- 1Dockerfile RUN 同时执行多条命令_dockerfile 一行 run多个命令
- 2python 简单随机验证码_python 产生一个四位随机验证码
- 3Ubuntu下,Python脚本自启动,在特定conda环境下运行相应代码
- 4收藏 | 14 种免费 GIS 软件_gis软件
- 5stm32 hal库 RCC初始化函数SystemClock_Config()梳理分析、初步细致学习(一)
- 6不同难度系数面试题,看你能答出几道?快来查漏补缺!
- 7十个docker面试题和答案
- 8hsv 直方图均衡化_Opencv从零开始 - 「启蒙篇」- 直方图、直方图均衡和反向投射...
- 9Django计算机毕业设计软考刷题小程序python(源码程序+lw+远程部署)_计算机专业毕业设计选题刷题小程序可以做吗
- 10python222网站实战(SpringBoot+SpringSecurity+MybatisPlus+thymeleaf+layui)-Tag标签管理实现
python爬虫Selenium批量关注微博用户_怎样爬虫提取微博关注
赞
踩
想要了解一个人,可以从ta的微博开始下手,微博的关注列表可以很好地看出一个人的兴趣。实验计划获取目标微博账号的关注列表并实现批量关注。
一、 网页分析
为减少网页反爬策略对实验产生影响,选取手机端网页进行分析(m.weibo.com)。下面根据关注的三个步骤进行分析。
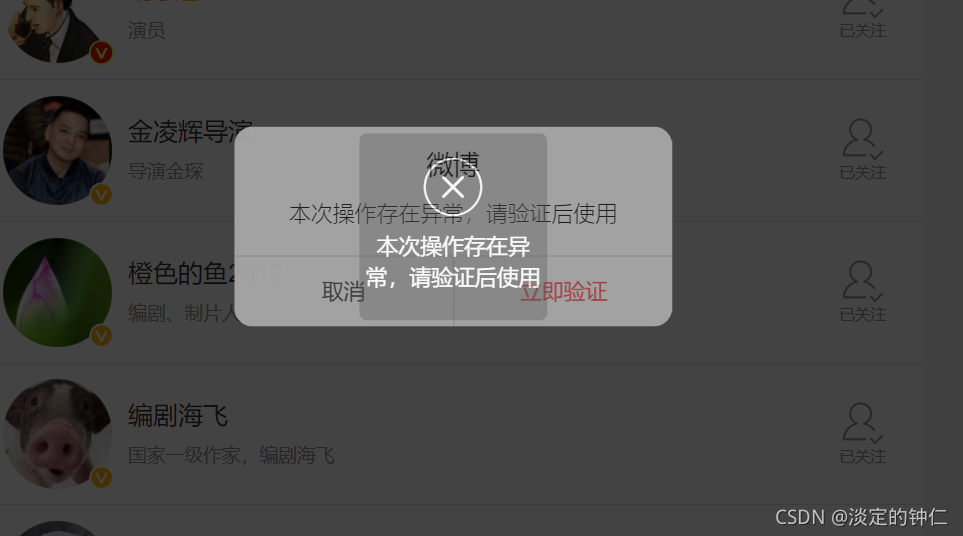
打不开手机端网页的情况:
输入网址后按F12打开开发者工具,在依次点击下方两个位置选择手机模式后即可正常浏览。
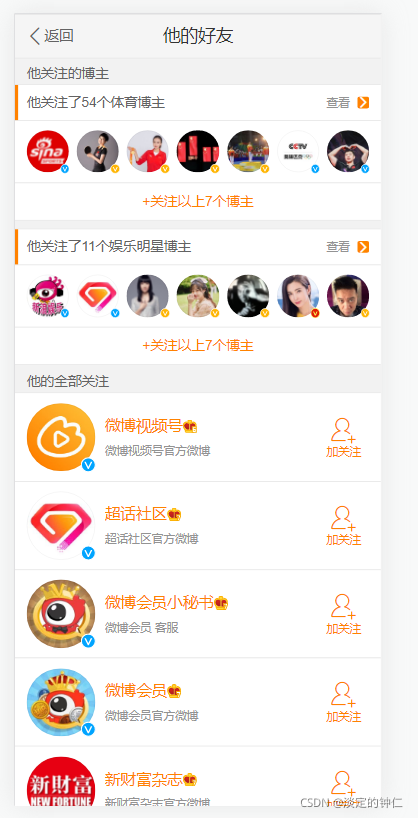
查看网页源代码,发现关注列表等信息明显是用js渲染出来的,很难通过requests直接获取,因此选择Selenium库作为爬取工具。

1、登录状态维持
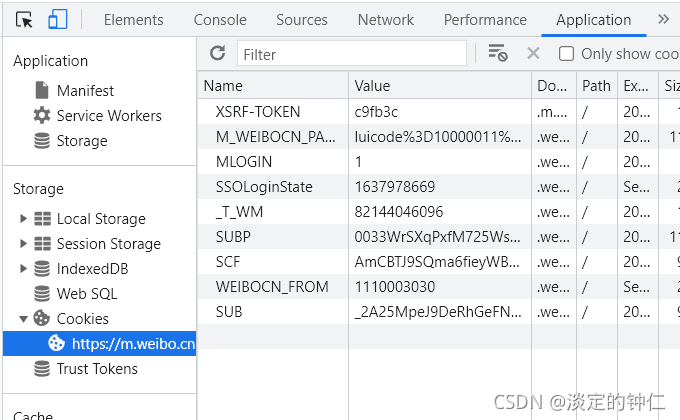
在进行一切操作之前需要登录自己的账号,而登录过程包含各种验证手段,不方便处理。因此在爬取页面前手动登录账号,并在chrome-开发者工具-Application-cookies中获取相应的cookie。在访问时,手动添加cookie可以保持登录的状态。
2、关注列表获取
分别找到三个用户的关注列表,对url进行分析。

发现有差异的部分仅为“followers_-_”之后,“_-_1042015”之前的部分(经验证知该值为微博用户号),postman检验知“_-_1042015”及其之后的参数均可去除。
由此得到了url格式:
url = 'https://m.weibo.cn/p/index?containerid=231051_-_followers_-_{}'.format(targetid)
# targetid 为目标账户的id
- 1
- 2
3、下拉刷新
页面每次向下滚动时会产生新的用户。为保证不会因操作频率过快而被目标网站检验,每次下拉都需要设置一定时间间隔。
4、关注目标用户的过程分析
右键点击关注按钮,即可在开发者工具中查看按钮在html中的位置。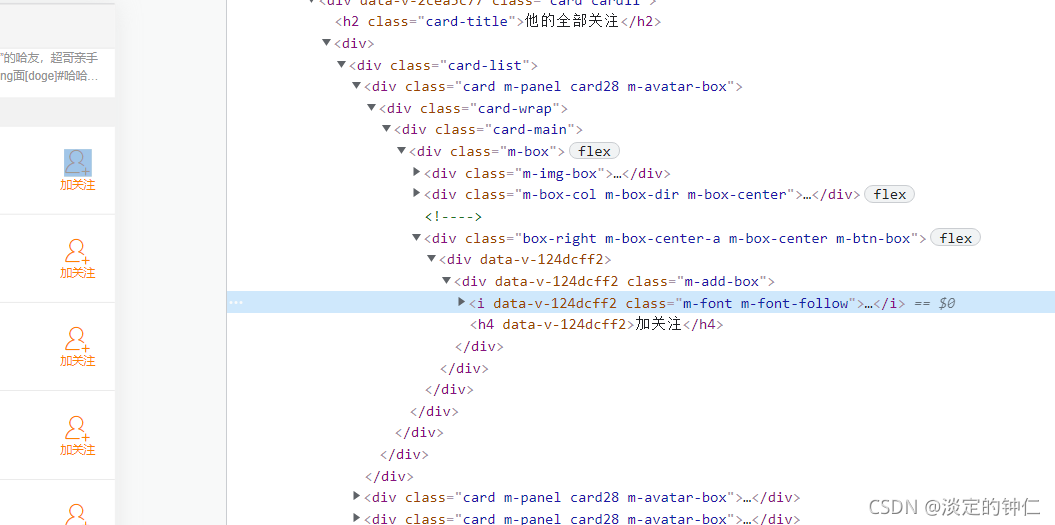
我们很快地找到按钮的位置,每一个class=“card m-panel card28 m-avatar-box”的div下“class="m-font m-font-follow"的i元素,据此可以很快使用xpath定位。但Selenium的click函数默认不支持对i元素的点击,采用execute_script函数执行js脚本可以绕过这个限制。
follow_button = browser.find_element_by_xpath('.//i[@class="m-font m-font-follow"]')
browser.execute_script("arguments[0].click();", follow_button)
time.sleep(random.uniform(0,1))
- 1
- 2
- 3
与下拉一样,为防止被目标网站屏蔽,每次点击设置一定时间间隔。
二、完整代码
注:
运行前提前安装Selenium库,以及相应的webdriver。
pip install selenium
