
- 1在Windows11系统中安装pyCharm Community_win11 pycharm安装
- 2【转载】——KVM_cirros-0.3.4-x86_64-disk.img
- 3【Codeforces】1120 Round #543 Div. 1 B-F简要题解_e. the very same munchhausen
- 4Bat shell 脚本相关查询记录
- 5js字符串转函数_js 字符串转函数
- 6Vue3 第三十二篇:常用组件:Tab栏_vue3 tab
- 7Python调用外部程序的9种方式,你都知道吗?_python启动其他程序
- 8开源轻量堡垒机——Teleport的安装配置和使用_teleport radmin
- 9Kafka系列之:Unexpected handshake request with client mechanism PLAIN, enabled mechanisms are []
- 10编写一个完整的程序,运行时向用户提问“试考了多少分?(0~100)”输入后判断其等级显示出来。_运行时向用户提问你考试考了多少分
D*(Dynamic A*)路径规划算法_d*算法
赞
踩
0 概览
- 闲来无事,重新推导一下经典的 D ∗ D* D∗ 算法
- D ∗ D* D∗ 算法也就是 D y n a m i c Dynamic Dynamic A ∗ A* A∗ 算法
1 D ∗ D* D∗
- D ∗ D* D∗ 算法是 D y n a m i c Dynamic Dynamic A ∗ A* A∗ 的简称,是一种适应于动态环境的启发式的路径搜索算法
- 同 A ∗ A* A∗ 算法类似, D ∗ D* D∗ 通过一个维护一个优先队列 O p e n L i s t OpenList OpenList 来对场景中的路径节点进行搜索。不同的是, D ∗ D* D∗ 从目标点开始搜索,通过将目标点置于 O p e n L i s t OpenList OpenList 中来开始搜索,直到机器人当前位置节点从 O p e n L i s t OpenList OpenList 出队为止
- D ∗ D* D∗ 分为两个阶段:第一阶段基于 D i j k s t r a / A ∗ Dijkstra/A* Dijkstra/A∗ 算法从目标点往起点进行搜索,得到搜索区域节点距离目标点最短路径的信息;第二阶段是动态避障搜索阶段(动态避障的时候,就可以充分利用在第一阶段当中所保存的信息,极大提高搜索效率)
- 因此 D ∗ D* D∗ 算法主要分为两个部分,第一部分是 P r o c e s s Process Process S t a t e State State,主要用于处理节点信息;第二部分是 M o d i f y Modify Modify C o s t Cost Cost,主要用于修正若干个受障碍物影响而导致代价值发生变化的那些节点信息
1.1 P r o c e s s Process Process S t a t e State State
- 主要用于处理节点信息
- 第一阶段,环境障碍物已知,都是静态的

1.2 M o d i f y Modify Modify C o s t Cost Cost
- 要用于修正若干个受障碍物影响而导致代价值发生变化的那些节点信息
- 第二阶段,动态避障,就需要充分利用第一阶段中所保存的信息

