
- 1面试笔记:面经-顺丰科技_顺丰ui面试题
- 2transform:translateZ(0),will-change GPU加速原理 动画实现_transform:translatez(0)的作用
- 32020年9家互联网大厂职级和薪酬曝光!含阿里腾讯字节美团……_阿里和美团offer比较
- 42023最新阿里、腾讯、华为、字节等大厂的薪资和职级对比_华为薪酬等级表2023
- 5十分钟使用VUE和Flask快速搭建前后端分离项目_vue flask
- 6STM32CUBEMX_基于PWM的呼吸灯_stm32mxcube 呼吸灯
- 7蓝桥杯-第九届蓝桥杯C语言A组/B组/C组-Python题解_蓝桥杯c组python
- 8【Python小程序】红红火火过大年,(代码)巧手编织中国结,分分钟那惊艳你哦~_弘扬中华优秀传统文化编程
- 9基于Vue-element-admin实现动态路由 二(后端配置动态路由)_动态路由 后端需要给什么
- 10【Python】多线程并发使两个程序同时运行_python多线程并发执行
R语言机器学习篇——随机森林_r语言的机器学习代码
赞
踩
参考书籍:陈强.机器学习及R应用.北京:高等教育出版社,2020
随机森林属于集成学习的方法,也称为组台学习,本章介绍随机森林与它的特例方法,装袋法,并分别以例子的形式讨论回归问题与分类问题的随机森林方法。
一 回归问题的随机森林
对于回归问题,调用MASS包数据框Boston作为数据集,分析波士顿房价的相关情况,选取70%左右的数据作为训练集,代码如下:
- library(MASS)
- dim(Boston)
- set.seed(1)
- train <- sample(506,354) #随机选取70%数据
1.装袋法估计
使用R中的随机森林包进行装袋法估计,注意参数中的“mtry=13”表示在该例中使用全部的特征变量,“importance=TRUE”计算变量重要性。最后代码及输出结果如下
- library(randomForest)
- set.seed(123)
- bag.fit <- randomForest(medv~.,data=Boston,subset=train,mtry=13,importance=TRUE,replace=T)
- bag.fit
- #Call:
- randomForest(formula = medv ~ ., data = Boston, mtry = 13, importance = TRUE, replace = T, subset = train)
- Type of random forest: regression
- Number of trees: 500
- No. of variables tried at each split: 13
-
- Mean of squared residuals: 11.94245
