
- 1SPI协议_spi msb
- 2UCOSIII-OSTimeDlyHMSM小问题(HardFault_Handler卡死)_ucos ii调用ostimedlyhmsm函数会进入hardfault_handler
- 3【Django】响应数据、重定向(redirect)、反向解析(reverse)_django redirect
- 4Docker | Docker+Nginx部署前端项目
- 5移动硬盘提示由于IO设备错误,无法运行此项请求数据怎么寻回_err:1117 由于 i/o 设备错误,无法运行此项请求
- 6MySQL数据库连接池 :Druid_mysql druid
- 7Docker容器的使用_docker mc book 使用 命令
- 8关键字volatile的作用和特性_volatile保证哪些特性
- 9图灵日记之java奇妙历险记--抽象类和接口
- 10【愚公系列】2023年12月 HarmonyOS应用开发者高级认证(完美答案)_@state修饰的属性不允许
使用Pytorch进行完整的模型训练_cifar10数据集_pycharm训练一个模型的步骤
赞
踩
前言
在B站大学跟这小土堆学习完了pytorch的教学视频之后,跟着up过了一遍完整的模型训练套路,为了方便以后的个人查阅,所以写此博文记录好模型训练的步骤以及总结个人实现过程中的一些笔记。
1.数据集准备及处理
模型训练使用的数据集是CIFAR10,我们引入数据集的时候,需要将download属性设置为True,这样pycharm后台会自动为我们下载数据集。不过这样的下载速度可能会很慢,看网上说要配置好镜像源才行,所以我采用了planB。
train_data = torchvision.datasets.CIFAR10(root="../dataset_cifar", train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../dataset_cifar", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
- 1
- 2
- 3
- 4
- 5
- 6
我们可以前往pytorch官网将数据集下载到本地,这样速度快很多。下载完成后,将数据集移动到pycharm对应的文件目录中,再次运行上面的代码,数据集就导入成功了。
接着我们加载数据集,并且查看一下数据集的大小
# 数据大小
train_data_size = len(train_data)
test_data_size = len(test_data)
# format可以将{}替换为函数内部的内容
print("训练数据集的长度为{}".format(train_data_size))
print("测试数据集的长度为{}".format(test_data_size))
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.搭建模型
我们通常将模型写在另外的python文件中,这里我们新建一个model.py文件,在里面搭建我们的模型。我们实现的模型结构如下图所示,最终得到一个10分类的结果。
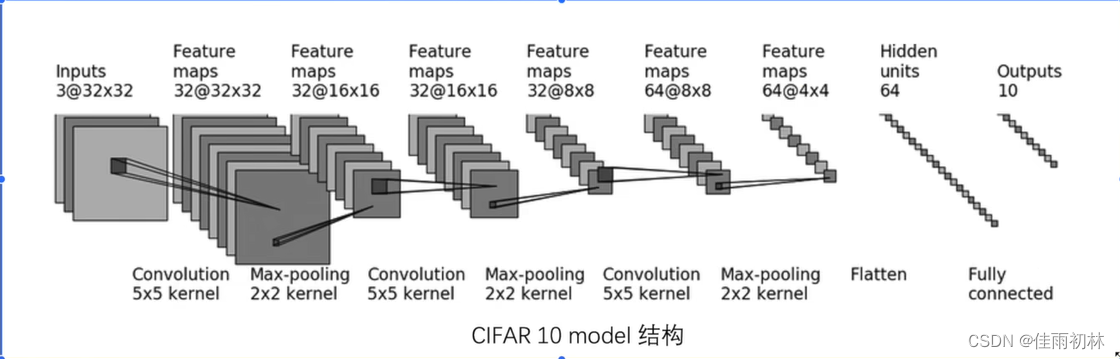 我们根据模型结构利用代码实现的时候,一定要弄清楚输入的通道数in_channel、输出的通道数out_channel、卷积核的大小kernel_size、移动步幅stride、以及padding。
我们根据模型结构利用代码实现的时候,一定要弄清楚输入的通道数in_channel、输出的通道数out_channel、卷积核的大小kernel_size、移动步幅stride、以及padding。
# 神经网络模型 class Lin(nn.Module): def __init__(self): super(Lin, self).__init__() self.model = nn.Sequential( # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(3, 32, 5, 1, 2), # 池化层 nn.MaxPool2d(2), # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(32, 32, 5, 1, 2), # 最大池化 nn.MaxPool2d(2), # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(32, 64, 5, 1, 2), # 最大池化 nn.MaxPool2d(2), # 将所有特征平铺 nn.Flatten(), # 线性层 nn.Linear(1024, 64), # 线性层:最终得到10个输出 nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
我们实现了模型,可以提前验证一下模型是否正确。我们可以给定相应的输入,来查看输出的结果的shape是否符合预期。(这里需要注意一下注释中补充的知识点)
"""
if __name__ == '__main__':的作用
一个python文件通常有两种使用方法,第一是作为脚本直接执行,
第二是 import 到其他的 python 脚本中被调用(模块重用)执行。
因此 if __name__ == 'main': 的作用就是控制这两种情况执行代码的过程,
在 if __name__ == 'main': 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,
而 import 到其他脚本中是不会被执行的
"""
if __name__ == '__main__':
lin = Lin()
# 64个数据,每个数据三通道,每个通道大小为32*32
input = torch.ones((64, 3, 32, 32))
output = lin(input)
print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.训练过程
实现模型之后,我们需要选择优化器、设置一下训练轮次等参数
