
数据结构(Java)学习笔记——知识点:图
赞
踩
数据结构(Java)学习笔记——知识点:图
十五、图
前面我们学习了线性表和树,而线性表局限于一个直接前驱和一个直接后继的关系。树也只能有一个直接前驱,也就是父节点。当我们需要表示多对多的关系的时候,我们就用到了图。
1、基本概述
图也是一种数据结构,其中节点可以有0个或多个相邻元素。两个节点之间的链接被称为边。节点也可以称为顶点。如图所示:
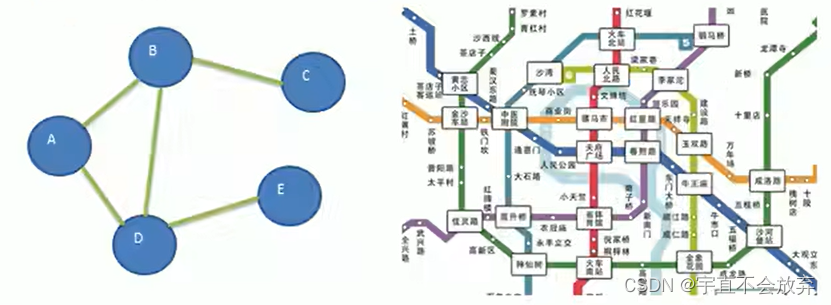
几个专业名词要知道:
1)顶点(vertex)
2)边(edge)
3)路径
4)无向图(上图):无向图就是链接没有方向,可以是A -> B,也可以是B -> A。
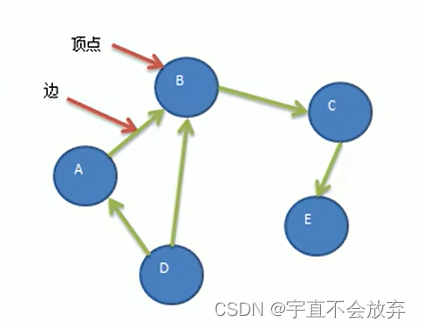
5)有向图(下图):有向图就是顶点之间的连接有方向,只能是A -> B。
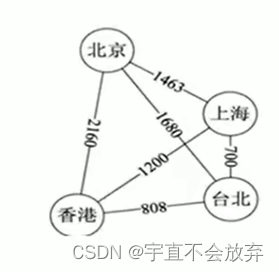
6)带权图(下图):边带权值,这种图也称为网。
2、图的表示方式
1)邻接矩阵(二维数组表示)
邻接矩阵是表示图形中顶点直接相邻关系的矩阵,对于 n 个顶点的图而言,矩阵的 row 和 col 表示的是 1…n 个点。
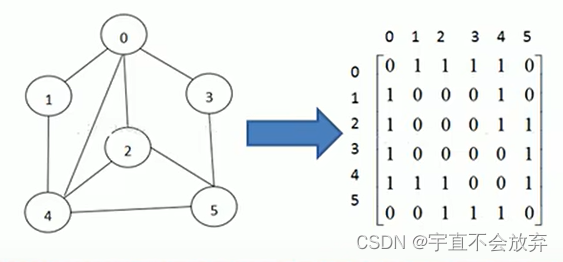
能连通,就用 1 表示,连不通就用 0 表示。
邻接矩阵需要给每个顶点都分配n个边的空间,其实有很多边都是不存在的,会造成空间的一定损失。所以为了解决,我们就有邻接表了。
2)邻接表(链表表示)
邻接表的实现只关心存在的边,不关心不存在id边。因此没有空间的浪费,邻接表由数组 + 链表组成。
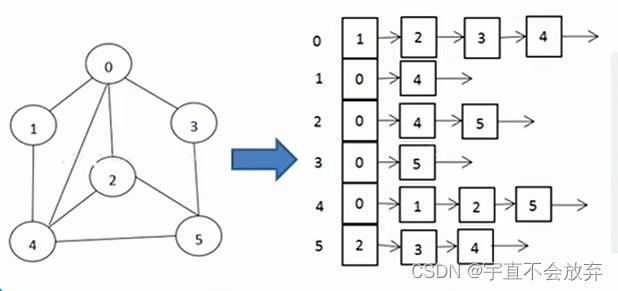
下标为 0 的数组,存放的链表都是和 0 这个节点直接相连的。
下标为 1 的数组,存放的链表都是和 1 这个节点直接相连的。.
