
热门标签
热门文章
- 1git commit相关命令_git commit -a
- 2SpringBoot-并发执行定时任务配置_taskregistrar.setscheduler(executors.newscheduledt
- 3TX2上使用tensorrt加速推理onnx_trt_engine_datatype=trt.datatype.float
- 4Docker安装——Ubuntu (Jammy 22.04)_ubuntu jammy docker
- 5Ubuntu20.04下载t265 深度摄像头的驱动realsense SDK(安装部分)_ubuntu20.04 t265
- 6如何在飞腾平台上安装Ubuntu操作系统_飞腾d2000安装ubuntu
- 7Flask Web开发 博客实例(一)flask框架理解_flask web blog
- 8嵌入式物联网设计水稻田智能灌溉系统实现
- 9基于STM32的智能循迹避障小车_stm32智能小车循迹程序
- 10android 照片加水印,Android 实现图片加水印或logo
当前位置: article > 正文
神经网络完整模型训练套路_argmax(1)
作者:程序自动化专家 | 2024-01-31 20:04:01
赞
踩
argmax(1)
#导入
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 把model中的所有引入,model中有模型
from model import *
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1、准备数据集
# 1、准备数据集:训练数据集,测试数据集
train_data = torchvision.datasets.CIFAR10("./dataset_ts", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10("./dataset_ts", train=True, transform=torchvision.transforms.ToTensor(), download=True)
# lenth 长度——获取数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2、利用DataLoader来加载数据集
# 格式化字符串的写法:如果train_data_size=10,
# 2、利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64) #相当于将数据打包为一个batch一个batch的加载
test_dataloader = DataLoader(test_data, batch_size=64)
- 1
- 2
- 3
- 4
- 5
3、搭建神经网络模型
tui = Tui()
- 1
CIFAR 10 model结构:
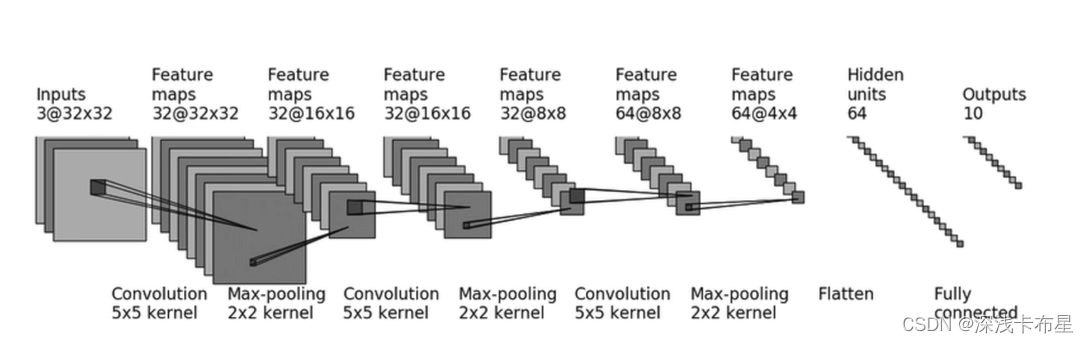
model.py文件:
# 搭建神经网络 import torch from torch import nn class Tui(nn.Module): def __init__(self) -> None: super().__init__() self.model = nn.Sequential( nn.Conv2d(3, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 64, 5, 1, 2), nn.MaxPool2d(2), nn.Flatten(), nn.Linear(64 * 4 * 4, 64), nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x # main函数 if __name__ == '__main__': tudui = Tui() # 验证网络模型的正确性,创造一个输入尺寸,判断输出尺寸是不是我们想要的 input = torch.ones((64, 3, 32, 32)) # batchsize=64,channel=3,尺寸32*32 output = tudui(input) print(output.shape)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4、定义损失函数
loss_fn = nn.CrossEntropyLoss() #交叉熵损失函数多用于分类问题
- 1
5、定义优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tui.parameters(), lr=learning_rate) #params:网络模型
- 1
- 2
6、设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
- 1
- 2
- 3
- 4
- 5
- 6
#添加tensorboard
writer = SummaryWriter("logs_train")
- 1
7、训练
- optimizer.step() 是优化器对 的值进行更新,以随机梯度下降SGD为例:学习率(learning rate, lr)来控制步幅,即:
x = x - lr * x.grad,减号是由于要沿着梯度的反方向调整变量值以减少Cost。
# 设置训练轮数
for i in range(epoch): #大循环!!!!
