
热门标签
热门文章
- 1dubbo负载均衡-RandomLoadBalance
- 2机器学习笔记(4)——多变量线性回归
- 3Android Studio App开发实战项目之实现淘宝电商App首页界面(附源码,可用于大作业参考)_android 淘宝代码
- 4鸿蒙harmonyOS 在DevEco Studio 安装应用时出现 INSTALL_PARSE_FAILED_USESDK_ERROR
- 5Tool-X 工具汇总
- 6STM32学习记录——光敏传感器的使用_stm32光敏传感器
- 7关于目标检测中按照比例将数据集随机划分成训练集和测试集
- 8yolov5 部署jetson nano(通用) 保姆级教学_yolov5部署到nano保姆级教程
- 9Android开发-网络请求框架okhttp3的使用_android okhttp3
- 10【物联网】液滴即信息:雨滴探测传感器实验解析降雨的密码_ps2操作杆实验目的
当前位置: article > 正文
Python爬虫学习基础——利用Ajax爬取B站用户信息_b站访客怎么查爬虫
作者:IT思考机器 | 2024-02-03 15:31:34
赞
踩
b站访客怎么查爬虫
Python爬虫学习基础——利用Ajax爬取B站用户信息
有时候我们在用requests抓取网页时,得到的结果可能和在浏览器中看到的不一样,原因是因为我们requests获取的是原始的HTML文档,而现在大多数网页都是经过JavaScript处理的。仅仅使用requests已经不能满足需求,今天,我们将使用Ajax分析爬取B站用户信息。
Ajax
Ajax,全称为Asynchronous JavaScript and XML,即异步的JavaScript和XML。他不是一门编程语言,而是利用JavaScript在保证页面不被刷新,页面链接不改变的情况下与服务器变换数据并更新部分页面的技术。更多详细的大家可以去W3Schools上了解,下面是链接:
http://www.w3school.com.cn/ajax/ajax_xmlhttprequest_send.asp
- 1
正式开始
首先我们分析网页情况,发现requests返回的response里没有任何和用户个人信息相关的东西。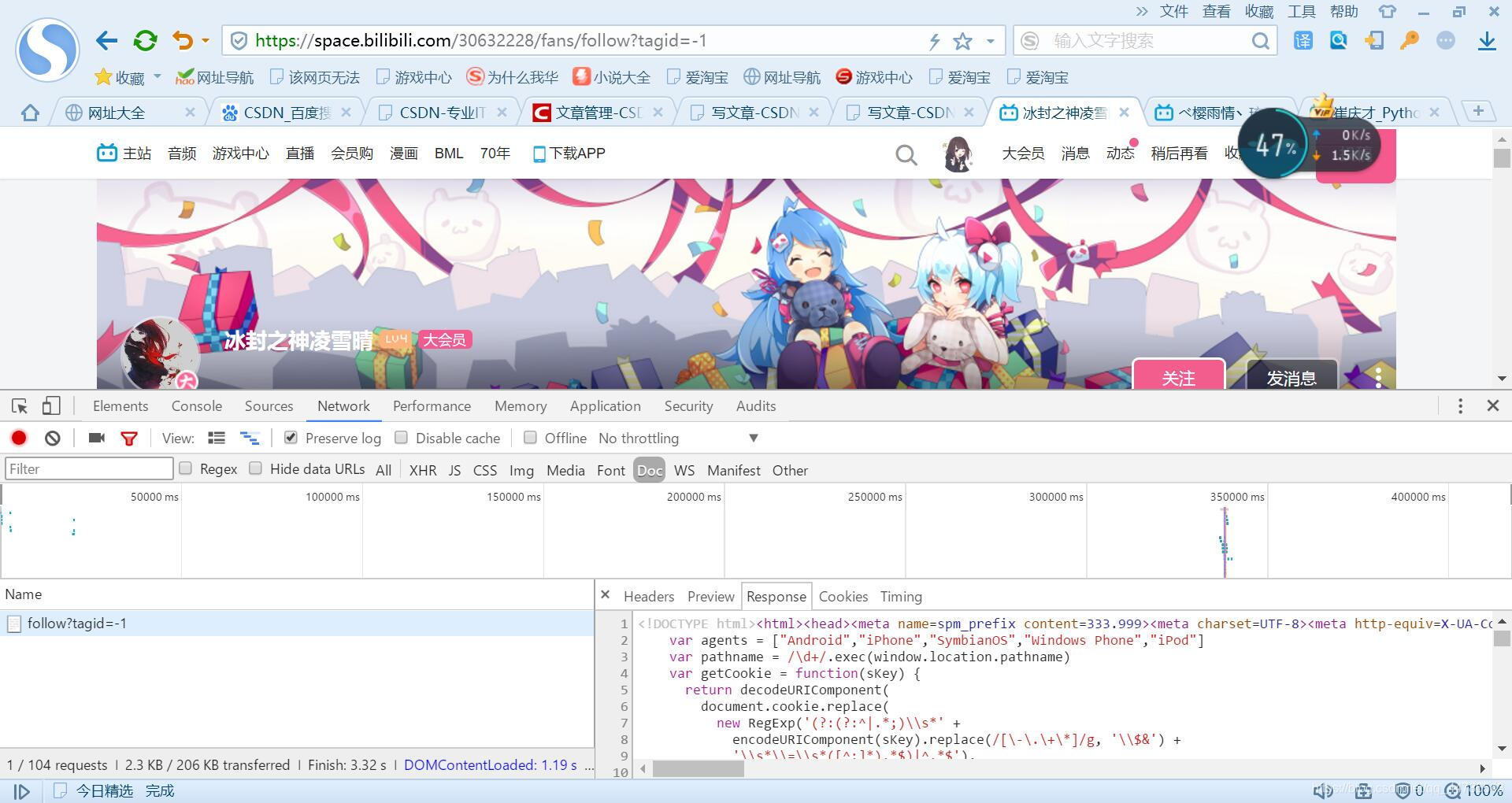
然后我们通过Ajax分析观察到用户个人信息隐藏在这里
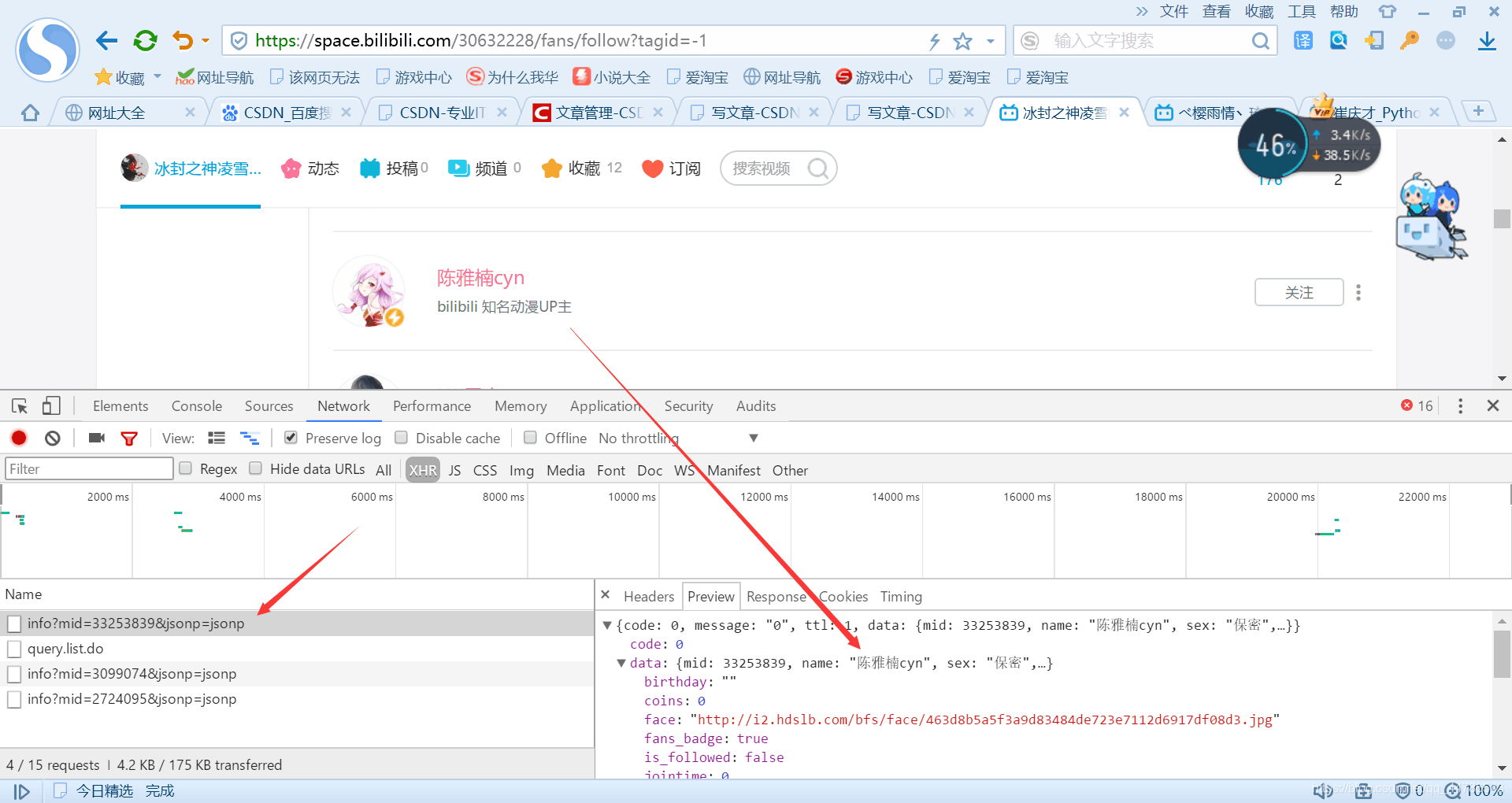
找到了我们想要的东西,当然就可以写代码了,首先我们要将url拼接起来
url_data = {'mid': mid,
'jsonp': 'jsonp'
}
url = 'https://api.bilibili.com/x/space/acc/info?'+urlencode(url_data)
- 1
- 2
- 3
- 4
然后就可以通过requests库发起请求了,请求以后我们可以通过json.load()将他转换成一个json对象,这样方便与我们接下来的操作。
// 这是请求模块
def get_request(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except requests.ConnectionError:
print("ERROR")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
接下来我们解析得到的json对象就行
// 解析模块
def parse_user(result):
if 'data' in result.keys():
item = {}
