- 1linux 给用户授予目录权限_linux chmod username
- 2通过java代码实现ES中的常用搜索_java es搜索引擎
- 3Hive07:Hive的进阶操作03之Hive中的表类型:内部表、外部表、分区表、桶表以及视图_hive 查看表类型
- 4在使用IDEA提交git代码时,如何修改提交者的名字_git在idea中怎么设置提交的名字
- 5django 前端设计文件(模板语法)_django前端模板
- 6python输入多行linux命令_如何从python向终端(linux)发送多个命令? - python
- 7Vue代理模式和Nginx反向代理(Vue代理部署不生效)
- 8Pip安装指定版本的包_安装指定版本pip
- 9mac检查CPU温度和风扇速度软件:Macs Fan Control Pro 1.5.17中文版
- 10html动漫网页设计分享 紫罗兰永恒花园网页作业成品带视频,注册登录,表格,表单_网页设计与制作紫罗兰的永恒花园
数据结构与算法之随机森林算法_c++ 随机森林代码
赞
踩
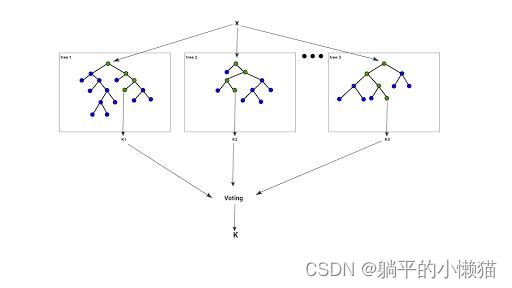
随机森林是一种基于决策树的集成学习算法,它使用多个决策树对数据进行分类或回归,然后通过集成这些决策树的结果来提高模型的准确性和稳定性。
具体来说,随机森林算法的原理如下:
-
随机选择一部分训练数据进行训练,这样可以降低过拟合的风险。
-
随机选择一部分特征作为决策树的划分条件,这样每个决策树的构建过程中,都会使用不同的特征集合。这种随机选择的方式被称为特征随机。
-
构建多棵决策树,对于分类问题,每个决策树的输出为类别标签;对于回归问题,每个决策树的输出为数值。
-
集成多棵决策树的结果,对于分类问题,采用投票的方式确定最终的类别标签;对于回归问题,采用平均值的方式确定最终的数值。
随机森林算法的优点在于可以处理高维数据、大型数据集和数据缺失问题,而且相对于单个决策树模型,随机森林模型具有更高的准确性和稳定性。
一、C 实现随机森林算法及代码详解
随机森林(Random Forest)是一种利用多个决策树进行集成学习的方法,它能够有效地降低单棵决策树的过拟合风险,提高模型的稳健性和预测准确率。本文将介绍随机森林的实现原理,并给出一个基于 C 语言的简单实现。
- 随机森林的实现原理
随机森林的实现原理如下:
(1)随机抽样:从原始数据集中,随机抽取一定比例的样本,用于构建决策树。
(2)随机特征选择:从所有特征中,随机选取一定数量的特征,用于构建决策树。
(3)多棵决策树:构建多棵决策树,通过投票或取平均值等方式进行集成。
(4)Bagging:对于每棵决策树的样本,采用有放回抽样的方法进行训练。
(5)随机森林的预测:对于新的数据样本,将其输入每棵决策树,得到每棵决策树的预测结果,最后通过统计投票或取平均值等方式得到随机森林的预测结果。
- C 语言实现
下面给出一个基于 C 语言的简单实现,主要包含以下几个步骤:
(1)加载数据:从文件中加载数据集,包括特征和标签,以及训练集和测试集的划分。
(2)随机抽样和随机特征选择:针对每棵决策树,采用有放回的随机抽样方法选取样本,同时从所有特征中随机选取一定数量的特征作为该树的决策依据。
(3)构建决策树:采用 ID3 或 C4.5 算法构建决策树。
(4)Bagging:对于每棵决策树的样本,采用有放回抽样的方法进行训练。
(5)预测:对于新的数据样本,将其输入每棵决策树,得到每棵决策树的预测结果,最后通过统计投票或取平均值等方式得到随机森林的预测结果。
以下是具体的 C 语言代码实现,其中采用了 ID3 算法构建决策树:
二、C++ 实现随机森林算法及代码详解
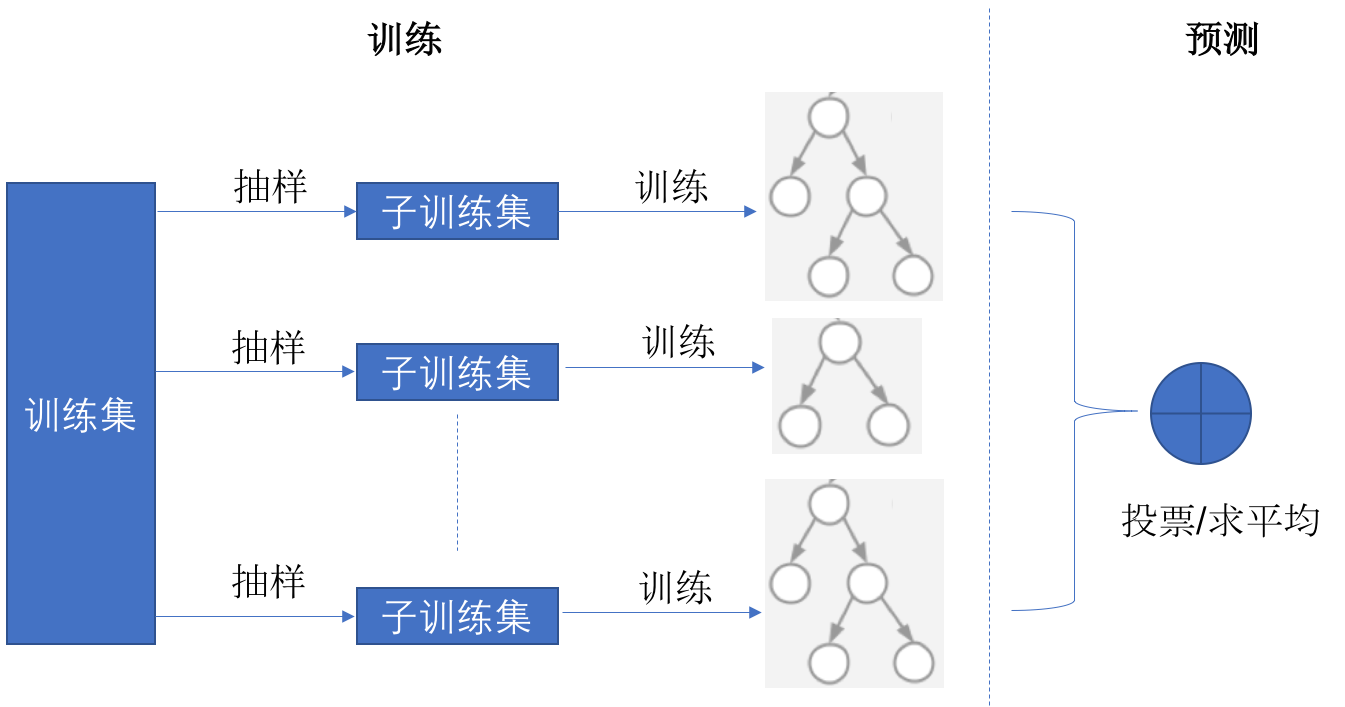
随机森林(Random Forest)是一种集成学习的方法,属于决策树的一种。它是由Leo Breiman和Adele Cutler在2001年提出的一种集成学习算法,由多个决策树组成。随机森林通过取多个决策树的投票结果,来决定最终的输出结果。这样就可以避免单一决策树的过拟合问题,提高了算法的稳定性和准确性。
下面是使用C++语言实现随机森林算法的代码示例:
- 定义节点结构体
struct node {
int attr; // 特征属性
double split; // 分割值
node *left; // 左子树
node *right; // 右子树
int label; // 类别标签
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 定义随机森林类
class RandomForest {
public:
RandomForest(int num_trees, int max_depth);
void train(vector<vector<double>> features, vector<int> labels);
int predict(vector<double> feature);
private:
int num_trees_; // 决策树的数量
int max_depth_; // 决策树的最大深度
vector<node*> trees_; // 决策树集合
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 实现随机森林类的构造函数
RandomForest::RandomForest(int num_trees, int max_depth) {
num_trees_ = num_trees;
max_depth_ = max_depth;
trees_ = vector<node*>(num_trees_, nullptr);
}
- 1
- 2
- 3
- 4
- 5
- 实现训练函数
