
- 1史上最全!考研考公视频在某度云倍速 | 敲重点!_gwy 学习 视频加速
- 2PMP一般要提前多久备考?_pmp需要准备多久
- 3elasticsearch-java api之搜索(二)——聚合_getaggregations
- 47-22龟兔赛跑/PTA基础编程题目集_乌龟与兔子进行赛跑,跑场是一个矩型跑道,跑道边可以随地进行休息。乌龟每分钟可以
- 5Linux系统中运行.sh文件的几种方法_.sh文件如何运行
- 6frida学习及使用
- 7React之Props,及与state的区别_react props和state区别用法
- 81.Vue概念_用于封装与应用程序的业务逻辑相关的数据
- 9ts:使用ts-node执行ts文件_node 运行ts
- 10CrossOver 23.7 for Mac中文破解版软件安装图文激活教程
写给工程师的 MacBook 商用级大模型知识库部署方案
赞
踩

本文介绍了如何在自己的 MacBook 上部署一套知识库方案辅助自己的知识管理工作,希望能给每位计划自己搭建大模型知识库应用的工程师一点参考。

背景
历史的车轮滚滚向前,大模型技术发展日新月异,每天都有新鲜的技术出炉,让人目不暇接,同时具备可玩性和想象空间的各种应用和开源库,仿佛让自己回到了第一次设置 JAVA_HOME 的日子,作为一枚古典工程师,我专门挑了个可能对手上工作有帮助的方向小试一把,尝试在自己的 MacBook 上部署一套知识库方案,看看能不能辅助自己的知识管理工作。
我自己的 Macbook 配置情况如下,可以流畅地运行没问题。经过量化处理的大模型,还是对办公本很友好的。

为什么要在 MacBook 搭建而不是直接采用现成的云服务呢?最核心最重要的是我们手上的文档资料出于安全要求,不能随便上传云服务,也就无法实际验证知识库的实际效用;另外对于工程师来说,自己亲手搭建一个完整的方案、能灵活调整和对接各种不同的模型、评测各种模型不同的表现,也是出于对技术的探索本能使然。
鉴于大模型已经是大模型及其周边概念已经是大家耳熟能详的东西,我这里就不再重复阐述相关的基础概念和理论了,直接进入动手环节,以用最快的速度部署起一个可用的知识库平台为目标,先用起来,再分各个环节优化。

方案概述
▐ 应用架构
首先来看一下最终方案的应用架构是什么样子(下图)。在这套方案中,我们采用实力排上游、并且在使用上对学术和商业都友好的国产大模型 ChatGLM3-6B 对话模型和基于 m3e-base 模型的 embedding search RAG 方案;基于这两个模型封装和 ChatGPT 兼容的 API 接口协议;通过引入 One API 接口管理&分发系统,形成统一的 LLM 接口渠道管理平台规范,并把封装好的接口协议注册进去;搭建与 Dify.ai 齐名的开源大模型知识库平台管理系统 FastGPT,实现集私有知识数据源预处理、嵌入检索、大模型对话一体的完整知识库应用流程。麻雀虽小五脏俱全,最终形成一套既满足商用标准、又能在 MacBook 跑起来的的方案。虽然智能程度和实际需求还有一定差距,但至少我们在不用额外购买显卡或云服务的情况下,以最小成本部署运行、并且能导入实际业务数据(如语雀知识库)进行实操验证,值得每位工程师都来动手尝试一下。
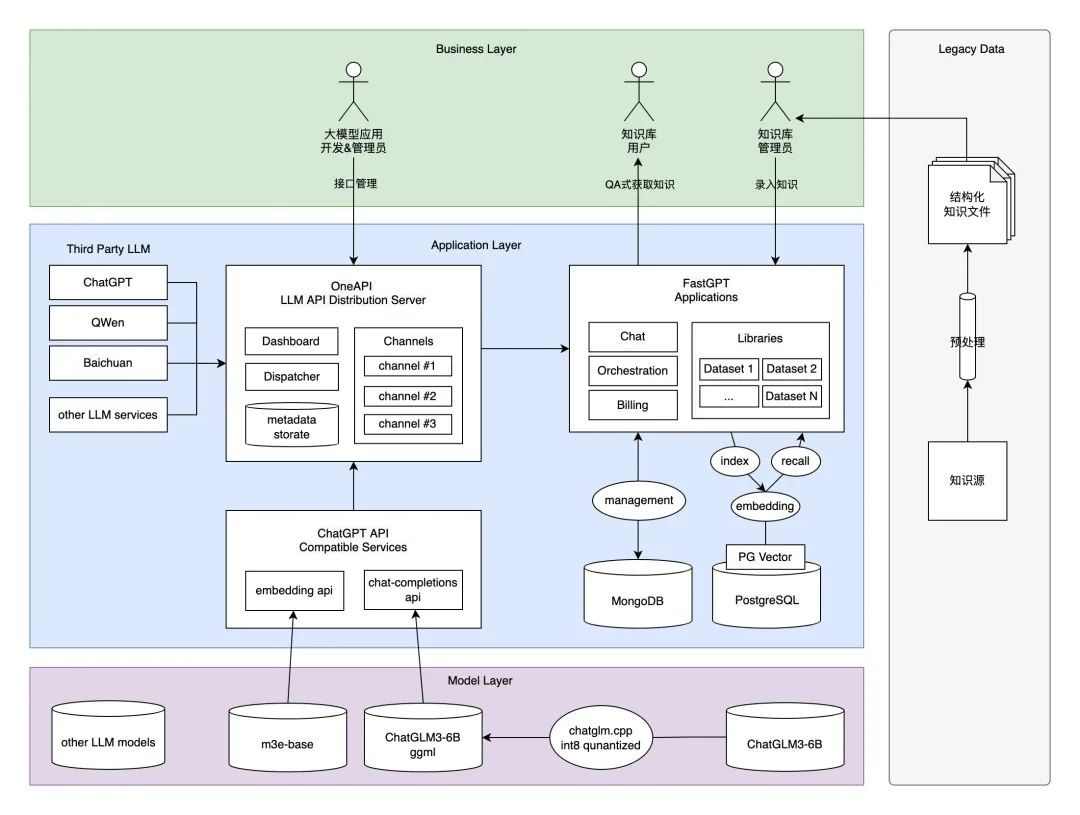