以此类推。。。。。
3、创建图
需求:要求用代码实现如下图的数据结构。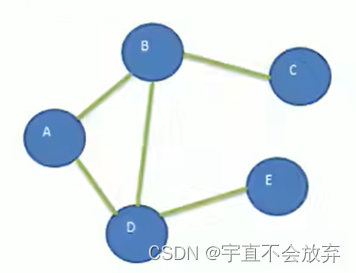
要求使用邻接矩阵来实现。
思路分析
1)顶点用String来存储,用ArrayList来存储二维数组
2)用 int[][] edges 来存储边。0表示不能直接相连,1表示能直接相连。
代码实现
public class Graph { private ArrayList<String> vertexList;//存储顶点集合 private int[][] edges;//存储邻接矩阵 private int numOfEdges;//表示边的数目 public static void main(String[] args) { //测试节点是否创建成功 int n = 5; String VertexValue[] = {"A","B","C","D","E"}; //创建图对象 Graph graph = new Graph(n); //循环添加顶点 for(String vertex : VertexValue){ graph.insertVertex(vertex); } //添加边 A-B A-C B-C B-D B-E graph.insertEdge(0,1,1); graph.insertEdge(0,2,1); graph.insertEdge(1,2,1); graph.insertEdge(1,3,1); graph.insertEdge(1,4,1); //显示邻接矩阵 graph.showGraph(); } //构造器 public Graph(int n){ //初始化矩阵和vertexList edges = new int[n][n]; vertexList = new ArrayList<String>(n); numOfEdges = 0; } //图中常用的方法 //返回节点的个数 public int getNumOfVertex(){ return vertexList.size(); } //显示图对应的矩阵 public void showGraph(){ for(int[] link : edges){ System.out.println(Arrays.toString(link)); } } //得到边的数目 public int getNumOfEdges(){ return numOfEdges; } //返回节点i(下标)对应的数据 public String getValueByIndex(int i){ return vertexList.get(i); } //返回v1和v2的权值 public int getWeight(int v1, int v2){ return edges[v1][v2]; } //插入节点 public void insertVertex(String vertex){ vertexList.add(vertex); } //添加边 public void insertEdge(int v1, int v2, int weight){ edges[v1][v2] = weight; edges[v2][v1] = weight; numOfEdges++;//节点数量自加 } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
运行结果
[0, 1, 1, 0, 0]
[1, 0, 1, 1, 1]
[1, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
- 1
- 2
- 3
- 4
- 5
所谓的图遍历,即便是对结点的访问。一个图由这么多节点,如何遍历这些节点,需要特定策略,一般两种访问策略:(1)深度优先遍历(2)广度优先遍历
4、图的深度优先遍历
图的深度优先搜索(Depth First Search)
1)深度优先遍历,从初始访问节点出发,初始访问节点可能有多个邻接节点,深度优先遍历的策略就是首先访问第一个邻接节点,然后再以这个被访问的邻接节点作为初始节点,访问它的第一个邻接节点,可以这样理解:每次都在访问完当前节点后首先访问当前节点的第一个邻接节点。
2)我们可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个节点的所有邻接节点进行横向访问。
3)显然,深度优先搜索是一个递归的过程。
深度优先遍历思路
1)访问初始节点 v,并标记节点 v 为已访问。
2)查找节点 v 的第一个邻接节点 w。
3)若 w 存在,则继续执行 4,如果 w 不存在,则返回到第 1 步,将从 v 的下一个节点继续。
4)若 w 未被访问,对 w 进行深度优先遍历递归(即把 w 当作另一个 v ,然后进行步骤 1 2 3 )
5)查找节点 v 的 w 邻接节点的下一个邻接节点,转到步骤 3 。
深度优先遍历代码实现
