
- 1Kafka入门-zookeeper与kafka集群安装与配置,kafka架构与原理,kafka API使用以及kafka eagle安装与使用_kafka eagle api
- 2Docker技术原理_docker原理
- 30205基础语法
- 4左移运算符和右移运算符
- 5AI项目八:yolo5+Deepsort实现目标检测与跟踪(CPU版)_yolov5 目标检测cpu
- 6关于写Windows service程序启动和停止需要注意的几个地方_winapi servicemain 不能启动
- 7零基础学编程,从入门到精通,中文编程工具下载,时间选择构件用法
- 8Unity3D开发WebAR,可以在手机上面使用_unity webgl ar
- 9回退上传到服务器的文件,源码上传到服务器文件
- 10STM32常见问题与C语言常识
SPSS Modeler决策树和神经网络模型对淘宝店铺服装销量数据预测可视化|数据分享...
赞
踩
全文链接:https://tecdat.cn/?p=34859
本文阐述了服装店铺营销的现状,为客户提出了将数据挖掘技术应用到服装营销中的方案(点击文末“阅读原文”获取完整代码数据)。
相关视频
在分析决策树算法的基础上,介绍了决策树神经网络和算法及其的构造,并使用该算法对淘宝店铺客户数据(查看文末了解数据免费获取方式)进行分类及对新客户类型预测,实现对商业数据中隐藏信息的挖掘,且对该挖掘模型进行了验证。
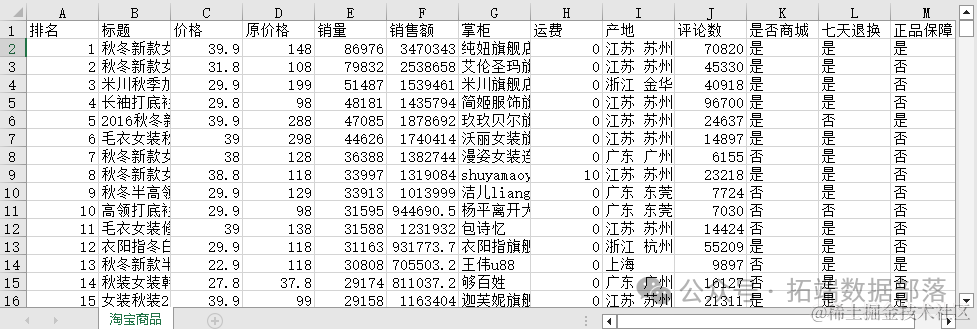
淘宝店铺原始数据
现在店铺面临的一个共同问题是店铺数据量非常大,而其中真正有价值的信息却很少。数据挖掘技术的出现,给店铺决策者带来了辅助决策支持。店铺可以利用先进的数据挖掘和商务智能分析技术对信息进行加工,店铺领导必须将经营模式转变为以客户为中心,为客户提供个性化服务。
建模前的准备过程
主要包括数据的抽取、数据的预处理、重要变量的描述统计。数据的预处理具体包括数据的清晰、属性的筛选、数据的平衡、数据的归一化、数据的离散化。
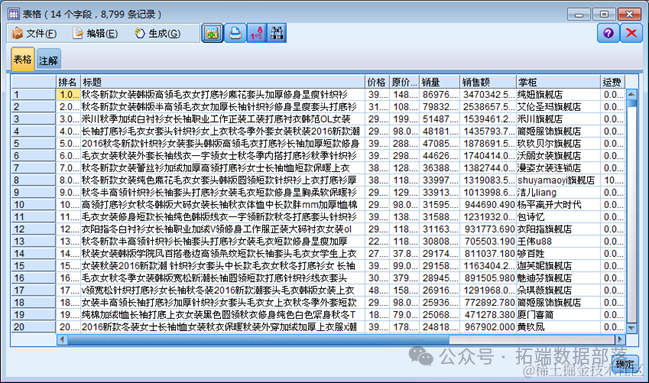