根据自己的chrome版本下载chromediver并添加至环境变量。
from selenium import webdriver import random import time total_num = 50 # 使用前手动获取cookies cookies = [{"name": "_T_WM", "value": "85458941036"}, {"name": "SUB", "value": "_2A25MpEV9DeRhGeFN6VAU9i7OwzSIHXVsZ2s1rDV6PUJbkdAKLXn9kW1NQEE7SA2lhJKFE8uT2XTdS1cBtmzNj532"}, {"name": "WEIBOCN_FROM", "value": "1110006030"}, {"name": "MLOGIN", "value": "1"}, {"name": "XSRF-TOKEN", "value": "b96148"}, {"name": "M_WEIBOCN_PARAMS", "value": "luicode%3D10000011%26lfid%3D231051_-_followers_-_1350995007_-_1042015%253AtagCategory_050%26fid%3D231051_-_followers_-_1350995007_-_1042015%253AtagCategory_050%26uicode%3D10000011"}, #{"name": "loginScene", "value":"102003"} ] # div class="m-dialog" # 滚动至最底端 def roll(driver): # 获取页面初始高度 js = "return action=document.body.scrollHeight" height = driver.execute_script(js) # 将滚动条调整至页面底部 driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 初始时间 t1 = int(time.time()) # 循环标识 status = True # 重试次数 num = 0 result = [] while status: # 判断数量是否足够 result = driver.find_elements_by_xpath('//i[@class="m-font m-font-follow"]') count = len(result) if count >= total_num: print("已达到预期数目.") status = False # 当前时间 t2 = int(time.time()) time.sleep(1) # 判断时间初始时间戳和当前时间戳相差是否大于5秒,小于5秒则下拉滚动条 if t2 - t1 < 5: new_height = driver.execute_script(js) if new_height > height: time.sleep(random.uniform(1,2)) driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 重置初始页面高度 height = new_height # 重置初始时间戳,重新计时 t1 = int(time.time()) elif num < 3: # 当超过5秒页面高度仍然没有更新时,进入重试逻辑,重试3次,每次等待3秒 time.sleep(3) num = num + 1 else: # 超时并超过重试次数,程序结束跳出循环,并认为页面已经加载完毕! print("滚动条已经处于页面最下方") status = False # 滚动条调整至页面顶部 driver.execute_script('window.scrollTo(0, 0)') break print("共{}个用户可供关注。".format(count)) def main(): start = time.time() # 开发者模式 options = webdriver.ChromeOptions() options.add_experimental_option('excludeSwitches', ['enable - automation']) # 启动浏览器 browser = webdriver.Chrome() # 