▐ 成型展示
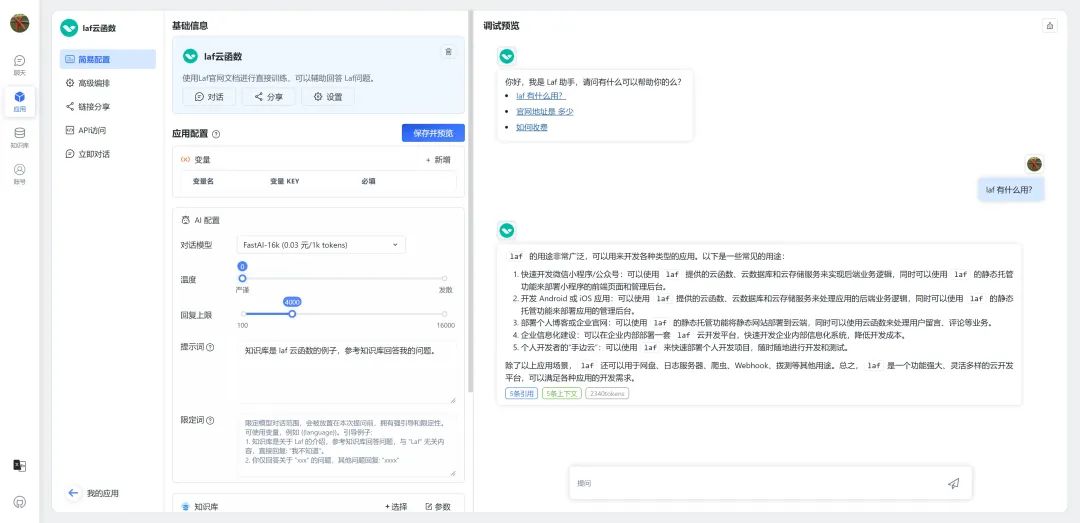
在用户终端,我们基于 FastGPT 提供知识库管理及使用方案。引用其官网介绍:FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。
先放一张官网上的图片,来增加一点吸引朋友们动手操作的动力:
▐ 部署要点
本套方案部署分为四个主要环节、14个具体步骤,只要一步步实操下去,每位朋友都可以在自己的本本上拥有属于自己的私有大模型知识库系统,步骤清单如下:
主要环节 | 详细步骤 |
一、准备大模型 | 1.1 下载对话语言模型 ChatGLM3-6B 1.2 下载文本嵌入模型 m3e-base 1.3 使用 chatglm.cpp 对 ChatGLM3-6B 进行量化加速 1.4 验证模型问答效果 |
二、搭建模型API服务 | 2.1 搭建模型API 2.2 搭建 One API 接口管理/分发系统 2.3 验证模型接口能力 |
三、搭建知识库应用 | 3.1 安装 MongoDB 3.2 安装 PostgreSQL & pgvector 3.3 搭建 FastGPT 知识库问答系统 3.4 验证模型对话能力 |
四、知识库问答实战 | 4.1 准备知识库语料 4.2 导入知识库数据 4.3 验证知识库问答效果 |
部分步骤可以简单地通过 Docker 镜像一键部署完成,但本着对细节一杆子插到底的部署思路,还是采取了纯手工作业的方法。注意,下面的步骤中仅包含了关键的命令,完整的命令可以参考对应系统的官网介绍。部分安装步骤如果速度不够理想,可以考虑采用国内源,包含但不限于 go、brew、pip、npm 等。

详细步骤
▐ 准备离线模型
这个环节我们的主要任务是把模型文件准备好、完成量化,并通过命令行的方式,进行交互式对话验证。
下载对话语言模型 ChatGLM3-6B
为什么选择 ChatGLM3-6B?常年霸榜的开源国产之光。ChatGLM3 一共开源了对话模型 ChatGLM-6B、基础模型 ChatGLM-6B-Base、长文本对话模型 ChatGLM3-6B-32K,对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。无论是用来做上手实践还是微调练习,目前看来都是比较好的选择。
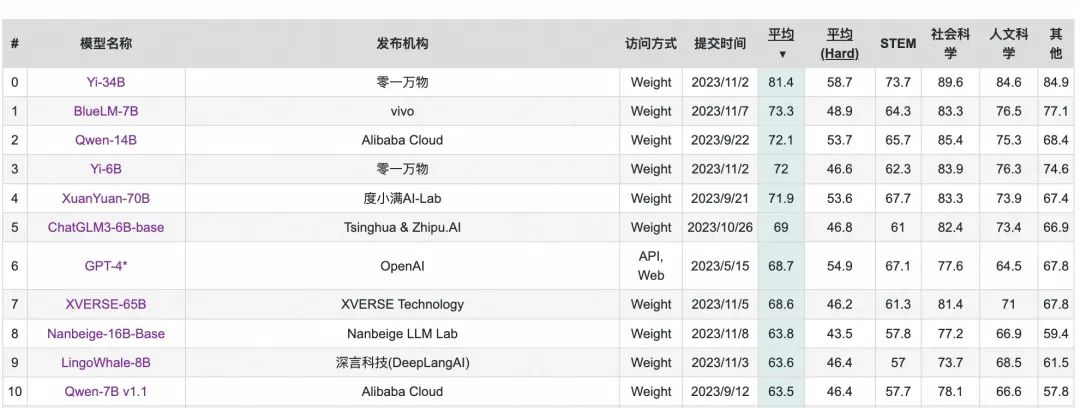
其实最重要的是,看看排行榜上的可选项,我的 MacBook 16G 内存只能带得动 ChatGLM3-6B 量化版本:
ChatGLM3-6B 现在比较方便的下载渠道有 HuggingFace 和 ModelScope,但是很明显能直接下载下来的可能性不大,所以我用家里的旧电脑科学下载后放到私有云CDN上,然后再用公司电脑下载,也方便未来随时随地取用,就是要花点小钱。ModelScope 也试过,不能直接下载文件,并且用 git clone 速度也不太理想,遂放弃。
如果用老一点的版本 ChatGLM2-6B 的话,网上也能找到一些比较好用的第三方镜像站。
HuggingFace:THUDM/chatglm3-6b