- % Var explained: 86.9
结果显示’函数random forest()默认估计500棵决策树(B=500),在每个节点均使用全部的13个变量,根据袋外观测值计算的OOB均方误差为11.94245;而准R方为0.869,即模型可解释响应变量medv86.9%的方差,使用plot()画出袋外误差(OOB均方误差),结果如下:
plot(bag.fit,main="Bagging OOB Errors")
在该图中,横轴为决策树的数目(B),纵轴为袋外误差,由图可见,B>200时,误差就趋于平稳,这时继续增大B,也不会使之下降。
接下来展示变量重要性,如下所示:
- #变量重要性
- importance(bag.fit)
- # %IncMSE IncNodePurity
- crim 16.955901 1112.22516
- zn 2.071627 30.37986
- indus 7.677858 140.58943
- chas 0.339128 44.09888
- nox 16.099685 438.55880
- rm 68.838872 20374.08905
- age 15.675505 493.82123
- dis 20.897606 1413.37172
- rad 3.470134 90.80601
- tax 8.935524 193.32866
- ptratio 22.174601 414.80738
- black 10.508969 274.43954
- lstat 40.192884 6898.26149
- > varImpPlot(bag.fit,main="Variable Importance Plot") #画图
输出结果中的变量重要结果的第1列(IncMSE)表示汇报在模型中去掉某个变量后,使得袋外误差上升的百分比(如去掉变量age,袋外误差上升15.68%);第2列(IncNodePurity)汇报基于训练样本计算的变量重要性。这里需要注意对于回归问题,NodePurity就是残差平方和;对于分类问题,则是基尼系数。

从图中可以看出,对于响应变量medv(社区房价中位数)影响最大的两个变量都是rm(房间数)和lstat(低端人口比重),若是想看某个变量的偏依赖图,可用以下的代码实现,以变量rm为例,结果如下所示:
- #变量偏依赖图
- partialPlot(bag.fit,Boston[train,],x.var=rm)
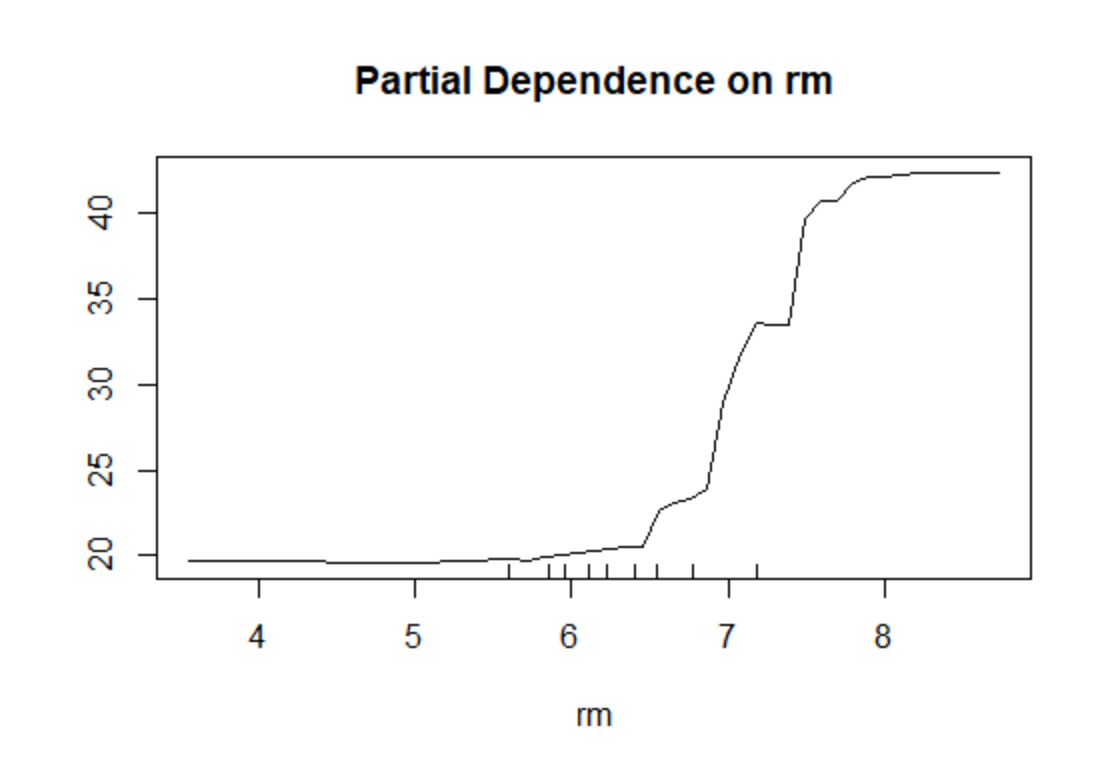
从上图可以看出,变量rm对房价medv的影响为正向,但并非完全线性。特别在rm较小或较大的尾部区域,变量rm对于房价medv的影响很微弱(函数几乎变为水平线)。另外,横轴上的地毯图(mgplot)标出变量rm的十分位数(即l/10,2/I0,…,9/10分位数)。这些分位数表明在rm的尾部区域观测值较少,因此尾部结果并非可信。