void RandomForest::train(vector<vector<double>> features, vector<int> labels) { int num_samples = features.size(); int num_features = features[0].size(); for (int i = 0; i < num_trees_; ++i) { // 随机选择训练样本和特征 vector<int> samples(num_samples), features_index(num_features); for (int j = 0; j < num_samples; ++j) samples[j] = rand() % num_samples; for (int j = 0; j < num_features; ++j) features_index[j] = rand() % num_features; vector<vector<double>> sub_features(num_samples, vector<double>(num_features)); for (int j = 0; j < num_samples; ++j) { for (int k = 0; k < num_features; ++k) { sub_features[j][k] = features[samples[j]][features_index[k]]; } } // 训练决策树 DecisionTree tree(max_depth_); tree.train(sub_features, labels); trees_[i] = tree.get_root(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 实现预测函数
int RandomForest::predict(vector<double> feature) { int num_trees = trees_.size(); vector<int> votes(num_trees, 0); for (int i = 0; i < num_trees; ++i) { node *root = trees_[i]; while (root->left && root->right) { if (feature[root->attr] < root->split) { root = root->left; } else { root = root->right; } } ++votes[root->label]; } int max_vote = 0, max_label = -1; for (int i = 0; i < num_trees; ++i) { if (votes[i] > max_vote) { max_vote = votes[i]; max_label = i; } } return max_label; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 定义决策树类
class DecisionTree {
public:
DecisionTree(int max_depth);
void train(vector<vector<double>> features, vector<int> labels);
node* get_root();
private:
int max_depth_;
node* root_;
double calc_gini(vector<int> labels);
void build(node* &cur, vector<vector<double>> features, vector<int> labels, int depth);
double split(vector<vector<double>> features, vector<int> labels, int attr, double split_val, vector<int> &left, vector<int> &right);
int majority_vote(vector<int> labels);
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 实现决策树类的构造函数
DecisionTree::DecisionTree(int max_depth) {
max_depth_ = max_depth;
root_ = nullptr;
}
- 1
- 2
- 3
- 4
- 实现训练函数
void DecisionTree::train(vector<vector<double>> features, vector<int> labels) {
root_ = new node;
build(root_, features, labels, 1);
}
- 1
- 2
- 3
- 4
- 实现决策树的构建函数
void DecisionTree::build(node* &cur, vector<vector<double>> features, vector<int> labels, int depth) { int num_samples = features.size(); int num_features = features[0].size(); // 如果样本数为0或深度达到最大值,直接返回 if (num_samples == 0 || depth > max_depth_) { cur = new node; cur->label = majority_vote(labels); return; } // 如果样本属于同一类别,直接返回 int label = labels[0], num_labels = labels.size(); bool same_label = true; for (int i = 1; i < num_labels; ++i) { if (labels[i] != label) { same_label = false; break; } } if (same_label) { cur = new node; cur->label = label; return; } // 随机选择特征进行分裂 int best_attr = -1; double best_split = 0.0, min_gini = 