ModelScope:ZhipuAI/chatglm3-6b(地址:https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary)
- // 从 Git 仓库下载模型文件
- // HuggingFace
- git lfs install
- git clone https://huggingface.co/THUDM/chatglm3-6b
-
-
- // ModelScope
- git lfs install
- git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
下载文本嵌入模型 m3e-base
为什么选择 moka-ai 的 M3E 模型 m3e-base?M3E 向量模型属于小模型,资源使用不高,CPU 也可以运行,使用场景主要是中文,少量英文的情况。用来验证我们的知识库系统足够了
官方下载地址:moka-ai/m3e-base,先把所有的模型文件 download 下来,后面使用
使用 chatglm.cpp 对 ChatGLM3-6B 进行量化加速
当我第一次知道 chatglm.cpp,只能说好人一生平安,chatglm.cpp 的出现拯救了纯 MacBook 党,让我们能在(低性能的)果本上基于 CPU 进行推理,也不会损失过多的精度。(其实损失多少我也不知道,不影响我们正常进行工程部署验证就行)
Github Repo: https://github.com/li-plus/chatglm.cpp
我使用的 Python 版本:3.11,最好单独准备一个 virtualenv

安装依赖:
- cd /Users/yaolu/AGI/github/chatglm.cpp
-
-
- # 先初始化 git 仓库
- git submodule update --init --recursive
-
-
- # 构建可执行文件
- cmake -B build
- cmake --build build -j
-
-
- # 安装 Python 依赖
- pip install .
如果发生 No module named 'chatglm_cpp._C' 的错误,把编译出来的文件 _C.cpython-311-darwin.so 放到 chatglm_cpp 目录下。
对 ChatGLM3-6B 进行 8-bit 量化处理:
python ./chatglm_cpp/convert.py -i /Users/yaolu/AGI/huggingface/THUDM/chatglm3-6b -t q8_0 -o chatglm3-ggml-q8.bin如果电脑带不动,还可以尝试 4-bit、5-bit 参数量化,完整参数列表见 chatglm.cpp 的 quantization types
验证模型问答效果
完成模型量化后,就可以在本地把大模型跑起来了,命令如下:
./build/bin/main -m chatglm3-ggml-q8.bin -i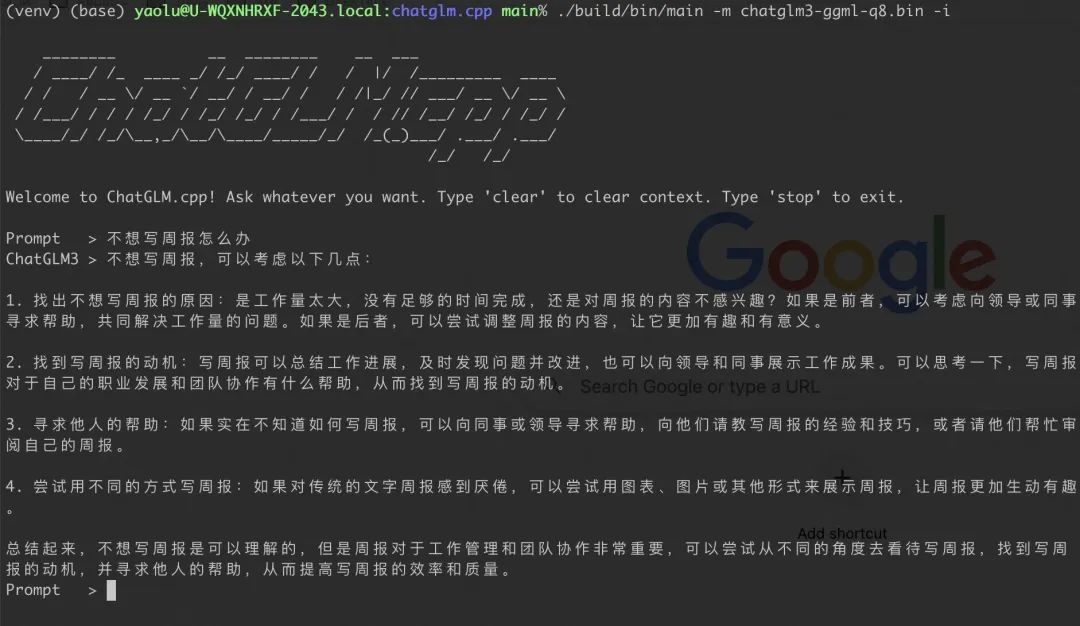
▐ 搭建模型API服务
我们在这个环节要完成的任务是,按照 ChatGPT 的接口规范、基于 FastAPI 封装 ChatGLM3-6B 的对话和 m3e-base 的嵌入能力;并注册到 One API 接口管理/分发系统中。
