
- 1Git常用命令总结_git --stat
- 2王垠:对 Go 语言的综合评价_王垠golang
- 3SSH远程连接登陆并且传输文件 --->>> ubuntu->ubuntu_ssh上传文件夹到ubuntu
- 4LeetCode——链表重复元素问题、重排链表_两个链表找到重复数
- 52020年第十届C/C++ B组第一场蓝桥杯省赛真题_c++蓝桥杯国赛题目
- 6多平台音视频下载软件工具 - VidJuice UniTube下载
- 7MySQL锁定状态查看命令
- 8Django笔记七之ManyToMany和OneToOne介绍_django manytomany
- 9SampleOnnxMnist_readme_自用_if [ ! -d ../../bin/chobj/sampleonnxmnist/sampleon
- 10【LM】轻量化BERT
基于windows和git学习shell(与linux下一致)_git bash能运行shell脚本吗?
赞
踩
目录
1 运行shell脚本的三种方式
(1)./test.sh
(2)sh test.sh
(3)/bin/sh test.sh
(4)source test.sh 或者 直接一个 . test.sh
正常来说,使用第一种就可以了。
2 变量声明
2.1 局部变量
name=haha 这种形式,中间不要有空格。
多个字符可以使用这样的形式 name="haha good" 或者 name='haha good'
2.2 全局变量
先声明成局部变量,然后使用export关键字进行导出成全局变量
- my_var=hello
- export my_var
在外层定义的全局变量在内层更改的话不会影响外层。(就是子shell里面做的更改不会影响父shell)。
变量默认都是字符串类型的,要是想要运算的话,声明的时候可以
使用 a=$((1+5)),这种$加上双括号的形式
使用a=$[1+5],这种$加上一层中括号的形式
可以使用 unset my_var 撤销变量,但是不能unset只读变量
2.3 只读变量
readonly b=5

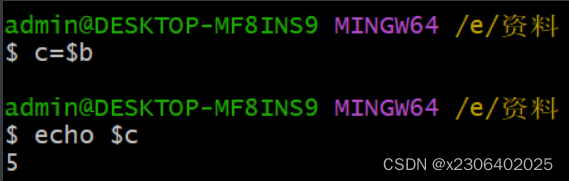
变量间的复制,并不是地址复制,单纯的值复制
2.4 特殊变量
2.4.1 $n
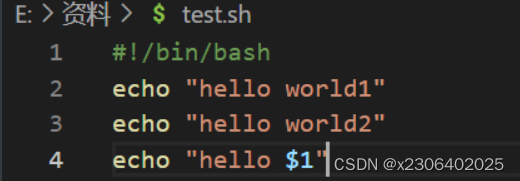
通过 $n的形式,获取执行.sh文件的时候,后面跟的第n个参数。n超过9之后用{}括起来,就像${10}。$0代表当前脚本

2.4.2 $#
$# 用于获取输入参数的个数,常用于循环,判断参数个数是否正确以及加强脚本的健壮性
2.4.3 $*、$@
这两个都是代表命令行的所有参数,只不过$*把所有参数看成一个整体,$@把每一个参数区分对待,就可以使用循环这种操作。
2.4.4 $?
功能描述:最后一次执行的命令(或者说就是紧挨着的上一次命令)的返回状态。如果这个变量值为0,证明上一个命令正确的执行;如果这个变量的值为非0(具体是哪个数,由命令自己来决定),则证明上一个命令执行的不正确了。
3运算符
使用 expr (未简化前)
- expr 1 + 2
- expr 3 - 2
- expr 5 \* 2
3.1 基本语法
$(()) 或 $[] 就是上文提到的
- $[5*10]
- a=$[6+8]
- a=$[4+5]
- #也可以使用命令替换
- a=$(expr 2 + 4)
- a=`expr 2 + 4`
4条件判断
4.1 基本语法
-
test condition condition中的判断符号前后要有空格,否则会将里面的表达式作为一个整体,非空就直接为真了
-
[ condition ] (注意condition前后要有空格,同时判断符号也要注意空格问题)
注意:条件非空即为true,[hello]返回true,[]返回false
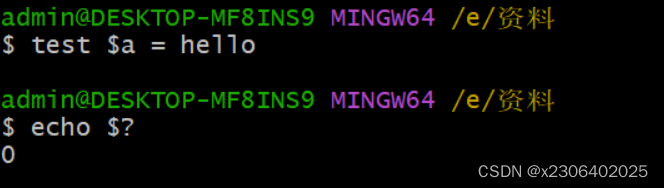
举例:可以看到使用 $?得到的值是0,表示上一个命令正确。
否则的话返回的就是非0值,表示上一次命令不正确,也就是判断失败了。
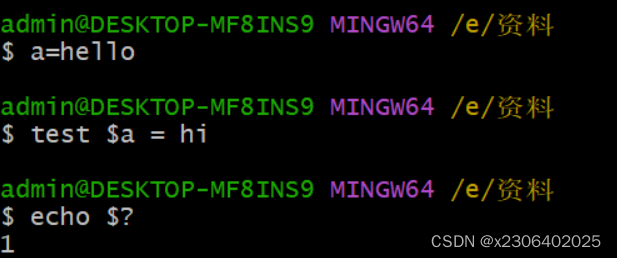
也可以使用第二种方法,这里注意就是,[ ]符号里面的空格问题。