下面对测试集进行预测,并画出预测值与实际值之间的散点图,计算出MSE,如下:
- bag.pred <- predict(bag.fit,newdata=Boston[-train,]) #得出测试集的预测值
- y.test <- Boston[-train,"medv"] #测试集的真实值
- plot(bag.pred,y.test,main="Bagging Prediciton")
- abline(0,1)
- mean((bag.pred-y.test)^2) #均方误差
- #[1] 22.96509

接下来运用OLS方法,与随机森林方法对比,判断预测效果的优劣。
- ols.fit <- lm(medv~.,Boston,subset=train)
- ols.pred <- predict(ols.fit,newdata=Boston[-train,])
- mean((ols.pred-y.test)^2)
- #[1] 27.31196
结果显示OLS测试集MSE为27.31,高于装袋法,这表明,对于波士顿房价数据尽管单颗回归树预测效果不及OLS,但集成学习的效果则优于OLS。
可以尝试不同的参数进行装袋法估计,例如以下的例子
- bag.fit <- randomForest(medv~.,data=Boston,subset=train,mtry=13,ntree=1000,
- nodesize=10)
其中参数“ntree=1000”表示种1000棵树(默认值为500);参数nodesize=10,表示将终节点的最小规模设为10个观测值(默认值为5)。
2.随机森林估计
下面估计随机森林模型,如下所示
- set.seed(123)
- forest.fit <- randomForest(medv~.,data=Boston,subset=train)
- forest.fit
- #Call:
- randomForest(formula = medv ~ ., data = Boston, subset = train)
- Type of random forest: regression
- Number of trees: 500
- No. of variables tried at each split: 4
-
- Mean of squared residuals: 10.33118
- % Var explained: 88.67
-
- forest.pred <- predict(forest.fit,newdata=Boston[-train,])
- mean((forest.pred-y.test)^2)
- #[1] 14.65405
对于回归问题,函数randomForest()默认“mtry=p/3“,故在此使用“mtry=4”进行估计(p=13)。计算随机森林的测试误差,为14.65,比装袋法有较大提升。