1.3 注意事项
- 算法将每一个节点的标识分为三类:
- 还未被遍历到的节点为 n e w new new
- 己经在 O p e n L i s t OpenList OpenList 的为 o p e n open open
- 曾经在 O p e n L i s t OpenList OpenList 但现在己经被移出的为 c l o s e d closed closed
- 每个节点到目标点 G G G 的代价为 h h h(这里参考了 A ∗ A* A∗ 算法的符号命名,并且 D ∗ D* D∗ 算法是从目标点到起始点方向进行搜索的;而在 A ∗ A* A∗ 算法里面,这是从起始点到目标点进行搜索的, h h h 在 A ∗ A* A∗ 当中是代表当前节点到目标节点的一个估计代价;而 h h h 在 D ∗ D* D∗ 当中是当前节点到目标节点的一个实际代价,如下图所示),两个节点 X X X 与 Y Y Y 之间的代价为 C ( X , Y ) C(X,Y) C(X,Y)
- T i p s Tips Tips
- 一般横向竖向移动是 1 1 1
- 然后对角线代价一般是 1.4 1.4 1.4
- 这样就行
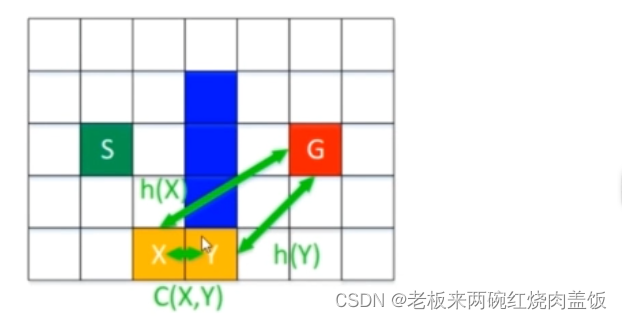
- X X X 到终点的代价 h ( X ) h(X) h(X):为 X X X 的父节点 Y Y Y 到终点的代价 h ( Y ) h(Y) h(Y) 加上 X X X 和 Y Y Y 之间的代价,即: h ( X ) = h ( Y ) + C ( X , Y ) h(X)=h(Y)+C(X,Y) h(X)=h(Y)+C(X,Y)
- 节点 X X X 在不断遍历过程中,与目标点的代价会增大或减小(在不断遍历的过程当中, h h h 会随着其父节点的变化而变化,如果 Y Y Y 上面的那个点由障碍物变成了自由空间,假如这个点是 Z Z Z 点,那么代价就该变为 h ( X ) = h ( Z ) + C ( X , Z ) h(X) = h(Z) + C(X,Z) h(X)=h(Z)+C(X,Z),并且这个 h ( X ) = h ( Z ) + C ( X , Z ) h(X) = h(Z) + C(X,Z) h(X)=h(Z)+C(X,Z) 是要小于 h ( X ) = h ( Y ) + C ( X , Y ) h(X)=h(Y)+C(X,Y) h(X)=h(Y)+C(X,Y) 的,所以这个 h h h 值就会减小,如下图所示)
- 假如这个点是 Z Z Z 点,那么代价就该变为 h ( X ) = h ( Z ) + C ( X , Z ) h(X) = h(Z) + C(X,Z) h(X)=h(Z)+C(X,Z),并且这个 h ( X ) = h ( Z ) + C ( X , Z ) h(X) = h(Z) + C(X,Z) h(X)=h(Z)+C(X,Z) 是要小于 h ( X ) = h ( Y ) + C ( X , Y ) h(X)=h(Y)+C(X,Y) h(X)=h(Y)+C(X,Y) 的,所以这个 h h h 值就会减小
- 同理,假如当某一个点变成障碍物的时候,那么 h h h 值可能就会增大
- 在增大或减小的这个过程当中,这个
k
k
k 就是始终保持变化的
h
h
h 的最小值,
k = min(k, h);

-
