
- 1【C++入门】(纯)虚函数和多态、抽象类、接口_c++ 多态,虚函数 接口详解
- 2ORB-SLAM策略思考之RANSAC
- 3《硬件设计指南-从器件认知到手机基带设计》正式上市!
- 432个关于FPGA的学习网站_verilog刷题网站
- 5Python Selenium3 自动化测试实战:构建高效测试项目_selenium3.0平台级自动化测试框架综合实战
- 6【软考】系统集成项目管理工程师【总】_软考中级系统集成项目管理工程师
- 7STM32F103C8T6+LD3320语音识别模块智能灯控
- 8java小项目——点餐系统_java点餐系统
- 9考研机试 三元组
- 10嵌入式培训机构四个月实训课程笔记(完整版)-Linux ARM平台编程第一天-嵌入式系统概述(物联技术666)
Mysql 增删改查(一) —— 查询(条件查询where、分页limits、排序order by、分组 group by)_where order by limit
赞
踩
查询 select 可以认为是四个基本操作中使用最为频繁的操作,然而数据量比较大的时候,我们不可能查询所有内容,我们一般会搭配其他语句进行查询:
- 假如要查询某一个字段的内容,可以使用 where
- 假如要查询前几条记录,可以使用 limit
- 假如要让查询结果,按照某种顺序显示,可以使用 order by
但是值得注意的是,当select 和上述三者的任意一个或者多个同时出现时,select 并非优先执行,不同语句之间的执行顺序存在优先级。
优先级的问题可以参考:select 与 where、order by、limit 子句执行优先级比较
目录
1、select
select 是最基本的查询,可以搭配 where、limit、order by 等语句使用,除此之外,查询时支持表达式的运算,select基本语法格式如下:
- select
- [distinct] {* | 字段名1,字段名2, ...}
- from 表名
- [where ...]
- [order by ...]
- [limit ...]
