
- 1Spring Boot 整合RabbitMQ
- 2AIGC,ChatGPT AI绘画 Midjourney 注册流程详细步骤
- 3头文件循环引用导致“unknown type name”的问题详解
- 4基于SSM的学生信息管理系统(选课管理系统)的设计与实现 (含源码+sql+视频导入教程)_sql学生选课管理系统
- 5C/C++大学课程信息系统_c++开课查询系统
- 6华为OD机试题【篮球比赛】用 C++ 进行编码 (2023.Q1)_华为机考篮球比赛吃+
- 7C++设计模式Learning:工厂方法_lesson learn 如何在工厂开展
- 8详解K8s Pod对象的生命周期_container lifecycle prestop
- 9三层架构实验
- 10Windows 10 |VMware开启虚拟化的最全面说明_vmware虚拟化引擎
基于PPYOLOE+PP-Tracking的低光场景多目标跟踪_基于ppyoloe+pp-tracking的自定义场景多目标跟踪
赞
踩
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
效果展示(没有镜头切换效果会更好)

一、项目背景
1.1 PP-YOLOE实现下游任务
PP-YOLOE+是基于PP-YOLOv2的卓越的单阶段Anchor-free模型,超越了多种流行的YOLO模型,当前多目标跟踪模型大多数在光线较为充足的条件下进行推理,然而实现低光场景的多目标跟踪同样重要。比如无人机的夜间物体检测、自动驾驶在夜间低光的多目标跟踪应用。
PP-YOLOE+模型具有强大的泛化能力,在低光场景下游任务检测效果提升效果显著。本项目使用PP-YOLOE+训练出自定义目标检测模型与多目标跟踪系统PP-Tracking相结合,通过将PP-Tracking中已实现的追踪算法进行迁移满足实际场景的多目标跟踪需求。下表为PP-YOLOE+在低光数据集ExDark的实验结果:
| 模型 | 数据集 | mAPval 0.5:0.95 | 下载链接 | 配置文件 |
|---|---|---|---|---|