下面考察随机森林测试误差与决策树数目(B)的关系,以B=100为例,展示如下
- MSE.forest <- numeric(100) # 创建100个空值数字
- set.seed(123)
- for(i in 1:100){
- fit <- randomForest(medv~.,data=Boston,subset=train,ntree=i)
- pred <- predict(fit,newdata=Boston[-train,])
- y.test <- Boston[-train,"medv"]
- MSE.forest[i] <- mean((pred-y.test)^2)
- } #查看决策树数目从1到100,测试误差的数值变化
下面再查看装袋法测试误差与决策树数目的关系:
- MSE.bag <- numeric(100)
- set.seed(123)
- for(i in 1:100){
- fit <- randomForest(medv~.,data=Boston,subset=train,ntree=i,mtry=13) #这里与随机森林不同
- pred <- predict(fit,newdata=Boston[-train,])
- y.test <- Boston[-train,"medv"]
- MSE.bag[i] <- mean((pred-y.test)^2)
- }
作为对比,计算单颗决策树的测试误差:
- library(rpart)
- set.seed(123)
- tree.fit <- rpart(medv~.,Boston,subset=train)
- min_cp <- tree.fit$cptable[which.min(tree.fit$cptable[,"xerror"]),"CP"]
- tree.prune <- prune(tree.fit, cp = min_cp)
- tree.pred <- predict(tree.prune,newdata=Boston[-train,])
- mse <- mean((tree.pred-y.test)^2)
- MSE.tree <- rep(mse,100)
最后,通过画图的形式,展示随机森林、单棵决策树、装袋法的测试误差变化,结果如下:
- plot(1:100,MSE.forest,type="l",col="blue",ylab="MSE",xlab="Number of Trees",
- main="Test Error",ylim=c(10,55))
- lines(1:100,MSE.bag,type="l")
- lines(1:100,MSE.tree,type="l",col="black",lty=2)
- legend("topright",lty=c(2,1,1),col=c("black","black","blue"),legend=c("Best Single Tree",