4.2 常用的判断条件
4.2.1 字符串等非数值比较
= 等于判断
!= 不等于判断
4.2.2 两个整数之间的比较
-eq 等于(equal) -ne 不等于(not equal)
-lt 小于(less than) -le 小于等于(less equal)
-gt 大于(greater than) -ge 大于等于(greater equal)

4.2.3 按照文件权限进行判断
-r 有读的权限 (read)
-w 有写的权限 (write)
-x 有执行的权限 (execute)

4.2.4 按照文件类型进行判断
-e 文件存在(existence)
-f 文件存在并且是一个常规文件(file)
-d 文件存在并且是一个目录 (directory)

4.2.5 多条件判断
&&表示前一条命令执行成功时,才执行后一条命令。
||表示上一条命令执行失败后,才执行下一条命令

上面的语句功能类似于 if ... else ...
5 流程控制
5.1 if判断
基本语法:
5.1.1 单分支
- if [ 条件判断 ]
- then
- 程序
- fi
5.1.2 多分支
- if [ 条件判断 ]
- then
- 程序
- elif [ 条件判断 ]
- then
- 程序
- else
- 程序
- fi
举例:
- #!/bin/bash
- age=$1
- if [ $age -ge 20 ] && [ $age -lt 30 ]
- then echo "年轻人"
- elif [ $age -ge 30 ] && [ $age -lt 50 ]
- then echo "青年人"
- else echo "老年人"
- fi

像上面这种多条件的要是不分括号的话要使用 -a 或者-o 来连接。(这里的a表示 and,o表示or)
如下所示。
- #!/bin/bash
- age=$1
- if [ $age -ge 20 ] && [ $age -lt 30 ]
- then echo "年轻人"
- elif [ $age -ge 30 ] && [ $age -lt 50 ]
- then echo "青年人"
- else echo "老年人"
- fi
-
- age=$2
- if [ $age -gt 20 -a $age -lt 30 ]
- then echo 年轻人
- elif [ $age -ge 30 -a $age -lt 50 ]
- then echo 中年人
- else echo 老年人
- fi


5.2 case语句
5.2.1 基本语法
- case $变量名 in
- "值1")
- 如果变量的值等于值1,执行当前
- ;;
- "值2")
- 如果变量的值等于值2,执行当前
- ;;
- ...省略其他分支...
- *)
- 如果变量的值都不是以上的值,则执行此
- ;;
- esac
注意事项:
-
case行尾必须为单词 in,每一个模式匹配必须以右括号 ")"结束
-
双分号" ;; "表示命令序列结束,相当于java中的break
-
最后的 " *)"表示默认模式,相当于java中的default
举例:
- #!/bin/bash
- case $1 in
- 1) echo one
- ;;
- 2) echo two
- ;;
- *) echo moren
- esac

5.3 for循环
5.3.1 基本语法1
for((初始值;循环控制条件;变量变化))
do
程序
done
- #!/bin/bash
- num=$1
- for((num;num<10;num++))
- do
- echo "haha $num"
- done

注意:如果程序里面要进行数值运算的话,要使用 $(()) 或者 $[],并且拿取数值要使用$开头。此处前文提到过。并且这里面没有使用-lt这种运算符,是因为使用了(()),在这里面是可以使用数学运算符的。
5.3.2 基本语法2
从后面的值里面依次遍历去进行处理
for 变量 in 值1 值2 值3...
do
程序
done
举例:
- #!/bin/bash
- for num in $1 $2 $3
- do
- echo "hello $num"
- done

补充:{}表示序列,{1..100} 就表示从1到100的序列
for num in {1..5}
do
echo "hello $num"
done
这里可以区别下$@和$*。如下
- for num in $@
- do
- echo $num
- done
-
- for num in $*
- do
- echo $num
- done

可以看出这种用法,两者并没有区别。但是如果加上双引号,就会有不同。
- for num in "$@"
- do
- echo $num
- done
-
- for num in "$*"
- do
- echo $num
- done