设 k k k 始终保持变化的 h h h 的最小值。也就是说,对于标识为 n e w new new 的点,表明还未遍历到, k = h = i n f ( ∞ ) k=h=inf(∞) k=h=inf(∞)
-
对于标识为 o p e n open open 或 c l o s e d closed closed 的点, k = m i n { k , h n e w } k=min\{k,h_{new}\} k=min{k,hnew}
-
这样就保证了 o p e n open open 或 c l o s e d closed closed 的点代价最小
-
节点 X X X 根据 k k k 与 h h h 的大小还有两种状态:若 h = k h=k h=k,记为 L o w e r Lower Lower 态;若 h > k h>k h>k,记为 R a i s e Raise Raise 态,表明有更优的路径(因为此时有 k k k 更小的值,肯定有最优路径)
-
由于 A ∗ A* A∗ 和 D ∗ D* D∗ 的路径搜索方向相反,为避免混淆不同算法所定义的父节点、子节点概念,统一将离搜索起点更近的节点作为父节点
-
注意这里是搜索起点, D ∗ D* D∗ 与 A ∗ A* A∗ 反着来的,所以 D ∗ D* D∗ 的搜索起点是目标点,而 A ∗ A* A∗ 的搜索起点是 真正的那个起点
-
在 A ∗ A* A∗ 算法里面,是把离起点更近的点称为父节点,离目标点近的就是子节点
-
在 D ∗ D* D∗ 算法里面,因为搜索路径相反,所以离起点最近的点称为子节点,离目标点近的就是父节点
- G G G 是搜索起点
- 比如这里 Y Y Y 是 X X X 的父节点,因为 Y Y Y 离 G G G 更近
- 然后
X
X
X 就是
Y
Y
Y 的子节点了
1.4 Code详解
1.4.1 P r o c e s s Process Process S t a t e State State 详解
1.4.1.1 步骤1
步骤1. 在 O p e n L i s t OpenList OpenList 中找到 k k k 值最小的那个节点 X X X 及对应的 k o l d k_{old} kold 值,并从 O p e n L i s t OpenList OpenList 当中移除
X = MIN_STATE();
if X = NULL then return -1;
k_old = GET_K_MIN();
DELETE(X);
- 1
- 2
- 3
- 4
- 记住,之前设了 k k k 是始终保持变化的 h h h 的最小值
1.4.1.2 步骤2
步骤2. 判断 k o l d k_{old} kold 是否小于 h ( X ) h(X) h(X),若确实小于的话,表明节点 X X X 已经受到障碍的影响(之前说过了,假如当某一个点变成障碍物的时候,那么 h h h 值可能就会增大),那么就遍历 X X X 的邻节点看是否能够以某个邻节点作为父节点,使 N o d e s ( ) . h Nodes().h Nodes().h 变小(如果变小了,那么就变成了 L o w e r Lower Lower 态,这个前面也说过,若 h = k h=k h=k,记为 L o w e r Lower Lower 态;若 h > k h>k h>k,记为 R a i s e Raise Raise 态,表明有更优的路径(因为此时有 k k k 更小的值,肯定有最优路径))。执行上述步骤只表明 h ( X ) h(X) h(X) 可以减小,但更新之后的 h ( X ) h(X) h(X) 与 k o l d k_{old} kold 相比,谁大谁小还尚未可知,需要继续判断,所以这一步是用来判断 X X X 的父节点的
