
- 1IOS版aplayer使用教程_IOS安全教程:反编译工具使用
- 2香港服务器CDN加速与DDOS防御方案_ddos1.301-cdn.net
- 3力扣80. 删除排序数组中的重复项 II C语言_力扣80题
- 4【华为od机试】约瑟夫问题-Python3_蓝球(5v5)比赛,每个球员拥有一个战斗力,每个队伍所有球员战斗力之和薇该队伍的总
- 5【LeetCode】字符串匹配_leetcode 字符串匹配
- 6Pycocotools2.0安装+Microsoft Visual C++ 14.0 安装_microsoft visual c++ 14.0的安装
- 7《动手学深度学习(PyTorch版)》笔记5
- 8微信网页版接口详解_微信登录接口
- 9安全、高效的MySQL DDL解决方案
- 10基于Java+Vue+uniapp微信小程序大学生科技竞赛管理系统设计和实现
特制自己的ChatGPT:多接口统一的轻量级LLM-IFT平台
赞
踩

©PaperWeekly 原创 · 作者 | 佀庆一
单位 | 中科院信息工程研究所
研究方向 | 视觉问答

项目简称:
Alpaca-CoT(当羊驼遇上思维链)
项目标题:
Alpaca-CoT: An Instruction Fine-Tuning Platform with Instruction Data Collection and Unified Large Language Models Interface
项目链接:
https://github.com/PhoebusSi/Alpaca-CoT

ChatGPT背后的技术
LLM:(Large Language Models)指经过大规模预训练且体量较大的语言模型,一般是 transformer-based 模型。
IFT:(Instruction Fine-Tuning)指令微调,指令是指用户传入的目的明确的输入文本,指令微调用以让模型学会遵循用户的指令。
CoT:(Chain-of-Thought)指令形式的一种特殊情况,包含 step-by-step 的推理过程。如下图蓝色部分所示。
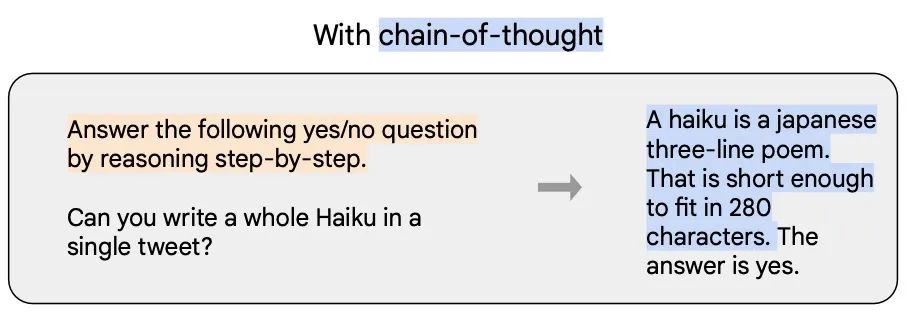

定位
ChatGPT 的出现验证了大型语言模型 (LLM) 在通用人工智能 (AGI) 上的潜力。基于 LLaMA [1] 等 Large Language Models (LLMs) 的 instruction-tuning 研究(如,Alpaca [2])大幅度加速了复现 ChatGPT 的进程。Alpaca-CoT 希望在这个研究方向上做出适度的贡献,以推进 LLMs 的开源进程、降低 LLMs 研究和使用成本。
具体来说,Alpaca-CoT 项目旨在探究如何更好地通过 instruction-tuning 的方式来诱导 LLM 具备类似 ChatGPT 的交互和 instruction-following 能力。为此,我们广泛收集了不同类型的 instruction(尤其是 Chain-of-Thought)数据集,并将包含 LLaMA、ChatGLM、Bloom 在内的多种 LLMs 集成进来统一接口。
在这基础上,我们基于 LLaMA 给出了深入细致的实证研究,以供未来工作参考。据我们所知,我们是首个将 CoT 拓展进 Alpaca 的工作,因此项目简称为 "Alpaca-CoT"。
热烈欢迎您向我们提供任何未被本项目收集的 instruction-tuning 及各类 tasks 数据集(或其来源)。我们将:
将这些数据收录并进行统一格式化处理,并注明来源;
用这些数据集 instruction finetune 一系列的 LLM(如 llama, ChatGLM 等),并开源其 checkpoint;
进行广泛的实证研究以探究新收录的数据集的作用。
同时也欢迎您向我们指出(general 或特定能力上)表现不错的开源 LLM,我们将:
将这些 LLM 集成到我们的平台中,可以通过超参切换不同的 LLM;
开源该模型在我们框架下 IFT 后的 checkpoint。
我们希望我们的项目能够为大型语言模型的开源过程做出适度的贡献,并降低 NLP 研究人员上手 LLM 相关研究的门槛。

