
- 1【K8S认证】2023年CKA考题汇总(解析+答案)_k8s证书认证考试
- 2Python实现代码雨效果_python画代码雨
- 3【目标检测】Faster R-CNN论文代码复现过程解读(含源代码)_使用voc格式进行训练,训练前需要下载好voc07+12的数据集
- 4unity中调用dll文件总结_unity调用dll
- 5【Spring Boot】集成Kafka实现消息发送和订阅_unexpected handshake request with client mechanism
- 6计划任务ScheduledExecutorService的使用_setremoveoncancelpolicy
- 7【书生·浦语大模型实战营】学习笔记1
- 8【JavaEE】传输层网络协议
- 9【无标题】Unity2021安装后无法打开的问题_unity pattern not found
- 10llama2大模型---商用部署(模型推理阶段)预算估算_v100 大模型推理
ALBERT: 轻量级的BERT_albert 轻量级bert
赞
踩
前言
当前的趋势是预训练模型越大,效果越好,但是受限算力,需要对模型进行瘦身。这里的ALBERT字如其名(A lite BERT),就是为了给BERT瘦身,减少模型参数,降低内存占用和训练时间(待思考)。
embedding参数因式分解
将大的语料矩阵分解成两个小的矩阵。减少模型宽度。
我们先看看BERT这一块是如何操作的。
首先,我们对序列中每一个token,都有一个token_id,需要基于token id生产一个embedding vector,进入transformer结构。BERT的方法是将token id进行one_hotting化(向量长度为词库长度V,bert里是30000),然后将one_hotting直接用look_up查找embedding表(V*H,这里H是设定的embedding vector长度)。
然后对segment id(实际上就是0和1),我们可以预训练,得到segment embedding(非必要)
对于position embeddings,也是预训练得到向量。
最后将三个向量加起来,获得我们的输入向量。我看代码里还做了一个layer_norm+dropout
这里的[CLS]是sentence vector,当然是指fine-tune后的
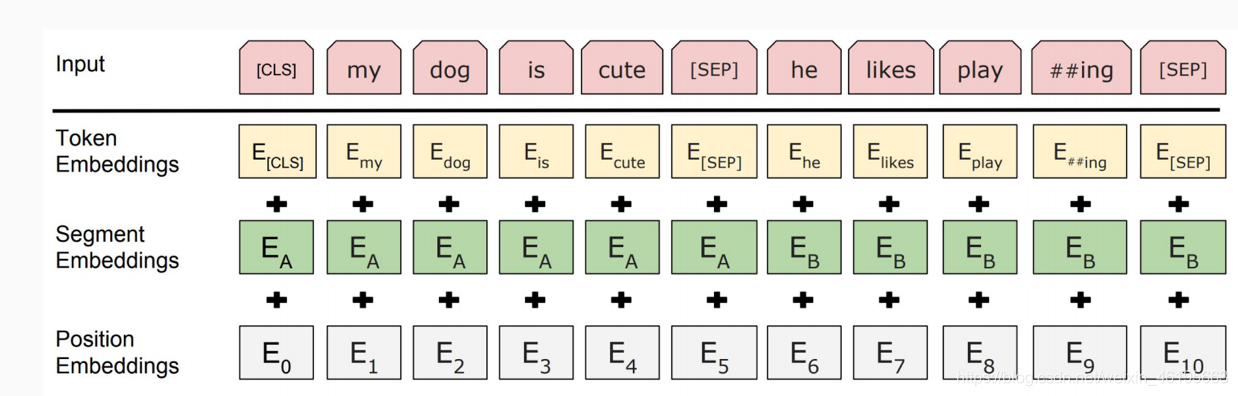
后续我们
具体操作参考google bert代码
def embedding_lookup(input_ids, vocab_size, embedding_size=128, initializer_range=0.02, word_embedding_name="word_embeddings", use_one_hot_embeddings=False): """Looks up words embeddings for id tensor. Args: input_ids: int32 Tensor of shape [batch_size, seq_length] containing word ids. vocab_size: int. Size of the embedding vocabulary. embedding_size: int. Width of the word embeddings. initializer_range: float. Embedding initialization range. word_embedding_name: string. Name of the embedding table. use_one_hot_embeddings: bool. If True, use one-hot method for word embeddings. If False, use `tf.gather()`. Returns: float Tensor of shape [batch_size, seq_length, embedding_size]. """ # This function assumes that the input is of shape [batch_size, seq_length, # num_inputs]. # # If the input is a 2D tensor of shape [batch_size, seq_length], we # reshape to [batch_size, seq_length, 1]. if input_ids.shape.ndims == 2: input_ids = tf.expand_dims(input_ids, axis=[-1]) embedding_table = tf.get_variable( name=word_embedding_name, shape=[vocab_size, embedding_size], initializer=create_initializer(initializer_range)) flat_input_ids = tf.reshape(input_ids, [-1]) if use_one_hot_embeddings: one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size) output = tf.matmul(one_hot_input_ids, embedding_table) else: output = tf.gather(embedding_table, flat_input_ids) input_shape = get_shape_list(input_ids) output = tf.reshape(output, input_shape[0:-1] + [input_shape[-1] * embedding_size]) return (output, embedding_table)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
注意,在bert config里,embedding_size = H = 768
当然这个embedding表需要后期训练得到,这里的计算复杂度非常高
O
(
H
∗
V
)
O(H*V)
O(H∗V),考虑到V是词库大小的化。
Albert的改进是,考虑wordpiece里词向量是上下文无关的,而Bert词向量结果是有关的,那么后者信息含量要高于前者,所以作者认为embeding_size < H。
为此,作者添加了一个中间环节,先将one_hotting的wordpiece向量转化为一个E维向量(
O
(
V
∗
E
)
O(V*E)
O(V∗E)),然后将这个E维向量转化为H维向量(
O
(
V
∗
H
)
O(V*H)
O(V∗H)),所以时间复杂度计为
O
(
V
∗
E
)
+
O
(
E
∗
H
)
O(V*E)+O(E*H)
O(V∗E)+O(E∗H))
训练也是需要训练这两个矩阵。
单纯看结果,参数因式分解有效果,但是不是主要原因
通过实验发现embedding size=128效果最好