接下来我们打开 Modeler,新建 Stream,拖入一个“可变文件”节点到工作区。双击节点。选择示例数据文件作为输入。然后我们点击“可变文件”节点的预览按钮。得到结果如图:
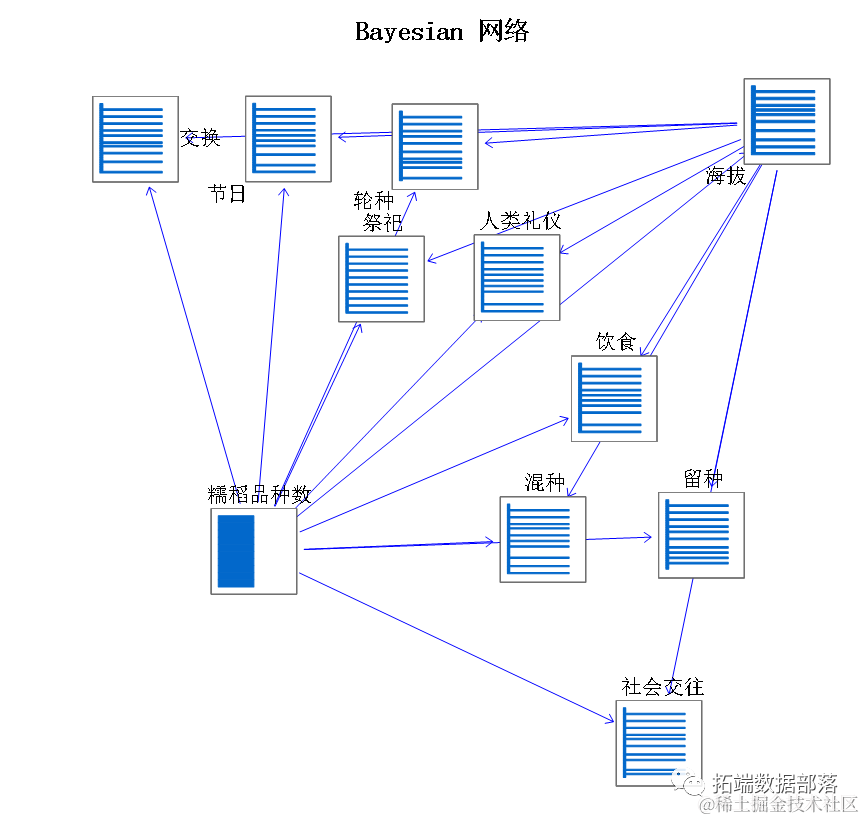
利用“数据审核”节点审核数据
“数据审核”节点可以提供给我们很多有用的信息,其中就包括数据缺失值信息。
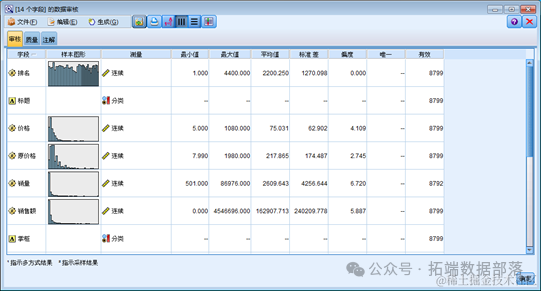
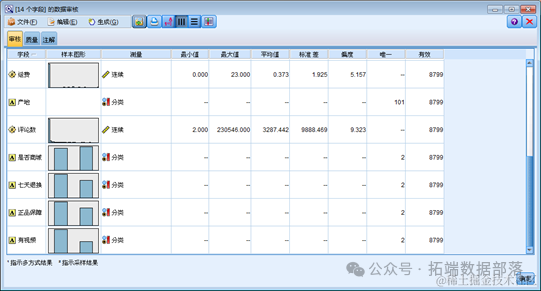
从上图中我们可以看到很多有用的信息,数据的分布图形,数据的类型,统计值等,在这里我们要关注的是最后一列有效数据,从销量来看可以发现有七个缺失值 ,这说明 “数据审核”节点已经成功的帮我们识别出了这列缺失值。同时我们可以发现有效数据仍然是 8792。
点击标题查阅往期内容
数据分享|spss modeler用贝叶斯网络分析糯稻品种影响因素数据可视化

左右滑动查看更多
01
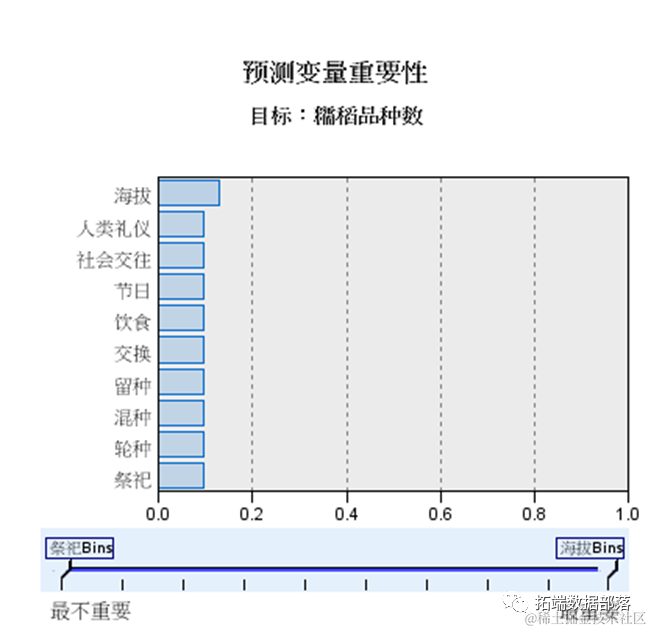
02
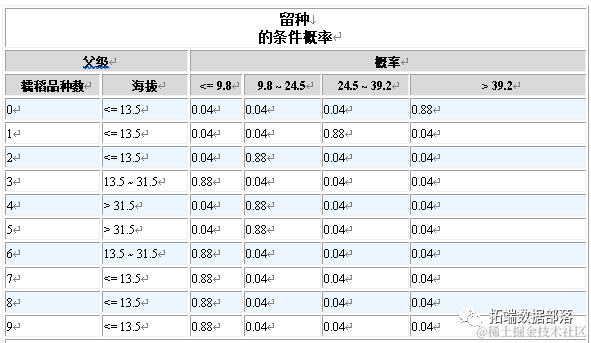
03
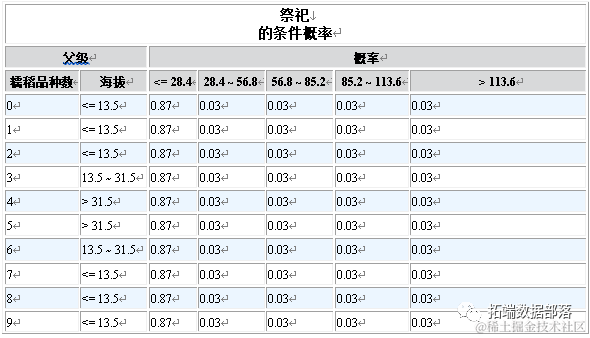
04
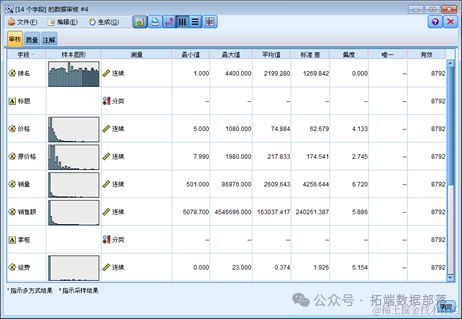
下边我们在 Modeler 中定义缺失值。
在类型页里我们发现有一列名为“缺失”,我们在销量这一列我们点击缺失这以空白项。
如上图,我们选择“定义空白”,添加一个缺失值为“无”。然后点击确定,关闭窗口。然后重新检查数据:
可以看到,其他变量的样本数也变成了8792,说明缺失值已经删去。
然后我们对数据进行异常点处理。
对于连续型数据,运行数据审核节点,在质量页面我们就可以查看离群值和极值。默认情况下,Modeler 是根据平均值的标准差来确定离群值和极值的。
得到异常值处理的结果:
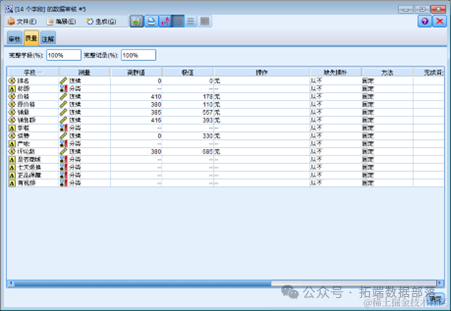
我们可以发现,数据中含有大量的异常点和极值。因此,我们需要把这些样本删除。
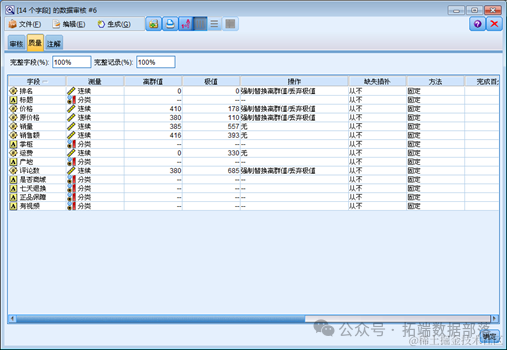
