
- 1SLAM知识点——eigen库学习_c++ cv2eigen
- 2Qt5.12实战之图形编程初识_qt 5.12 实战
- 3Unity之正确设置手机显示布局&&获取手机朝向_如何获取手机朝向
- 4搭建个人网站【华为云服务器、阿里云域名】_华为云域名备案到阿里云
- 52023 ATT&CK v13版本更新指南_attck
- 6python3.10在centos下安装以及配置_centos安装python3.10
- 7Godot 游戏引擎个人评价和2024年规划(无代码)_godot 平台适配
- 8ZYNQ 网络通信的四种实现方案_axi 1g/2.5g ethernet subsystem
- 9vue+element ui动态增加表单项并支持删除_vue动态新增表单
- 10Class 的继承_class 继承
基于小浣熊漫画cms的python爬虫项目实战(一)
赞
踩
创建 Scrapy 爬虫框架项目
- 本篇是在 Anaconda 环境下,如果没有安装 Anaconda 请到官网下载安装
- 下载地址:Anaconda | Individual EditionAnaconda | Individual EditionAnaconda's open-source Individual Edition is the easiest way to perform Python/R data science and machine learning on a single machine.
 https://www.anaconda.com/download/Anaconda | Individual Edition
https://www.anaconda.com/download/Anaconda | Individual Edition
一、 Scrapy 爬虫框架项目的创建
-
1.打开【cmd】
-
2.进入你要使用的 Anaconda 环境
-
1.环境名可以在【Pycharm】的【Settings】下【Project:】下找到
-
2.使用命令:activate 环境名,例如:activate learn
-
3.进入想要存放 scrapy 项目的目录下
-
4.新建项目:scrapy startproject xxx项目名,例如:scrapy startproject dem
-
5.在文件资源管理器打开该目录,就会发现生成了好几个文件
-
6.使用 Pycharm 打开项目所在目录就可以了。这里我们就把项目创建好了,分析一下自动生成的文件的作用
-
1.2 Scrapy 爬虫框架项目的开发
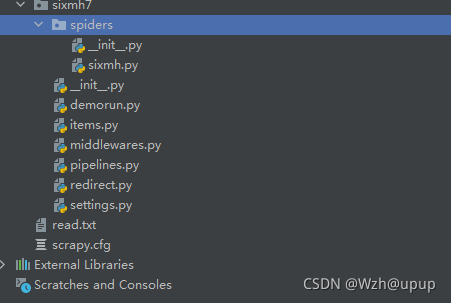
- 1.使用 Pycharm 打开项目,截图:
- 2.项目的开发的大致流程:
- 1.明确需要爬取的目标/产品:编写 item.py
