
热门标签
热门文章
- 1JavaScript系列—Object.assign()介绍以及原理实现_js object.assign()
- 22023新华为OD机试题 - 最小的调整次数 特异性双端队列(JavaScript) | 刷完必过_有一个特异性的双端队列,该队列可以从头部或尾部添加数据,但是只能从头部移出数据
- 3HTML学生个人网站作业设计:电影网站设计——钢铁侠电影下(9页) HTML+CSS+JavaScript 简单DIV布局个人介绍网页模板代码 DW学生个人网站制作成品下载_钢铁侠网页毕业设计
- 4.NET中常见的错误及解决方法
- 5win python 怎么创建一个独立的进程_在Windows下将Python转化成独立的EXE程序 (转载)...
- 6最新手机厂商Android kernel内核下载_小米内核开源地址
- 7Qt动画入门QPropertyAnimation_qt qpropertyanimation卡顿
- 8Django框架全面讲解 -- 中间件(MiddleWare)_django middleware 只管一个app
- 9微服务SpringCloud(Bus 消息总线)整合十九_spring bus和mq
- 10Graph U-Nets 笔记_graphunet
当前位置: article > 正文
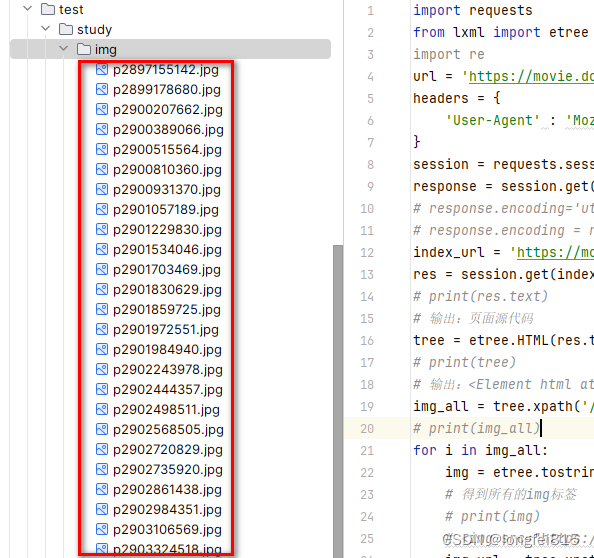
python爬虫之豆瓣首页图片爬取
作者:数据可视化灵魂 | 2024-02-01 10:17:11
赞
踩
python爬虫之豆瓣首页图片爬取
- import requests
- from lxml import etree
- import re
- url = 'https://movie.douban.com'
- headers = {
- 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari/537.36'
- }
- session = requests.session()
- response = session.get(url,headers = headers)
- # response.encoding='utf-8'
- # response.encoding = response.apparent_encoding
- index_url = 'https://movie.douban.com'
- res = session.get(index_url,headers=headers)
- # print(res.text)
- # 输出:页面源代码
- tree = etree.HTML(res.text)
- # print(tree)
- # 输出:<Element html at 0x186fa6a3100>
- img_all = tree.xpath('//img')
- # print(img_all)
- for i in img_all:
- img = etree.tostring(i, encoding='UTF-8').decode('UTF-8')
- # 得到所有的img标签
- # print(img)
- # <img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2900931370.jpg" alt="小行星猎人" rel="nofollow" class=""/>
- img_url = tree.xpath('//img/@src')
- # img_name = tree.xpath('//img/@alt')
- # print(img_url,img_name)
- # 输出:许多个列表
- for i in img_url:
- # print(i)
- last_str = i.split('/')[-1]
- # print(last_str)
- # 输出:多个p2900931370.jpg p2901057189.jpg
- every_name = last_str.split('.')[0]
- # print(every_name)
- # 输出:多个p2900931370 p2901057189
- res_url = session.get(i,headers=headers)
- with open(f'./img/{every_name}.jpg','wb') as f:
- f.write(res_url.content)

运行结果:
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读


相关标签