选择工具条里的生成按键,选择离群值和极值超节点。这时,Modeler 会帮我们自动生成一个过滤离群值和极值的超节点。我们连接“可变文件”节点和这个超节点,Modeler 就会帮我们按照我们期望的处理方式来处理离群值和极值。
然后我们可以得到以下的均值比较结果:
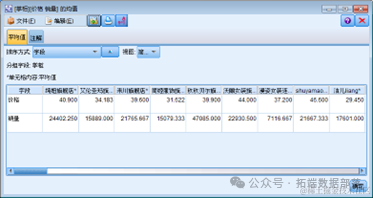
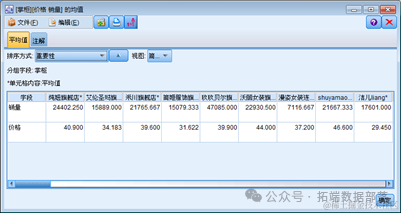
从结果我们可以判断影响用户会选择哪一个店家的重要因素是该店铺的销量而非价格。
数据的建模与仿真
决策树演算法是在进行数据挖掘时经常使用的分类和预测方法。
一个决策树的架构,是由三个部分所组成:叶节点 (Leaf Node)、决策节点 (Decision nodes) 以及分支 。决策树演算法的基本原理为:通过演算法中所规定的分类条件对于整体数据进行分类,产生一个决策节点,并持续依照演算法规则分类,直到数据无法再分类为止。
决策树演算法依据其演算原理以及可适用分析数据类型的不同延伸出多种决策树演算法。在 IBM SPSS Modeler 中,主要提供了四种常用的决策树演算法供使用者选择,分别为:C5.0、CHAID、QUEST 以及 C&R Tree 四种。
模型的建立
建立决策树模型串流
为了产生决策树模型,我们需要在数据建模前就定义好各栏位的角色,也就是加入字段选项下的「类型」节点。将类型节点拉入串流后,我们会先点选读取值按钮,接着设定角色。在本案例中,栏位 y 是我们最后预测的目标,因此先将其角色设定为“目标”,余下的栏位则是要设定为“输入”。
数据分区
为了在训练出模型后能够分析模型准确度,在此我们将加入字段选项下的「分区」节点,将数据分为 70%训练数据以及 30%测试数据。
考量到数据特性以及我们希望提供的决策树具有多元分类法,因此我们将建立 chaid分类模型。
CHAID 节点设定
将 CHAID 节点与分区节点连结后,我们将于此节点编辑页面中的模型标签下设定相关的变数。由于 CHAID 节点设定较多,以下将挑选我们有修改预设值的变数进行详细介绍。此定义来自“SPSS Modeler 15 Modeling Nodes 文件”。
生成决策树模型
决策树节点设定完成后,点击主工具列的运行当前流前即可看到两个决策树模型的产生。查看器标签则是将一样的决策树结果用树状图的方式展现。