if k_old < h(X) then
for each neighbor Y of X:
if h(Y) <= k_old and h(X) > h(Y) + c(Y, X) then
//上面这条语句就是说,h(X)也就是X直接到G的代价,是要比G到Y,再加上Y到X的代价要大的,如下图解释
b(X) = Y;//找到代价更小的,就Y成为父节点
h(X) = h(Y) + c(Y, X);//然后置换之前的代价
- 1
- 2
- 3
- 4
- 5
- 6
- 上面代码解释
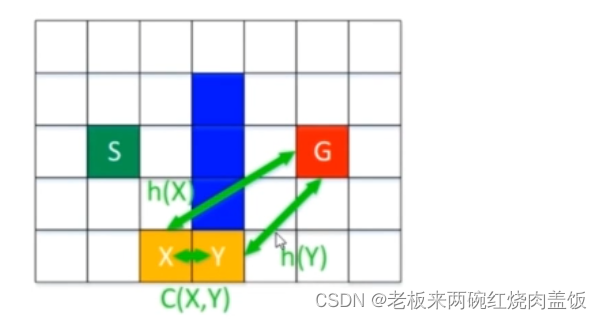
- 就表示以 Y Y Y 作为父节点这条路,由于直接从 X X X 直接到 G G G 这条路的
- 所以现在就可以更新,
b(X) = Y;,就是 Y Y Y 变成 X X X 的父节点 - 再去更新 h ( X ) h(X) h(X) 值
- 执行上述步骤只表明 h ( X ) h(X) h(X) 可以减小,但是不一定能减小到刚好等于 k o l d k_{old} kold ,且更新后的 h ( X ) h(X) h(X) 与 k o l d k_{old} kold 相比,谁大谁小还尚未可知,因为 k o l d k_{old} kold 是之前存储的,所以需要继续判断,看下面的步骤3与步骤4,来综合判断
1.4.1.3 步骤3
- 步骤3的前提条件是
if k_old = h(X),如果不能减小到 k o l d k_{old} kold,就看步骤4
步骤3. 因为不知道更新后的 k o l d k_{old} kold 与 h ( X ) h(X) h(X) 谁大谁小,所以需要继续判断,若 k o l d = h ( X ) k_{old} = h(X) kold=h(X), L o w e r Lower Lower 态,此时 X X X 无需判断,但需判断邻节点 Y Y Y 是否有必要以 X X X 作为父节点,也就是如下图
if k_old = h(X) then
for each neighbor Y of X:
if t(Y) = NEW or
(b(Y) = X and h(Y) 不等于 h(X) + c(X, Y)) or
(b(Y) = X;
INSERT(Y, h(X) + c(X, Y))
- 1
- 2
- 3
- 4
- 5
- 6
- 如图, h ( Y ) h(Y) h(Y) 这条路径已经是最优了,现在搜索 X X X 的邻节点,是否能以 X X X 作为其父节点
- 注意,图这里的与上述所说的 Y Y Y 重了,注意不要混淆
- 具体看这
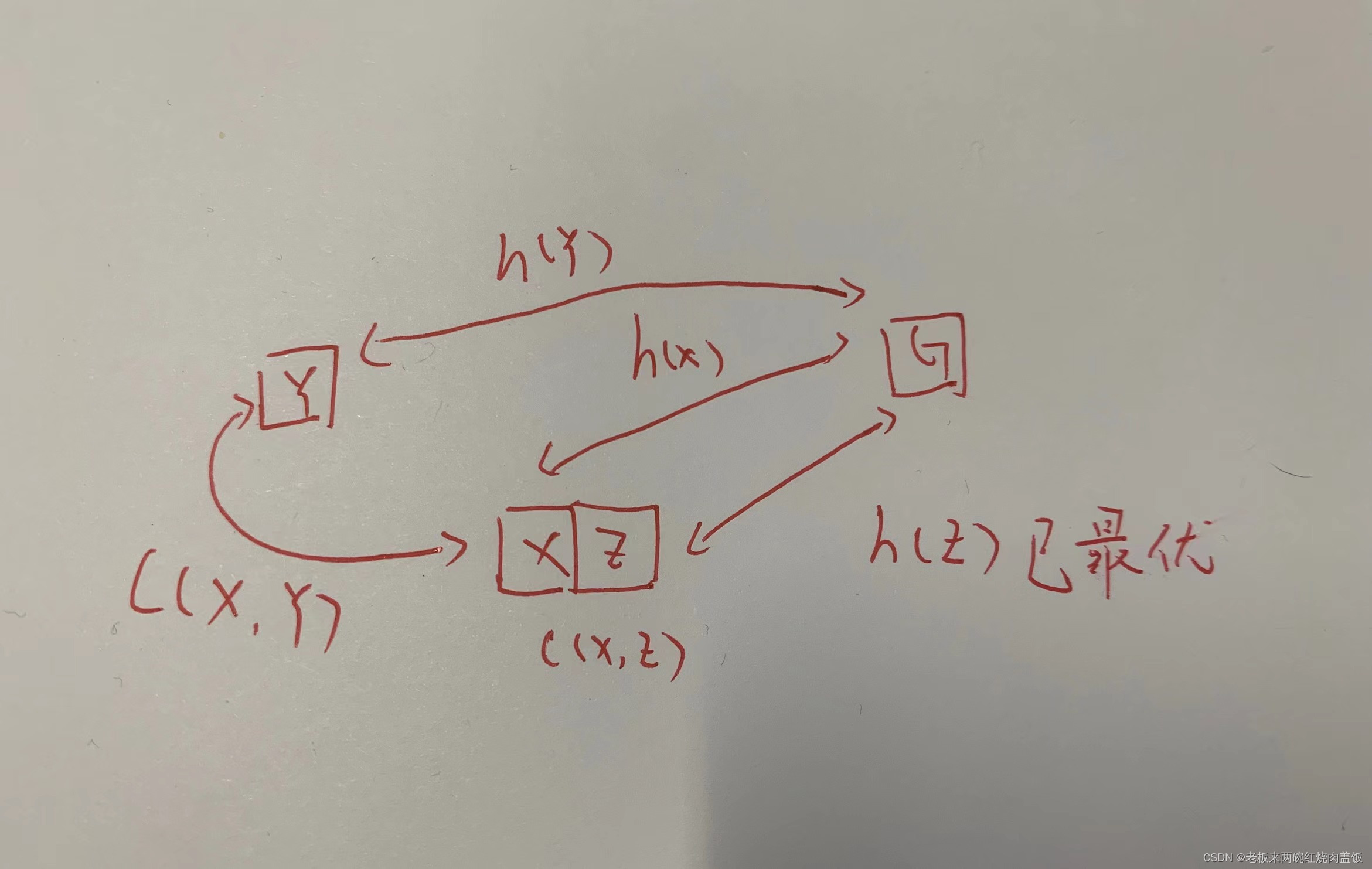
- 以下情况都参考上图
- 若情况1
t(Y) = NEW,表明邻节点 Y Y Y 还未纳入 O p e n L i s t OpenList OpenList,那么就以 X X X 作为父节点; - 若情况2