- "Bagging","Random Forest")) #图标,区分不同的线所代表的方法
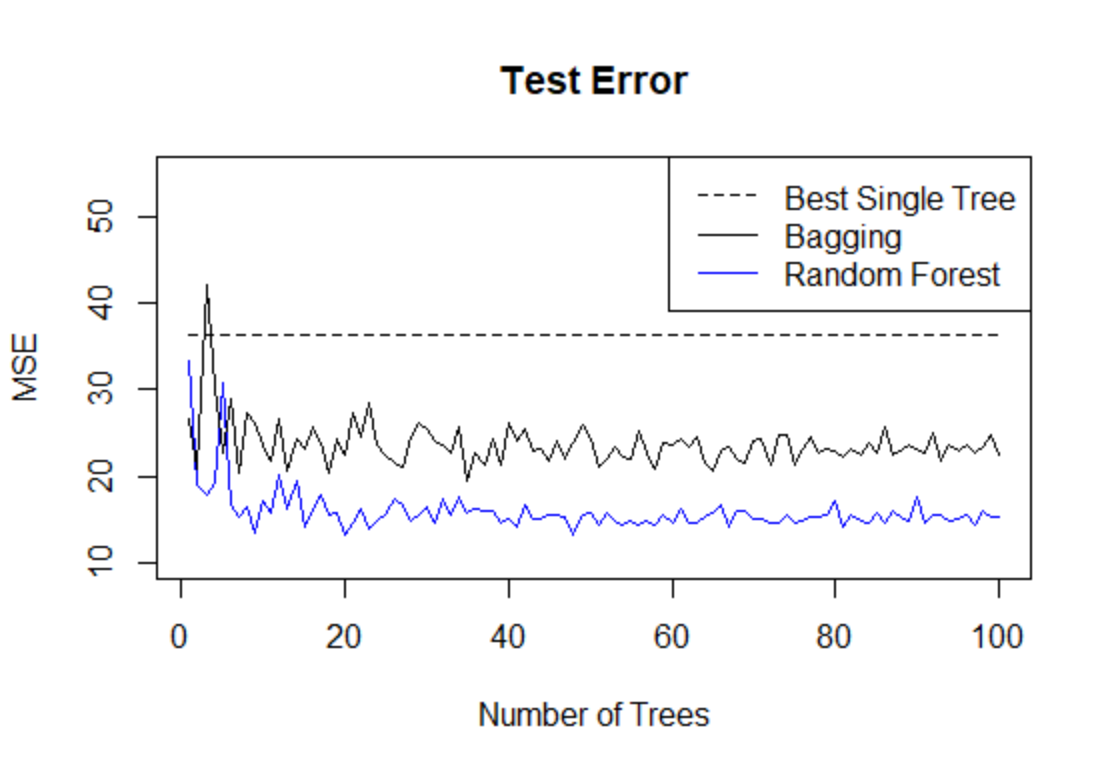
由图可见,装袋法的测试误差低于最优的单棵树,而随机森林的测试误差比装袋法还更低。随机森林的一个重要调节参数为mtry,即每次用于节点分裂的变量个数,这可以通过最小化袋外误差或交叉验证误差来确定,首先考虑最小化袋外误差:
可用R包random forest中的tuneRF()函数,达到上述的目的,该函数需要设定参数“step—Factor”表示随机选择变量个数的缩放倍数,并不考虑mtry的所有可能取值,下面通过计算寻找使袋外误差最小的mtry:
- MSE <- numeric(13) #mtry最多可以取到13因为有13个特征变量
- set.seed(123)
- for(i in 1:13){
- fit <- randomForest(medv~.,data=Boston,subset=train,mtry=i)
- MSE[i] <- mean(fit$mse[500])
- }
- MSE
- # [1] 19.557467 12.717293 10.658755 9.903552 10.026058 9.815894
- [7] 9.899590 10.344245 10.561024 10.875071 11.038252 11.606371
- [13] 11.963906
-
- min(MSE)
- which.min(MSE) #找到哪个mtry值使得MSE最小
- plot(1:13,MSE,type="b",xlab = "mtry",main="OOB Errors")
- abline(v=which.min(MSE),lty=2)
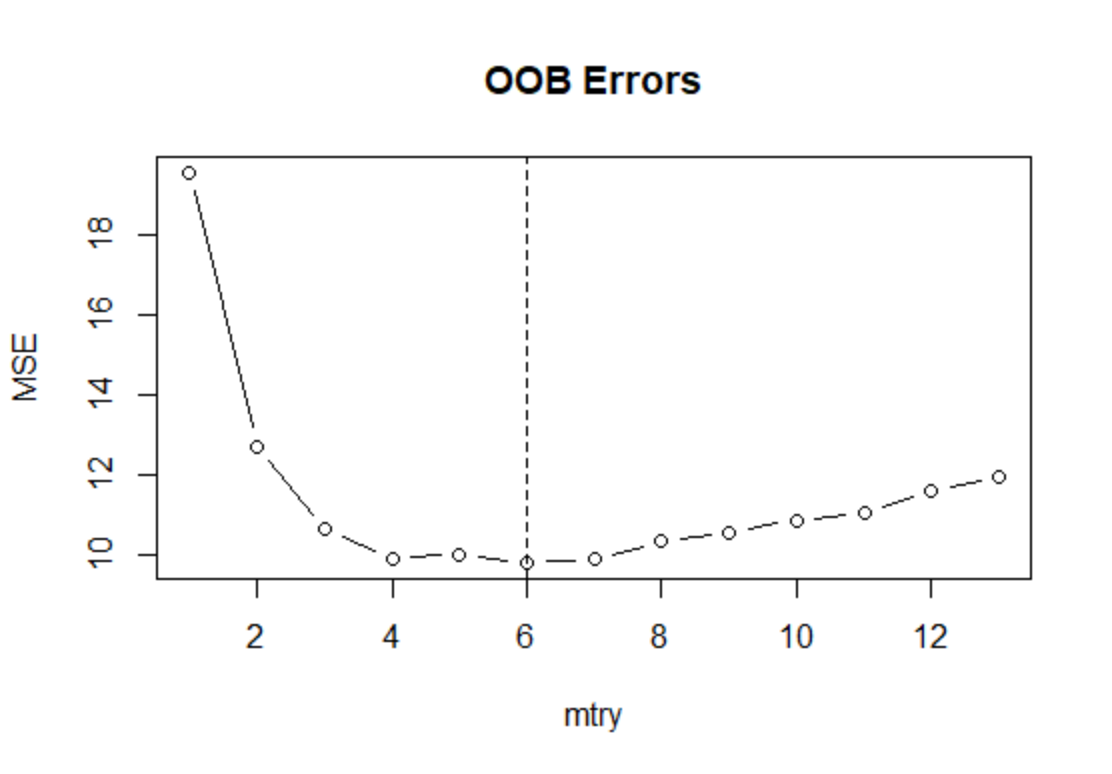
结果显示,当mtry=6时,袋外误差达到最小,仅为9.81589,不过mtry=4~7之间的结果差别不大。
下面使用另一种方式——交叉验证误差,来选择mtry的最优值,可使用rfcv()函数,但该函数同样不考虑所有mtry取值,因此还是通过计算找出。
首先将将训练数据随机分为大致相等的5折(训练数据为354个,10折的话就很小,会造成结果不够准确)
- Boston_train <- Boston[train,]
- set.seed(12345)
- foldid <- sample(1:5,size=354,replace=TRUE) # use the same folds
- head(foldid)
- #[1] 3 2 4 2 5 3
其中’训练集定义为Boston_train。通过从1:5中有放回地抽取354次,可得到训练集中每个观测值的分组归属。
其次,初始化MSE为一个13×5的矩阵,其中MSE(i,j)元素用于记录当mtry=i,而以第j折作为验证集的均方误差:
- MSE <- matrix(rep(0,65),ncol=5) # initialize CV error for mtry
- for (i in 1:13){
- for (j in 1:5){
- train_cv <- Boston_train[foldid!=j,]
- holdout <- Boston_train[foldid==j,]
- fit <- randomForest(medv~.,data=train_cv,mtry=i)
- pred <- predict(fit,newdata=holdout)
- y.test <- holdout[,"medv"]
- MSE[i,j] <- mean((pred-y.test)^2)
- }
- }
- cv.error <- apply(MSE,1,mean)
- min(cv.error)
- #[1] 16.21452
- which.min(cv.error)
- #[1] 8
其中,在外面的for循环,考察mtry=1:13的不同情形。给定mtry取值后,在里面的for循环,则依次以第j折作为验证集,计算相应的均方误差。最后,使用apply()函数计算矩阵MSE每行的平均值,即为对应于不同mtry取值的交叉验证误差。
结果显示’在mtry=8时,交叉验证误差达到最小值,但交叉验证误差的最小值明显高于袋外误差的最小值,由于在进行交叉验证时,每次仅使用训练集的4/5进行估计,故可能高估测试误差.更直观地,画交叉验证误差图,如下所示:
- plot(1:13,cv.error,type="b",xlab="mtry",main="Cross-Validation Error")
- abline(v=which.min(cv.error),lty=2)

最后,通过for循环,通过测试集误差来选择最优mtry:
- MSE <- numeric(13)
- set.seed(123)
- for(i in 1:13){
- fit <- randomForest(medv~.,data=Boston,subset=train,mtry=i)
- pred <- predict(fit,newdata=Boston[-train,])
- y.test <- Boston[-train,"medv"]
- MSE[i] <- mean((pred-y.test)^2)
- }
- min(MSE)
- #[1] 14.65984
- which.min(MSE)
- #[1] 4
- plot(1:13,MSE,type="b",xlab = "mtry",main="Test Error")
- abline(v=which.min(MSE),lty=2)
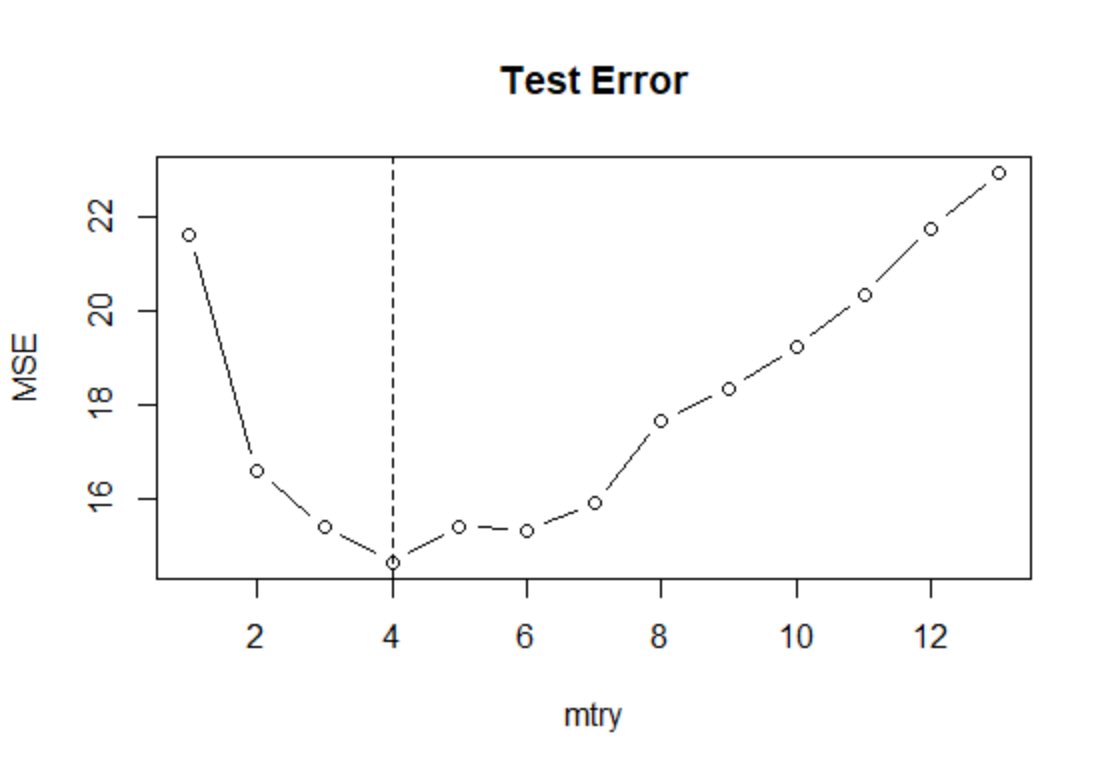
严格来说,如果使用测试集来选择调节参数,则无法再使用测试集估计测试误差,因为测