- 2.在 spider 目录下载创建 python 文件制作爬虫:
- 地址 spider/xxspider.py 负责分解,提取下载的数据
- 3.存储内容:pipelines.py
- Pipeline.py 文件
- 对应 pipelines 文件
- 爬虫提取出数据存入 item 后,item 中保存的数据需要进一步处理,比如清洗,去虫,存储等
- Pipeline 需要处理 process_item 函数
- process_item
- spider 提取出来的 item 作为参数传入,同时传入的还有 spider
- 此方法必须实现
- 必须返回一个 Item 对象,被丢弃的 item 不会被之后的 pipeline
- _ init _:构造函数
- 进行一些必要的参数初始化
- open_spider(spider):
- spider 对象对开启的时候调用
- close_spider(spider):
- 当 spider 对象被关闭的时候调用
- Spider 目录
- 对应的是文件夹 spider 下的文件
- _ init _:初始化爬虫名称,start _urls 列表
- start_requests:生成 Requests 对象交给 Scrapy 下载并返回 response
- parse:根据返回的 response 解析出相应的 item,item 自动进入 pipeline:如果需要,解析 url,url自动交给 requests 模块,一直循环下去
- start_requests:此方法尽能被调用一次,读取 start _urls 内容并启动循环过程
- name:设置爬虫名称
- start_urls:设置开始第一批爬取的 url
- allow_domains:spider 允许去爬的域名列表
- start_request(self):只被调用一次
- parse:检测编码
- log:日志记录
二 、爬取前的分析
2.1 在正式爬取资源前,我们可以利用scrapy shell来分析我们想爬取的漫画网页主页,整理下思路。在cmd中运行如下指令:
scrapy shell http://www.sixmh7.com/23370/
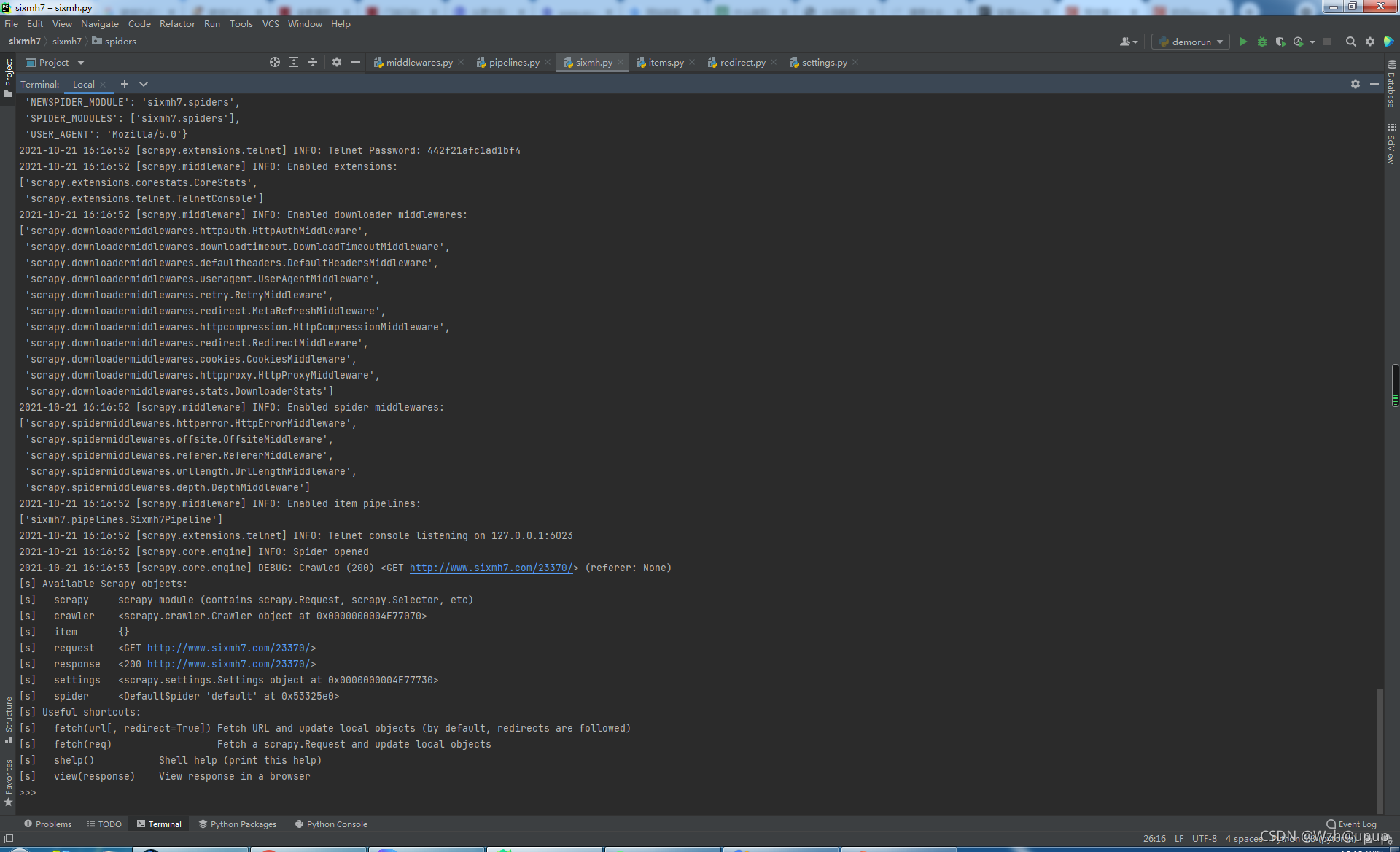
我们可以看到,输入命令后,就会有一些日志一样的东西显示出来,蓝色区域则显示出可以使用的scrapy命令,接下来我们需要用到“response”来进行爬取前的分析,你可以接着输入response.body这条命令,看看会输出什么
2.2.查看章节链接和章节名:我们利用浏览器打开开发者工具,查看一下漫画主页的链接,如图:
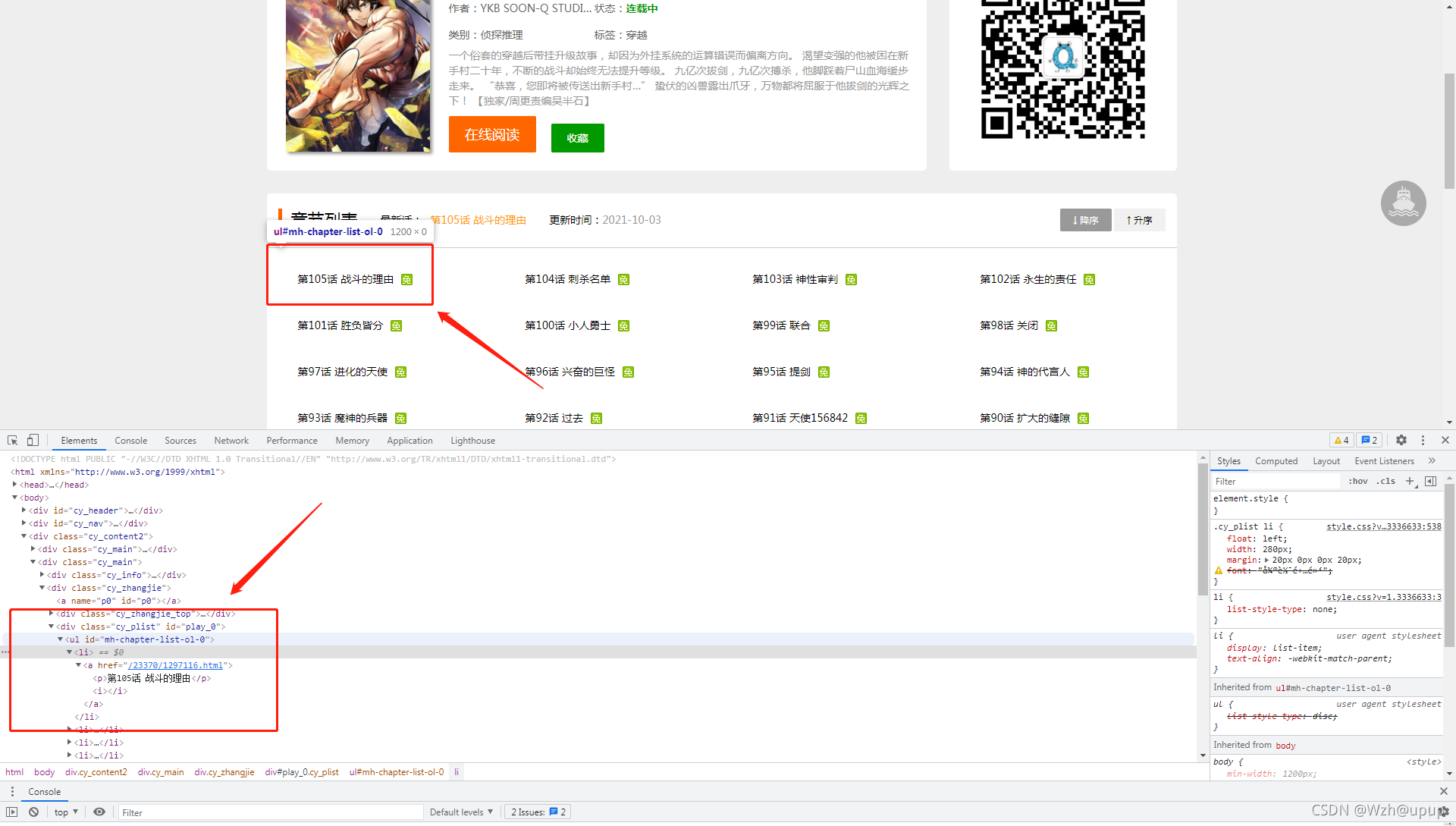
我们可以发现,章节链接都在<li>里面,这里我们利用scrapy shell来提取一下:
2.2.1.提取章节名
