
- 13. git中文件的三种常见状态_git文件状态
- 2
Title Title - 3主流开源深度学习框架简介
- 4【HarmonyOS应用开发】Web组件的使用(十三)
- 5EasyExcel快速入门_@excelproperty
- 6Java架构师方案—多数据源原理及应用(附完整项目代码)_java多数据源原理
- 7年薪100w+的阿里p7专家,顶尖的技术人才,只因做到了这几点_阿里巴巴设计专家年薪百万
- 8ubuntu18 安装 Docker Docker-compose_ubuntu18 安装docker compose
- 9理论结合实际:如何调试神经网络并检查梯度_怎么查看模型有没有进行梯度回传
- 10深入浅出Java虚拟机,从来没有人能把Java 虚拟机讲解的这么透彻_深入理解java虚拟机
ALBERT 论文笔记_微调albert时显存占用很大
赞
踩
单位:Google Research
时间:2020.2
发表:ICLR2020
论文链接:https://arxiv.org/abs/1909.11942
一、前言
1. ALBERT想做些什么?
深度学习在模型结构想不到更好的后,就会想到增加模型的规模即深度和宽度,google团队在提出bert模型后也如是思考,想通过增加bert的宽度来提高效果。
但bert模型再预训练时已经很大了,强如google拥有这么好的TPU集群,增加self_attention神经元个数至2048时也跑不动。于是乎便想找方法来减少模型的参数,让更深更宽的bert可以训练。
2. ALBERT做到了什么?
在论文的摘要中,作者如是说:
综合经验证据表明,我们提出的方法导致的模型与原始的BERT相比,其规模大小要好得多。我们的最佳模型在GLUE、RACE和SQuAD基准上建立了新的最先进的结果,而与BERT-large相比,其参数更少
提出的ALBERT-base模型,表现与BERT-base相当,其参数量仅仅是后者的十分之一!
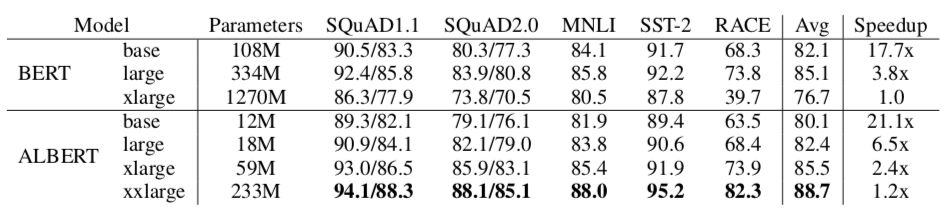
不过这里要先泼一泼冷水,如果你想要的是一个预测时间大幅减少在低算力的服务器能上线的模型的话,那么ALBERT不会是你要的答案,同一规格的ALBERT和BERT预测速度是一样的。本笔记主要分析下论文中的创新点和一些启发。
二、ALBERT: A Lite BERT
1. 作者的思路
1.1 提高参数的利用率
Bert在训练时一共有334M参数,其中20%的参数来源于word_embedding(V x E),80%来源于12个transformer encoder(12 x L x H x H)
NLP任务中的vocab size本来就很大,如果embedding size = hidden size的话,模型参数量就容易很大,对于词的分布式表示,往往并不需要这么高的维度,比如在Word2Vec时代就多采用50或300这样的维度
1.2 改进预训练任务
很多研究(XLNet、RoBERTa)都发现next sentence prediction没什么用处,因为这个任务不仅包含了句间关系预测,也包含了主题预测,而主题预测显然更简单些(比如一句话来自新闻财经,一句话来自文学小说),模型会倾向于通过主题的关联去预测,大大简化了此预训练任务的难度,所以很多模型后续都换更难度更高的预训练任务代替或直接舍去
1.3 增加数据量,加大模型
这是很自然的一个想法,让模型多学习到一些知识总是有益无害
2. 具体做法
2.1 低秩分解
作者使用了小一些的E(64、128、256、768),训练一个独立于上下文的embedding(VxE),之后计算时再投影到隐层的空间(乘上一个ExH的矩阵),相当于做了一个因式分解
举个例子就比如是将20000 * 768的embedding层改为20000 * 128 + 128 * 768,Embedding层的参数量便减少6倍
2.2 参数共享
跨层参数共享,就是不管12层还是24层都只用一个transformer
具体分为三种模式:只共享 attention 相关参数、只共享 FFN 相关参数、共享所有参数。
2.3 预训练任务改进
将NSP任务替换为SOP(sentence order prediction)任务,预测两句话有没有被交换过顺序,正例与NSP任务一样是两句连贯的句子,负例的构造加大了些难度,SOP并不从不相关的句子中生成,而是将原来连续的两句话翻转形成负例
3. 实验
3.1 Factorized embedding parameterization
低秩分解的对比实验如下图