| PP-YOLOE_m | ExDark | 56.4 | 下载链接 | 配置文件 |
| PP-YOLOE+_m (obj365_pretrained) | ExDark | 57.7(+1.3) | 下载链接 | 配置文件 |
| PP-YOLOE+_m (coco_pretrained) | ExDark | 58.1(+1.7) | 下载链接 | 配置文件 |
1.2 多目标跟踪系统PP-Tracking
多目标跟踪,一般简称为MOT(Multiple Object Tracking)。在事先不知道目标数量的情况下,对视频中的行人、汽车、动物等多个目标进行检测并赋予ID进行轨迹跟踪。不同的目标拥有不同的ID,以便实现后续的轨迹预测、精准查找等工作。
PaddleDetection团队提供了实时多目标跟踪系统PP-Tracking,是基于PaddlePaddle深度学习框架的业界首个开源的实时多目标跟踪系统,具有模型丰富、应用广泛和部署高效三大优势。 PP-Tracking支持单镜头跟踪(MOT)和跨镜头跟踪(MTMCT)两种模式,针对实际业务的难点和痛点,提供了行人跟踪、车辆跟踪、多类别跟踪、小目标跟踪、流量统计以及跨镜头跟踪等各种多目标跟踪功能和应用。
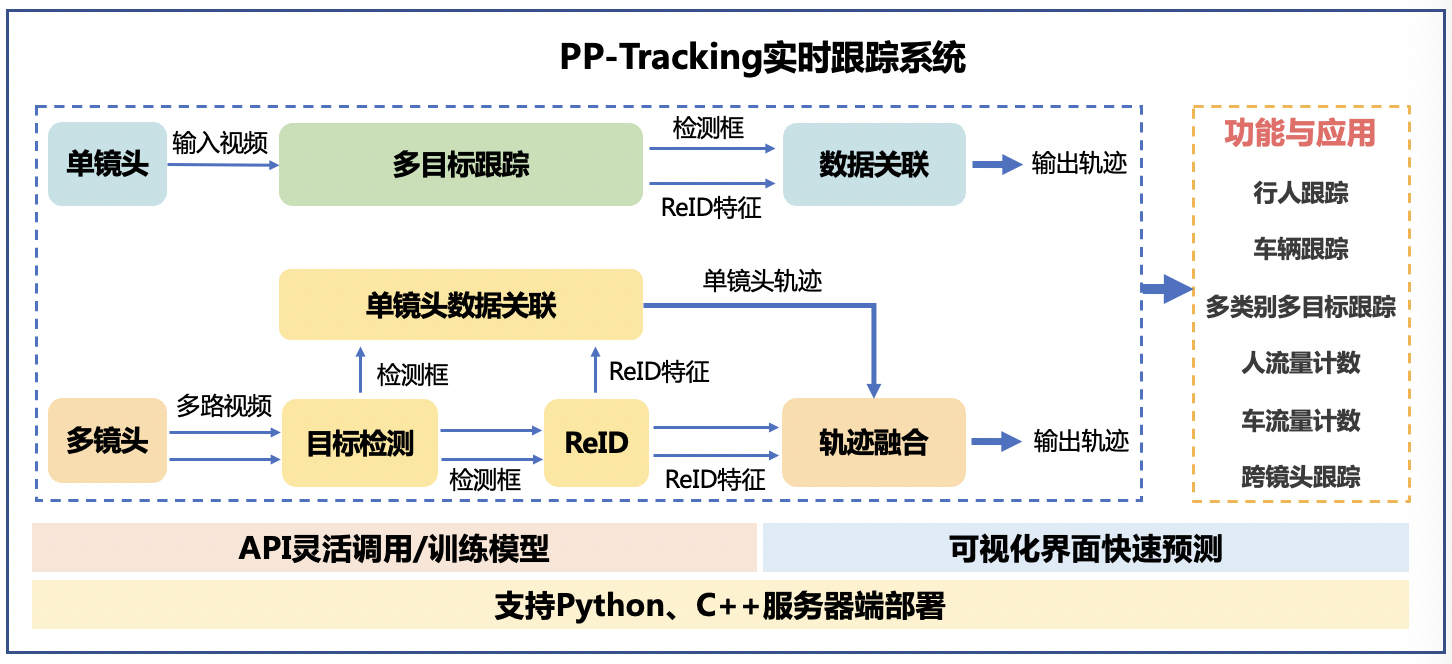
二、环境准备
2.1 数据准备
本项目采用低光数据集ExDark进行训练和推理部署,低光数据集使用ExDark,该数据集是一个专门在低光照环境下拍摄出针对低光目标检测的数据集,包括从极低光环境到暮光环境等10种不同光照条件下的图片,处理后的COCO格式,包含图片训练集5891张,测试集1472张,12个类别,ExDark COCO格式下载
1.Bicycle 2.Boat 3.Bottle 4.Bus 5.Car 6.Cat 7.Chair 8.Cup 9.Dog 10.Motorbike 11.People 12.Table
数据集来源 :https://github.com/cs-chan/Exclusively-Dark-Image-Dataset/tree/master/Dataset
下图为数据集部分图像:

# 解压数据集
!unzip -q /home/aistudio/data/data223920/Exdark.zip
- 1
- 2
2.2 安装PaddleDetection以及依赖
!mkdir PaddleDetection
- 1
# 解压PaddleDetection-develop
!unzip -q /home/aistudio/data/data218809/PaddleDetection-develop.zip
!mv PaddleDetection-develop/* PaddleDetection
!rm -r PaddleDetection-develop
- 1
- 2
- 3
- 4
# 安装PaddleDetection依赖
%cd PaddleDetection
!pip install -r requirements.txt --user
!python setup.py install --user
- 1
- 2
- 3
- 4
三、模型训练
本次采用PP-YOLOE+m(cocopretrained) 模型进行训练和推理,它相较于PP-YOLOE_m在预训练模型上进行更改,通过使用更加切合场景的coco预训练模型使得精度提升了1.7个点,本文通过改变训练的学习率在其基础上再次提升了0.4个点。达到了58.5的高精度,同时V100的average FPS为40以上,满足目标跟踪的场景需求,四卡训练好的模型保存在newconfig/best_model.pdparams
配置文件在PaddleDetection/configs/ppyoloe/application/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark.yml处,主要更改以下两个部分:
-
optimizer_80e.yml:base_lr: 0.0005(官方默认八卡,四卡训练的学习率调低1/2)
-
newconfig/exdark_detection.yml:数据集路径改为个人绝对路径
# 训练更改配置文件覆盖
!cp ../newconfig/optimizer_80e.yml configs/ppyoloe/_base_/optimizer_80e.yml
!cp ../newconfig/exdark_detection.yml configs/ppyoloe/application/_base_/exdark_detection.yml
- 1
- 2
- 3
# 开始单卡训练,学习率需要再降低4倍
# 恢复训练 -r output/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark/best_model.pdparams
!python tools/train.py \
-c configs/ppyoloe/application/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark.yml \
--use_vdl=True \
--vdl_log_dir=../work/ \
--eval
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# 开始四卡训练
# 恢复训练 -r output/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark/best_model.pdparams
!export CUDA_VISIBLE_DEVICES=0,1,2,3
!python -m paddle.distributed.launch --gpus 0,1,2,3 tools/train.py \
-c configs/ppyoloe/application/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark.yml --fleet \
--use_vdl=True \
--vdl_log_dir=../work/ \
--eval
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
训练过程可视化

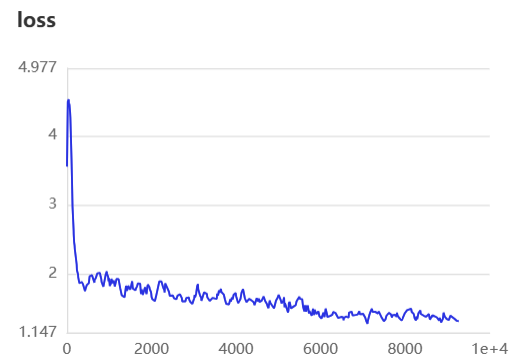
# 模型评估
!python -u tools/eval.py \
-c configs/ppyoloe/application/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark.yml \
-o weights=output/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark/best_model
- 1
- 2
- 3
- 4

四、推理图片

# 挑一张验证集的图片展示预测效果
!python tools/infer.py \
-c configs/ppyoloe/application/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark.yml \
-o weights=output/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark/best_model \
--infer_img=../Exdark/images/2015_00020.jpg \
--draw_threshold=0.50 \
--save_results=True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
# 批量预测
!python tools/infer.py \
-c configs/ppyoloe/application/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark.yml \
-o weights=output/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark/best_model \
--infer_dir=../test_img/ \
--output_dir=../test_img/infer_images/ \
--draw_threshold=0.5 \
--save_results=True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
五、多目标跟踪与视频推理
( 在这里感谢尛冥ing大佬的帮助!解决报错问题)
5.1导出ppyoloe推理模型
#导出部署模型
!python tools/export_model.py \
-c configs/ppyoloe/application/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark.yml \
-o weights=output/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark/best_model
- 1
- 2
- 3
- 4
# 导入一些可视化需要的包
import cv2
import numpy as np
from matplotlib import pyplot as plt
import os
%matplotlib inline
import imageio
import matplotlib.animation as animation
from IPython.display import HTML
import warnings
warnings.filterwarnings("ignore")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
# 定义一个展示视频的函数 def display(driving, fps, size=(8, 6)): fig = plt.figure(figsize=size) ims = [] for i in range(len(driving)): cols = [] cols.append(driving[i]) im = plt.imshow(np.concatenate(cols, axis=1), animated=True) plt.axis('off') ims.append([im]) video = animation.ArtistAnimation(fig, ims, interval=1000.0/fps, repeat_delay=1000) plt.close() return video

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
# 展示一下输入的视频, 这个视频只有十几秒,时间很快
video_path = '/home/aistudio/hp.mp4'
video_frames = imageio.mimread(video_path, memtest=False)
# 获得视频的原分辨率
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps).to_html5_video())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

