
- 1DP读书:《openEuler操作系统》(八)TCP、UDP与跨机器通讯
- 2跨平台Recorder录音插件:支持多种格式、音频可视化、实时上传、语音识别
- 3【UnityUGUI】复合控件详解,你还记得多少
- 4Java+Swing+MySQL实现学生选课管理系统_基于java swing+mysql的学生选课管理系统
- 5鸿蒙应用开发学习路线(OpenHarmony/HarmonyOS)_openharmony学习路线
- 6OpenHarmony解读之设备认证:数据接收管理-获取HiChain实例(2)
- 7基于GPT-4的 IDEA 神仙插件,无需魔法,亲测好用!
- 8KALI--入门教程--kali下载(vm),更新国内源,更换中文界面_kali环境下载
- 9【Django】单元测试TestCase、Client的用法_django testcase使用
- 10旅行商问题(枚举,回溯,动态规划,贪心,分支界限)_c语言回溯算法旅行商问题现在我们从景点 a 出发,要去 b、c、d、e 共 4 个景点,按
【文本到上下文 #7】探索 NLP 中的 Seq2Seq、编码器-解码器和注意力机制
赞
踩

今天,我们将探讨序列到序列 (seq2seq) 模型的复杂工作原理,特别关注编码器-解码器架构和注意力机制。这些概念是各种 NLP 应用的基础,从机器翻译到问答系统。
这是可以期待的:
- Seq2Seq模型中的编码器-解码器框架:深入研究 Seq2Seq 模型的核心结构,其中我们解开了编码器和解码器的角色和功能。本节将阐明这两个组件如何相互作用以有效地处理和翻译各种 NLP 任务中的序列。
- 注意力机制:增强 Seq2Seq 模型:了解注意力机制在完善 Seq2Seq 模型中的关键作用。我们将探讨它如何解决编码器-解码器框架的局限性,特别是在处理长序列方面,以及它对输出的准确性和连贯性的影响。
- 何时使用这些模型:深入了解具有注意力机制的 Seq2Seq 模型的实际应用。本节将指导您完成各种场景和用例,帮助您了解这些模型在 NLP 领域中的位置和原因特别有效。
- 实际实施: 语言翻译示例:通过动手语言翻译示例逐步实现实际应用。从数据预处理到模型构建和训练,本综合指南将为您提供在实际场景中应用Seq2Seq模型的具体知识。
请继续关注这些先进的 NLP 概念,将理论见解与实际应用相结合,丰富多彩的旅程。无论您是初学者还是经验丰富的从业者,这篇博文都旨在增强您在 NLP 动态领域的理解和技能。
二、Seq2Seq模型中的编码器-解码器框架
序列到序列模型彻底改变了我们在 NLP 中处理语言任务的方式。核心思想是将输入序列(如句子中的单词)映射到输出序列(如另一种语言的翻译单词)。这种映射是通过两个主要组件实现的:编码器和解码器,通常使用长短期记忆 (LSTM) 网络或门控循环单元 (GRU) 实现。
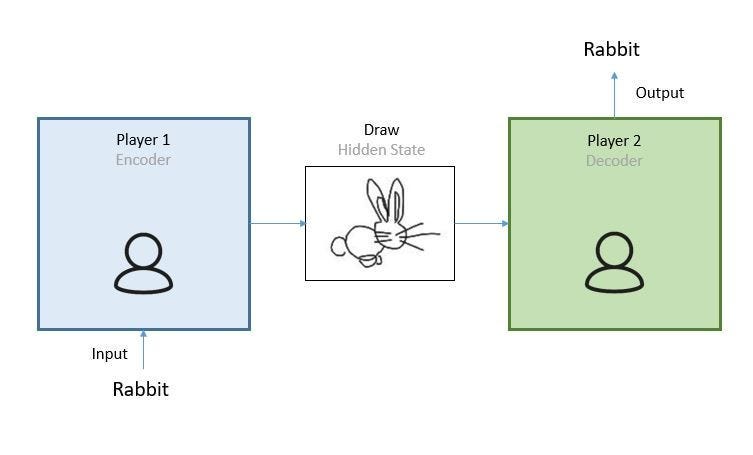
2.1 编码器:
编码器的工作是读取和处理输入序列。在 LSTM 的背景下,这涉及:
- Xi:这表示时间步长 i 的输入序列。
- hi and ci:在每个时间步长中,LSTM 保持两种状态——隐藏状态 (h) 和单元状态 (c),它们在时间步长 i 处共同形成 LSTM 的内部状态。
- Yi:尽管编码器确实在每个时间步生成一个输出序列 Yi,其特征是词汇表上的概率分布(使用 softmax),但这些输出通常被丢弃。我们保留的是内部状态(隐藏状态和单元状态)。
编码器的最终内部状态(我们称之为上下文向量)被认为封装了整个输入序列的信息,为解码器生成有意义的输出奠定了基础。
2.2 译码器:
解码器是另一个 LSTM 网络,它接管编码器中断的地方。它使用编码器的最终状态作为其初始状态:
- 初始化: 解码器的初始状态是编码器的最终状态(上下文向量)。
- 操作:解码器在每个时间步长中,使用前一个单元的隐藏状态生成输出以及它自己的隐藏状态。