(1) 全列查询
全列查询:查询结果会展示所有字段的内容,可以通过附带条件语句来查询符合条件的记录。
- -- 展示exam_result表中的 “ 全部记录 ” 的全部字段内容
- select * from exam_result;
-
- -- 展示exam_result表中 “ id=1所在记录 ” 的全部字段内容
- select * from exam_result where id=1;

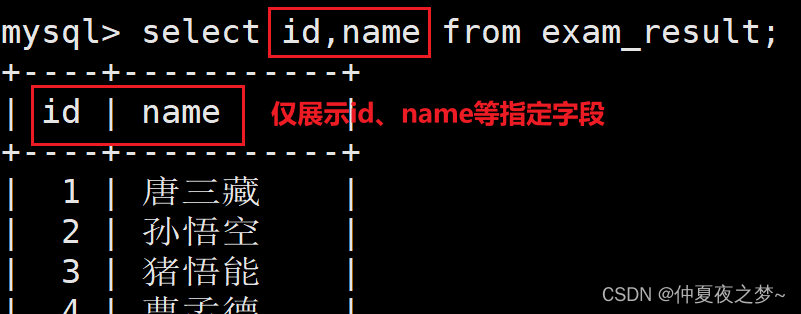
(2) 指定列查询
指定列查询:仅显示指定字段的内容
- -- 展示exam_result表中的 “ 全部记录 ” 的全部字段内容
- select * from exam_result;
-
- -- 展示exam_result表中 “ id=1所在记录 ” 的全部字段内容
- select * from exam_result where id=1;
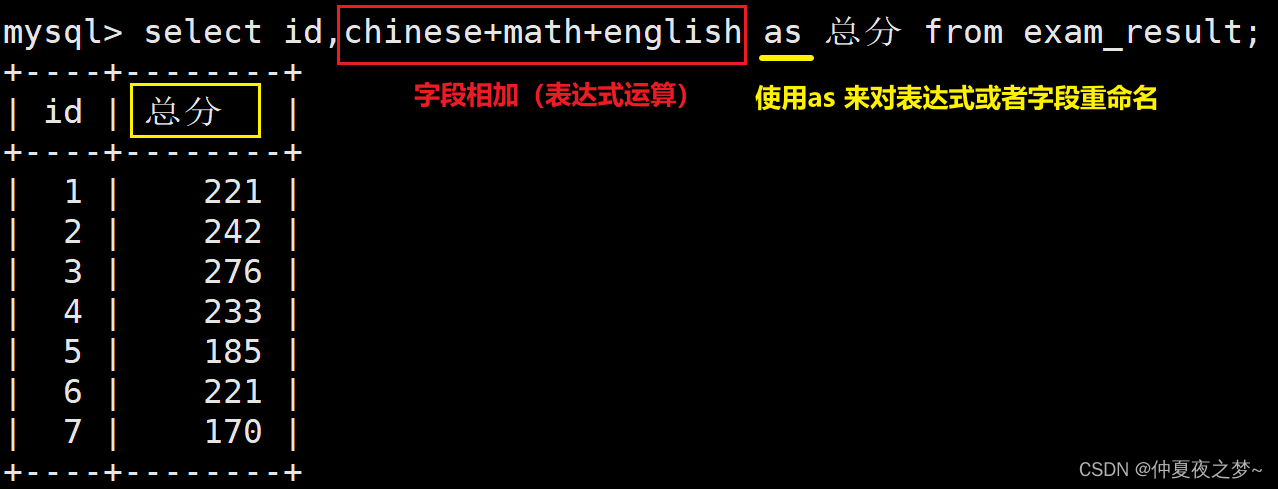
(3) 查询字段为表达式
查询时,字段支持四则运算,而且允许给表达式起别名
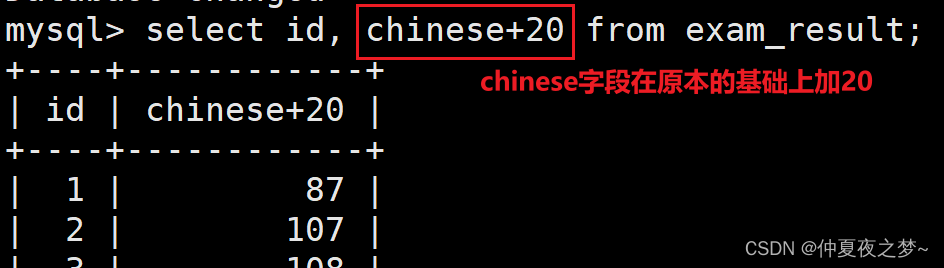
也可以对原本的字段作四则运算
(4) 为查询结果起别名(as)
可以为一个字段起别名,来增强字段的辨识性。语法格式如下:
select 字段名 as 别名 ...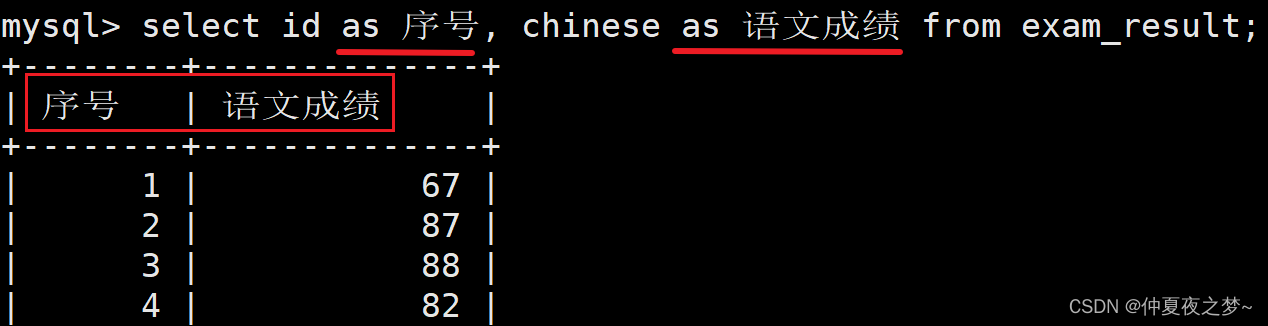
也可以为表达式起别名,详见上面第三点 “ 查询字段为表达式 ”
(4) 查询结果去重(distinct)
语法格式如下:
select distinct 字段名 ... -- 对xx字段的结果进行去重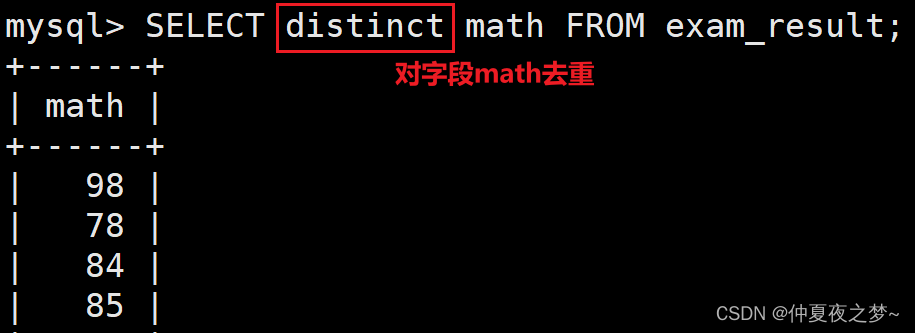
注意:适合对单一字段查询时的去重,存在多个字段时,去重会失效。
2、条件语句(where)
当记录较多的时候,仅使用 select 无法满足满足需求,因为很多记录是不需要的,比如我们要查看xx班级的学生成绩,我只想知道总分大于90分的同学有哪些,此时就需要滤除一些记录。