b(Y) = X and h(Y) 不等于 h(X) + c(X, Y),表明虽然 Y Y Y 的父节点是 X X X,但是 h ( Y ) h(Y) h(Y) 却与 h ( X ) + C ( X , Y ) h(X) + C(X, Y) h(X)+C(X,Y) 不相等了,表明 Y Y Y 的父节点 X X X 的 h ( X ) h(X) h(X) 有过更新,可能是由于障碍引起的; - 若情况3
b(Y) 不等于 X and h(Y) > h(X) + c(X, Y),表明现在 Y Y Y 的父节点不是 X X X,但是 Y Y Y 可以通过将 X X X 作为父节点,使得 h ( Y ) h(Y) h(Y) 更小; - 上述3种情况,都应该将 X X X 作为 Y Y Y 的父节点,并把 Y Y Y 移到 O p e n L i s t OpenList OpenList 后,再进一步考察
1.4.1.4 步骤4
- 前提条件
k_old 不等于 h(X)
步骤4. 若 k o l d k_{old} kold 不等于 h ( X ) h(X) h(X),则处于 R a i s e Raise Raise 态,说明节点 X X X 受到了影响,还未恢复为 L o w e r Lower Lower 态,遍历其邻域 Y Y Y
for each neighbor Y of X:
- 1
步骤4.1.
- 若情况1,表明邻节点 Y Y Y 还未纳入 O p e n L i s t OpenList OpenList;
- 若情况2,表明虽然 Y Y Y 的父节点是 X X X,但是 h ( Y ) h(Y) h(Y) 却不等于 h ( X ) + c ( X , Y ) h(X) + c(X, Y) h(X)+c(X,Y)。因此应该将 X X X 作为 Y Y Y 的父节点,更新 Y Y Y 的 h h h 值和 k k k 值
for each neighbor Y of X:
if t(Y) = NEW or
(b(Y) = X and h(Y) 不等于 h(X) + c(X, Y)) then
(b(Y) = X;
INSERT(y, h(X) + c(X, Y))
- 1
- 2
- 3
- 4
- 5
步骤4.2.
- 步骤4.2.1. 若满足,表明
Y
Y
Y 可以通过将
X
X
X 作为父节点,使
h
(
Y
)
h(Y)
h(Y) 更小。但是
X
X
X 自身还是
R
a
i
s
e
Raise
Raise 态,故要先将
X
X
X 追加到
O
p
e
n
L
i
s
t
OpenList
OpenList,待下一次循环满足条件就将
X
X
X 作为
Y
Y
Y 的父节点
- 可以看出,以下的代码与步骤3的差不多,但是为什么判断条件过后,执行语句不太一样呢?
- 因为在步骤3当中, X X X 是 L o w e r Lower Lower 态,所以那时候可以直接把 X X X 作为 Y Y Y 的父节点插入进去
- 但是现在步骤4当中, X X X 还是 R a i s e Raise Raise 态,所以需要先把 X X X 追加到 O p e n L i s t OpenList OpenList 当中,使得 X X X 变为 L o w e r Lower Lower 态,再循环一次,满足所有条件之后,就可以把 X X X 作为 Y Y Y 的父节点了,否则 X X X 自己都没摆平,还去摆平子节点?