目标用户的id targetid = 1827683445 url = 'https://m.weibo.cn/p/index?containerid=231051_-_followers_-_{}'.format(targetid) browser.get(url) time.sleep(2) # 添加cookie for cookie in cookies: browser.add_cookie(cookie) # 刷新状态 browser.refresh() # 下滚并获取目标数量的用户 roll(browser) # 查找用户所在div targets = browser.find_elements_by_xpath('//div[@class="card m-panel card28 m-avatar-box"]') if len(targets) != 0: count = 0 for target in targets: # 查找用户昵称 name = target.find_elements_by_xpath('.//h3')[0].text # 查找关注按钮 follow_button = target.find_elements_by_xpath('.//i[@class="m-font m-font-follow"]') if len(follow_button) != 0: follow_button = follow_button[0] # 检查是否有弹窗 dialog = browser.find_elements_by_xpath('//div[@class="m-dialog"]') if len(dialog) == 0: print("Success: 成功关注 {}".format(name)) # 保存至文件 with open('followname_{}.txt'.format(targetid), 'a', encoding='utf-8') as f: f.write("%s\n" % name) # 点击关注 browser.execute_script("arguments[0].click();", follow_button) time.sleep(random.uniform(0.6,1.5)) count += 1 else: print("Error: 关注失败.") break if count == total_num: break print("共关注了{}个用户.".format(count)) print("耗费时间:{}s".format(time.time()-start)) time.sleep(10) if __name__ == '__main__': main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
三、效果展示
整体算是实现了基本的自动化功能,关注效率偏低。毕竟每次关注都会向目标网站发送请求,请求到达一定频率账号就会被封禁(我的账号昨天封了一整天。。。)。如果代理ip的话,由于每次发送关注请求的均为同一个账户,还是无法避免账户的封禁。
运行中:

关注前:

关注后:

四、拓展
另外还写了一个批量取消关注的程序,原理类似:
from selenium import webdriver import random import time # 使用前手动获取cookies cookies = [{"name": "_T_WM", "value": "85458941036"}, {"name": "SUB", "value": "_2A25MpEV9DeRhGeFN6VAU9i7OwzSIHXVsZ2s1rDV6PUJbkdAKLXn9kW1NQEE7SA2lhJKFE8uT2XTdS1cBtmzNj532"}, {"name": "WEIBOCN_FROM", "value": "1110006030"}, {"name": "MLOGIN", "value": "1"}, {"name": "XSRF-TOKEN", "value": "b96148"}, {"name": "M_WEIBOCN_PARAMS", "value": "luicode%3D10000011%26lfid%3D231051_-_followers_-_1827683445_-_1042015%253AtagCategory_050%26fid%3D231051_-_followers_-_1827683445_-_1042015%253AtagCategory_050%26uicode%3D10000011"} ] # 