
- 1dubbo(4)-负载均衡_dubbo.consumer.loadbalance
- 2蓝桥杯java组基础练习题50题_蓝桥杯java软件开发题目
- 308. Springboot集成webmagic实现网页爬虫_webmagic 最新版本
- 4【CTR排序】多任务学习之MMOE模型_mmoe粗排模型
- 5Springboot 统计 代码执行耗时时间 ,玩法多到眼花_springboot 接口耗时监控
- 6基于LM2596和ESP32的数控直流电源_lm2569数控电源
- 7联想Y720安装ubuntu18.04双系统,解决wifi问题并安装GTX1060显卡驱动记录_y720双显卡
- 8最新最全垃圾分类小程序,含图片识别和语音识别,视频播放,垃圾分类搜索,垃圾知识答题,积分排行,文章推荐,收藏点赞文章 登录注册等功能_智能生活垃圾识别分类小程序
- 9关于ipad:无法验证服务器身份_ipad无法验证服务器身份怎么解决
- 10强强联手:科东软件与飞腾实现产品兼容性互认证明_产品见兼容证明模板
Hugging Face 中文预训练模型使用介绍及情感分析项目实战_huggingface上的微博情感分析数据集
赞
踩
Hugging Face 中文预训练模型使用介绍及情感分析项目实战
Hugging Face
一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA, state-of-the-art)的NLP技术,而非困窘于训练资源的匮乏"
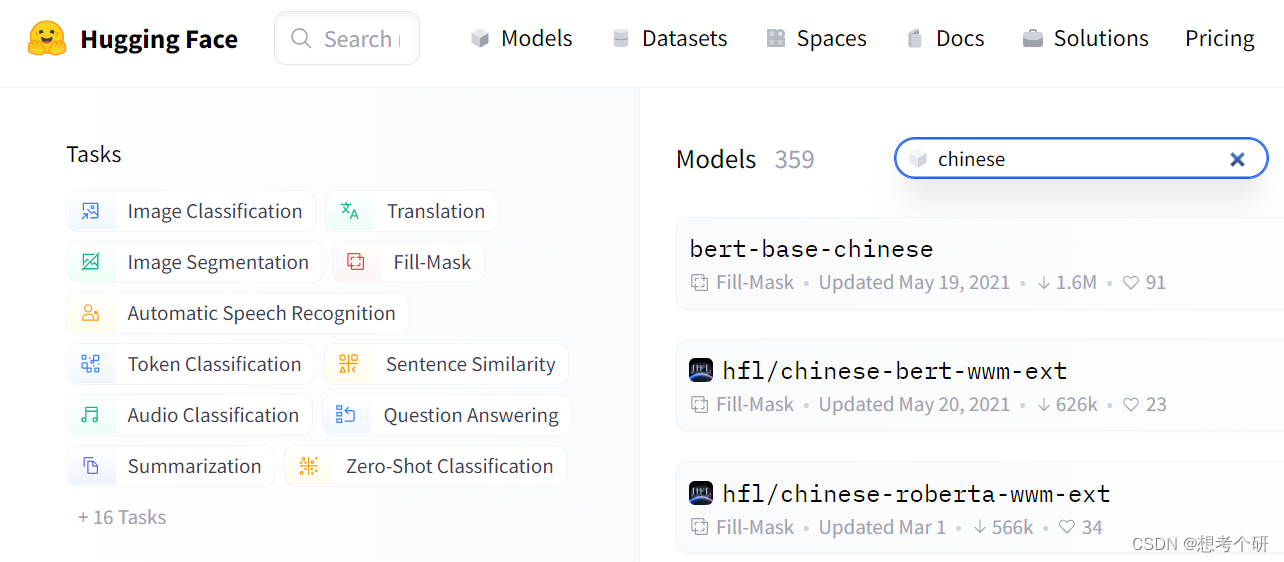
其中,transformer库提供了NLP领域大量预训练语言模型和调用框架,方便根据自己的需求快速进行语言模型搭建,这里为自己学习做下简单总结(参考官方教程)。
目录
-
- 语言模型与自然语言处理
- 语言模型
- 自然语言处理常见任务
- 其他非文本任务
- 经典模型处理能力(句子序列长度)
- transformer库piepeline接口介绍
- 语言模型与自然语言处理
-
- tokenizer介绍
- model介绍
-
Transformer常用model架构(带head)接口输出
- AutoModel架构的输出(通用类,不带head部分)
- AutoModelForMaskedLM 架构的输出
- AutoModelForSequenceClassification架构的输出
- AutoModelForTokenClassification架构的输出
- 模型输出logits概率处理
-
- 数据集预处理
- 模型搭建(预训练模型加载)
- 数据集编码和数据加载器生成
- 微调训练
- 模型保存
正文
-
Transformer整体介绍
-
语言模型与自然语言处理
-
语言模型:简易理解就是求概率P(tm|t1、t2、…、tn)
-
自然语言处理常见任务
- Classifying whole sentences: 情感分析,检测垃圾邮件,判断句子语法上是否正确或两个句子逻辑上是否有关联。
- Classifying each word in a sentences: 识别句子的语法成分(动名词、形容词)或NER命名实体识别(人名,地名,组织)。
- Generating text content: 文本自动生成,或文本填空。
- Extracting an answer from a text : 问答系统,给定问题和上下文,根据上下文信息提取问题的答案。
- Generating a new sentence from an input text: 文本摘要、文本翻译。
-
其他非文本任务:
图像:
-
图像分类:对图像进行分类。
-
图像分割:对图像中的每个像素进行分类。
-
物体检测:检测图像中的物体。
音频:
-
音频分类:为给定的音频片段分配标签。
-
自动语音识别 (ASR):将音频数据转录为文本。
-
-
-
经典模型处理能力(句子序列长度)
- RNN 10-40
- LSTM/GRU 50-100
- Transformer BERT 521 GPT 1024
- Transformer-XL LXNet 3000-5000
-
transformer库piepeline接口介绍
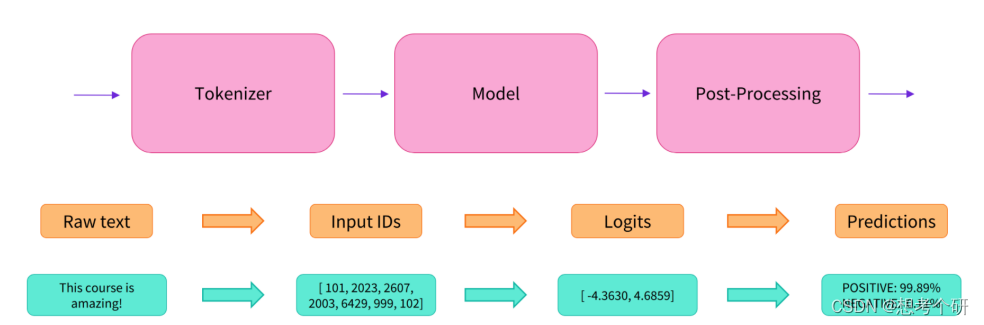
Transformers library 中最基本对象是pipeline,它将数据预处理、预训练语言模型和目标结果处理步骤串联起来,使我们能够直接输入文本并获得自己需要的答案。
Pipeline结构示意图:
pipeline的简单使用:
import torch from transformers import pipeline # 哈工大中文预训练模型bert-roberta-wwm (已下载到本地) model_path = r"D:\appData\bert-wwm-ext\chinese-roberta-wwm-ext" # 测试中文填词任务 fill_mask_model = pipeline(task='fill-mask', # 填写要做的任务类型,确定POST-processing model=model_path, # 处理任务要使用的预训练语言模型 tokenizer=model_path # 输入数据预处理,需要的分词编码器(与要使用的语言模型相关) ) fill_mask_model(['我[MASK]你']) # 返回 ''' [{'score': 0.8178807497024536, 