概述
近期,LLaMA [1] 显示出惊人的 zero-shot 和 few-shot 能力,仅需较少的参数即可和 GPT-3.5 性能相当(LLaMA-13B 显著优于 GPT-3(175B),LLaMA-65B 与 PaLM-540MB 相当),明显降低了训练、微调和使用 competitive 大型语言模型的成本。
最近,为了提高 LLaMA 的 instruction-following 能力,Stanford Alpaca [2] 借助 self-instruct [3] 的方式生成的 52K Englishi instruction-finetuning 数据对 LLaMA 进行了微调,达到了客观的效果。然而,目前该方向的研究仍然面临着以下四个挑战:
即便仅对 7b 大小的 LLM fientune,依然对计算资源有着较高的要求;
用于 instruction finetuning 的开源数据集较少,缺少资源整合;
缺少统一的平台,可以轻松切换不同的 LLMs 和不同类型的 IFT 数据;
缺乏各 instruction 类型带来的影响的实证研究,如响应中文的能力和 CoT 能力。
为此,我们提出了 Alpaca-CoT 项目,该项目结合了相关的近期前沿技术,具有以下优势:
仅需要较低计算资源即可高效完成对 LLaMA 的微调。7b, 13b 和 30b 版本的 LLaMA 模型均可在单卡 80G A100 上完成训练。我们的代码主要修改自 Alpaca-LoRA,其使用了 low-rank adaptation (LoRA) [4], PEFT 和 bitsandbytes 等技术来达到降低计算资源需求的效果;
我们发布的模型显著提升了 CoT (reasoning) 能力;
我们发布的模型显著提升了对中文指令的响应能力;
维护了一个仍在不断扩大规模的 intruction-finetuning 的数据集集合。该集合包含了中文、英文和 CoT、code、story 等 instruction 数据。同时,我们也维护了一个训练自各种 instruction 数据集的模型 checkpoint 集合。
集成了多种 LLMs 并统一了调用接口,可通过超参轻松切换。目前包含 LLaMA, ChatGLM [5] 和 Bloom [6],后续将持续加入更多,以供研究者们轻松调用和对比不同 LLMs。
提供了详尽透彻的 Empirical Study,这里的 findings 可能会对促进未来 LLM 探索有一定的参考价值。

多接口统一的开源平台
为了便于研究者们在 LLM 上做系统的 IFT 研究,我们收集了不同类型的 instruction 数据,集成了多种 LLM,并统一了接口,可以轻松定制化想要的搭配:
--model_type: 设置想要研究的LLM,目前已支持 [llama, chatglm 和 bloom],其中 llama 的英文能力较强,chatglm 的中文能力较强,bloom 关注多语种能力,后续将会集成更多的 LLMs。
--data: 设置用以 IFT 的数据类型,以灵活特制想要的指令遵循能力,如追求较强的推理能力可设置 alpaca-cot,较强的中文能力可设置 belle1.5m,金融相关的响应能力可设置 finance,code 和 story 生成可设置 gpt4all。
--model_name_or_path: 与 --model_type 相对应,用来加载目标 LLM 的不同型号权重。如,要加载 llama 的 13b 的模型权重时可设置 decapoda-research/llama-13b-hf。
你可以在这里下载训练自各种类型 instruction 数据的所有 checkpoints:
https://huggingface.co/QingyiSi/Alpaca-CoT/tree/main
- # 单卡
- CUDA_VISIBLE_DEVICES=0 python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf \
- --data alpaca-belle-cot --lora_target_modules q_proj v_proj
-
- # 多卡
- python3 -m torch.distributed.launch --nproc_per_node 4 \
- --nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py \
- --model_type llama --model_name_or_path decapoda-research/llama-7b-hf \
- --data alpaca-belle-cot --lora_target_modules q_proj v_proj
然后,在 gernerate.py 中的 LoRA_WEIGHTS 设置成下载路径,即可直接运行模型的 inference 以查看模型效果。

