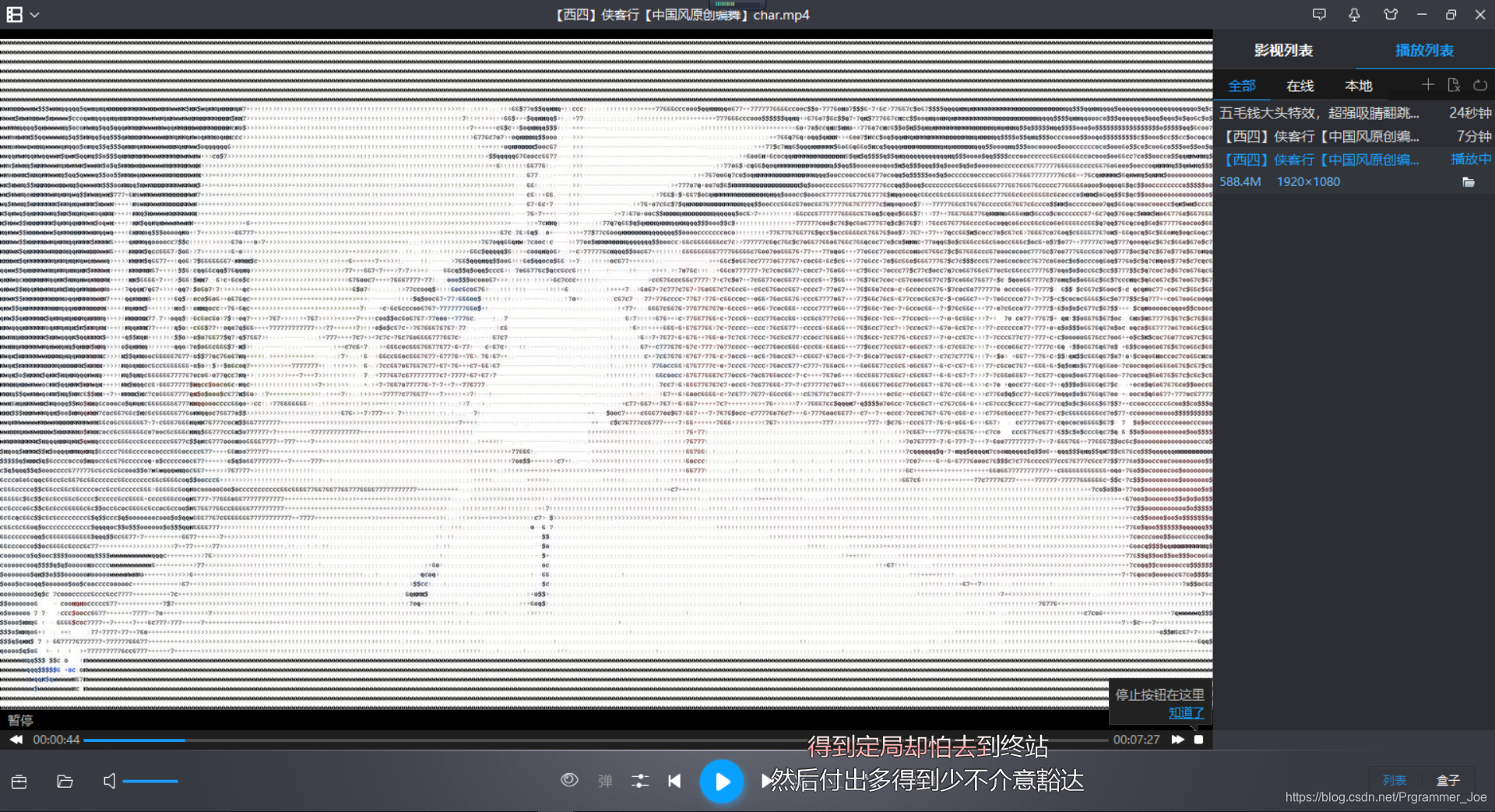
转载请附上声明和地址