5.2PP-Tracking追踪算法迁移
参考文档:多目标跟踪 (Multi-Object Tracking)
PaddleDetection中提供了SDE和JDE两个系列的多种算法实现,同时也支持ByteTrack和FairMOT(MCFairMOT)的多类别的多目标跟踪,本项目应用场景当然是多类别,因此采用ByteTrack进行迁移。
ByteTrack(ByteTrack: Multi-Object Tracking by Associating Every Detection Box) 通过关联每个检测框来跟踪,而不仅是关联高分的检测框。对于低分数检测框会利用它们与轨迹片段的相似性来恢复真实对象并过滤掉背景检测框。
参考文档:ByteTrack (ByteTrack: Multi-Object Tracking by Associating Every Detection Box)
配置文件修改:这里将deploy/pipeline/config/tracker_config.yml中的type改为JDETracker 确保实现多类别检测

注意:
如果模型导出文件的参数不匹配,可能会报错:TypeError: __init__() got an unexpected keyword argument 'norm_type',因此需要将infer_cfg.yml进行一定的更改,具体情况根据模型参数进行分析,这里将norm_type: none注释掉
!cp ../newconfig/infer_cfg.yml output_inference/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark/infer_cfg.yml
!cp ../newconfig/tracker_config.yml deploy/pipeline/config/tracker_config.yml
- 1
- 2
进行视频推理,推理好的视频文件保存在PaddleDetection/output/hp.mp4
!python deploy/pptracking/python/mot_sde_infer.py \
--model_dir=output_inference/ppyoloe_plus_crn_m_80e_coco_pretrained_exdark/ \
--tracker_config=deploy/pipeline/config/tracker_config.yml \
--video_file=/home/aistudio/hp.mp4 \
--threshold=0.2 \
--device=GPU \
# --save_mot_txts
- 1
- 2
- 3
- 4
- 5
- 6
- 7
说明:
- 运行ByteTrack模型需要确认
tracker_config.yml的跟踪器类型为type: JDETracker,上边已经进行更改 - 跟踪模型是对视频进行预测,不支持单张图的预测,默认保存跟踪结果可视化后的视频,可添加
--save_mot_txts(对每个视频保存一个txt)或--save_mot_txt_per_img(对每张图片保存一个txt)表示保存跟踪结果的txt文件,或--save_images表示保存跟踪结果可视化图片。 - 跟踪结果txt文件每行信息是
frame,id,x1,y1,w,h,score,-1,-1,-1。 --threshold表示结果可视化的置信度阈值,默认为0.5,低于该阈值的结果会被过滤掉,为了可视化效果更佳,可根据实际情况自行修改。--model_dir表示上述导出的模型路径,可根据自己训练的模型自行更改路径--device运行时的设备,可选择CPU/GPU/XPU,默认为CPU--tracker_config表示跟踪器配置文件,这里采用JDETracker,可根据实际需求配置跟踪器--video_file待检测视频文件
# 输出的视频展示,可以看到展示的效果还是不错的,在暗光环境下依然可以实现多目标多类别的跟踪!
video_path = '/home/aistudio/PaddleDetection/output/hp.mp4'
video_frames = imageio.mimread(video_path, memtest=False)
# 获得视频的原分辨率
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps).to_html5_video())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

六、参考资料与总结
-
通过PP-YOLOE+的训练,验证,推理等流程,实现低光场景模型的应用,并在官方基础上略微提升了精度
-
将PP-Tracking多目标多类别追踪算法迁移到PP-YOLOE的模型中,完成了复杂场景的多目标跟踪模型泛化
-
训练好的模型精度还没有达到最优,可以通过进一步调参进行精度提升,由于多目标跟踪模型大多基于连续视频的数据集进行训练,这里采用的是无关联的数据集训练的,在一定程度上会影响跟踪性能,可以跟换数据集进行尝试
-
多目标在实际应用上大多有多个相机联动,可以更换tacker类型进行尝试,感兴趣的可以尝试一下捕捉摄像头进行视频流检测
此文章为搬运
原项目链接

