
热门标签
热门文章
- 1vue中项目总结及文件夹配置_vue项目文件夹介绍libs
- 2虚拟技术微软自家的Hyper_V 报错the image's hash and certificate are not allowed_windows hyperv使用centos iso报错
- 3JAVA 将时间戳转化成时间的三种写法_string.valueof(timestamp)作用
- 4三层交换机实现VLAN互连_三层交换机vlan间互通
- 5crontab 犯了一个错误,每小时执行一次 * */1 * * *_*/1 * * * *
- 6Opencv图像拼接_cv::mat 拼接
- 7Sobel边缘检测算法
- 8python中的进程、线程(threading、multiprocessing、Queue、subprocess)
- 9NVIDIA RTX A6000/RTX3090/3080/3070深度学习训练/GPU服务器硬件配置推荐2021_a6000 fp16
- 10Neo4j Cypher查询语言详解
当前位置: article > 正文
易懂:决策树与随机森林_决策树的原理及分析结果较容易解释,随机森林难解释
作者:代码架构师 | 2024-02-01 09:32:48
赞
踩
决策树的原理及分析结果较容易解释,随机森林难解释
相关知识铺垫
- 信息熵的定义:在物理界中,熵是描述事物无序性的参数,熵越大则越混乱;而信息熵是信息论中用于度量信息量的一个概念。一个系统越是有序,信息熵就越低;一个系统越是混乱,信息熵就越高,所以,信息熵也可以说是系统有序化程度的一个度量。
- 信息熵的公式:
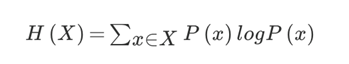
也可以理解为:H(x) = -(p1logp1 + p2logp2 + … + p32logp32) - 信息熵公式案例:在不知道任何有关信息不知道的情况下:在32个比赛用马(样本)中猜出一个编号为获胜者(目标值)的信息熵计算:H(X) = -(1/32log1/32+1/32log1/32+…+1/32*log1/32) =log32 = 5
- 这里的5代表了:1、按照二分法最多5次就能猜中获胜马的编号;2(重要)、该事务此时的总的信息熵为5。
- 如果此时我们知道了这些马的一个特征:马的血统,那么通过相关计算(具体参考下面一个详细的计算案例)就会发现该事物的总的信息熵会被减少,那么此时便可以引出信息增益的概念。
- 信息增益:当得知数据集中某一个特征条件之后,减少的信息熵的大小度量。
- 信息增益公式: g(D,A)=H(D)-H(D|A) 。 g(D,A):指的是信息增益;H(D):指的是目标值的信息熵的大小;H(D|A):条件熵的大小(条件熵是指:知道某个特征后总的信息熵的值)。H(D)和H(D|A)计算公式如下:
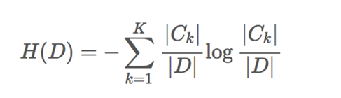
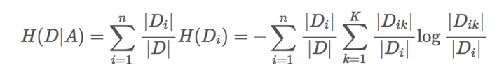
- 为了更好的理解这个信息增益公式,我用了一些别人的测试案例 类别为目标值 (代表女方是否愿意和该男性相亲),具体数值我并没有计算出来。:

1、我们用A1、A2、A3、A4分别表示年龄、有工作、有自己的房子和信贷四个特征。
2、此时:g(D,A1) = H(D) - H(D|A1)。
3、 此时:H(D) = - (9/15)log(9/15)-(6/15)log(6/15)。
4、此时:H(D|A1) = - [(5/15)H(D1)+(5/15)H(D2)+(5/15)H(D3)] ps:D1、D2、D3 分别指的是:青年、中年、老年;(5/15)指的是:青年、中年、老年在特征中所占数量比。。
5、此时:H(D1) = - (2/5)log(2/5) - (3/5)log(3/5) ps:2/5 指的是青年在目标值中不同选择的所占比。