response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/p/text()').extract()
2.2.2.提取章节链接
response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/@href').extract()
这里我们发现,这里并不是全部章节的内容,需要点击查看更多章节动态获取,接下来我们分析动态获取的接口(有一些漫画站不需要动态获取,只是把静态的内容隐藏了)
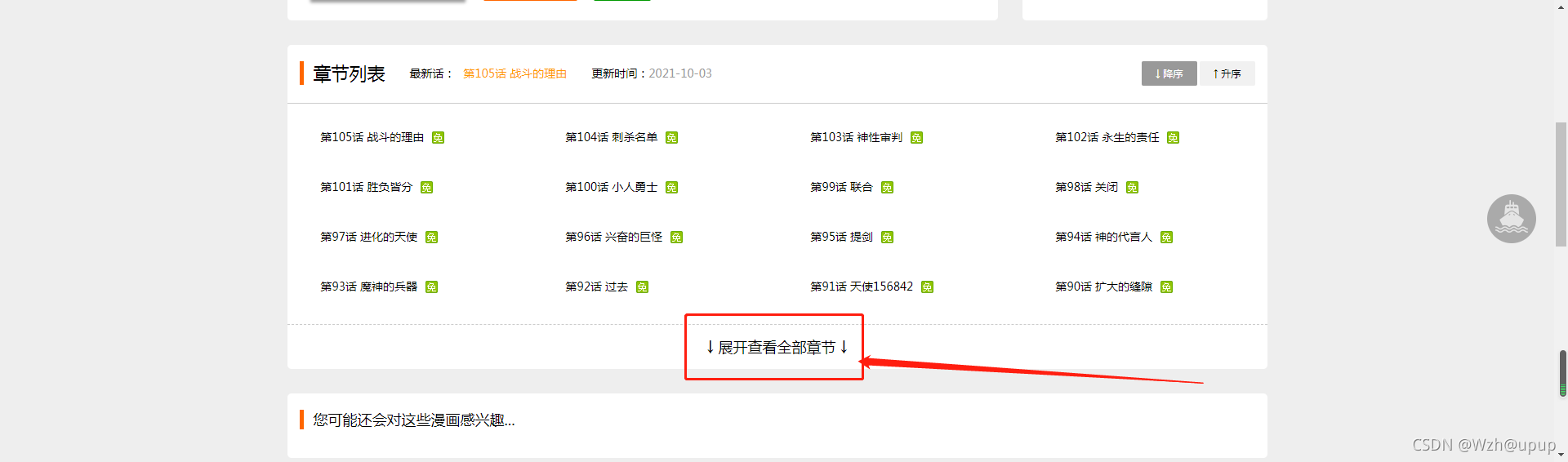
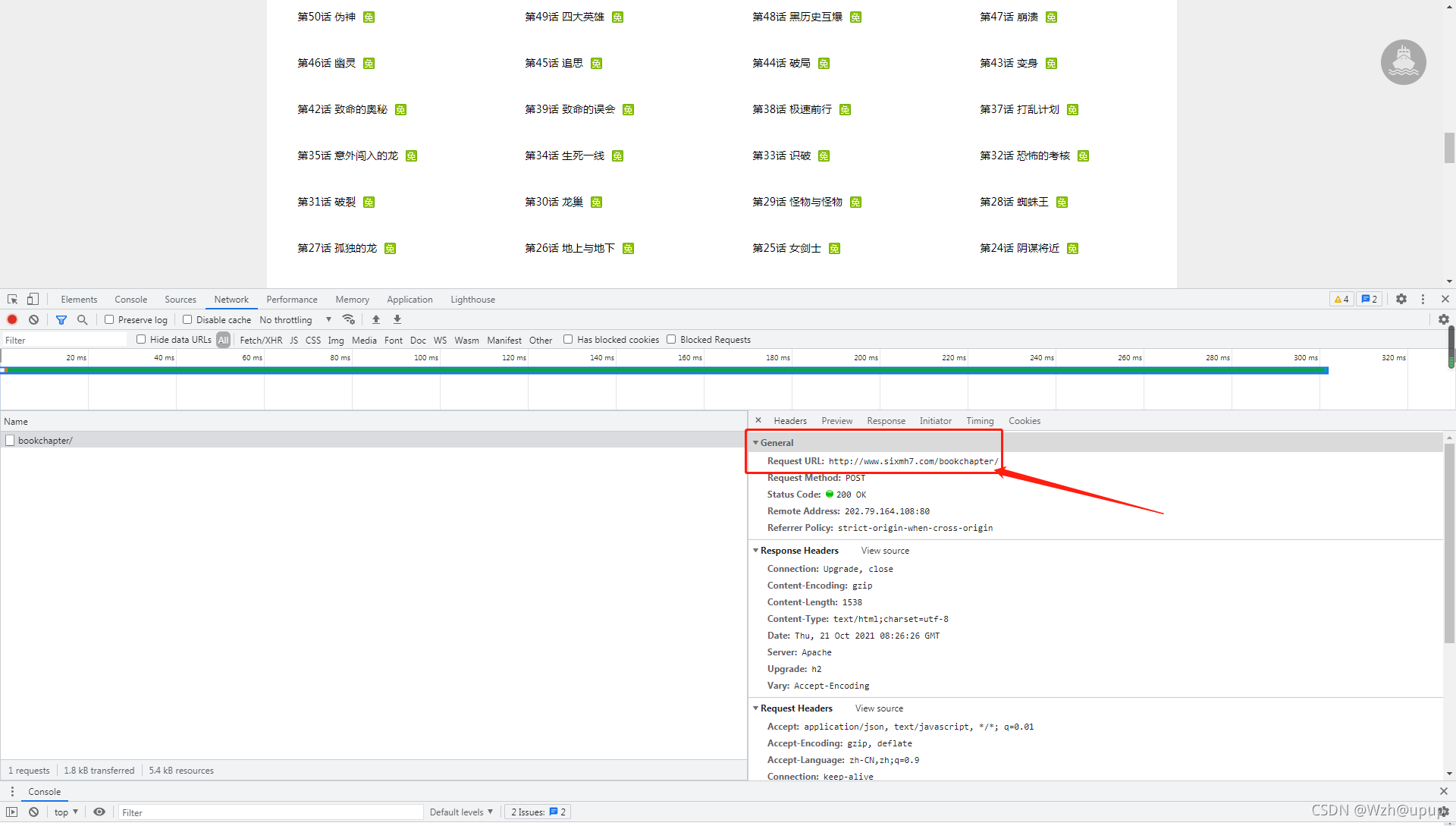
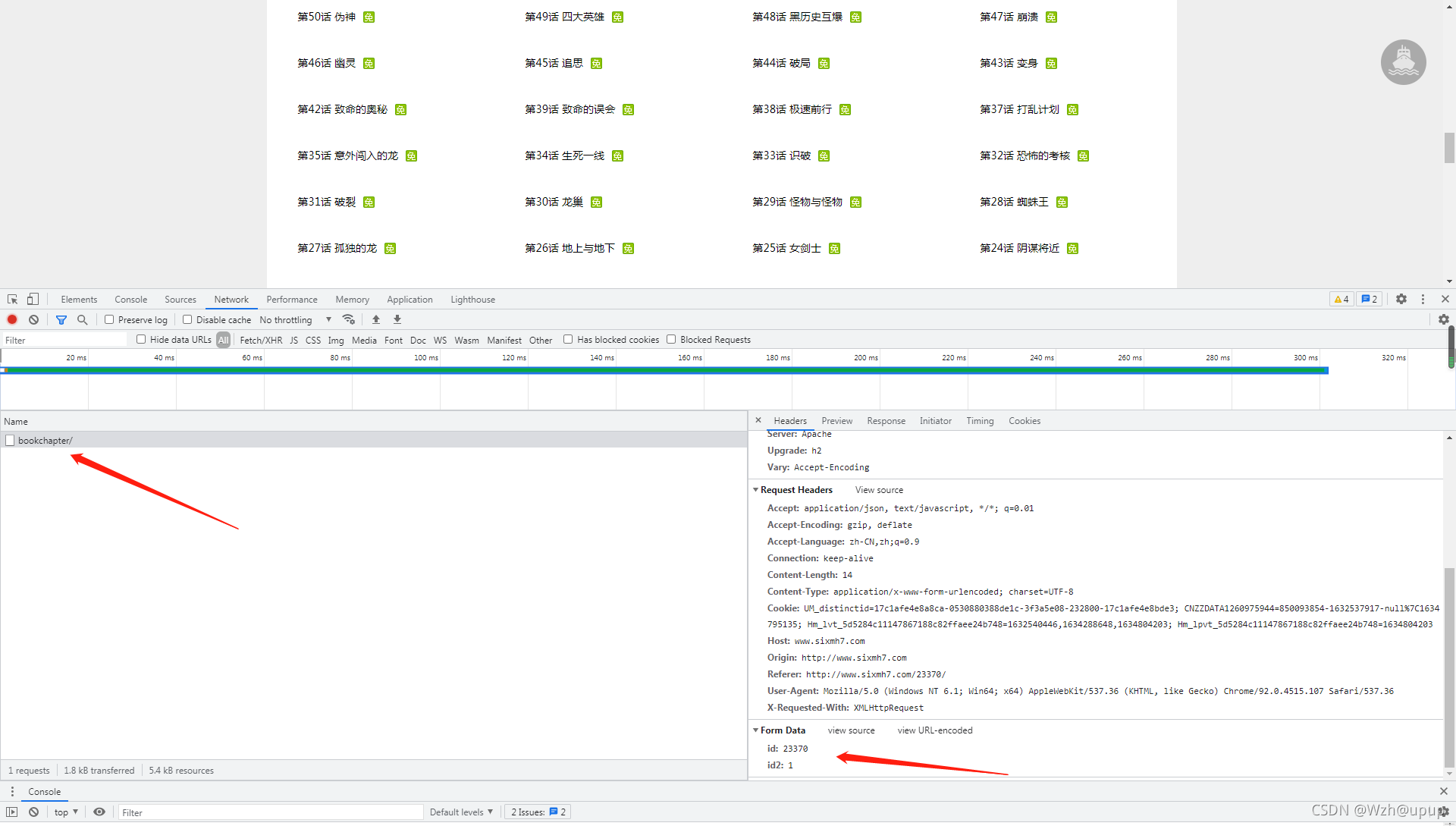
 接下来获取全部的链接和章节名,就不截图了,下面直接上代码
接下来获取全部的链接和章节名,就不截图了,下面直接上代码
- # 章节链接地址
- urls = response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/@href').extract()
- # 获取所有的章节名
- dir_names = response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/p/text()').extract()
- data = {
- "id": 23370,
- "id2": 1
- }
- response = requests.post("http://www.sixmh7.com/bookchapter/", data=data)
- for index in range(len(response.json())):
- link_url = "/23370/" + response.json()[index]['chapterid'] + ".html"
- urls.append(link_url)
- dir_name = response.json()[index]['chaptername']
- dir_names.append(dir_name)
2.3.分析图片链接来源
首先我们要理清楚一个思路:章节链接(link_urls)和图片链接(img_urls)是两种链接,你点进第一章后,利用开发者工具就能发现这一点。相当于说:每页漫画都有两个链接:页面链接和图片来源链接,2.2步中我们利用response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/@href').extract()获取到的是页面链接,而我们要做的就是首先跳转到这个页面,然后找到图片链接,最后将保存的图片链接下载。