试集的信息已经通过选中的调节参数而提前“泄露”。
更为专业的做法为’将全样本一分为三,其中一部分作为训练集,—部分作为验证集,而另一部分作为测试集。其中,训练集用于训练数据,验证集用于选择调节参数,而测试集则仅用于测试。
这就是关于回归的随机森林方法,接下来讨论分类的随机森林。
二 分类问题的随机森林
在讨论分类问题时,使用R包mlbench的声呐数据Sonar来演示,它包含208个观测值与61个变量,其中响应变量为因子class,表示声呐的回音来自“金属筒”(M)还是“岩石”(R),特征变量共60个(V1~V60),表示不同角度与频道下声呐反射信号的能量。研究的目的在于区分声呐信号来自于金属还是岩石。
首先导入数据集,考察数据的基本特征,并选取训练集和测试集
- library(mlbench)
- data(Sonar)
- dim(Sonar) #考察数据的维度
- #[1] 208 61
- table(Sonar$Class) #考察响应变量的分布情况
- # M R
- 111 97
-
- set.seed(1)
- train <- sample(208,158) #随机选取70%数据作为训练集
其次估计决策树与逻辑回归算法,作为比较随机森林算法的基准
- #决策树
- library(rpart)
- set.seed(123)
- fit <- rpart(Class~.,data=Sonar,subset=train)
- min_cp <- fit$cptable[which.min(fit$cptable[,"xerror"]),"CP"]
- min_cp
- fit_best <- prune(fit, cp = min_cp)
- pred <- predict(fit_best,newdata=Sonar[-train,],type="class")
- y.test <- Sonar[-train,"Class"]
- (table <- table(pred,y.test)) #混淆矩阵
- # y.test
- pred M R
- M 24 15
- R 4 22
- (error_rate <- 1-sum(diag(table))/sum(table)) #错误率
- #[1] 0.2923077
通过单颗修枝后的决策树结果可得出,预测的错误率为28%,其次考虑逻辑回归的预测结果:
- #Logit
- fit <- glm(Class~.,data=Sonar,subset=train,family=binomial)
- prob <- predict(fit,newdata=Sonar[-train,],type="response")
- pred <- prob >= 0.5
- (table <- table(pred,y.test))
- # y.test
- pred M R
- FALSE 20 9
- TRUE 6 15