参数共享
采用全层参数共享(FFN layer + Attention Layer)减少模型深度。
比较四种共享方法:不共享(Bert-type),只共享Attention,只共享FFN ,全共享(Albert-type)。
从实验结果来看,全共享形式对模型效果有明显下降,下降原因主要来源共享FNN层,而共享Attention层不会影响模型效果(至少看起来不明显),但是对模型压缩效果有限。
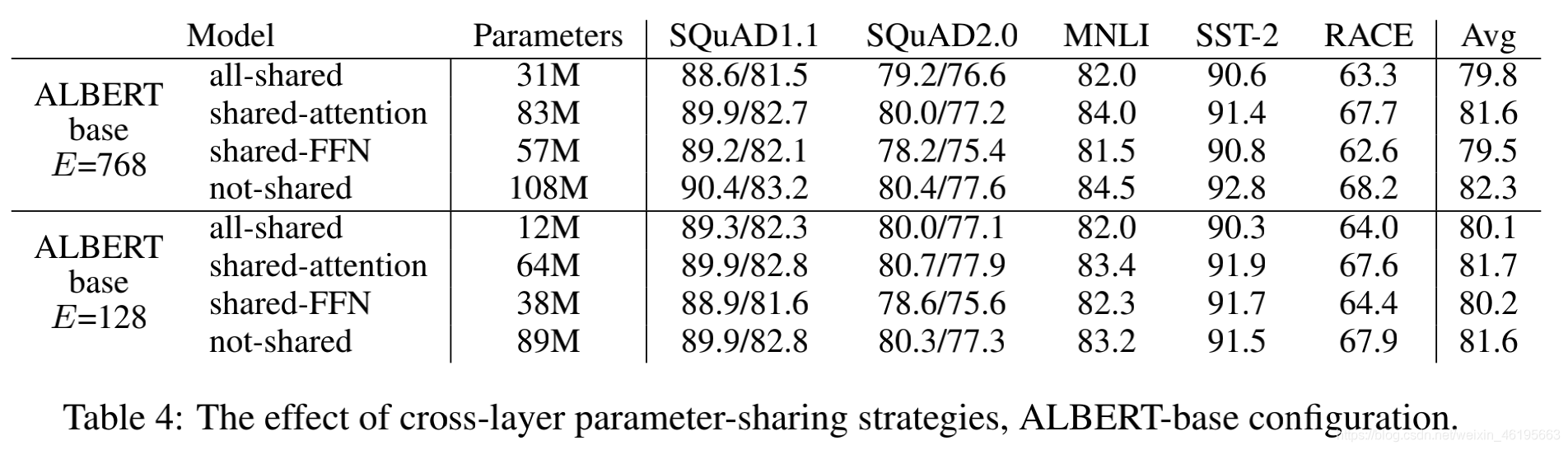
但是最终模型效果中与BERT_large比较的ALBERT是基于BERT_xxlarge压缩的,虽然参数相比BERT更少。但不足以证明参数共享那么高效(压缩是有损的)
SOP instead of NSP
不用NSP是因为任务难度不够(与MLM相比),NSP会混淆主题预测和语序连贯性预测
SOP实际上正样本是BERT同上下文,负样本是乱序上下文,避免了主题预测,只关注语言连贯性。
同时发现,SOP可以解决NSP,但是NSP解决不了SOP

结论
这里同上,采用ALBERT_xxlarge是L=12, H=4096。相比BERT_large,这是一个宽而浅的模型,参数量大约为前者70%。

其他压缩方法
参见:BERT压缩
论文来源:Lan, Z. , Chen, M. , Goodman, S. , Gimpel, K. , Sharma, P. , & Soricut, R. . (2019). Albert: a lite bert for self-supervised learning of language representations.