5.4 while循环
5.4.1 基本语法
while [判断条件]
do
程序
done
举例:
- #!/bin/bash
- # 从1加到100
- num=1
- count=0
- while [ $num -le 100 ]
- do
- count=$[ $num + $count ]
- num=$[ $num + 1 ]
- # 也可以人性化的写法,加上let打头的话,就可以像其他语法一样使用了
- # 但是这种方式要注意空格问题
- # let count=num+count
- # let num++
- done
- echo $count

6 read读取控制台输入
6.1 基本语法
区别于之前的从控制台读取,类似 $@ $*之类的,这类是在脚本执行的时候就将参数输入。这里是一种交互式的读取,可以在程序执行过程中读取参数。
read (选项) (参数)
-
选项:
-p:指定读取值时候的提示符 promt:提示符
-t:制定读取值时等待的时间(秒)。如果-t不加表示一直等待,超时之后就会自动退出
-
参数:
变量:指定读取值得变量名
举例:
- #!/bin/bash
- # 功能:在7秒钟内,从控制台读取一个参数,并将参数存储到变量 var 中,然后再输出
- read -t 7 -p "请在7秒钟之内输入参数:" var
- echo $var

可以看出执行shell脚本后,会出现下面界面。等待控制台输入参数。这里输入一个参数3,可以查看到结果如下:

也可以同时读取多个参数,如下
- #!/bin/bash
- # 功能:从控制台输入两个参数,并输出
- read -p "请输入参数:" var1 var2
- echo $var1
- echo $var2

7 函数
7.1 系统函数
7.1.1 basename
1.基本语法
basename [string / pathname] [suffix]
功能描述:basename命令会删除掉所有的前缀包括最后一个 ('/')字符,然后将字符串显示出来。basename可以理解为取路径里的文件名称
选项:
suffix为后缀,如果suffix被定义了,basename会将pathname或者string中的suffix去掉
2.举例

补充:
- #!/bin/bash
- # $() 是命令替换 ,date是一个系统函数 +%s表示时间格式是时间戳的形式
- filename1="$1"_log_$(date +%s)
- filename2=$1_log_$(date +%s)
- filename3=$1_log_$(date)
- echo $filename1
- echo $filename2
- echo $filename3

7.1.2 dirname
1.基本语法
dirname 文件绝对路径名
功能描述:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分)。dirname可以理解为去文件路径的绝对路径名称
2.举例

可以看出dirname和basename有点互补的意思,如下。

7.2 自定义函数
基本语法
[ function ] funcname[()]
{
action;
[return int;]
}
经验技巧
-
必须在调用函数的地方之前,先声明函数,shell脚本是逐行运行的。不会像其他语言一样先编译
-
函数返回值只能通过$?系统变量获得,可以显示加:return返回。如果不加,将会以最后一条·命令运行结果作为返回值。return 后跟数值 n(0-255)
举例
- #!/bin/bash
-
- function add(){
- s=$[$1+$2]
- #也可使用下面的运算方式
- # let s=$1+$2
- echo $s
- }
- read -p "输入两个求和参数:" var1 var2
-
- # 调用函数,和调用shell脚本类似
- add $var1 $var2

- function add2(){
- s=$[$1+$2]
- return $s
- }
- read -p "输入两个求和参数:" var1 var2
-
- # 调用函数,和调用shell脚本类似
- add2 $var1 $var2

可以用 $?来接收返回值,但这里就会有一个问题,$?只能接受0-255之间的整数值,太受限制了。所以可以使用别的方式来解决问题。
- function add3(){
- s=$[$1+$2]
- echo $s
- }
- read -p "输入两个求和参数:" var1 var2
- sum=$(add3 $var1 $var2)
- # 这样就可以拿到函数的返回值,然后再进行其他操作
- echo $[$sum*$sum]

8 正则表达式入门
在linux中,grep、sed、awk等文本处理工具都支持通过正则表达式进行模式匹配
8.1 常规匹配

查看当前目录下,匹配for的所有文件
8.2 常用特殊字符
^ 用来匹配一行的开头; ^a 表示以a开头

查看文件last.sh中以t开头的行
$ 用来表示一行的结束; a$表示以a结尾
. 匹配一个任意字符
比如 cat /e/资料/test.sh |grep a..s 用来匹配文件中以a开头,s结尾的4个字符的字符串
不单独使用,和上一个字符连用,表示匹配上一个字符0到多次
例如, grep| he*llo 会匹配 hllo hello heello heeello ...
字符区间 [ ]
[ ] 表示匹配某个范围内的一个字符,例如
[6,8] 匹配6或者8 也可写成[68],功能是一样的
[0-9] 匹配0-9之间的数字
[0-9]* 匹配任意长度的数字字符串
[a-z] 匹配a-z之间的字符
[a-z]* 匹配任意长度的字母字符串
[a-c,e-f] 匹配a-c或者e-f之间的任意字符
对一些特殊字符匹配要转义,比如匹配一个文件中以$结尾
cat /e/资料/last.sh |grep '\$'
举例使用:去匹配手机号
需求:第一位为1,第二位在34578之内,剩下的9位随意