可以看到当E取128时是性价比最高的选择,总参数降低了10M左右
3.2 Cross-layer parameter sharing
从最后一列的 Avg 来看,如果是只共享 attention 参数,不仅可以减维,还能保持性能不掉。然而,可能是作者为了追求轻量和简洁度,把 FFN 也共享了,最终选择了降低的参数量是最多的所有层次参数共享

作者对比了每一层输入与输出嵌入矩阵间的L2距离和余弦相似度,发现 BERT 比较震荡,而ALBERT 从一层到另一层的转换要比 BERT 平滑得多,结果表明,权重共享有效地提升了神经网络参数的鲁棒性

3.3 Inter-sentence coherence loss
可以看到SOP任务对于各个数据集效果提升还是很明显的

3.4 一些小trick
-
ALBERT的最大模型在训练1M步后仍然没有过拟合,于是作者决定删除dropout,进一步提高模型能力
-
Bert 的 MLM 目标,是随机遮住 15% 的词来预测。ALBERT 预测的是 n-gram 片段,包含更完整的语义信息。每个片段的长度取值 n(最大为3),根据概率公式计算得到。比如,取1-gram 、2-gram、3-gram 的概率分别为 6/11,3/11,2/11。
-
BERT 为了加速训练,前 90% 的 steps 使用了 128 个 token 的短句,最后 10% 才使用 512 个词的长句来训练 position embedding。而 ALBERT 似乎是 90% 的情况下,输入的 segment 取满了 512 个词,其输入序列要比 BERT 长接近一半,从数据上看,更长的数据提供更多的上下文信息,可能可以提升模型的能力
3.5 总结
- albert-base和bert-base前向传播时间也就是预测时间几乎一样,严格来说理论上因为embedding部分多了个矩阵运算,时间上会稍慢一些
- 参数量大大减少,能加快训练速度和显存占用。但albert参数降低到bert的1/10,并不意味着它的显存占用量能降低到1/10,实际只下降了大概10%-20%,因为缓存的隐层激活值(用于反向传播计算梯度)也会占用相当比例的显存,这一部分暂时还省不下来
- 在同样的预测速度下,albert效果更差;在同样的效果下,albert更慢
三、自己的思考
- 参数共享后由于模型的参数量大大减少,所以不存在模型过大导致过拟合问题,所以要去除dropout。同样的原因使得ALBERT的方式可以使模型做的更大更宽,精度也还能持续增长
- 参数共享的方法应该会使得那一层模型更具有普遍性,之前提出的一些预处理方法,采用ALBERT的参数可能会表现的更好
- BERT large 有24层,而 ALBERT xlarge 是24层,2048维,xxlarge是12层,4096维。作者表示xxlarge模型取24层时与取12层表现相当。这其中隐含的信息我现在还没想到
- 因为参数量减少,在相同显存大小下应该能部署更多的线程,以达到更高的并发量,在工业上有一定可取性
四、参考文章
- https://zhuanlan.zhihu.com/p/108105658
- https://zhuanlan.zhihu.com/p/84273154
- https://www.zhihu.com/question/347898375
- https://blog.csdn.net/weixin_37947156/article/details/101529943
- https://kexue.fm/archives/7846