'token': 4263, 'token_str': '爱', 'sequence': '我 爱 你'}, {'score': 0.05486121028661728, 'token': 2682, 'token_str': '想', 'sequence': '我 想 你'}, {'score': 0.02797825261950493, 'token': 3221, 'token_str': '是', 'sequence': '我 是 你'}, {'score': 0.019031845033168793, 'token': 1469, 'token_str': '和', 'sequence': '我 和 你'}, {'score': 0.01068081520497799, 'token': 3612, 'token_str': '欠', 'sequence': '我 欠 你'}] '''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
默认情况下,给定特定任务,pipeline会自动选择一个特定的预训练模型。
将文本输入pipeline,pipeline的处理涉及3个步骤,对应上面的pipeline结构图
-
tokenizer: 文本预处理为对应model可以理解的格式
-
model: 预处理模型输入对应model
-
post-processing: 将model的输入经过全连接/激活,处理成任务需要输出的形式
至此,只需要修改参数 task名+匹配的预训练语言模型,就能简单实现自然语言处理任务(同样也可以使用pipeline实现其他如图像、音频分类等任务)。
-
-
tokenizer和model介绍
通过pipeline接口,我们能实现特征的任务,但越简单的接口,往往伴随着缺乏灵活性的问题。一般情况下,不直接使用pipeline,使用其中tokenizer和model,配合模型后续处理生成适合自己任务的模型。
-
tokenizer介绍
from transformers import BertModel,BertTokenizer,BertConfig # 主要加载预训练模型词汇表,分词规则等 tokenizer = BertTokenizer.from_pretrained(model_path) #分词器序列编码,解码 data_encode = tokenizer( text = ['我 爱 你','我恨你','天空'], # 输入多条分本 text_pair = None, add_special_tokens = True, # padding = 'max_length', # 填充长度不够的序列 truncation = True, # 过长序列截断 max_length = 5, # 指定序列长度 stride = 0, is_split_into_words = False, # text或text_pair参数输入字符串列表时,起作用,指定序列是否分批 pad_to_multiple_of = None, # 指定数据处理后的返回 return_tensors = 'pt',# 指定返回数据类型,pt:pytorch np:数组 'tf':tensorflow 不指定返回list return_token_type_ids = True, # 指定上下句子关系,上句为0,下句为1 return_attention_mask = True, # 返回句子序列实际长度,1代表真实token,0代表填充 return_overflowing_tokens = False, return_special_tokens_mask = True,# 指定特殊字符位置,1代表起始符[CLS],分隔符[sep],填充符[PAD]等,0代表正常token return_offsets_mapping = False, return_length = True,# 返回序列长度 verbose = True ) data_encode ''' {'input_ids': tensor([[ 101, 2769, 4263, 872, 102], [ 101, 2769, 2616, 872, 102], [ 101, 1921, 4958, 102, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]]), 'special_tokens_mask': tensor([[1, 0, 0, 0, 1], [1, 0, 0, 0, 1], [1, 0, 0, 1, 1]]), 'length': tensor([5, 5, 4]), 'attention_mask': tensor([[1, 1, 1, 1, 1], [1, 1, 1, 1, 1], [1, 1, 1, 1, 0]])} ''' tokenizer.decode(token_ids=data_encode['input_ids'][0]) # 字符解码 >> [CLS] 我 爱 你 [SEP] [PAD]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
-
model介绍
