
- 1分类预测 | Matlab实现OOA-CNN-SVM鱼鹰算法优化卷积支持向量机分类预测
- 2C++ 大数组定义在main函数中不能执行,将其定义为全局变量可以执行——BSS段、数据段、代码段、堆与栈及五大内存分区——堆栈的空间大小_c++将主函数中的数组设置为全局变量
- 3Docker使用
- 4springboot整合线程池_springboot 融合 thread
- 5第一章-初识Java与Java基础_java1.6 与java11.0.16
- 6Baichuan2大模型与SAIL奖“东方.翼风”重磅发布,MindSpore SPONGE暑期学校第三季圆满收官_percnn
- 7adb查询终端键值_adb获取按键值
- 8手机壳也能散热了?
- 9在Docker Desktop中安装Kubernetes_docker desktop kubernetes
- 10ALBERT 论文笔记_微调albert时显存占用很大
R语言KNN模型分类信贷用户信用等级数据参数调优和预测可视化|数据分享
赞
踩
全文链接:https://tecdat.cn/?p=34941
本文主要介绍了如何帮助客户通过读取信贷数据(查看文末了解数据免费获取方式)、查看部分数据、转换数据为因子并将数值变量归一化、进行描述性分析、建立knn模型等步骤对数据进行分析(点击文末“阅读原文”获取完整代码数据)。
相关视频
通过分别选择不同的k值进行建模,并对比它们的准确度,找到最优的参数k。文章还介绍了如何扩大参数的范围,找到最优的k值,并绘制数据的散点图,查看每个分类的分布情况。通过图表分析,得出了模型的预测点和实际点的符合程度较好的结论。
读取数据
credit <- read.table("man.data")查看部分数据
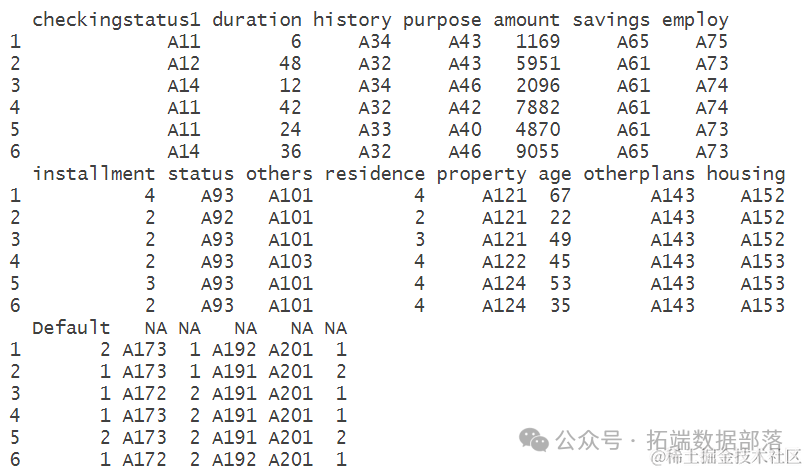
根据对数据集的命名和查看,可以看出数据集包含了多个变量,如checkingstatus1、duration、history等,这些变量代表了不同的个人和贷款信息。数据集的前几行展示了每个变量的取值情况,以及最后一列是目标变量"Default",它表示了客户是否违约。这些信息对于理解数据集的结构和内容非常重要。在进一步的分析中,这些变量将被用于建立模型,以预测客户是否会违约。
转换数据为因子,并且将数值变量归一化
- germalt <- factor(germanault)
-
- gemadit[sapply(germt, is.numeric)] <- lapply(gerdit[sapply(germanit, is.numeric)], scale)
对数据进行描述性分析
summary(gerdit.subset)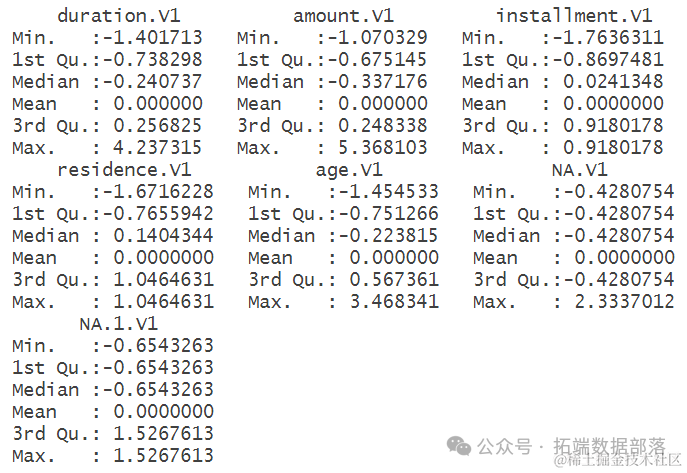
根据对数据进行描述性分析的结果,可以看出各个变量的分布情况。例如,duration.V1(借款周期)、amount.V1(借款金额)、installment.V1(分期付款)等变量的最小值、最大值、中位数和平均值等统计信息。通过这些统计信息,可以初步了解数据的范围和分布情况,为后续建模和分析提供基础。例如,可以看出借款周期和借款金额的方差较大,而分期付款的方差较小,这些信息对于理解数据的特点和规律具有重要意义。
knn模型
将数据分区,70%为训练集,30%为测试集,建立knn模型,然后对比模型的准确度
- set.seed(111)
- test <-sample(1:nrow(germ.subset),nrow(germubset)*0.2)
然后我们分别选取,不同的k作为knn模型的参数,得到模型的结果之后,对比它们的准确度,从而选出最优的参数k。
分别对不同的参数进行建模
- knn.1 <- k train.def, k=1)
- it, train.def, k=5)
- kndef, k=20)
然后分别计算不同参数下的准确度:
- ## test.def
- ## knn.1 0 1
- ## 0 54 11
- ## 1 21 14
-
-
- ## [1] 0.535
-
- ## test.def
- ## knn.5 0 1
- ## 0 62 13
- ## 1 13 12
-
- ## [1] 0.545
-
- ## test.def
- ## knn.20 0 1
- ## 0 69 13
- ## 1 6 12
-
- ## [1] 0.605