2.3.1 接下来我们分析章节里的图片链接,如下图
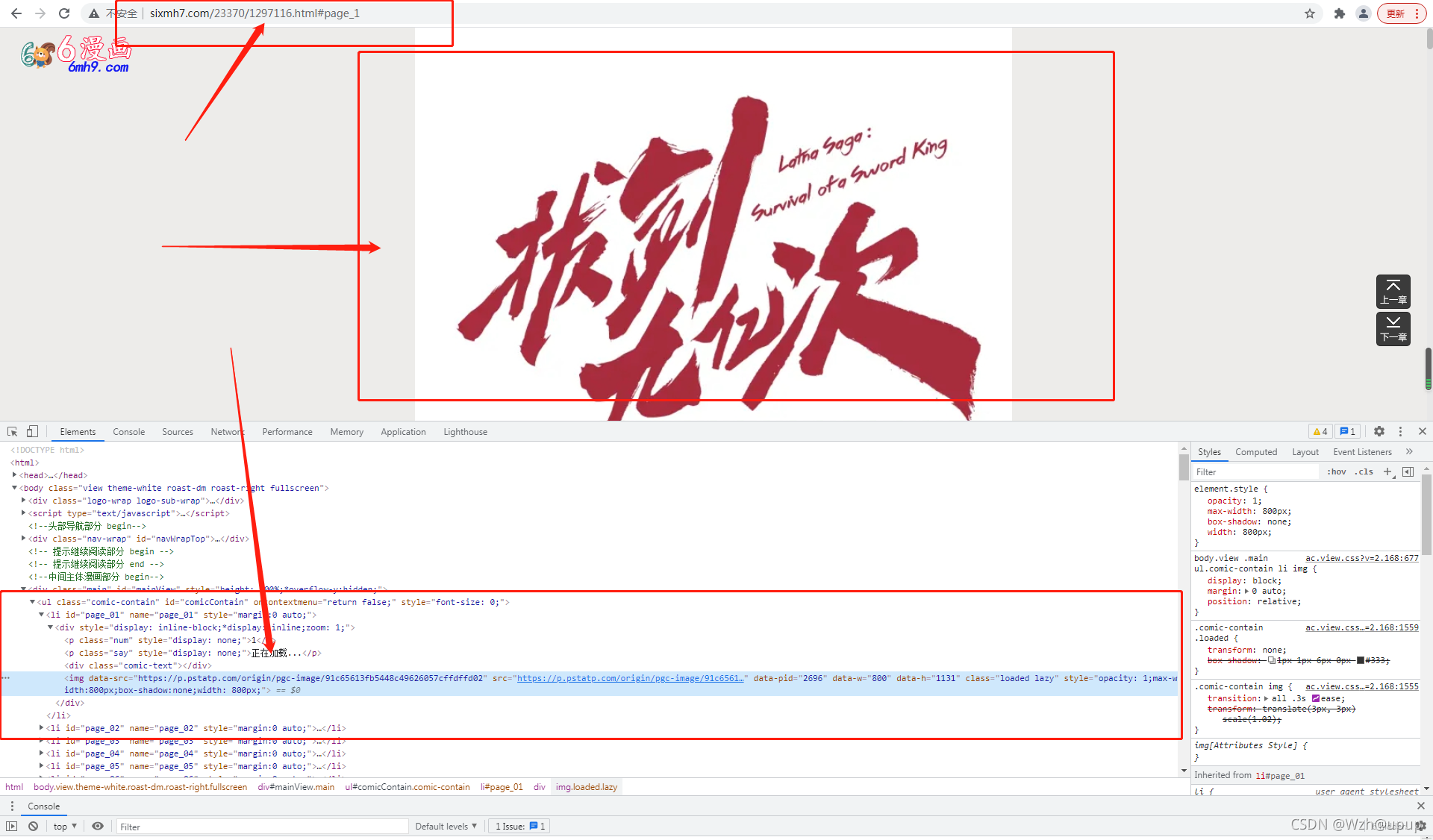
2.3.2 获取本页的图片链接
这里,我们很容易就和上面一样想到,利response.xpath('//li[@id="page_01"]/img/@src').extract()
来获取图片链接,但是当你真正这么做了,就会发现输出为空。原因就在于这一段html是利用简单的js动态加载进去的,你可以利用response.body来查看html不经过css和js修饰的源码。就会发现并没有打印出图片的信息,只有一堆js
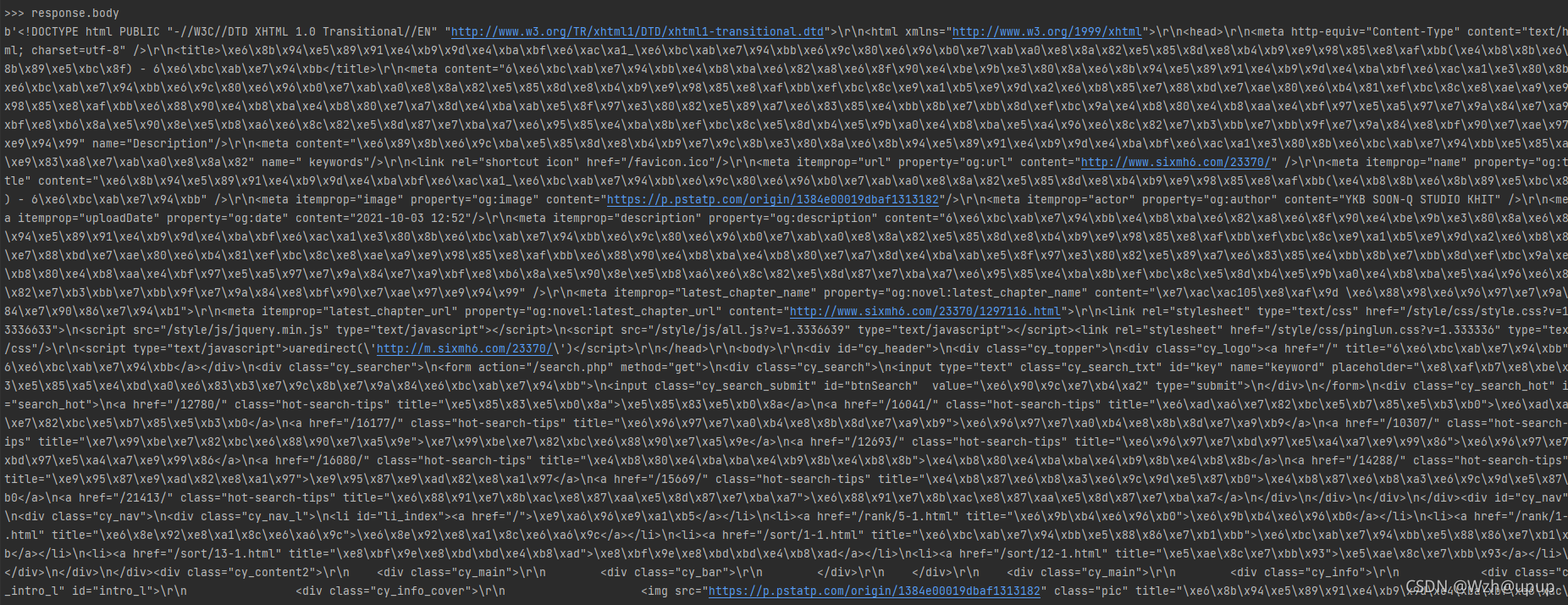
由于这里的动态加载方法较为简单,如下图,可以直接利用开发者工具查看到js代码,因此我们直接获取js,然后进行分析即可(后续复杂的动态请求晚点学)

但是在这里我们发现,这段js代码被加密了,所以我们需要对这段eval代码进行解密
从scrapy shell进去章节页面,输入如下命令获取js
response.xpath('//script/text()').extract()[2].strip()
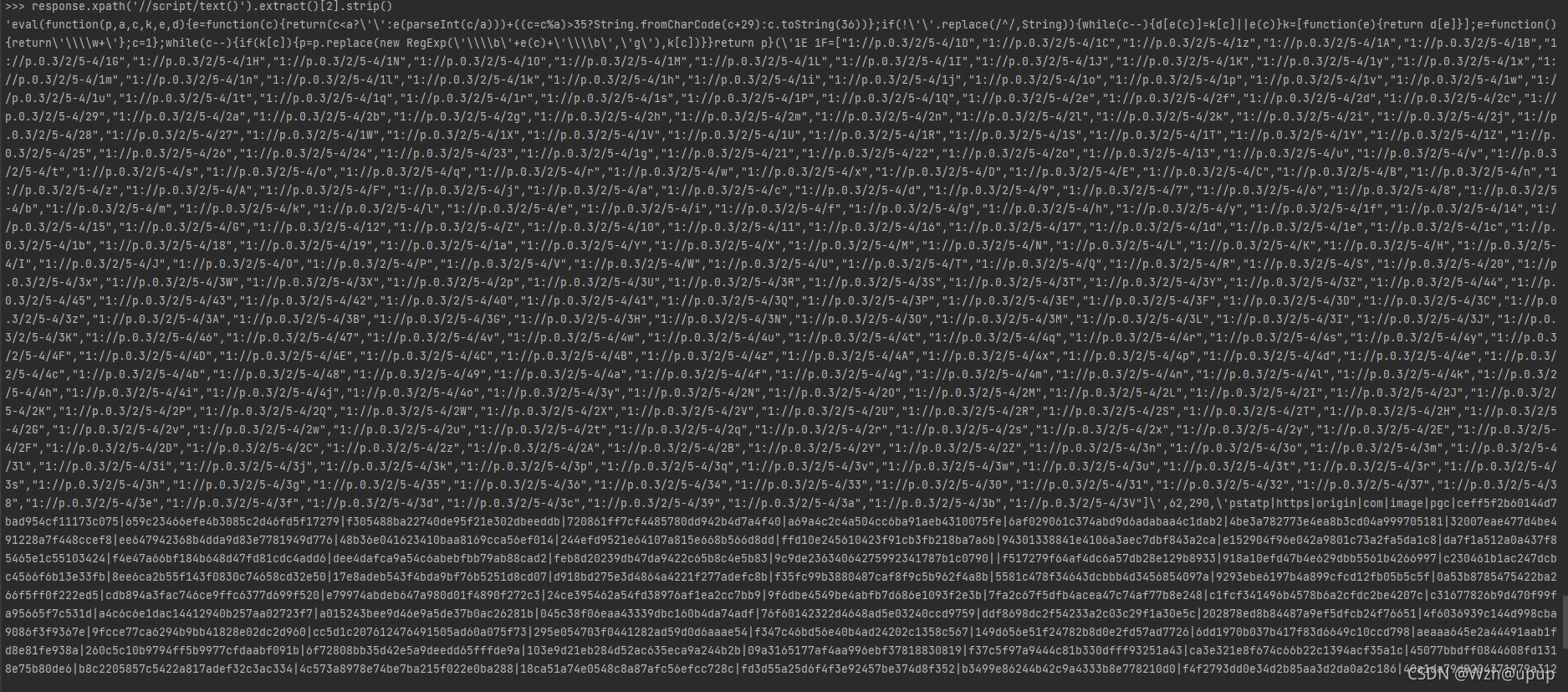
- eval_js = response.xpath('//script/text()').extract()[2].strip()
- js = """
- function decode(code) {
- if(code.indexOf("eval(function")>-1){
- code = code.replace(/^eval/, '');
- code = eval(code);
- return code;
- }
- }
- """
- com = execjs.compile(js)
- images = com.call('decode', eval_js)[13:].replace(']', '').split(",")
2.4这里我把前面需要的内容整理下,方便直接看:
- # 章节链接地址
- urls = response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/@href').extract()
- # 获取所有的章节名
- dir_names = response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/p/text()').extract()
- data = {
- "id": 23370,
- "id2": 1
- }
- response = requests.post("http://www.sixmh7.com/bookchapter/", data=data)