或者加上-E表示grep支持扩展的正则表达式

9文本处理工具
9.1 cut
cut命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。
基本用法
cut [选项参数] filename
说明:默认分隔符是制表符
选项参数说明
| 选项参数 | 功能 |
|---|---|
| -f | 列号,提取第几列 -f 1 选出第1列。可以使用1,3,5 这样正则选出1,3,5这几列。还可以使用 3-5选出3~5这几列。4- 选出4以及之后的列 |
| -d | 分隔符,按照指定分隔符分割列,默认是制表符 |
| -c | 按字符进行切割 后加n表示取第几列 比如 -c 1 |
举例
1数据准备

2切割cut.txt文件第一列

3切割第二、三列。(没有第三列所以只显示第二列)

4切割处guan

5选取系统PATH变量值

6切割ipconfig后打印的IP地址

9.2 awk
一个强大的文本分析工具,把文本逐行的读入,以空格为默认分隔符将每行切片,切开的部分在进行分析处理。
9.2.1 基本用法
awk [选项参数] ‘/pattern1/{action1} /pattern2/{action2} ...’ filename
pattern:表示awk在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
选项参数说明
| 选项参数 | 功能 |
|---|---|
| -F | 指定输入文件分隔符 |
| -v | 赋值一个用户定义变量 |
举例
搜索awk.txt文件以root关键字开头的所有行,并输出该行的第5列
awk.txt文件内容如下


也可以不用匹配直接对每行进行操作,类似于cut
9.2.2 awk内置变量
| 变量 | 说明 |
|---|---|
| FILENAME | 文件名 |
| NR | 已读的记录数(行号) |
| NF | 浏览记录的域的个数(切割后,列的个数) |
实例:
统计awk.txt文件名,每行的行号,每行的列数
使用awk解决切割ipconfig后打印的IP地址(可以类比上面的cut)
last 综合案例
1 归档文件
实际生产应用中,往往需要对重要数据进行归档备份
需求:实现一个每天对指定目录归档备份的脚本,输入一个目录文件(末尾不带/),将目录下所有文件按天归档保存,并将归档日期附加在归档文件名上,放在/root/archive下。
这里运用到了归档(打包)命令:tar 注意打包和压缩是有区别的
后面可以加上 -c 选项表示归档,加上 -z 选项表示同时进行压缩,得到的文件后缀名为 .tar.gz
-c:创建归档
-x:释放归档
-f:指定归档文件名称,必须放在所有选项的最后
-z、-j、-J:调用 .gz、.bz2、.xz 格式的工具进行处理
-t:显示归档中的文件清单
-C:指定释放路径
具体实现:
- #!/bin/bash
-
- # 首先判断输入参数个数是否为1
- if [ $# -ne 1 ]
- then
- echo "参数个数错误,应该输入一个参数作为归档的目录名"
- exit
- fi
-
- # 从输入参数获取目录名称
- if [ -d $1 ] #首先判断是不是一个存在的目录
- then
- echo
- else
- echo
- echo "目录不存在"
- exit #退出
- fi
-
- DIR_NAME=$(basename $1) #获取目录名
- DIR_PATH=$(cd $(dirname $1); pwd) #进入获取的绝对路径目录下
- # DIR_PATH=$(dirname $1)
-
-
- # 获取当前日期
- DATE=$(date +%y%m%d)
- # 定义生成的归档文件名称
- FILENAME=after_${DIR_NAME}_$DATE.tar.gz
-
- DEST=/e/资料/after/$FILENAME
-
- # 开始归档目录文件
-
- echo "开始归档目录文件.."
- echo
-
- # tar 选项 需要归档的位置以及名称(理解为new) 被归档的文件(理解为old)
- tar -czf $DEST $DIR_PATH/$DIR_NAME
-
- # 判断是否归档成功
- if [ $? -eq 0 ]
- then
- echo
- echo "归档成功"
- echo "归档文件为:$DEST"
- echo
- else
- echo "归档失败"
- fi
-
- exit


可以做定时任务
crontab -l 查看当前有的定时任务
crontab -e 来做一个编辑
- #分 时 天 月 星期几
- #下面便是每天凌晨2点执行/e/资料目录下的脚本last.sh 脚本参数是 /e/资料/before
- 0 2 * * * /e/资料/last.sh /e/资料/before