# 创建网络模型 lin = Lin() # 损失函数 loss_fn = nn.CrossEntropyLoss() # 优化器:选择随机梯度下降 learn_rate = 1e-2 optimizer = torch.optim.SGD(lin.parameters(), lr=learn_rate) # 设置训练网络的一些参数 # 记录训练的次数 total_train_step = 0 # 记录测试的次数 total_test_step = 0 # 训练的轮次 epoch = 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
并且要将我们的训练时候的效果进行可视化,我们引入tensorboard,将我们训练过程中loss的变化绘制成图表。一定要注意,因为我们是采用mini-batch的训练方法,所以每次进行模型优化之前,我们需要将梯度清零,避免梯度进行累加
# 添加tensorboard writer = SummaryWriter("logs") for i in range(epoch): print("====================第{}轮训练开始了=====================".format(i + 1)) # 训练步骤开始 lin.train() for data in train_dataloader: imgs, targets = data outputs = lin(imgs) loss = loss_fn(outputs, targets) # 利用优化器优化模型 # 这里一定要要将梯度清零,因为采用的是mini-batch的训练方式,避免梯度累加 optimizer.zero_grad() loss.backward() optimizer.step() total_train_step = total_train_step + 1 # 每训练100次再将loss打印出来 if total_train_step % 100 == 0: print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) writer.add_scalar("train_loss", loss.item(), total_train_step)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4.测试集验证
我们在每个epoch训练完成之后,就利用训练好的模型在测试集上经行验证,查看模型表现的表现。
# 测试步骤开始 lin.eval() total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data outputs = lin(imgs) loss = loss_fn(outputs, targets) # loss是tensor数据类型,loss.item()可以将loss化为数值类型 total_test_loss = total_test_loss + loss.item() # 用来查看测试集上的正确率 accuracy = (outputs.argmax(1) == targets).sum() total_accuracy = total_accuracy + accuracy print("整体测试集上面的Loss:{}".format(total_test_loss)) print("整体测试集上面的正确率:{}".format(total_accuracy/test_data_size)) writer.add_scalar("test_loss", total_test_loss, total_test_step) writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step) # with下面的for循环完成一次代表测试完成了一次 total_test_step = total_test_step + 1 writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
5.模型的保存
模型的保存常见的两种方式,方式一保存了整个模型的结构和模型的参数,而方式二是采用了字典的方式保存了模型的参数
# 保存方式一:模型结构+参数
torch.save(vgg16,"vgg16_method1.pth")
# 保存方式二(官方推荐):模型参数
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
- 1
- 2
- 3
- 4
- 5
对两种方式保存模型进行读取也有所差别:
# 保存方式一加载模型
model = torch.load("vgg16_method1.pth")
print(model)
# 保存方式2加载模型
vgg16 = torchvision.models.vgg16
vgg16.load_state_dict()
model = torch.load("vgg16_method2.pth")
print(model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
上面为模型保存和加载的知识内容补充,在本实验中,我们在测试代码后面加入保存的代码内容,这样我们就可以将每一个训练轮次后的模型保存下来。
# 对模型进行保存
torch.save(lin, "lin_{}.pth".format(i))
print("模型已保存")
- 1
- 2
- 3
6.GPU训练
gpu训练只能在模型、损失函数、数据(输入、标注)三个地方使用

引入gpu进行训练两种方式,下面代码展示的引入方式一