# 加载预训练bert中文语言模型(主要是预训练参数) model = BertModel.from_pretrained(pretrained_model_name_or_path=model_path) bert_out = model.forward( input_ids = data_encode.input_ids, # 对应tokener输出字符序列编码 attention_mask = data_encode.attention_mask, token_type_ids = data_encode.token_type_ids, position_ids = None, head_mask = None, inputs_embeds = None, encoder_hidden_states = None, encoder_attention_mask = None, past_key_values = None, use_cache = None, output_attentions = None, output_hidden_states = True, # 是否返回 return_dict = None ) # bert_out.hidden_states # 返回每个block的隐藏层输出 bert_out.last_hidden_state.shape # 返回bert模型最后一个block隐藏层输出 bert_out.pooler_output.shape # 返回[CLS]标记处对应的向量后面接个全连接再接tanh激活后的输出 ''' torch.Size([3, 5, 768]) (batch,sequence_len,word_embedding_szie) torch.Size([3, 768]) (batch,word_embedding_szie) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
transformers 中有tokenizer和model类还有很多其他的函数功能,这里只是bert预训练中文语言模型的使用,可以在model(经过tokenizer处理后分词数据输入)的带有语义的隐藏层输出后面,灵活添加后续处理层,实现自己特定的任务。
-
-
Transformer常用model架构(带head)接口输出
transformer库有很多带有不同预设输出的model架构,针对预训练模型输出结果后续处理的层,称之为head层。head将transformer network(多头注意力机制)最终隐藏层输出的高维特征向量作为输入,并将他们投影到不同的维度上,head通常由一个或几个线性层组成。
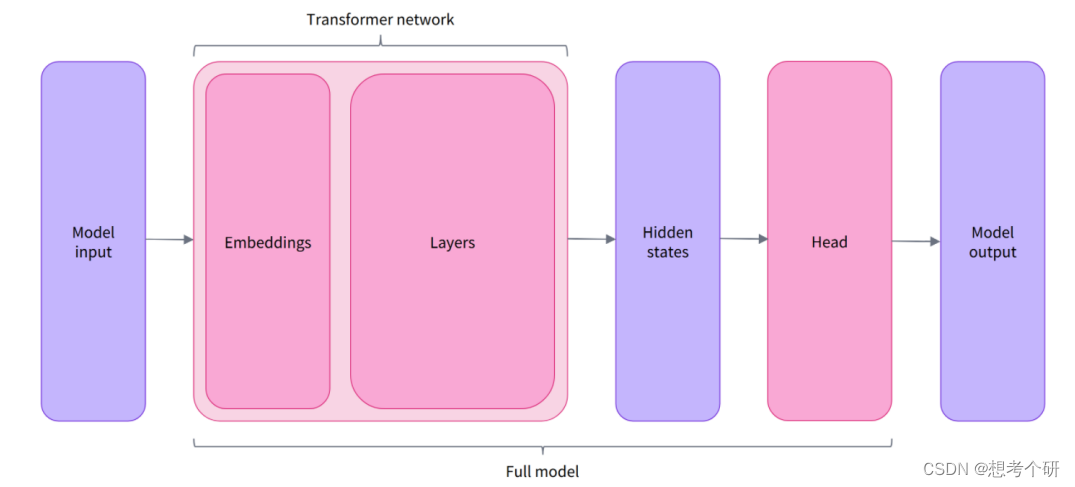
-
AutoModel架构的输出(通用类,不带head部分)
In many cases, the architecture you want to use can be guessed from the name or the path of the pretrained model you are supplying to the from_pretrained() method. AutoClasses are here to do this job for you so that you automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary. – 官方原文
– 大概意思 AutoModel是个通用类,能从输入的预训练模型名称中或预训练模型存储路径中,自动生成相应模型的architecture(架构)并自动加载checkpoint(可以理解为对应层的权重参数)
– BertModel 专用于加载BERT架构模型的基础类。
from transformers import ( AutoTokenizer, AutoModel, AutoConfig, AutoModelForMaskedLM, AutoModelForSequenceClassification, AutoModelForTokenClassification) # 记载预训练模型 auto_model = AutoModel.from_pretrained(model_path) bert_model = BertModel.from_pretrained(model_path) tokenizer = AutoTokenizer.from_pretrained(model_path) # 验证AutoModel和BertModel加载同一个模型输出结果 data = tokenizer(text=['我爱你'],return_tensors='pt') auto_model(data.input_ids).last_hidden_state bert_model(data.input_ids).last_hidden_state ''' tensor([[[ 0.0963, 0.0306, -0.0745, ..., -0.6741, 0.0229, -0.3951], [ 0.8193, -0.4155, 0.4848, ..., -0.7079, 0.5251, -0.2706], [ 0.2164, 0.2476, -0.2831, ..., -0.1583, 0.1191, -1.0851], [ 0.8606, -0.5950, 0.8120, ..., -0.4619, 0.1180, -0.4674], [ 0.0963, 0.0306, -0.0745, ..., -0.6741, 0.0229, -0.3951]]], grad_fn=<NativeLayerNormBackward>) tensor([[[ 0.0963, 