- for index in range(len(response.json())):
- link_url = "/23370/" + response.json()[index]['chapterid'] + ".html"
- urls.append(link_url)
- dir_name = response.json()[index]['chaptername']
- dir_names.append(dir_name))
-
- #进入第一章分析
- scrapy shell http://www.sixmh7.com/23370/1297116.html
- #获取IMG SRC(注意输出的是js,还需要后续处理)
- response.xpath('//script/text()').extract()[2].strip()

三、正式编写
1)items.py
- class Sixmh7Item(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- # 漫画名
- book_name = scrapy.Field()
- # 漫画别名
- nick_name = scrapy.Field()
- # 分类
- tags = scrapy.Field()
- # 作者名字
- author = scrapy.Field()
- # 状态,1代表完结,0代表连载中
- end = scrapy.Field()
- # 封面图远程地址
- cover_url = scrapy.Field()
- # 章节名
- chapter_name = scrapy.Field()
- # 地区id
- area_id = scrapy.Field()
- # 由图片标签组成的字符串
- images = scrapy.Field()
- # 章节序
- chapter_order = scrapy.Field()
- # 漫画简介
- summary = scrapy.Field()
- # 后台配置的api_key
- api_key = scrapy.Field()
- # 用来区别采集源,自己写
- src = scrapy.Field()
- # 用来唯一定义每个漫画,可以是该漫画的url,也可以是该漫画在被采集站的id
- src_url = scrapy.Field()
- # 用来唯一定义每个章节,与src_url同理
- c_src_url = scrapy.Field()
- # 章节链接
- link_url = scrapy.Field()
- BOT_NAME = 'sixmh7'
-
- SPIDER_MODULES = ['sixmh7.spiders']
- NEWSPIDER_MODULE = 'sixmh7.spiders'
- USER_AGENT = 'Mozilla/5.0'