- (error_rate <- 1-sum(diag(table))/sum(table))
- #[1] 0.3
通过逻辑回归的结果可得出,预测的错误率为30%,下面进行随机森林的估计
- #随机森林
- fit <- randomForest(Class~.,data=Sonar,subset=train,importance=TRUE)
- fit
- #Call:
- randomForest(formula = Class ~ ., data = Sonar, importance = TRUE, subset = train)
- Type of random forest: classification
- Number of trees: 500
- No. of variables tried at each split: 7
-
- OOB estimate of error rate: 17.09%
- Confusion matrix:
- M R class.error
- M 78 7 0.08235294
- R 20 53 0.27397260
结果显示,函数randomForest()默认使用mtry=7个变量作为候选分裂变量,因为
 ,袋外误差为18.99%,但金属类的袋外误差为9.41%,而岩石类的袋外误差高达30.14%。使用plot()函数即可同时画这三个袋外误差:
,袋外误差为18.99%,但金属类的袋外误差为9.41%,而岩石类的袋外误差高达30.14%。使用plot()函数即可同时画这三个袋外误差:
- plot(fit,main="OOB Errors",col=c(4,1,1))
- legend("topright", colnames(fit$err.rate),lty=1:3,col=c(4,1,1))

在上图中,蓝色实线为整个样本的OOB误差,而另外两条虚线则分别为金属(M类)与岩石(R类)样例的袋外误差。下面查看变量重要性以及影响最大的V11变量的偏依赖图,如下所示
- varImpPlot(fit,main="Variable Importance Plot")
- partialPlot(fit,Sonar[train,],x.var=V11)

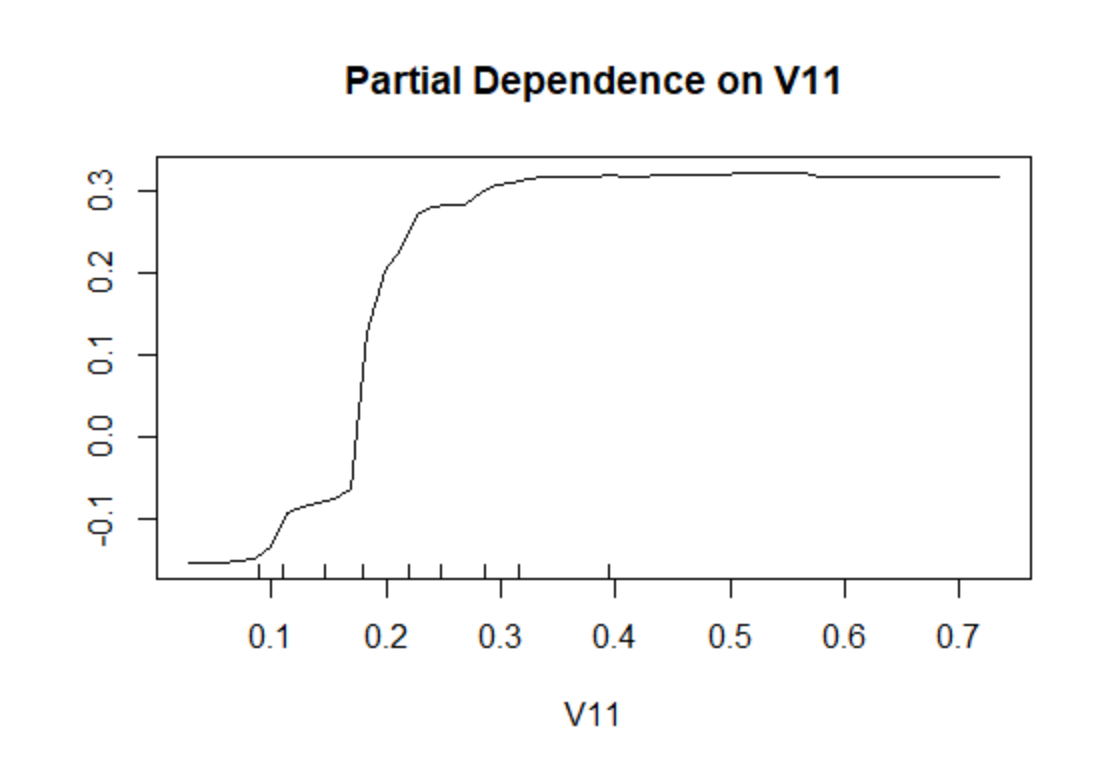
最后考察随机森林的预测效果,如下:
- pred <- predict(fit,newdata=Sonar[-train,])
- (table <- table(pred, y.test))
- # y.test
- pred M R
- M 25 7
- R 1 17
- (error_rate <- 1-sum(diag(table))/sum(table))
- #[1] 0.16
结果显示,随机森林的预测错误率为14%,仅是单棵决策树测错误率的一半,因此随机森林算法在此例的预测效果要优于另外两种方法。