指令数据集合
该集合仍在不断更新和扩增中。可在以下链接下载和查看更多数据细节:
https://huggingface.co/datasets/QingyiSi/Alpaca-CoT
数据统计
注意:下图是截止到 2.26 日收集到的数据集的统计情况,仅作为 motivation 展示。目前已收集了更多数据集,如金融相关,code 生成相关的指令数据集。
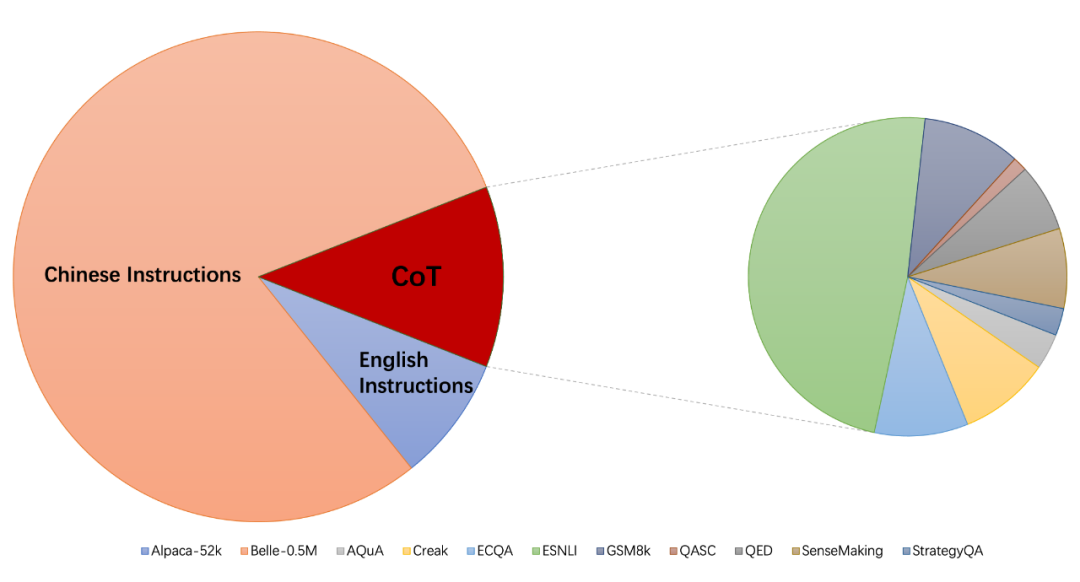
当前的 instruction-finetuning 数据集合主要包含以下三个部分:
alpaca_data_cleaned.json: 包含 5 万左右英文指令数据;
CoT_data.json: 包含 9 个 CoT 数据集,共 7 万条左右数据(相关的数据集由 FLAN [7] 发布,我们统一了数据 format);
belle_data_cn.json: 包含 50 万左右中文指令数据(相关的中文 instruction 数据由 BELLE [8] 发布)。
数据下载
你可以在这里下载所有我们已经统一格式后的 formatted 数据:
https://huggingface.co/datasets/QingyiSi/Alpaca-CoT/tree/main
然后,将下载到的文件全部放到 data folder:
https://github.com/PhoebusSi/alpaca-CoT/tree/main/data
数据格式
我们集合中的所有数据均已被转化成相同的格式,每个样本的格式如下:
- [
- {"instruction": instruction string,
- "input": input string, # (may be empty)
- "output": output string}
- ]
注意,对于 CoT 数据集,我们首先使用 FLAN 提供的 template 将其从原数据转化成 Chain-of-Thought 的形式,之后再统一成以上格式。
https://github.com/google-research/FLAN/blob/main/flan/v2/templates.py
格式统一化的脚本可以在这里找到:
https://github.com/PhoebusSi/alpaca-CoT/blob/main/data/origin_cot_data/formating.py
您也可以标注或生成(e.g., 采取 self-instruct 的做法)符合自己业务/专业需求的特定方向的 IFT 数据。如果同意开源且质量较好,我们会收集到我们维护的数据指令集合中并注明来源:
https://huggingface.co/datasets/QingyiSi/Alpaca-CoT/tree/main