- ROBOTSTXT_OBEY = False
- ITEM_PIPELINES = {
- 'sixmh7.pipelines.Sixmh7Pipeline': 1,
- }
3)sixmh.py(正式版)
- class SixmhSpider(scrapy.Spider):
- name = 'sixmh'
-
- def __init__(self):
- # 章节链接server域名
- self.server_link = 'http://www.sixmh7.com'
- self.allowed_domains = ['www.sixmh7.com']
- self.start_urls = ['http://www.sixmh7.com/23370/']
-
- # 可以查看scrapy文档
- def start_requests(self):
- yield scrapy.Request(url=self.start_urls[0], callback=self.parse1)
-
- # 解析response,获取每个大章节图片链接地址
- def parse1(self, response):
- items = []
- # 漫画名
- book_name = response.xpath('//div[@class="cy_title"]/h1/text()').extract()[0]
- # 漫画别名
- nick_name = response.xpath('//div[@class="cy_title"]/h1/text()').extract()[0]
- # 分类
- tags = response.xpath('//div[@class="cy_xinxi"]/span/text()').extract()[3].replace("标签:", "")
- # 作者名字
- author = response.xpath('//div[@class="cy_xinxi"]/span/text()').extract()[0].replace("作者:", "")
- # 状态,1代表完结,0代表连载中
- status = response.xpath('//div[@class="cy_xinxi"]/span/font/text()').extract()[0]
- if '连载中' == status:
- end = 0
- else:
- end = 1
- # 封面图远程地址
- cover_url = response.xpath('//div[@class="cy_info_cover"]/img/@src').extract()[0]
- # 漫画简介
- summary = response.xpath('//div[@class="cy_xinxi cy_desc"]/p/text()').extract()[0]