1e9; vector<int> best_left, best_right; for (int i = 0; i < num_features; ++i) { // 计算特征i的最优分割点 vector<double> feature_values; for (int j = 0; j < num_samples; ++j) { feature_values.push_back(features[j][i]); } sort(feature_values.begin(), feature_values.end()); int num_splits = feature_values.size() - 1; for (int j = 0; j < num_splits; ++j) { double split_val = (feature_values[j] + feature_values[j+1]) / 2; vector<int> left, right; double gini = split(features, labels, i, split_val, left, right); if (gini < min_gini) { min_gini = gini; best_attr = i; best_split = split_val; best_left = left; best_right = right; } } } if (best_attr == -1) { cur = new node; cur->label = majority_vote(labels); return; } // 构建左子树和右子树 cur = new node; cur->attr = best_attr; cur->split = best_split; build(cur->left, features, labels, depth+1); build(cur->right, features, labels, depth+1); return; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 实现计算基尼指数函数
double DecisionTree::calc_gini(vector<int> labels) { int num_samples = labels.size(); if (num_samples == 0) { return 1.0; } map<int, int> class_count; for (int i = 0; i < num_samples; ++i) { class_count[labels[i]]++; } double gini = 1.0; for (auto &pair : class_count) { double prob = (double)pair.second / num_samples; gini -= prob * prob; } return gini; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 实现求解最优分割点函数
double DecisionTree::split(vector<vector<double>> features, vector<int> labels, int attr, double split_val, vector<int> &left, vector<int> &right) {
int num_samples = labels.size();
for (int i = 0; i < num_samples; ++i) {
if (features[i][attr] < split_val) {
left.push_back(labels[i]);
} else {
right.push_back(labels[i]);
}
}
double gini_left = calc_gini(left), gini_right = calc_gini(right);
return (gini_left * left.size() + gini_right * right.size()) / num_samples;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 实现求解绝对众数函数
int DecisionTree::majority_vote(vector<int> labels) { int num_samples = labels.size(); map<int, int  # 三、Java 实现随机森林算法及代码详解 随机森林算法基于决策树的集成学习,它在输入样本的自助采样和随机特征选择上增加了随机化,从而有效地减少了过拟合现象。随机森林算法具有广泛的应用,如分类、回归和特征选择等。 下面给出随机森林算法的代码实现。 首先,我们需要使用决策树来实现随机森林。这里我们使用 CART 决策树算法,其中每个节点使用基尼指数来进行划分。代码如下: ```java import java.util.*; public class DecisionTree { private List<double[]> data; private List<Integer> labels; private int maxDepth; private Node root; // 决策树节点类 private static class Node { private int splitAttribute; private double splitValue; private Node left; private Node right; private int label; public Node(int splitAttribute, double splitValue) { this.splitAttribute = splitAttribute; this.splitValue = splitValue; } public Node(int label) { this.label = label; } public boolean isLeaf() { return