使用where 语句时,可以搭配比较运算符(>、<、=)、逻辑运算符(and、or、not)和通配符(%、_)一起使用。
语法格式如下:
select ... where 条件表达式(1) 比较运算符
常用比较运算符如下:
| 运算符 | 说明 |
| >、>=、<、<= | 大于,大于等于,小于,小于等于 |
| =、is null | 等于(非NULL字段的比较) |
| <=> | 等于(用于判断字段是否等于NULL) |
| != | 不等于(非NULL字段的比较) |
| <>、is not null | 不等于(判断字段是否不等于NULL) |
| between A1 and A2 | 判断某个字段的值是否在A1和A2之间(注意是闭区间) |
| in (option1, option2 ...) | 判断某个字段的值是否为列表中的某一个 |
| like | 模糊匹配。搭配通配符使用,% 表示多个字符,_ 表示一个字符 |
在使用上述运算符时,有几点需要注意:
第一,NULL代表字段为空,不可以直接使用等号运算符比较,因为一个空字段和其他值比较没有意义。比如下面这种写法是错误的。
select * from exam_result where name=null -- 等号运算符不能参与null的比较第二,通配符理解为占位,比如:
- -- 查询所有姓张的学生(“张后面可以有多个字符”)
- select * from exam_result where name like "张%"
-
- -- 查询所有的张某(“张”后面只能有一个字符)
- select * from exam_result where name like "张_"
- “张%”可以理解为保留“张”后面有多个字符的字段,“张_”可以理解为保留“张”后面只有一个字符的字段
- “%张”可以理解为保留“张”前面有多个字符的字段,“_张”可以理解为保留“张”前面只有一个字符的字段
(2) 逻辑运算符
常用逻辑运算符如下:
| 运算符 | 说明 |