""" 在这种方式下引入cuda,如果电脑是没有gpu的话,会出现报错情况,要想防止报错情况,那么就需要在每一个 使用cuda的地方进行一次判断 if torch.cuda.is_available(): """ lin = Lin() # =====================这里可以用cuda=========================== lin = lin.cuda() # 损失函数 loss_fn = nn.CrossEntropyLoss() # =====================这里可以用cuda=========================== loss_fn = loss_fn.cuda() for i in range(epoch): print("====================第{}轮训练开始了=====================".format(i + 1)) # 训练步骤开始 lin.train() for data in train_dataloader: imgs, targets = data # =====================这里可以用cuda=========================== imgs = imgs.cuda() targets = targets.cuda() outputs = lin(imgs) loss = loss_fn(outputs, targets) # 测试步骤开始 lin.eval() total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data # =====================这里可以用cuda=========================== imgs = imgs.cuda() targets = targets.cuda() # 后续代码删除
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
使用gpu训练的方式二:这种方式更改起来要方便得多
""" 使用gpu训练模型的方式二 """ # 定义训练设备:cpu、cuda device = torch.device("cuda") lin = Lin() # =====================这里可以用cuda=========================== lin = lin.to(device) # 损失函数 loss_fn = nn.CrossEntropyLoss() # =====================这里可以用cuda=========================== loss_fn = loss_fn.to(device) for i in range(epoch): print("====================第{}轮训练开始了=====================".format(i + 1)) # 训练步骤开始 lin.train() for data in train_dataloader: imgs, targets = data # =====================这里可以用cuda=========================== imgs = imgs.to(device) targets = targets.to(device) # 测试步骤开始 lin.eval() total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data # =====================这里可以用cuda=========================== imgs = imgs.to(device) targets = targets.to(device)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
7.模型验证(测试)
我们随机在网上找一张图片,然后运用训练好的模型对该图片进行预测。该数据集十个分类项为下图所示:

我利用之前训练了10次得模型对一张狗的图片进行预测(训练1次后的代码正确率有60%多了),代码如下所示:
import torch import torchvision from PIL import Image from torch import nn image_path = "image/dog.jpg" image = Image.open(image_path) print(image) transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()]) image = transform(image) print(image.shape) class Lin(nn.Module): def __init__(self): super(Lin, self).__init__() self.model = nn.Sequential( # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(3, 32, 5, 1, 2), # 池化层 nn.MaxPool2d(2), # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(32, 32, 5, 1, 2), # 最大池化 nn.MaxPool2d(2), # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(32, 64, 5, 1, 2), # 最大池化 nn.MaxPool2d(2), # 将所有特征平铺 nn.Flatten(), # 线性层 nn.Linear(1024, 64), # 线性层:最终得到10个输出 nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x model = torch.load("train_epoch/lin_9.pth",map_location=torch.device('cpu')) print(model) image = torch.reshape(image, (1, 3, 32, 32)) model.eval() with torch.no_grad(): output = model(image) print(output) print(output.argmax(1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
总结
以上就是整个模型的验证过程,对于pytorch的使用有了一定的了解。自己的能力十分有限,非常感谢网上各位大佬的分享,让小白的学习之路稍加平坦了一些,不过自己还需要好好加油,要学习的东西还有很多!