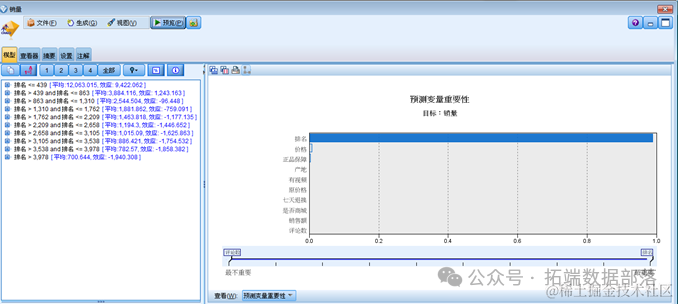
从上图中我们可以看到预测变量的重要性,排名是对销量变量影响最大的变量。其次是价格和正品保障。
分析结果
在前面的串流产生中,我们加入了分区节点将数据分成训练数据与测试数据,因此在决策树模型产生后,可加入分析节点 。分析节点中我们勾选重合矩阵选项,因此除了分析节点原本就提供的正确错误率比较,可进一步了解实际值与预测值的比较矩阵 。
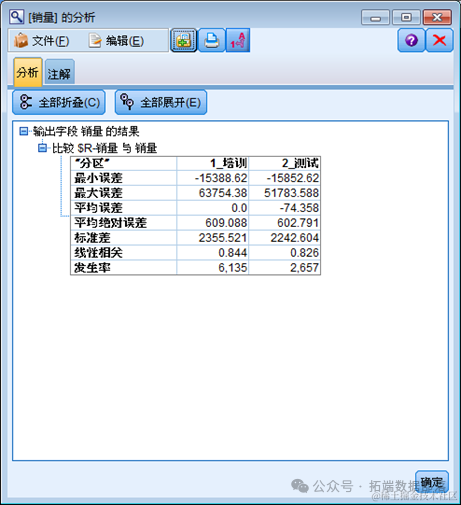
然后我们对该数据进行神经网络分析。
然后我们可以得到如下的神经网络模型结果:
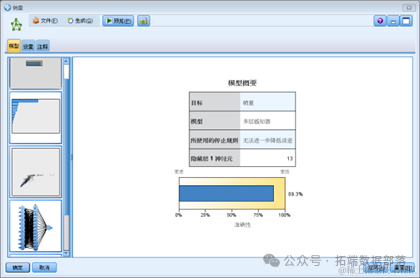
上图是对神经网络模型的一个概要,其中包括目标变量,使用的模型,使用的停止规则以及神经元的个数,还有该模型的正确率。同时我们也可以得到,预测变量的重要性。
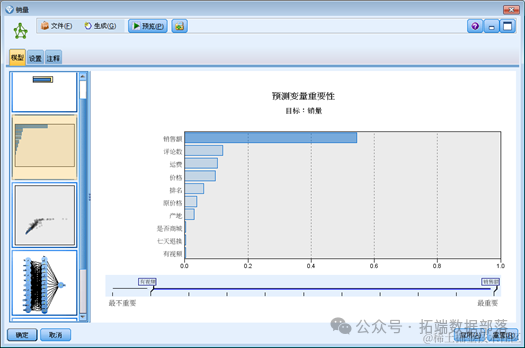
从上面的图形中我们可以判断,对销量影响最大的变量是销售额,然后是评论数,其次是运费,价格排名,原价格等等。从上面的结果我们可以判断神经网络模型得到的变量重要性,和决策树模型得到的结果有些不同。
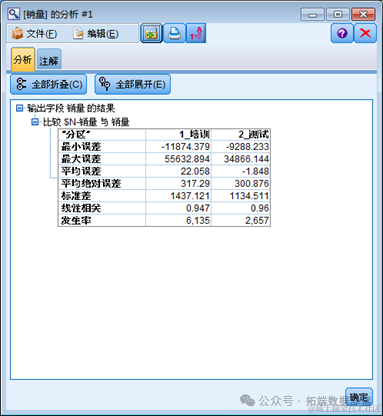
因此下面我们还要对神经网络模型和决策树模型在测试集上的准确度表现进行对比。
分析结果
在前面的串流产生中,我们加入了分区节点将数据分成训练数据与测试数据,因此在决策树模型产生后,可加入分析节点 。分析节点中我们勾选重合矩阵选项,因此除了分析节点原本就提供的正确错误率比较,可进一步了解实际值与预测值的比较矩阵 。
结论与决策、建议
本文的预测系统使用了神经网络模型和决策树模型,建立了服装销售量预测模型,实现了服装销售量的预测以及结果分析,并且通过变量重要性图以及误差分析对比,让店铺了解该商品的重要影响因素是销售额、评论、价格等等,使得决策者可以有一个合理的服装销量的预测值。
因此,服装店铺可以根据以上所得的决策树模型来分析客户数据,获得各类会员的特点,对客户进行分类,实现对客户价值度、客户结构等的研究。这样有助于店铺为不同类型的客户制定针对性的营销策略,找到针对性强的销售分市场,稳定并扩大客户群体。