print("---------第{}轮训练开始---------".format(i+1))
- 1
- 2
- 3
# 7、训练步骤开始: # 并不是说把网络设置为训练模式才可以训练 # 作用是:当模块中有Dropout, BatchNorm层时,一定要调用他,对其特定模块起作用 tui.train() for data in train_dataloader: #从dataloader中一个batch一个batch的取数据 imgs, targets = data outputs = tui(imgs) #真实输出 # ①计算真实输出与目标之间的误差 loss = loss_fn(outputs, targets) # ②优化器调优 优化模型 optimizer.zero_grad() #梯度清零 loss.backward() #反向传播, 得到每个参数的梯度 optimizer.step() #对每个梯度进行优化 total_train_step = total_train_step + 1 #记录训练次数,一个batch一次 if total_train_step % 100 == 0: print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) #.item()作用:将tensor型输出为整数 writer.add_scalar("train_loss", loss.item(), total_train_step)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
8、测试
- model.eval(): 的作用是启用 Batch Normalization 和 Dropout。
在模型中,我们通常会加上Dropout层和batch normalization层。在模型预测阶段,我们需要将这些层设置到预测模式,model.eval()就是帮我们一键搞定的,如果在预测的时候忘记使用model.eval(),会导致不一致的预测结果。 - model.train(): 的作用是启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
-
torch.no_grad(): 通常在实际代码中,在预测阶段,也会加上
torch.no_grad()来关闭梯度的计算。那么,预测阶段的代码基本要这样写 -
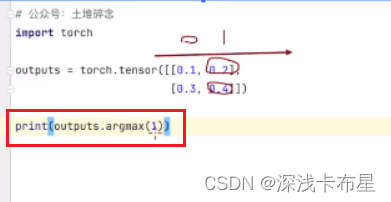
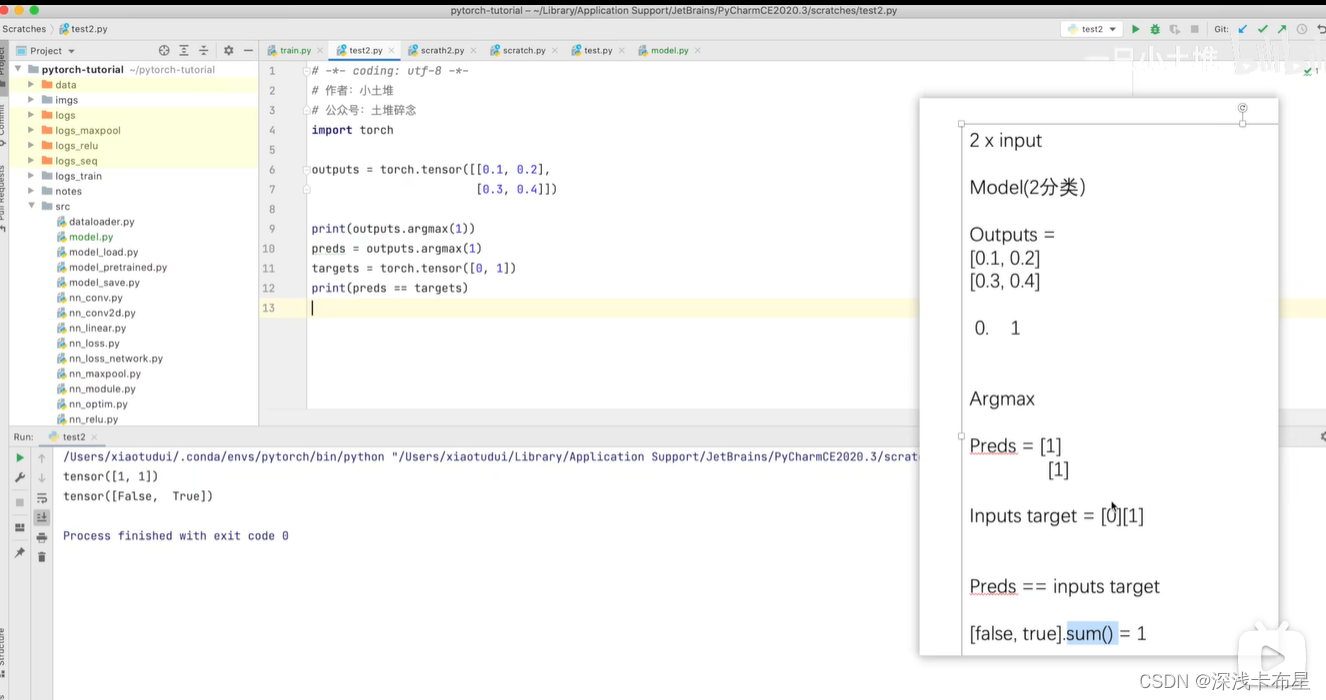
accuracy=(outputs.