left == null && right == null; } } public DecisionTree(List<double[]> data, List<Integer> labels, int maxDepth) { this.data = data; this.labels = labels; this.maxDepth = maxDepth; root = buildTree(data, labels, 0); } // 训练决策树 private Node buildTree(List<double[]> data, List<Integer> labels, int depth) { if (depth >= maxDepth || data.size() == 0) { return new Node(getMajorityLabel(labels)); } double minGini = Double.POSITIVE_INFINITY; int splitAttribute = 0; double splitValue = 0; // 随机选择 m 个特征 int m = (int) Math.sqrt(data.get(0).length); List<Integer> attributes = randomAttributes(m, data.get(0).length); // 在随机选择的特征中选取最优划分属性和划分值 for (int attribute : attributes) { for (double value : randomValues(data, attribute)) { List<double[]> leftData = new ArrayList<>(); List<int[]> leftLabels = new ArrayList<>(); List<double[]> rightData = new ArrayList<>(); List<int[]> rightLabels = new ArrayList<>(); for (int i = 0; i < data.size(); i++) { if (data.get(i)[attribute] <= value) { leftData.add(data.get(i)); leftLabels.add(new int[]{labels.get(i)}); } else { rightData.add(data.get(i)); rightLabels.add(new int[]{labels.get(i)}); } } double gini = giniIndex(leftLabels, rightLabels); if (gini < minGini) { splitAttribute = attribute; splitValue = value; minGini = gini; } } } Node node = new Node(splitAttribute, splitValue); List<double[]> leftData = new ArrayList<>(); List<Integer> leftLabels = new ArrayList<>(); List<double[]> rightData = new ArrayList<>(); List<Integer> rightLabels = new ArrayList<>(); // 根据最优划分属性和划分值构建左右子树 for (int i = 0; i < data.size(); i++) { if (data.get(i)[splitAttribute] <= splitValue) { leftData.add(data.get(i)); leftLabels.add(labels.get(i)); } else { rightData.add(data.get(i)); rightLabels.add(labels.get(i)); } } node.left = buildTree(leftData, leftLabels, depth + 1); node.right = buildTree(rightData, rightLabels, depth + 1); return node; } // 随机选择 m 个特征 private List<Integer> randomAttributes(int m, int n) { List<Integer> attributes = new ArrayList<>(); for (int i = 0; i < m; i++) { int attribute; do { attribute = new Random().nextInt(n); } while (attributes.contains(attribute)); attributes.add(attribute); } return attributes; } // 在某个属性值的范围内随机选择一个值 private List<Double> randomValues(List<double[]> data, int attribute) { List<Double> values = new ArrayList<>(); double min = Double.POSITIVE_INFINITY; double max = Double.NEGATIVE_INFINITY; for (double[] instance : data) { min = Math.min(min, instance[attribute]); max = Math.max(max, instance[attribute]); } for (int i = 0; i < 10; i++) { values.add(min + (max - min) * new Random().nextDouble()); } Collections.sort(values); return values; } // 计算基尼指数 private double