items = result.get('data')
item['name'] = items['name']
item['sex'] = items['sex']
item['level'] = items['level']
item['face'] = items['face']
return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里我只获取了用户的一部分信息,如果你想获取更多的可以自行添加,接下来我们就是把获取到的信息存在Mongdb上
// Mongdb数据库的一些基本操作
MONGO_URI = 'localhost'
MONGO_DATABASE = 'bilibili'
client = pymongo.MongoClient(MONGO_URI)
db = client[MONGO_DATABASE]
collection = db[MONGO_DATABASE]
if collection.update_one({'name': item['name']}, {'$set': item}, True):
print("存入MONGODB成功")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
最后我们还可以把用户的头像下载下来,因为前面我们已经获取到了链接
//下载用户头像代码 def download_face(face): try: response = requests.get(face, headers=headers) if response.status_code == 200: save_face(face, response.content) except requests.ConnectionError: print("ERROR") def save_face(face, content): file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg') if not os.path.exists(file_path): with open(file_path, 'wb') as f: f.write(content) print("下载%s成功" % face) else: print("该用户头像已存在")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
完整代码以及运行结果
最后,是不是觉得下载速度会很慢,我们只要开启多线程就可以啦。下面是完整代码
//完整代码与注释 import requests from urllib.parse import urlencode import json import pymongo from Pa_Chong.Mongo_Setting import * import os from hashlib import md5 from multiprocessing import Pool headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'} client = pymongo.MongoClient(MONGO_URI) db = client[MONGO_DATABASE] collection = db[MONGO_DATABASE] def get_request(url): #请求模块 try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.text except requests.ConnectionError: print("ERROR") def parse_user(result): #解析模块 if 'data' in result.keys(): item = {} items = result.get('data') item['name'] = items['name'] item['sex'] = items['sex'] item['level'] = items['level'] item['face'] = items['face'] return item def download_face(face): #下载模块 try: response = requests.get(face, headers=headers) if response.status_code == 200: save_face(face, response.content) except requests.ConnectionError: print("ERROR") def save_face(face, content): #下载模块 file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg') #这里我们利用了一下md5避免下载相同的头像 if not os.path.exists(file_path): with open(file_path, 'wb') as f: f.write(content) print("下载%s成功" % face) else: print("该用户头像已存在") def main(mid): url_data = {'mid': mid, 'jsonp': 'jsonp' } url = 'https://api.bilibili.com/x/space/acc/info?'+urlencode(url_data) #利用urlencode函数构造链接 response = get_request(url) result = json.loads(response) item = parse_user(result) print("正在下载%s" % item['face']) download_face(item['face']) if collection.update_one({'name': item['name']}, {'$set': item}, True): #存储到数据库中,利用updata_one函数避免重复存入 print("存入MONGODB成功") if __name__ == '__main__': pool = Pool(5) #这里我们开启了5个进程 mid = [i for i in range(1, 10)] pool.map(main, mid)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
运行结果图
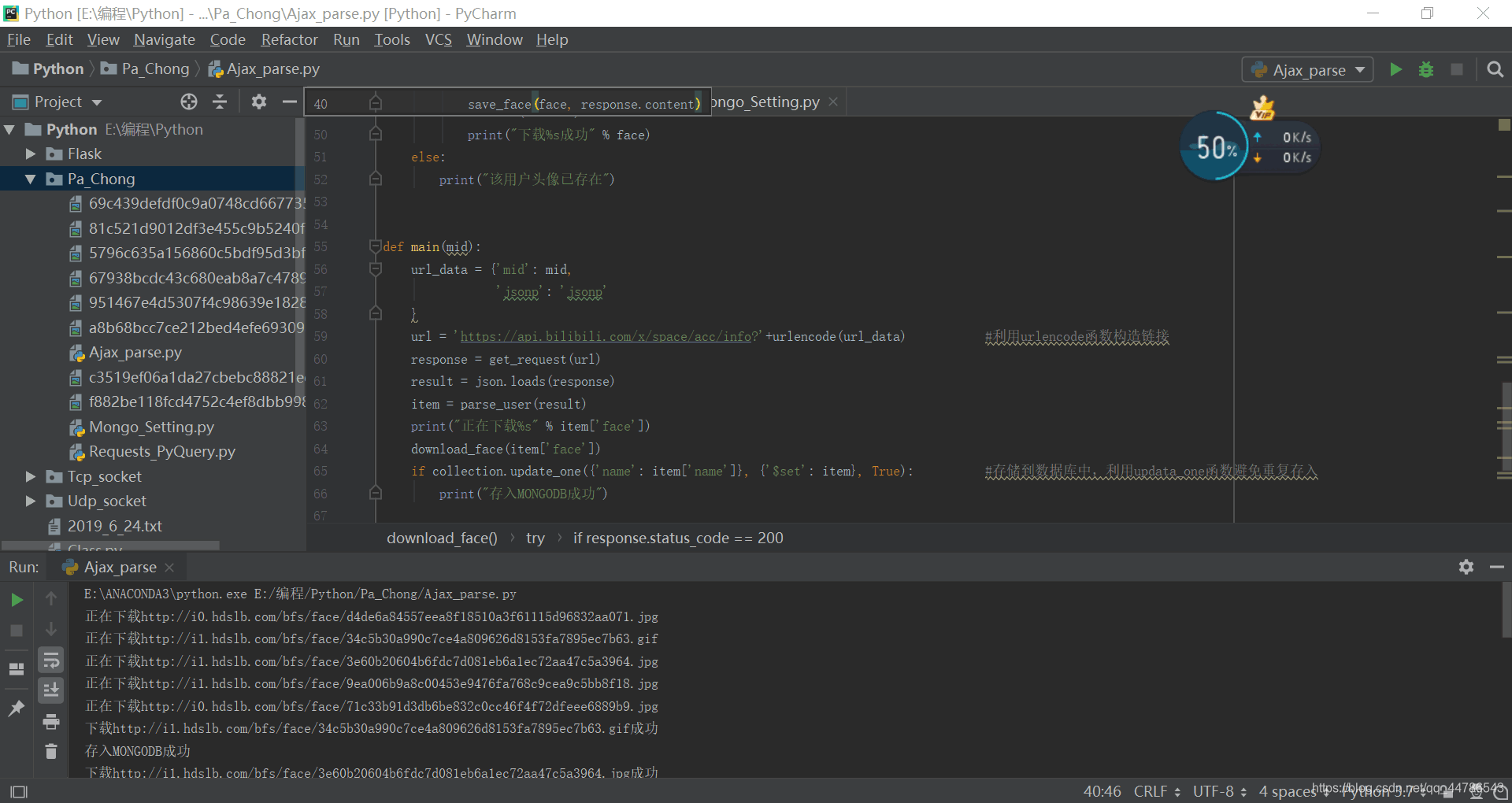
头像下载情况
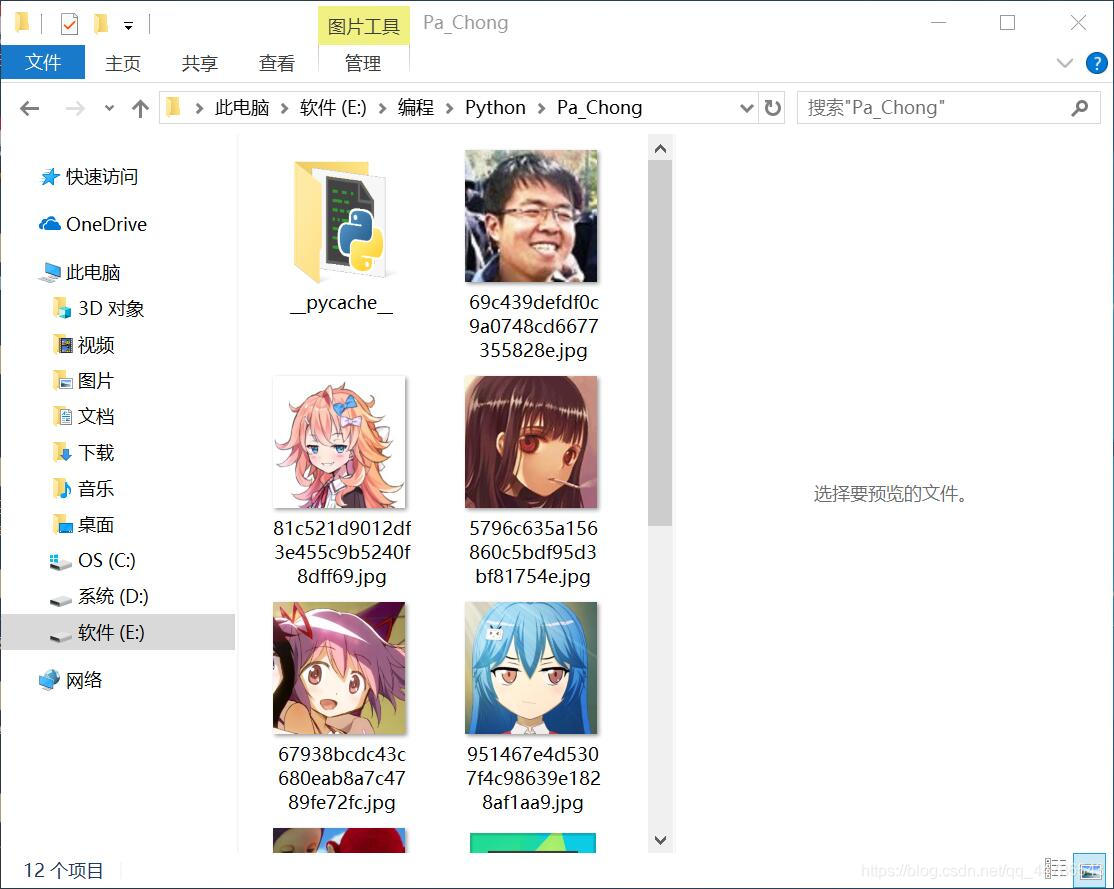
Mongdb数据库存储情况:
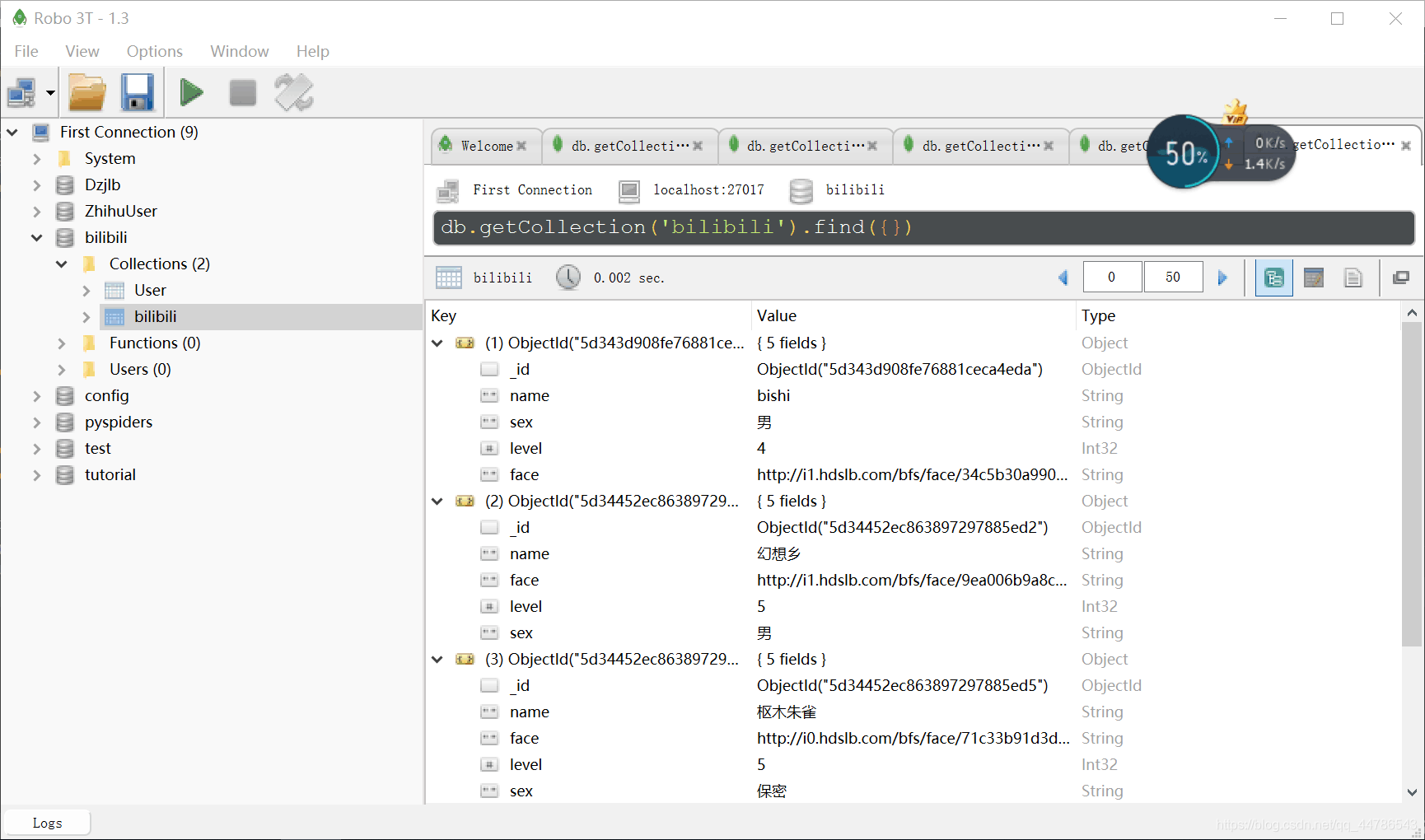
最后,向大家说明一下,我们这里只爬取了B站UID为1到10的9个用户的信息,只是教大家怎么爬取而已,如果你想爬取更多的用户信息当然也是可以的,只要结合代理池就可以了。这里就不做更多的说明了。学会了Ajax原理,相信大家的爬虫能更进一步。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/57177
推荐阅读



相关标签