0.0306, -0.0745, ..., -0.6741, 0.0229, -0.3951], [ 0.8193, -0.4155, 0.4848, ..., -0.7079, 0.5251, -0.2706], [ 0.2164, 0.2476, -0.2831, ..., -0.1583, 0.1191, -1.0851], [ 0.8606, -0.5950, 0.8120, ..., -0.4619, 0.1180, -0.4674], [ 0.0963, 0.0306, -0.0745, ..., -0.6741, 0.0229, -0.3951]]], grad_fn=<NativeLayerNormBackward>) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
AutoModel类输出:
- 输出为BaseModelOutputWithPoolingAndCrossAttentions。
- 包含’last_hidden_state’和’pooler_output’两个元素。
- 'last_hidden_state’的形状是(batch size,sequence length,768)
data = tokenizer(text=['我爱你'],return_tensors='pt') model = AutoModel.from_pretrained(model_path) outputs = model(**data) outputs.keys() outputs.last_hidden_state.shape # 最后一层隐藏层输出 outputs.pooler_output.shape # pooler output是取[CLS]标记处对应的向量后面接个全连接再接tanh激活后的输出 ''' odict_keys(['last_hidden_state', 'pooler_output']) torch.Size([1, 5, 768]) (batch,sequence_len,word_embedding_szie) torch.Size([1, 768]) (batch,word_embedding_szie) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
-
AutoModelForMaskedLM 架构的输出(with a masked language modeling head,可用于文本填空任务)
AutoModelForMaskedLM输出:
- 输出为MaskedLMOutput
- 包含’logits’元素,形状为[batch size,sequence length,21128],21128是’vocab_size’。
model = AutoModelForMaskedLM.from_pretrained(model_path) outputs = model(**data) outputs.keys() outputs.logits.shape ''' odict_keys(['logits']) torch.Size([1, 5, 21128]) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
AutoModelForSequenceClassification架构的输出(with a sequence classification head,文本分类型任务)
data = tokenizer(text=['我爱你'],return_tensors='pt') model = AutoModelForSequenceClassification.from_pretrained(model_path) outputs = model(**data) outputs.keys() outputs.logits.shape ''' odict_keys(['logits']) torch.Size([1, 2]) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
AutoModelForTokenClassification架构的输出(with a token classification head,命名实体识别任务)
AutoModelForTokenClassification输出:
- 输出为TokenClassifierOutput
- 包含’logits’元素,形状为[batch size,sequence length,2]。
model = AutoModelForTokenClassification.from_pretrained(model_path) outputs = model(**data) outputs.keys() outputs.logits.shape ''' odict_keys(['logits']) torch.Size([1, 5, 2]) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
模型输出logits概率处理
logits,即模型最后一层输出的原始的、非标准化的分数。要转换为概率,它们需要经过softmax(所有
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/47226
-
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