- # 章节链接地址
- urls = response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/@href').extract()
- # 获取所有的章节名
- dir_names = response.xpath('//ul[@id="mh-chapter-list-ol-0"]/li/a/p/text()').extract()
- data = {
- "id": 23370,
- "id2": 1
- }
- response = requests.post("http://www.sixmh7.com/bookchapter/", data=data)
- for index in range(len(response.json())):
- link_url = "/23370/" + response.json()[index]['chapterid'] + ".html"
- urls.append(link_url)
- dir_name = response.json()[index]['chaptername']
- dir_names.append(dir_name)
- # 保存章节链接和章节名
- for index in range(len(urls)):
- item = Sixmh7Item()
- item['api_key'] = 'abc123456'
- item['link_url'] = self.server_link + urls[index]
- item['chapter_name'] = dir_names[index]
- item['chapter_order'] = re.sub('\D', '', dir_names[index])
- item['book_name'] = book_name
- item['nick_name'] = nick_name
- item['tags'] = tags
- item['author'] = author
- item['end'] = end
- item['cover_url'] = cover_url
- item['summary'] = summary
- item['src'] = self.server_link
- item['src_url'] = self.start_urls[0]
- item['c_src_url'] = self.server_link + urls[index]
- item['area_id'] = 1
- items.append(item)
- # 根据每个章节的连接,发送request请求,并传递item参数
- for item in items:
- yield scrapy.Request(url=item['link_url'], meta={'item': item}, callback=self.parse2)
-
- # 解析一个章节的第一页的页码数和图片链接
- def parse2(self, response):
- # 接收传递的item
- item = response.meta['item']
- # 下面一句不能少,是用来更新要解析的章节链接
- item['link_url'] = response.url
- hxs = Selector(response)
- # 获取章节第一页图片的链接
- eval_js = hxs.xpath('//script/text()').extract()[2].strip()
- js = """
- function decode(code) {
- if(code.indexOf("eval(function")>-1){
- code = code.replace(/^eval/, '');
- code = eval(code);
- return code;
- }
- }
- """
- com = execjs.compile(js)
- images = com.call('decode', eval_js)[13:].replace(']', '').split(",")
- tags = []
- for i in images:
- tags.append(eval(i))
- # 将获取的章节的第一页的图片链接保存到img_url中
- item['images'] = ','.join(tags)
- # 返回item,交给item pipeline下载图片
- yield item
这一段代码比较多,但是我相信只要你一步步敲过来,那么肯定很容易理解代码,而且我在学习原博客的过程中,也是遇到了许多坑,修改了很多地方,如果你直接复制我的代码却没法运行,你可以这么做:将报错以后的地方全部注释,然后print输出报错的东西(比如item报错你就print(item)一下),然后对照报错信息进行修改。
- import requests
-
-
- class Sixmh7Pipeline:
- def process_item(self, item, spider):
- url = 'http://www.xswang.online/api.php/postbot/save'
- print(item)
- res = requests.post(url=url, data=item)
5)运行
scrapy crawl sixmh四、总结和后续
总的来说,学了这个教程后就有思路能爬取某个网站的所有漫画之类的了,但我依旧存在以下几个问题:
复杂的动态加载如何实现爬取
遇到需要登录,甚至需要vip的内容如何爬取
这些就留着接下来一段时间学习了