搭建模型API
用 chatglm.cpp 自带的 openai_api.py 魔改了一下,使其支持完成对话和文本 embedding 的两个核心调用:
/v1/chat/completions
/v1/embeddings
代码如下:
- import asyncio
- import logging
- import time
- from typing import List, Literal, Optional, Union
-
-
- import chatglm_cpp
- from fastapi import FastAPI, HTTPException, status, Depends
- from fastapi.middleware.cors import CORSMiddleware
- from pydantic import BaseModel, Field#, computed_field
- #from pydantic_settings import BaseSettings
- from sse_starlette.sse import EventSourceResponse
-
-
- from sentence_transformers import SentenceTransformer
- from sklearn.preprocessing import PolynomialFeatures
- import numpy as np
- import tiktoken
-
-
- logging.basicConfig(level=logging.INFO, format=r"%(asctime)s - %(module)s - %(levelname)s - %(message)s")
-
-
-
-
- class Settings(object):
- model: str = "/Users/yaolu/AGI/github/chatglm.cpp/chatglm3-ggml-q8.bin"
- num_threads: int = 0
-
-
-
-
- class ChatMessage(BaseModel):
- role: Literal["system", "user", "assistant"]
- content: str
-
-
-
-
- class DeltaMessage(BaseModel):
- role: Optional[Literal["system", "user", "assistant"]] = None
- content: Optional[str] = None
-
-
-
-
- class ChatCompletionRequest(BaseModel):
- model: str = "default-model"
- messages: List[ChatMessage]
- temperature: float = Field(default=0.95, ge=0.0, le=2.0)
- top_p: float = Field(default=0.7, ge=0.0, le=1.0)
- stream: bool = False
- max_tokens: int = Field(default=2048, ge=0)