- 输出生成:每个时间步长的输出y_t是使用 softmax 函数计算的。此函数在输出词汇上生成概率分布,帮助确定最终输出(如翻译中的单词)
解码器通过对上下文向量及其先前的输出进行条件反射,有效地学习生成目标序列。
三、注意力机制:增强 Seq2Seq 模型
虽然编码器-解码器架构为序列映射提供了强大的框架,但它并非没有局限性。一个关键问题是依赖于固定长度的上下文向量来编码整个输入序列,这对于长序列来说可能是个问题。这就是注意力机制发挥作用的地方。
3.1 注意力如何工作:
注意力机制允许解码器将注意力集中在编码器输出的不同部分,用于解码器自身输出的每一步。从本质上讲,它计算权重分布(或注意力分数),以确定每个输入元素对每个输出的重要性。
- 注意力分数: 这些是根据解码器的当前状态和每个编码器的输出计算得出的。
- 上下文向量:这是编码器输出的加权总和,权重由注意力分数给出。
- 解码器的输入:上下文向量与解码器的输入(在许多情况下,是前一个输出)组合在一起以生成当前输出。
注意力机制提供了更动态的编码过程,使模型能够为更长的序列生成更准确和连贯的输出。
3.2 何时使用这些模型
3.2.1 带编码器-解码器的 Seq2Seq
- 适用于输入和输出序列具有不同长度和结构的任务。
- 常用于机器翻译、文本摘要和语音识别。
3.2.2 注意力机制
- 对于上下文对于固定大小的向量来说可能过于宽泛的较长序列至关重要。
- 增强了处理复杂输入(如对话上下文或详细文本)的模型。
四、实际实施:语言翻译示例
4.1 第 1 步:数据预处理
为简单起见,我们将使用一种非常基本的预处理形式。

4.2 第 2 步:构建模型
接下来,我们用注意力层构建 seq2seq 模型。
4.3 步骤 3:训练模型
我们将目标文本转换为分类数据进行训练。请注意,在实际场景中,您应该使用更多数据并执行训练-测试拆分。
- from tensorflow.keras.utils import to_categorical
- decoder_target_data = to_categorical(target_texts, num_decoder_tokens)
- model.fit([input_texts, target_texts], decoder_target_data, batch_size=64, epochs=50, validation_split=0.2)
4.4 第 4 步:推理模型
为编码器和解码器设置推理模型。
- # Encoder Inference Model
- encoder_model = Model(encoder_inputs, encoder_states)
-
- # Decoder Inference Model
- decoder_state_input_h = Input(shape=(latent_dim,))
- decoder_state_input_c = Input(shape=(latent_dim,))
- decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
- decoder_outputs, state_h, state_c = decoder_lstm(decoder_embedding, initial_state=decoder_states_inputs)
- decoder_states = [state_h, state_c]
- decoder_outputs = decoder_dense(decoder_outputs)
- decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states)
4.5 第 5 步:翻译功能
最后,让我们为翻译过程创建一个函数。
此代码提供了一个基本框架来理解具有注意力的 seq2seq 模型的工作原理。请记住,这是一个简化的示例。对于实际应用,您需要更复杂的预处理、更大的数据集和模型参数的微调。