public class Graph { private ArrayList<String> vertexList;//存储顶点集合 private int[][] edges;//存储邻接矩阵 private int numOfEdges;//表示边的数目 //定义一个数组,boolean[],记录某个节点是否被访问过。 private boolean[] isVisited; public static void main(String[] args) { //测试节点是否创建成功 int n = 5; String VertexValue[] = {"A","B","C","D","E"}; //创建图对象 Graph graph = new Graph(n); //循环添加顶点 for(String vertex : VertexValue){ graph.insertVertex(vertex); } //添加边 A-B A-C B-C B-D B-E graph.insertEdge(0,1,1); graph.insertEdge(0,2,1); graph.insertEdge(1,2,1); graph.insertEdge(1,3,1); graph.insertEdge(1,4,1); //显示邻接矩阵 graph.showGraph(); graph.dfs(graph.isVisited, 0); } //找到第一个邻接节点 public int getFirstNeighbor(int index){ for(int i = 0; i < vertexList.size(); i++){ if(edges[index][i] > 0){//有邻接节点 return i; } } return -1; } //根据前一个邻接节点的下标来获取下一个邻接节点 public int getNextNeighbor(int row,int col){ for(int j = col + 1; j < vertexList.size(); j++){ if(edges[row][j] > 0){ return j;//返回第一个未找到过的节点 } } return -1;//没找到就返回-1 } //深度优先遍历 public void dfs(boolean[] isVisited,int index){ System.out.print(getValueByIndex(index) + "->");//输出当前节点 isVisited[index] = true;//输出后将该节点设置为已被访问 //查找当前节点的第一个邻接节点 int w = getFirstNeighbor(index); while(w != -1){//如果有邻接节点,就一直遍历 if(!isVisited[w]){//如果当前节点没有被访问过 dfs(isVisited,w);//接着搜索下一行的树 } //如果当前节点已经被访问过了 w = getNextNeighbor(index,w);//向下一层搜索 } } //对上面的方法进行重载 public void dfs(){ //遍历所有的节点,进行dfs【回溯】 for(int i = 0; i < getNumOfVertex(); i++){ if(!isVisited[i]){//如果还有没被找到的节点,就再以这个节点为起点,重新遍历一下 dfs(isVisited,i); } } } //构造器 public Graph(int n){ //初始化矩阵和vertexList edges = new int[n][n]; vertexList = new ArrayList<String>(n); numOfEdges = 0; isVisited = new boolean[n]; } //图中常用的方法 //返回节点的个数 public int getNumOfVertex(){ return vertexList.size(); } //显示图对应的矩阵 public void showGraph(){ for(int[] link : edges){ System.out.println(Arrays.toString(link)); } } //得到边的数目 public int getNumOfEdges(){ return numOfEdges; } //返回节点i(下标)对应的数据 public String getValueByIndex(int i){ return vertexList.get(i); } //返回v1和v2的权值 public int getWeight(int v1, int v2){ return edges[v1][v2]; } //插入节点 public void insertVertex(String vertex){ vertexList.add(vertex); } //添加边 public void insertEdge(int v1, int v2, int weight){ edges[v1][v2] = weight; edges[v2][v1] = weight; numOfEdges++;//节点数量自加 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
运行结果
[0, 1, 1, 0, 0]
[1, 0, 1, 1, 1]
[1, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
A->B->C->D->E->
- 1
- 2
- 3
- 4
- 5
- 6
5、图的广度优先遍历
图的广度优先搜索(Broad First Search)
类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的节点的顺序,以便按照这一个顺序来访问这些节点的邻接节点。
广度优先遍历思路
1)访问初始节点 v,并标记节点 v 为已访问。
2)节点 v 入队列。
3)当队列非空时,继续执行,否则算法结束。
4)出队列,取得队头节点 u。
5)查找节点 u 的第一个邻接节点 w。
6)若节点 u 的邻接节点 w 不存在,则转到步骤 3);否则循环执行一下三个步骤。
6.1 若节点 w 尚未被访问,则访问节点 w 并标记为已访问。
6.2 节点 w 入队列
6.3 查找节点u的继w邻接节点后的下一个邻接节点 w ,转到步骤 6).