-
-
- model_config = {
- "json_schema_extra": {"examples": [{"model": "default-model", "messages": [{"role": "user", "content": "你好"}]}]}
- }
-
-
-
-
- class ChatCompletionResponseChoice(BaseModel):
- index: int = 0
- message: ChatMessage
- finish_reason: Literal["stop", "length"] = "stop"
-
-
-
-
- class ChatCompletionResponseStreamChoice(BaseModel):
- index: int = 0
- delta: DeltaMessage
- finish_reason: Optional[Literal["stop", "length"]] = None
-
-
-
-
- class ChatCompletionUsage(BaseModel):
- prompt_tokens: int
- completion_tokens: int
-
-
- #@computed_field
- @property
- def total_tokens(self) -> int:
- return self.prompt_tokens + self.completion_tokens
-
-
-
-
- class ChatCompletionResponse(BaseModel):
- id: str = "chatcmpl"
- model: str = "default-model"
- object: Literal["chat.completion", "chat.completion.chunk"]
- created: int = Field(default_factory=lambda: int(time.time()))
- choices: Union[List[ChatCompletionResponseChoice], List[ChatCompletionResponseStreamChoice]]
- usage: Optional[ChatCompletionUsage] = None
-
-
- model_config = {
- "json_schema_extra": {
- "examples": [
- {
- "id": "chatcmpl",
- "model": "default-model",
- "object": "chat.completion",
- "created": 1691166146,
- "choices": [
- {
- "index": 0,
- "message": {"role": "assistant", "content": "你好声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/54287?site推荐阅读
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