| and | 等价于C语言中的逻辑与(&&) |
| or | 等价于C语言中的逻辑或(||) |
| not | 等价于C语言中的逻辑取反(!) |
- -- 查询所有id为1 / 3 / 5,而且姓张的学生
- select * from exam_result where id in (1,3,5) and name like '张%'
3、结果排序(order by)
order by 可以对某一个字段或者多个字段进行排序,默认是升序排序。其实就是根据某一个字段来对整个查询结果进行排序。
- order by asc:升序排序(asc代表ascend)
- order by desc:降序排序(desc代表descend)
语法格式如下:
select ... order by 字段名 [asc | desc](1) 一个字段的排序
暂时不考虑条件判断,对所有学生的数学成绩进行排序
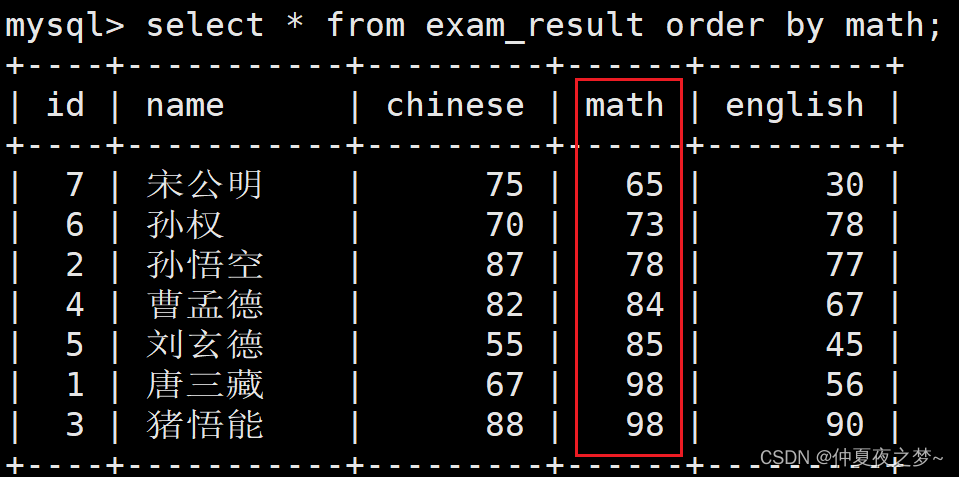
(2) 多个字段的排序
order by 可以根据多个字段来对查询结果排序。多个字段排序时,遵循的规则是:
- 先根据字段1比较,如果能比较出大小,那就只使用字段1
- 如果字段1中的比较结果为相等,再根据字段2比较
多个字段排序的语法格式如下:
select ... order by 字段名1, 字段名2, ... [asc | desc]比如要根据语文成绩和数学成绩来对查询结果进行降序排序。我们会发现当字段 chinese 中不存在两个值相等的情况时,会一直根据chinese比较。
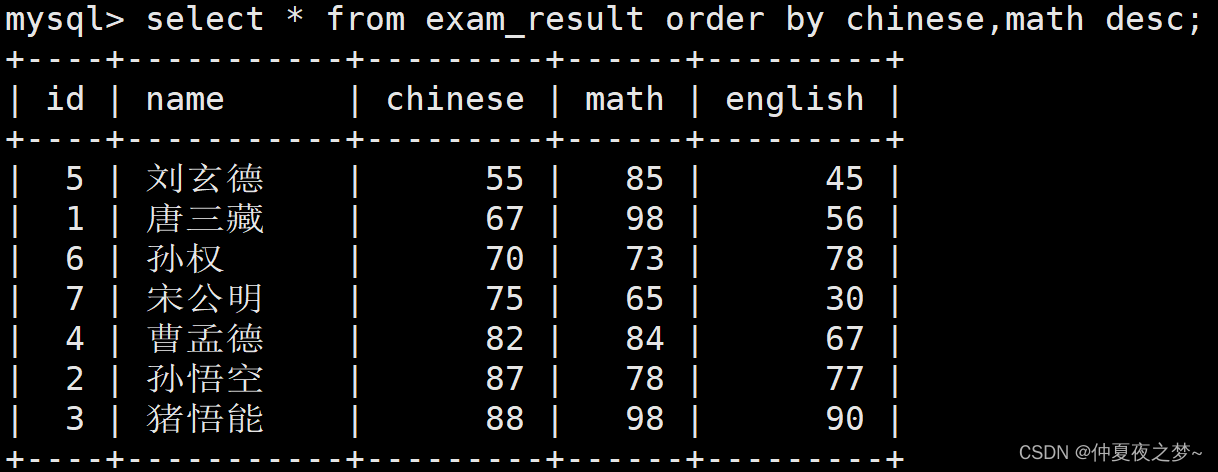
4、分页(limit)
所谓分页其实也可以理解为截取,从某个位置开始,截取 N 条记录。实现方式有两种,语法格式如下:
- -- start: 表示起始位置,即要从第几行开始截
- -- step: 表示步长,即要截多少条记录
-
- -- 方式一:
- select ... limit start, step
-
- -- 方式二:
- select ... limit step offset start