模型效果
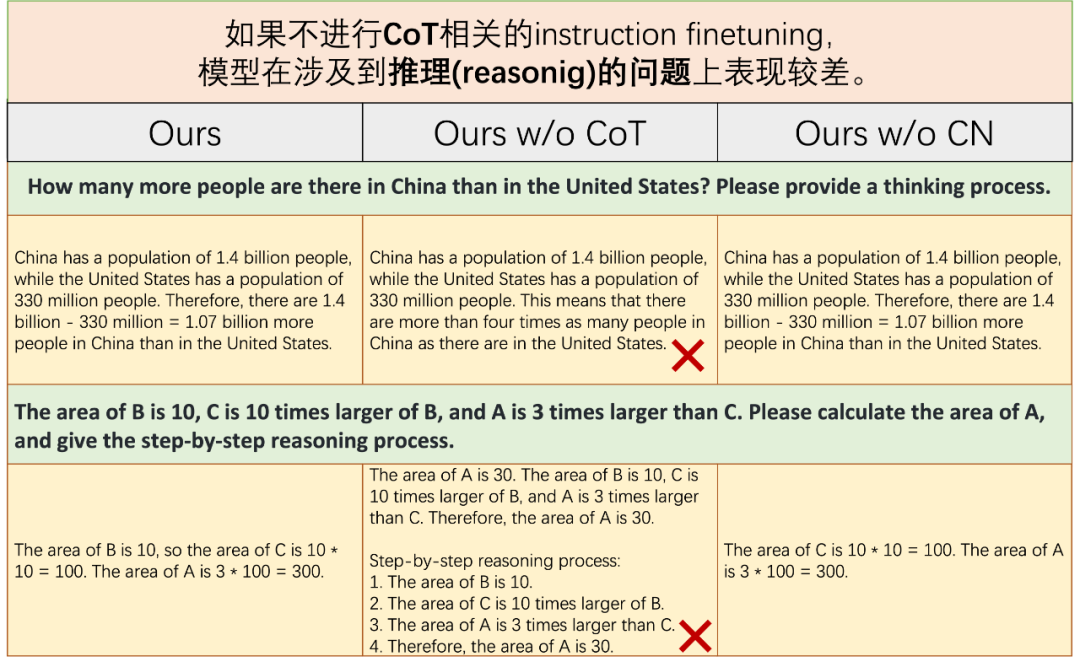
关于CoT和Chinese Instructions的消融对比
"w/o CoT" 和 "w/o CN" 分别表示用在 instruction-finetuning 期间不采用 CoT 数据和 Chinese instructions。
下图是需要推理能力的问题上的表现:
下图是需要遵循中文指令的问题上的表现:

下图是在较复杂问题上的表现:
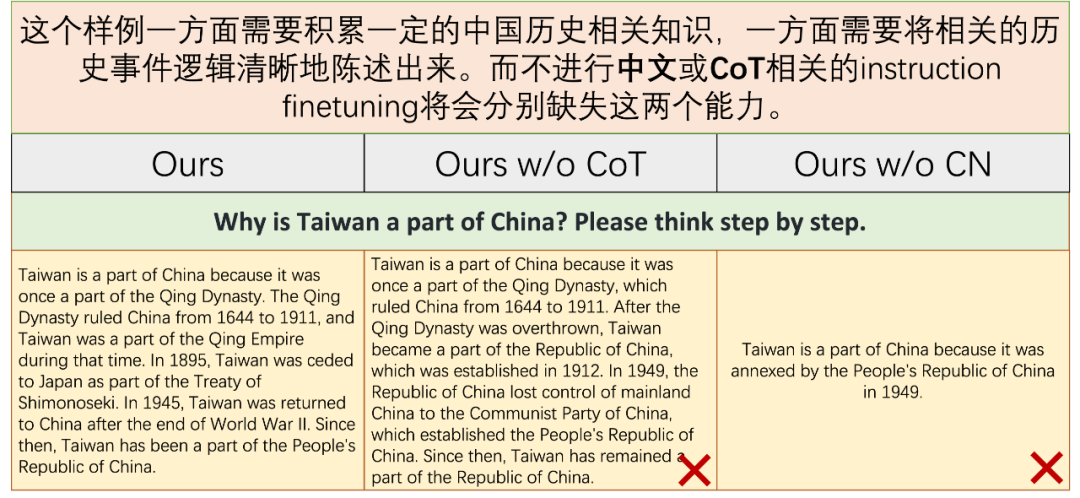
从以上样例可以看出,从我们完整数据集 collection(英文、中文和 CoT 指令数据)中微调得到的模型可以显著提高 reasoning 能力和响应中文指令的能力。
更多能力展示



对比实验
CoT能力
下图是引入 CoT 能力前(原 Alpaca)后(Ours w/CoT)的表现对比:

可以看出,我们的模型不仅可以给出准确的答案,而且还可以给出对应的思考过程。
遵循中文指令的能力
下图是引入遵循中文指令能力前后在中文指令上的表现对比:

其中 Alpaca 未使用任何中文指令数据集,Belle 在更多的中文指令数据集中微调关注 multiple-lingual 的大语言模型 BLOOM。
可以看出,原模型 Alpaca 在第一个例子中无法准确识别中文指令,在第三个例子中无法用中文响应中文指令。而我们的模型表现基本与 Belle 持平。后续,我们将会引入更多中文指令数据,同时我们的 repository 将分出一个 branch 专门探究中文交互能力。
下图是引入遵循中文指令能力前后在英文指令上的表现对比:

可以看出,在中文指令数据集上微调后,并不会对模型 follow 英文指令造成负面影响。

总结
在 LLM 上的 IFT 研究是一个 impressive 的方向,其加速了复现 ChatGPT 的进程。然而,由于 instruction 数据集的开源工作较少,大模型训练需要极高计算资源等原因,目前相关的研究仍处于起始阶段,几乎被 OpenAI、微软、Google、Meta 等大公司垄断。
我们的工作 Alpaca-CoT 在解决这两个问题上各迈出了一小步:基于 Alpaca-LoRA 的技术路线(单机可训)将不同的 LLM 集成进来,以降低不同 LLM 的计算资源消耗,同时持续收集、统一格式化指令数据,以搭建出更方便的多接口统一的研究平台。欢迎大家在我们的平台上进行自己的研究,一起为加速复现 ChatGPT 而努力!

参考文献
[1]. LLaMA: Open and Efficient Foundation Language Models https://arxiv.org/abs/2302.13971
[2]. Stanford Alpaca: An Instruction-following LLaMA model https://github.com/tatsu-lab/stanford_alpaca
[3]. Self-Instruct: Aligning Language Model with Self Generated Instructions https://arxiv.org/abs/2212.10560
[4]. LoRA: Low-Rank Adaptation of Large Language Models https://arxiv.org/pdf/2106.09685.pdf
[5]. ChatGLM: An Open Bilingual Dialogue Language Model https://github.com/THUDM/ChatGLM-6B
[6]. BLOOM: A 176B-Parameter Open-Access Multilingual Language Model https://arxiv.org/abs/2211.05100
[7]. FLAN: Scaling Instruction-Finetuned Language Models https://arxiv.org/abs/2210.11416
[8]. BELLE: Bloom-Enhanced Large Language model Engine https://github.com/LianjiaTech/BELLE

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。



Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