滚动至最底端 def roll(driver): # 获取页面初始高度 js = "return action=document.body.scrollHeight" height = driver.execute_script(js) # 将滚动条调整至页面底部 driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') time.sleep(5) # 定义初始时间戳(秒) t1 = int(time.time()) # 定义循环标识,用于终止while循环 status = True # 重试次数 num = 0 while status: # 获取当前时间戳(秒) t2 = int(time.time()) # 判断时间初始时间戳和当前时间戳相差是否大于5秒,小于5秒则下拉滚动条 if t2 - t1 < 5: new_height = driver.execute_script(js) if new_height > height: time.sleep(1) driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 重置初始页面高度 height = new_height # 重置初始时间戳,重新计时 t1 = int(time.time()) elif num < 3: # 当超过5秒页面高度仍然没有更新时,进入重试逻辑,重试3次,每次等待3秒 time.sleep(3) num = num + 1 else: # 超时并超过重试次数,程序结束跳出循环,并认为页面已经加载完毕! print("滚动条已经处于页面最下方!") status = False # 滚动条调整至页面顶部 driver.execute_script('window.scrollTo(0, 0)') break def main(): total = 20 count = 0 browser = webdriver.Chrome() browser.get('https://m.weibo.cn/p/index?containerid=231093_-_selffollowed') for cookie in cookies: browser.add_cookie(cookie) browser.refresh() roll(browser) follows = browser.find_elements_by_xpath("//i[@class=\'m-font m-font-followed\']") for follow in follows: # 取消关注 follow.click() time.sleep(random.uniform(0.5, 1.0)) # 确定按钮 browser.find_element_by_xpath("//a[@class=\"m-btn m-btn-white m-btn-text-orange\"]").click() count += 1 if count == total: break print("Done") time.sleep(10) if __name__ == '__main__': main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
五、总结
1.Selenium实现所见即所得,可以有效实现对js渲染页面元素的爬取。
2.一般的网站都需要登录,传入cookie可以保持登录状态。
3.爬取过程中会遇到被目标网站封禁的情况,需要灵活调整等待时间以最大程度模拟人的行为。
1.Selenium实现所见即所得,可以有效实现对js渲染页面元素的爬取。
2.一般的网站都需要登录,传入cookie可以保持登录状态。
3.爬取过程中会遇到被目标网站封禁的情况,需要灵活调整等待时间以最大程度模拟人的行为。
4.目前实现效率不是很高,由于每次关注都会向目标网站发送请求,请求到达一定频率就会被封禁(大概关注30个用户就会被封禁了)。暂时没有找到合理的解决方法。求大佬提供思路。如果只是爬取信息的话被封禁的概率则要低一些。