6、由此我们便可计算H(D2)、H(D3)进而求出g(D,A1),最终求出g(D,A2)、g(D,A3)、g(D,A4)从而确定最优特征。
7、通过计算,我们可以确定g(D,A3)的值最大,也就说明是否有房是四个特征的信息增益中最大的,即为最优特征,同时,也从侧面反映了,女性在择偶方面“有没有房”是第一要素。
关于决策树
- 重要:观看下文的时候,你可能需要参考决策树算法输出的模型图片来理解,请参考:决策树理解参考图。
- 简单了解一下何为决策树:参考上图,通俗来讲:女性在选择相亲对象的时候,会有一个优先级判断,“是否有房”为信息增益最大的特征,即:此特征最为“优先”,所以“有房的”在她们心里会更重要一些,其次是年龄,工作,信贷情况,每一次的优先级判断就是决策树划分的过程,从是否有房,依次“生根发叶”。
- 那么就可以引出一个概念(决策树预测数据的原理):决策树在对数据进行分析的时候,实际上是一个选择的过程,我们把最优特征定为第一个树节点的话,那么在不一样的选择就会产生新的节点,当一个节点不会生成新的节点的时候,那么这个节点就代表着一种可能性,而测试集每个样本就是按照训练集进行选择的规则,而推测出这个“可能性”,其“可能性”也就对应着该样本的目标值。
- 为什么决策树深度会影响预测的准确性?:也许树越深越复杂,树节点就会越多,测试集样本就会越容易“选择”错的可能性。
- 决策树的目的:尽可能的让训练集的每个样本都可以正确的分类(在不指定树的深度的情况下,树会一直进行“决策”,直到节点真的不会再生成了)。
- 决策树具体使用的算法有:ID3:信息增益 最大准则;C4.5:信息增益比 最大准则;CART:1、回归树:平方差 最小准则 ,2、分类树:基尼系数 最小准则( 基尼系数是sklearn选择划分决策树的默认原则)
- 为什么sklearn划分决策树的默认原则是基尼系数?:这是因为基尼系数相对于信息增益而言划分的更加仔细(它将每个数值形的数据都进行了更为细致的划分)。
- 决策树优点:1、简单的理解和解释,树木能够可视化。2、需要很少的数据准备,其他技术通常需要数据归一化。
- 决策树缺点:1、决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合,具体参考:过拟合与次拟合。2、决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成。
- 关于过拟合:定义:为了得到一致假设而使假设变得过度严格称为过拟合 。简单举个例子:当决策树在不断的“生根发叶的时候”,有的“叶子”只是为了一个样本(异常点)而“长出来的”,它不具有普遍性,这就是过拟合。
- 如何处理过拟合?: 1、减枝cart算法(a、规定一个节点有多少个样本的时候才能继续产生子节点;b、规定一个节点最少有几个样本。))。2、随机森林(使用较多)。
- 决策树算法Python实现:决策树算法python实现
关于随机森林
- 首先要明白:随机森林的前提是决策树
- 了解一下集成学习方法:集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。通俗来讲:解决一个问题的时候,不要太死板,如果答案不具有普遍性,那么就要多尝试,从而使答案具有普遍性了。随机森林就是通过创建多个决策树来解决其过拟合问题。
- 随机森林的定义(预测数据的原理):随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
- 随机森林建立多个决策树的过程:
- 1、先看单个树建立的过程:1、随机在n个样本中选择一个样本,重复n次。 2、随机在M个特征中选出m个特征(m<M)
- 2、建立十棵决策树的过程:重复单个树建立的过程。
- 3、需要注意的是:单个树建立的过程采用的是随机有放回的抽样(bootstrap抽样)
- 4、简单说明一下为什么要随机有放回的抽样:如果不随机那么训练出来的树不都一样了?如果不把样本再放回去数据不放回,那么训练出来的树能具有普遍性?