最后我们得到了结果文件:

模型的改进
模型可能还不够完善,服装销售额还要考虑其他因素,服装促销的费用,店面的规模等,模型需要进一步完善才行。同时,模型训练的数据也还可以增加,少量的训练数据不具备非常强的说服力。另外由于模型的误差还是比较大,因此,可以考虑进一步调整模型的参数,以提高模型的准确度。
参考文献
[1] 王惠文,吴载斌,孟杰.偏最小二乘回归的线性与非线性方法[M].北京:国防工业出版社,2006.9,1-2,32.
[2] 任露泉.回归设计及其优化[M].北京:科学出版社,2009,20,248. [3] 黄强等.PC使用一册通[M] .北京:人民邮电出版社,1998,10.
[4] 周品,赵新芳.MATLAB数理统计分析[M].北京:国防工业出版社,2009.4,274.
数据获取
在公众号后台回复“淘宝数据”,可免费获取完整数据。

本文中分析的数据分享到会员群,扫描下面二维码即可加群!

点击文末“阅读原文”
获取全文完整文件数据报告资料。
本文选自《SPSS Modeler决策树和神经网络模型对淘宝店铺服装销量数据预测可视化》。


点击标题查阅往期内容
数据分享|R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言逻辑回归logistic模型分析泰坦尼克titanic数据集预测生还情况
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
R语言用局部加权回归(Lowess)对logistic逻辑回归诊断和残差分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言用线性模型进行臭氧预测:加权泊松回归,普通最小二乘,加权负二项式模型,多重插补缺失值
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言多元时间序列滚动预测:ARIMA、回归、ARIMAX模型分析
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据

![]()