最后将完整的代码附着在后面,希望对大家有所帮助!
train.py
import torch import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from model import * train_data = torchvision.datasets.CIFAR10(root="../dataset_cifar", train=True, transform=torchvision.transforms.ToTensor(), download=True) test_data = torchvision.datasets.CIFAR10(root="../dataset_cifar", train=False, transform=torchvision.transforms.ToTensor(), download=True) # 数据大小 train_data_size = len(train_data) test_data_size = len(test_data) # format可以将{}替换为函数内部的内容 print("训练数据集的长度为{}".format(train_data_size)) print("测试数据集的长度为{}".format(test_data_size)) # 利用DataLoader加载数据集 train_dataloader = DataLoader(train_data, batch_size=64) test_dataloader = DataLoader(test_data, batch_size=64) # 创建网络模型 lin = Lin() # 损失函数 loss_fn = nn.CrossEntropyLoss() # 优化器:选择随机梯度下降 learn_rate = 1e-2 optimizer = torch.optim.SGD(lin.parameters(), lr=learn_rate) # 设置训练网络的一些参数 # 记录训练的次数 total_train_step = 0 # 记录测试的次数 total_test_step = 0 # 训练的轮次 epoch = 10 # 添加tensorboard writer = SummaryWriter("logs") for i in range(epoch): print("====================第{}轮训练开始了=====================".format(i + 1)) # 训练步骤开始 lin.train() for data in train_dataloader: imgs, targets = data outputs = lin(imgs) loss = loss_fn(outputs, targets) # 利用优化器优化模型 # 这里一定要要将梯度清零,因为采用的是mini-batch的训练方式,避免梯度累加 optimizer.zero_grad() loss.backward() optimizer.step() total_train_step = total_train_step + 1 # 每训练100次再将loss打印出来 if total_train_step % 100 == 0: print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) writer.add_scalar("train_loss", loss.item(), total_train_step) # 测试步骤开始 lin.eval() total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data outputs = lin(imgs) loss = loss_fn(outputs, targets) # loss是tensor数据类型,loss.item()可以将loss化为数值类型 total_test_loss = total_test_loss + loss.item() # 用来查看测试集上的正确率 accuracy = (outputs.argmax(1) == targets).sum() total_accuracy = total_accuracy + accuracy print("整体测试集上面的Loss:{}".format(total_test_loss)) print("整体测试集上面的正确率:{}".format(total_accuracy/test_data_size)) writer.add_scalar("test_loss", total_test_loss, total_test_step) writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step) # with下面的for循环完成一次代表测试完成了一次 total_test_step = total_test_step + 1 # 对模型进行保存 torch.save(lin, "lin_{}.pth".format(i)) print("模型已保存") writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
model.py
from torch import nn import torch # 神经网络模型 class Lin(nn.Module): def __init__(self): super(Lin, self).__init__() self.model = nn.Sequential( # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(3, 32, 5, 1, 2), # 池化层 nn.MaxPool2d(2), # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(32, 32, 5, 1, 2), # 最大池化 nn.MaxPool2d(2), # 5*5卷积:in_channel;out_channel;kernel_size;stride;padding nn.Conv2d(32, 64, 5, 1, 2), # 最大池化 nn.MaxPool2d(2), # 将所有特征平铺 nn.Flatten(), # 线性层 nn.Linear(1024, 64), # 线性层:最终得到10个输出 nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x # 用来验证我们上面网络模型的正确性:就是给定一个输入,看看通过网络模型之后的输出规格是否符合结果 """ if __name__ == '__main__':的作用 一个python文件通常有两种使用方法,第一是作为脚本直接执行, 第二是 import 到其他的 python 脚本中被调用(模块重用)执行。 因此 if __name__ == 'main': 的作用就是控制这两种情况执行代码的过程, 在 if __name__ == 'main': 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行, 而 import 到其他脚本中是不会被执行的 """ if __name__ == '__main__': lin = Lin() # 64个数据,每个数据三通道,每个通道大小为32*32 input = torch.ones((64, 3, 32, 32)) output = lin(input) print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50