简单总结下随机森林
- 适用场景:数据量大,特征值多,数据本身更复杂的场景。
- 优点:1、极高的准确率;2、可有效的运行在大数据集上;3、能够处理具有高维特征的输入样本,且不需要降维;4、能够评估各个特征在分类问题上的重要性。
python实现决策树的API介绍
- API:class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- 重要参数介绍:criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’;max_depth:树的深度大小;random_state:随机数种子,默认为None,可使用np.random(用来设置分枝中的随机模式的参数,为了避免高纬度数据随机性太明显,最好指定一个数值);min_samples_leaf:规定每个节点最少有几个训练样本;min_samples_split:该节点具有多少训练样本时,才可以继续分支;
python实现随机森林的API介绍
- Api:class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’,
max_depth=None, bootstrap=True, random_state=None) - 重要参数介绍:n_estimators:i森林里的树木数量默认是10,(一般给:120,200,300,500,800,1200比较合适);criteria:分割特征的测量方法,默认基尼系数;max_depth:树的最大深度 ,默认无,(一般给:5,8,15,25,30 即可);bootstrap:是否在构建树时使用放回抽样 ,默认True;max_features:每个决策树的最大特征数量(特征多了容易过拟合),默认auto。
- 总结下随机森林常用超参数:n_estimators、max_depth、
决策树理解参考图
- 图片借鉴网络

决策树与随机森林案例
- 经典的泰坦尼克号生死预测案例
- 需求:预测泰坦尼克号乘客存活可能性
- 数据集:泰坦尼克号数据集
- 数据集备注:数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别,其中age数据存在缺失。
#!/usr/local/bin/python3 # -*- coding: utf-8 -*- # Author : rusi_ import os import pandas as pd from sklearn.tree import DecisionTreeClassifier, export_graphviz from sklearn.feature_extraction import DictVectorizer from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.ensemble import RandomForestClassifier def decision_tn(): """ 决策树预测泰坦尼克号乘客生死问题 :return: None """ tn = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt") x = tn[['pclass', 'age', 'sex']] y = tn["survived"] x["age"].fillna(x["age"].mean(), inplace=True) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # Feature Engineering(one hot) dict_ = DictVectorizer(sparse=False) x_train = dict_.fit_transform(x_train.to_dict(orient="records")) x_test = dict_.transform(x_test.to_dict(orient="records")) dec = DecisionTreeClassifier() dec.fit(x_train, y_train) print("预测的准确率为:\n", dec.score(x_test, y_test)) print(dict_.feature_names_) # Derive the structure of decision tree export_graphviz(dec, out_file="./obj_file/tree.dot", feature_names=dict_.get_feature_names()) return def random_forest_tn(): """ 随机森林预测泰坦尼克号乘客生死问题 :return: None """ tn = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt") x = tn[['pclass', 'age', 'sex']] y = tn["survived"] x["age"].fillna(x["age"].mean(), inplace=True) x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # Feature Engineering(one hot) dict_ = DictVectorizer(sparse=False) x_train = dict_.fit_transform(x_train.to_dict(orient="records")) x_test = dict_.transform(x_test.to_dict(orient="records")) # Random forest rf = RandomForestClassifier() # Grid search with cross validation param = {"n_estimators": [120, 200, 300, 500, 800, 1200], "max_depth": [5, 8, 15, 25, 30]} gc = GridSearchCV(rf, param, cv=2) gc.fit(x_train, y_train) print(f"准确率:{os.linesep}", gc.score(x_test, y_test)) print(f"查看选择最优的参数模型:{os.linesep}", gc.best_params_) return if __name__ == '__main__': # 预测的准确率为: # 0.8054711246200608 # decision_tn() # 准确率:0.8328267477203647 # 查看选择最优的参数模型: # {'max_depth': 5, 'n_estimators': 300} random_forest_tn()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
补充
- 决策树与one-hot编码的关系:决策树与one-hot编码
- 我的代码片种有生成决策树dot文件,关于如何将dot文件转换成png文件格式请参考:win下dot转png
- 关于参数详情可自行查看源码或查阅相关资料。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/52945?site
推荐阅读
相关标签