//接上面的if
else
if b(Y) 不等于 X and h(Y) > h(X) + c(X, Y) then
INSERT(X, h(X))
- 1
- 2
- 3
- 4
- 步骤4.2.2. 如果上方的4.2.1还没摆平,那么就执行4.2.2, Y Y Y 的父节点不是 X X X;让 Y Y Y 成为 X X X 父节点, h ( X ) h(X) h(X) 更小; Y Y Y 已经从 O p e n L i s t OpenList OpenList 移除;当前从 O p e n L i s t OpenList OpenList 取出的最小值 k o l d k_{old} kold 居然比 h ( Y ) h(Y) h(Y) 小(因为 D ∗ D* D∗ 应该是与 D i j k s t r a Dijkstra Dijkstra 算法相类似的,正常的来说 k o l d k_{old} kold 应该是要比 h ( Y ) h(Y) h(Y) 大的)。上述四个与条件,表明己经被 O p e n L i s t OpenList OpenList 移出的 Y Y Y 受到了障碍影响导致 h h h 值升高,故要重新将 Y Y Y 置于 O p e n L i s t OpenList OpenList 中,进行下一轮考察
else
if b(Y) 不等于 X and h(Y) > h(X) + c(X, Y) and
t(Y) = CLOSED and h(Y) > k_old then
INSERT(Y, h(Y))
- 1
- 2
- 3
- 4
1.4.1.5 步骤5
- 返回 k o l d k_{old} kold 及被修改的 O p e n L i s t OpenList OpenList 信息
1.5 流程图
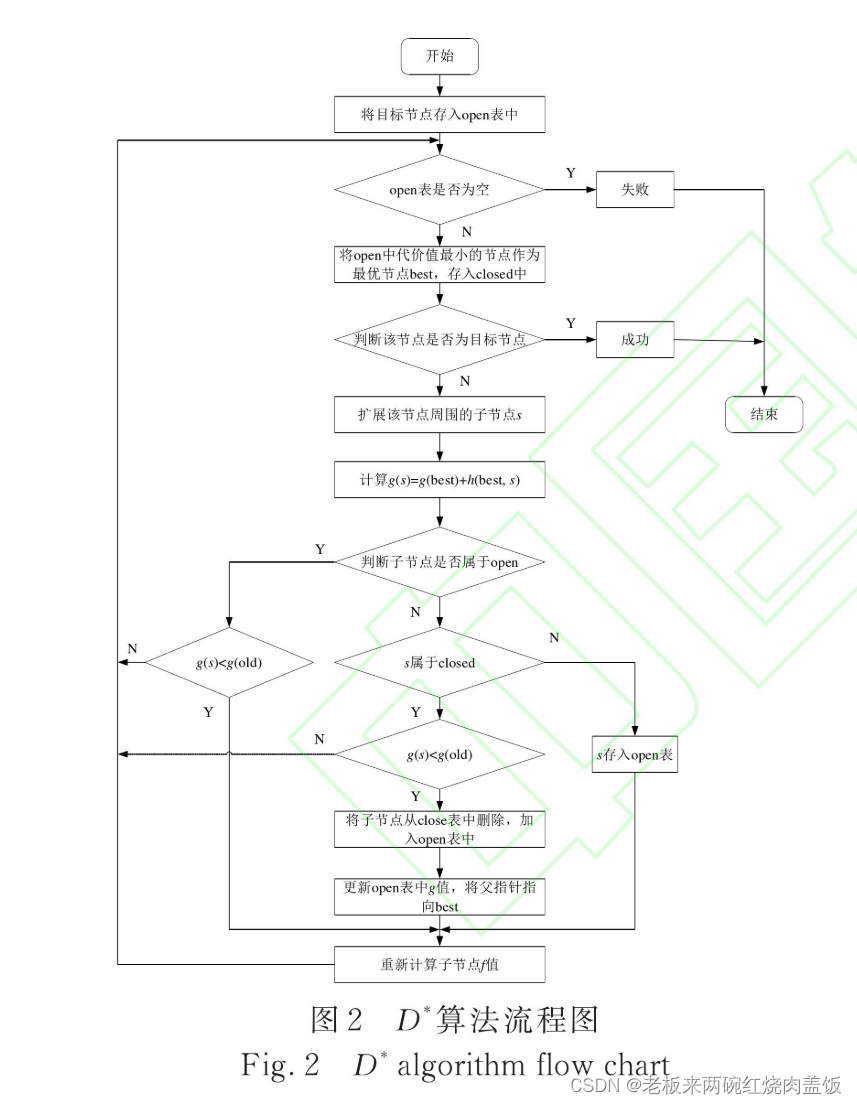
2 总结
以上就是 D ∗ D* D∗ 算法最核心的几个步骤,可以看出算法是相当复杂,怪不得后面出现了这么多改进的 D ∗ D* D∗ 算法