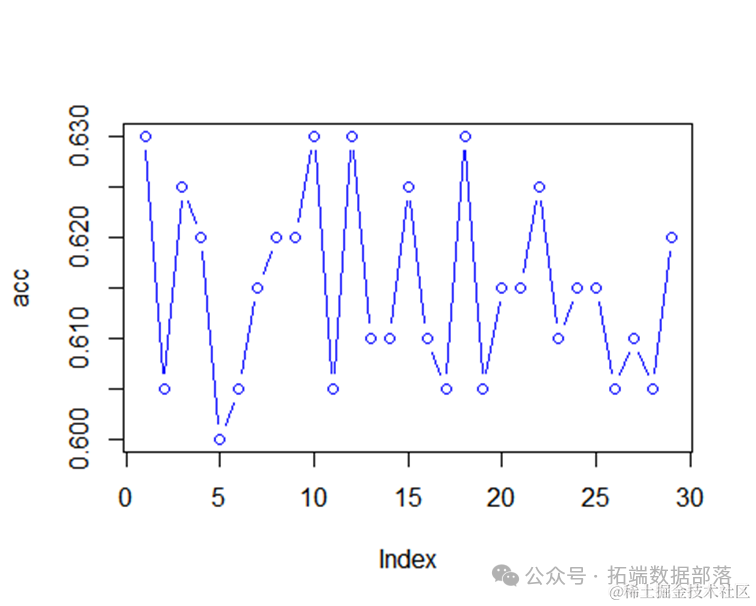
从不同的近邻数的结果来看,我们可以发现当参数为20的时候,模型的准确率最高为0.605。
因此我们可以认为最优的knn参数是20。
扩大参数的范围,使参数从2到30变化,并分别计算不同参数下的准确度,从而找到最优的参数。
- acc=numeric(0)
- for(k in 2:30){
-
- plot(acc,type="b",col="blue")
点击标题查阅往期内容

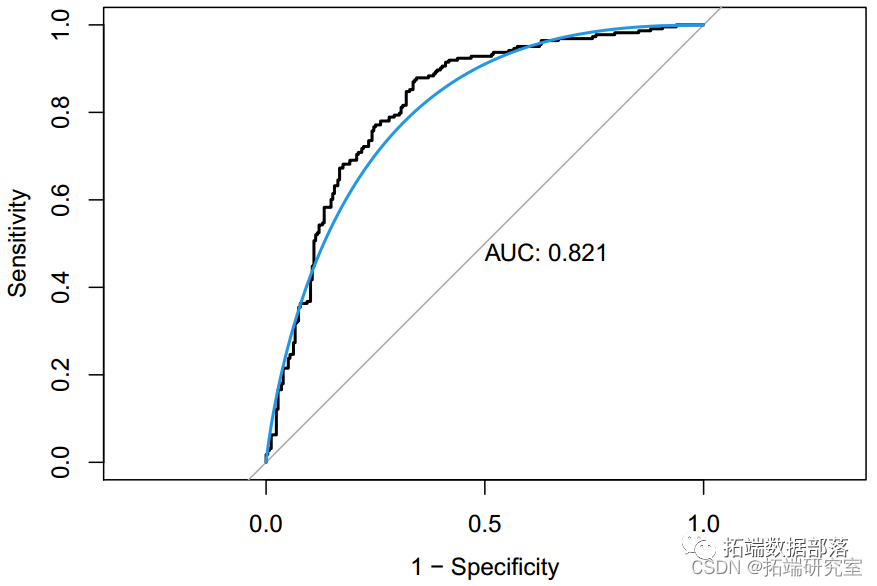
数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC

左右滑动查看更多
01

02
03
04
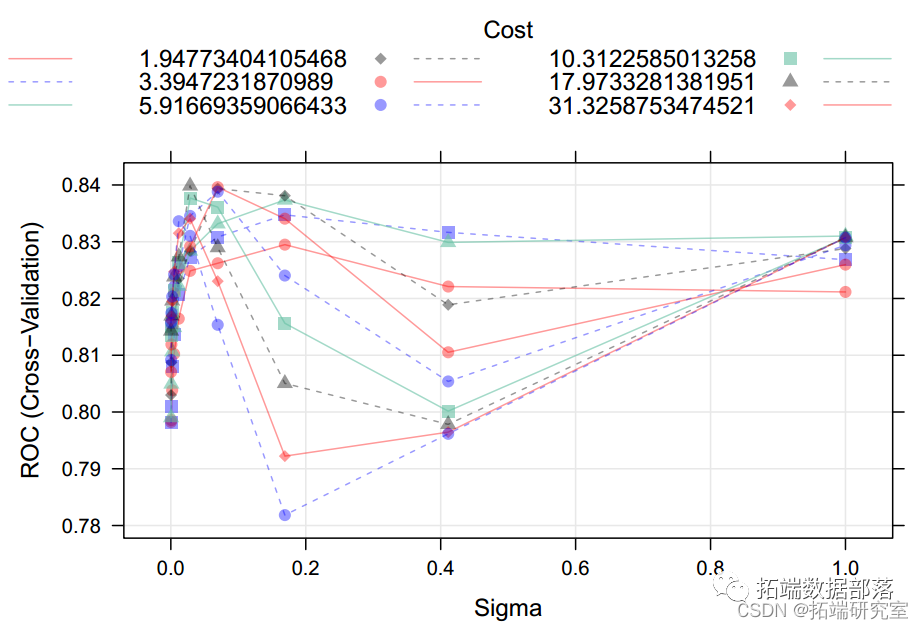
- #查看最优k
- which.max(acc)+1
-
- ## [1] 2
因此,最优的k为2。
绘制数据的散点图,查看每个分类的分布情况
plot(train.germancredit[,c("amount","duration")],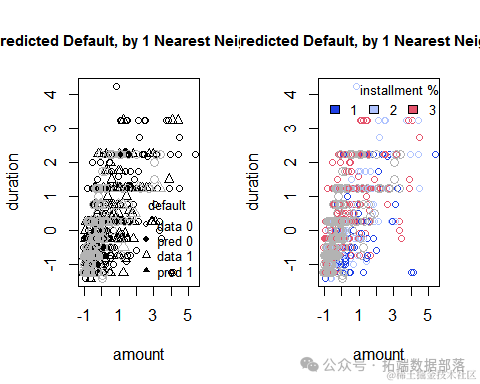
图中四种颜色的点分别表示以下四个种类的用户:
图中的圆形和三角形分别代表没有信贷的用户和有信贷的用户。实心点和空心点,分别代表着预测的数据和实际的数。从散点图的结果来看空心点和实心点的覆盖重合度较高,说明模型的预测点和实际点的符合程度较好。同时可以看到不同的客户,信用等级的分类出现了不同的分布情况。三角形代表信用较好的客户,他们的借款周期一般较短,借款金额也较少。而圆形的点代表没有信贷的用户,他们的借款周期较长,借款金额较大,存在信贷危机。
数据获取
在公众号后台回复“信贷数据”,可免费获取完整数据。

本文中分析的数据分享到会员群,扫描下面二维码即可加群!

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言KNN模型分类信贷用户信用等级参数调优和预测可视化》。


点击标题查阅往期内容
数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC
Python信贷风控模型:Adaboost,XGBoost,SGD, SVC,随机森林, KNN预测信贷违约支付
Python进行多输出(多因变量)回归:集成学习梯度提升决策树GRADIENT BOOSTING,GBR回归训练和预测可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线

![]()