比如我们要截取前三条记录,第一种方式的查询结果:
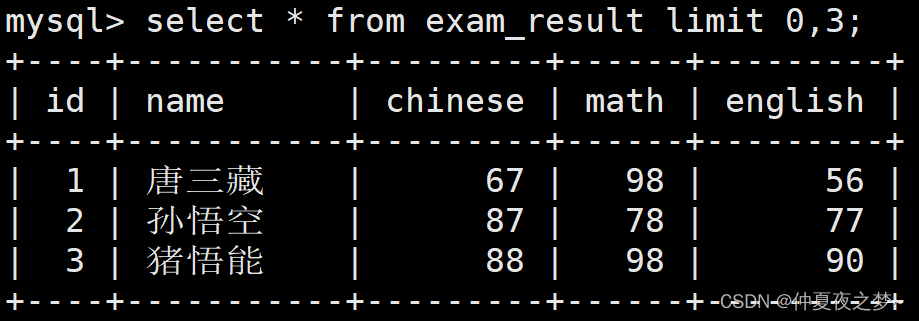
第二种方式的查询结果:
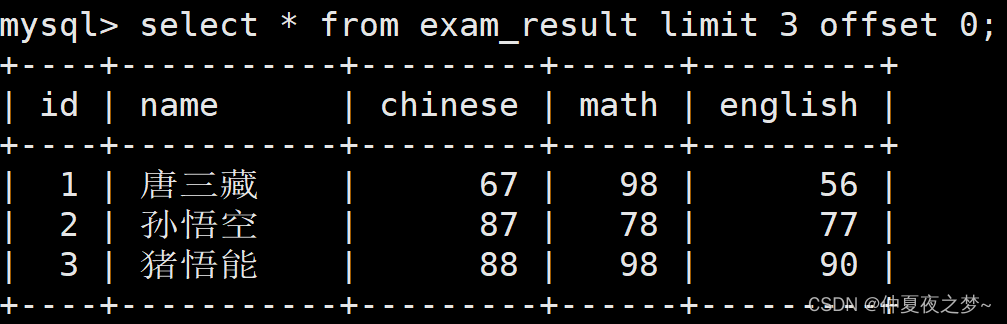
5、分组(group by)
(1) 无条件分组
group by 表示根据某一个字段的内容进行分组,以下面这个表为例:
- 假设根据 department 字段分组,分组的结果:技术部、行政部
- 假设根据 department_id 字段分组,分组的结果:1001、1002
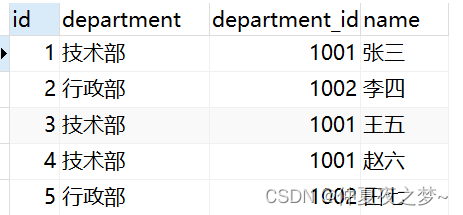
需要注意的是,group by 、where、select的执行顺序依次是:where > group by > select
where针对的是整个表数据的筛选,筛选完以后再分组,可以减少要分组的记录;然后才是 group by 分组;最后是在每一个分组中做查询或者表达式计算处理。
- -- 先根据字段1分组,然后在字段1分组的基础上,根据字段2分组
- select ... group by 字段1, 字段2 ...
假设我们要计算每个部门的人数,基本思路是根据部门分组,然后使用select在每一个分组中统计人数,统计记录数量使用聚合函数count。

(2) 有条件分组(having)
where只适用于筛选整表记录,并不适合筛选分组记录,如果希望对每一个分组进行筛选,我们可以使用 having。having的优先级在group by 之后,因为针对的是分组以后的记录筛选。所以我们可以得到最终的优先级顺序:where > group by > select > having
group by 与 having 搭配使用的格式如下:
select ... group by 字段1, ... having 每一个分组的筛选条件(3) where 与 having 的区别
where筛选的是表数据,而having 筛选的是每个的分组数据,两者并不冲突,因为他们的执行优先级不同