argmax(1)==targets).sum(): 求每个对应位置最大的值和targets比较返回true或false。利用sum求和。 -
在分类问题当中,通常需要有正确率作为分类评判的标准。
当argmax(1)时,是 横向 查找比较数据的大小索引,取出最大值所在的位置也就是说,如果是为1,则返回每一行最大值的索引
当argmax(0)时,是纵向查找比较数据的大小索引,取出最大值所在的位置 。也就是说,如果是为0,则返回每一列最大值的索引

# 如何知道模型又没有训练好————进行测试,在测试机上跑一遍, # 用测试数据集上的损失或正确率评估模型有没有训练好 # 8、测试 # 模型中如果有BatchNormalization和Dropout,在预测时使用model.eval()后会将其关闭以免影响预测结果。 # (1)设置测试参数 total_test_loss = 0 #总损失 total_accuracy = 0 #整体正确率 # (2)测试步骤开始 tui.eval() # 将网络模型中的梯度消失,只需要测试,不需要对梯度进行调整,也不需要利用梯度来优化 with torch.no_grad(): for data in test_dataloader: #从测试集中取数据 imgs, targets= data outputs = tui(imgs) loss = loss_fn(outputs, targets) #计算损失 total_test_loss = total_test_loss + loss.item() #计算总损失 # 求每个对应位置最大的值和targets比较返回true或false。利用sum求和 accuracy = (outputs.argmax(1) == targets).sum() total_accuracy = total_accuracy + accuracy #计算测试正确的总个数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
9、计算测试集的loss,正确率,以此展现训练网络在测试集上的效果
# 9、计算测试集的loss,正确率,以此展现训练网络在测试集上的效果
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size)) #正确率为测试正确的个数/测试集总个数
# 将结果在tensorboard上展示
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
writer.add_scalar("test_loss", total_test_loss, total_test_step)
total_test_step = total_test_step + 1
torch.save(tui, "tui_{}.pth".format(i)) #将模型保存指定路径中
print("模型已保存")
writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
完整程序:
model.py文件:
# 搭建神经网络 import torch from torch import nn class Tui(nn.Module): def __init__(self) -> None: super().__init__() self.model = nn.Sequential( nn.Conv2d(3, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 32, 5, 1, 2), nn.MaxPool2d(2), nn.Conv2d(32, 64, 5, 1, 2), nn.MaxPool2d(2), nn.Flatten(), nn.Linear(64 * 4 * 4, 64), nn.Linear(64, 10) ) def forward(self, x): x = self.model(x) return x # main函数 if __name__ == '__main__': tudui = Tui() # 验证网络模型的正确性,创造一个输入尺寸,判断输出尺寸是不是我们想要的 input = torch.ones((64, 3, 32, 32)) # batchsize=64,channel=3,尺寸32*32 output = tudui(input) print(output.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
train.py文件:
import torch import torchvision.datasets from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 把model中的所有引入,model中有模型 from model import * # 1、准备数据集:训练数据集,测试数据集 train_data = torchvision.datasets.CIFAR10("./dataset_ts", train=True, transform=torchvision.transforms.ToTensor(), download=True) test_data = torchvision.datasets.CIFAR10("./dataset_ts", train=True, transform=torchvision.transforms.ToTensor(), download=True) # lenth 长度——获取数据集的长度 train_data_size = len(train_data) test_data_size = len(test_data) print("训练数据集的长度为:{}".format(train_data_size)) print("测试数据集的长度为:{}".format(test_data_size)) # 格式化字符串的写法:如果train_data_size=10, # 2、利用DataLoader来加载数据集 train_dataloader = DataLoader(train_data, batch_size=64) #相当于将数据打包为一个batch一个batch的加载 test_dataloader = DataLoader(test_data, batch_size=64) # 3、搭建神经网络模型 tui = Tui() # 4、定义损失函数 loss_fn = nn.CrossEntropyLoss() #交叉熵损失函数多用于分类问题 # 5、定义优化器 learning_rate = 1e-2 optimizer = torch.optim.SGD(tui.parameters(), lr=learning_rate) #params:网络模型 # 6、设置训练网络的一些参数 # 记录训练的次数 total_train_step = 0 # 记录测试的次数 total_test_step = 0 # 训练的轮数 epoch = 10 # 添加tensorboard writer = SummaryWriter("logs_train") # 设置训练轮数 for i in range(epoch): print("---------第{}轮训练开始---------".format(i+1)) # 7、训练步骤开始: # 并不是说把网络设置为训练模式才可以训练 # 作用是:当模块中有Dropout, BatchNorm层时,一定要调用他,对其特定模块起作用 tui.train() for data in train_dataloader: #从dataloader中一个batch一个batch的取数据 imgs, targets = data outputs = tui(imgs) #真实输出 # ①计算真实输出与目标之间的误差 loss = loss_fn(outputs, targets) # ②优化器调优 优化模型 optimizer.zero_grad() #梯度清零 loss.backward() #反向传播, 得到每个参数的梯度 optimizer.step() #对每个梯度进行优化 total_train_step = total_train_step + 1 #记录训练次数,一个batch一次 if total_train_step % 100 == 0: print("训练次数:{},Loss:{}".format(total_train_step, loss.item())) #.item()作用:将tensor型输出为整数 writer.add_scalar("train_loss", loss.item(), total_train_step) # 如何知道模型又没有训练好————进行测试,在测试机上跑一遍, # 用测试数据集上的损失或正确率评估模型有没有训练好 # 8、测试 # 模型中如果有BatchNormalization和Dropout,在预测时使用model.eval()后会将其关闭以免影响预测结果。 # (1)设置测试参数 total_test_loss = 0 #总损失 total_accuracy = 0 #整体正确率 # (2)测试步骤开始 tui.eval() # 将网络模型中的梯度消失,只需要测试,不需要对梯度进行调整,也不需要利用梯度来优化 with torch.no_grad(): for data in test_dataloader: #从测试集中取数据 imgs, targets= data outputs = tui(imgs) loss = loss_fn(outputs, targets) #计算损失 total_test_loss = total_test_loss + loss.item() #计算总损失 # 求每个对应位置最大的值和targets比较返回true或false。利用sum求和 accuracy = (outputs.argmax(1) == targets).sum() total_accuracy = total_accuracy + accuracy #计算测试正确的总个数 # 9、计算测试集的loss,正确率,以此展现训练网络在测试集上的效果 print("整体测试集上的Loss: {}".format(total_test_loss)) print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size)) #正确率为测试正确的个数/测试集总个数 # 将结果在tensorboard上展示 writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step) writer.add_scalar("test_loss", total_test_loss, total_test_step) total_test_step = total_test_step + 1 torch.save(tui, "tui_{}.pth".format(i)) #将模型保存指定路径中 print("模型已保存") writer.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
参考:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/51933
推荐阅读

相关标签