广度优先遍历代码实现
package com.database.graph; import java.util.ArrayList; import java.util.Arrays; import java.util.LinkedList; public class Graph { private ArrayList<String> vertexList;//存储顶点集合 private int[][] edges;//存储邻接矩阵 private int numOfEdges;//表示边的数目 //定义一个数组,boolean[],记录某个节点是否被访问过。 private boolean[] isVisited; public static void main(String[] args) { //测试节点是否创建成功 int n = 5; String VertexValue[] = {"A","B","C","D","E"}; //创建图对象 Graph graph = new Graph(n); //循环添加顶点 for(String vertex : VertexValue){ graph.insertVertex(vertex); } //添加边 A-B A-C B-C B-D B-E graph.insertEdge(0,1,1); graph.insertEdge(0,2,1); graph.insertEdge(1,2,1); graph.insertEdge(1,3,1); graph.insertEdge(1,4,1); //显示邻接矩阵 graph.showGraph(); //dfs遍历 //System.out.println("深度优先:");//A-B-C-D-E //graph.dfs(); //bfs遍历 System.out.println("广度优先:");//A-B-C-D-E graph.bfs(); } //找到第一个邻接节点 public int getFirstNeighbor(int index){ for(int i = 0; i < vertexList.size(); i++){ if(edges[index][i] > 0){//有邻接节点 return i; } } return -1; } //根据前一个邻接节点的下标来获取下一个邻接节点 public int getNextNeighbor(int row,int col){ for(int j = col + 1; j < vertexList.size(); j++){ if(edges[row][j] > 0){ return j;//返回第一个未找到过的节点 } } return -1;//没找到就返回-1 } //广度优先遍历 public void bfs(boolean[] isVisited, int i){ int u;//表示队列的头节点对应的下标 int w;//邻接节点w //队列,记录节点访问的顺序 LinkedList queue = new LinkedList(); //访问节点,输出节点信息 System.out.print(getValueByIndex(i) + "->"); //标记为已访问 isVisited[i] = true; //将节点加入队列 queue.addLast(i); while(!queue.isEmpty()){ //取出队列的头节点下标 u = (Integer) queue.removeFirst(); //得到第一个邻接节点的下标w w = getFirstNeighbor(u); while(w != -1){//找到了 //是否访问过 if(!isVisited[w]){//没访问 System.out.print(getValueByIndex(w) + "->"); //标记已经访问 isVisited[w] = true; //入队 queue.addLast(w); } //已经访问过,以u为前驱节点,找w后面的下一个邻接节点 w = getNextNeighbor(u,w);//体现出广度优先 } } } //遍历所有的节点,都进行广度优先搜索 public void bfs(){ for(int i = 0; i < getNumOfVertex(); i++){ if(!isVisited[i]){ bfs(isVisited,i); } } } //深度优先遍历 public void dfs(boolean[] isVisited,int index){ System.out.print(getValueByIndex(index) + "->");//输出当前节点 isVisited[index] = true;//输出后将该节点设置为已被访问 //查找当前节点的第一个邻接节点 int w = getFirstNeighbor(index); while(w != -1){//如果有邻接节点,就一直遍历 if(!isVisited[w]){//如果当前节点没有被访问过 dfs(isVisited,w);//接着搜索下一行的树 } //如果当前节点已经被访问过了 w = getNextNeighbor(index,w);//向下一层搜索 } } //对上面的方法进行重载 public void dfs(){ //遍历所有的节点,进行dfs【回溯】 for(int i = 0; i < getNumOfVertex(); i++){ if(!isVisited[i]){//如果还有没被找到的节点,就再以这个节点为起点,重新遍历一下 dfs(isVisited,i); } } } //构造器 public Graph(int n){ //初始化矩阵和vertexList edges = new int[n][n]; vertexList = new ArrayList<String>(n); numOfEdges = 0; isVisited = new boolean[n]; } //图中常用的方法 //返回节点的个数 public int getNumOfVertex(){ return vertexList.size(); } //显示图对应的矩阵 public void showGraph(){ for(int[] link : edges){ System.out.println(Arrays.toString(link)); } } //得到边的数目 public int getNumOfEdges(){ return numOfEdges; } //返回节点i(下标)对应的数据 public String getValueByIndex(int i){ return vertexList.get(i); } //返回v1和v2的权值 public int getWeight(int v1, int v2){ return edges[v1][v2]; } //插入节点 public void insertVertex(String vertex){ vertexList.add(vertex); } //添加边 public void insertEdge(int v1, int v2, int weight){ edges[v1][v2] = weight; edges[v2][v1] = weight; numOfEdges++;//节点数量自加 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
运行结果
[0, 1, 1, 0, 0]
[1, 0, 1, 1, 1]
[1, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
[0, 1, 0, 0, 0]
广度优先:
A->B->C->D->E->
- 1
- 2
- 3
- 4
- 5
- 6
- 7