giniIndex(List<int[]> leftLabels, List<int[]> rightLabels) { double gini = 0; int totalSize = leftLabels.size() + rightLabels.size(); double leftRatio = (double) leftLabels.size() / totalSize; double rightRatio = (double) rightLabels.size() / totalSize; gini += leftRatio * gini(leftLabels); gini += rightRatio * gini(rightLabels); return gini; } private double gini(List<int[]> labels) { double gini = 1; Map<Integer, Integer> labelCount = new HashMap<>(); for (int[] label : labels) { int count = labelCount.getOrDefault(label[0], 0); labelCount.put(label[0], count + 1); } for (int label : labelCount.keySet()) { double ratio = (double) labelCount.get(label) / labels.size(); gini -= ratio * ratio; } return gini; } // 获取多数类标签 private int getMajorityLabel(List<Integer> labels) { Map<Integer, Integer> labelCount = new HashMap<>(); for (int label : labels) { int count = labelCount.getOrDefault(label, 0); labelCount.put(label, count + 1); } int majorityLabel = 0; int majorityCount = 0; for (int label : labelCount.keySet()) { int count = labelCount.get(label); if (count > majorityCount) { majorityLabel = label; majorityCount = count; } } return majorityLabel; } // 预测样本标签 public int predict(double[] instance) { Node node = root; while (!node.isLeaf()) { if (instance[node.splitAttribute] <= node.splitValue) { node = node.left; } else { node = node.right; } } return node.label; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
然后,我们可以使用随机森林算法来对数据进行分类。随机森林算法的基本步骤如下:
- 随机从原始样本中采样出 k k k 个子样本;
- 对每个子样本训练一棵决策树;
- 使用训练好的决策树对未见过的样本进行预测,并将每棵决策树的预测结果进行投票;
- 根据投票结果来确定最终预测结果。
下面是随机森林算法的代码实现:
import java.util.*; public class RandomForest { private List<double[]> data; private List<Integer> labels; private int numTrees; private int maxDepth; private List<DecisionTree> trees; public RandomForest(List<double[]> data, List<Integer> labels, int numTrees, int maxDepth) { this.data = data; this.labels = labels; this.numTrees = numTrees; this.maxDepth = maxDepth; trees = new ArrayList<>(); for (int i = 0; i < numTrees; i++) { List<double[]> sampleData = new ArrayList<>(); List<Integer> sampleLabels = new ArrayList<>(); for (int j = 0; j < data.size(); j++) { int index = new Random().nextInt(data.size()); sampleData.add(data.get(index)); sampleLabels.add(labels.get(index)); } trees.add(new DecisionTree(sampleData, sampleLabels, maxDepth)); } } // 预测样本标签 public int predict(double[] instance) { Map<Integer, Integer> labelCount = new HashMap<>(); for (DecisionTree tree : trees) { int label = tree.predict(instance); int count = labelCount.getOrDefault(label, 0); labelCount.put(label, count + 1); } int maxCount =
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38