
前言
社区在Flink 1.12版本通过FLIP-146提出了增强Flink SQL DynamicTableSource/Sink接口的动议,其中的一个主要工作就是让它们支持独立设置并行度。很多Sink都已经可以配置sink.parallelism参数(见FLINK-19937),但Source还没动静。这是因为Source一直以来有两种并行的标准,一是传统的流式SourceFunction与批式InputFormat,二是原生支持流批一体的FLIP-27 Source,并且Connector之间的实现并不统一。
笔者最近在Flink钉群闲逛时,经常看到如下图所示的发言,可见大家对Source(主要是Kafka Source)支持独立设置并行度的需求比较急切。


本文就来基于1.13.0版本实现该需求,注意此版本的SQL Kafka Source尚未迁移到FLIP-27。这项改进已经过验证,可以在生产环境使用,但仍属于过渡方案,故不会向社区发起PR。
实现ParallelismProvider
ScanTableSource的运行时逻辑需要由ScanTableSource.ScanRuntimeProvider来提供,一共有5种,如下图所示。
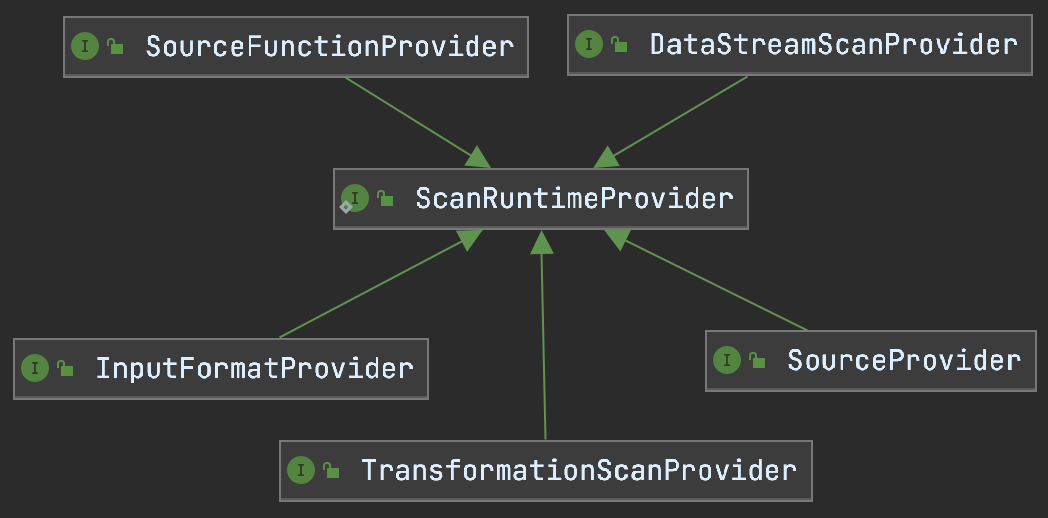
显然我们要修改SourceFunctionProvider,让它实现FLIP-146定义的ParallelismProvider接口,表示它支持独立设置并行度。代码很简单:
- @PublicEvolving
- public interface SourceFunctionProvider extends ScanTableSource.ScanRuntimeProvider, ParallelismProvider {
-
- /** Helper method for creating a static provider. */
- static SourceFunctionProvider of(SourceFunction<RowData> sourceFunction, boolean isBounded) {
- return new SourceFunctionProvider() {
- @Override
- public SourceFunction<RowData> createSourceFunction() {
- return sourceFunction;
- }
-
- @Override
- public boolean isBounded() {
- return isBounded;
- }
- };
- }
-
- /** Helper method for creating a static provider with a provided parallelism. */
- static SourceFunctionProvider of(SourceFunction<RowData> sourceFunction, boolean isBounded, Integer sourceParallelism) {
- return new SourceFunctionProvider() {
- @Override
- public SourceFunction<RowData> createSourceFunction() {
- return sourceFunction;
- }
-
- @Override
- public boolean isBounded() {
- return isBounded;
- }
-
- @Override
- public Optional<Integer> getParallelism() {
- return Optional.ofNullable(sourceParallelism);
- }
- };
- }
-
- /** Creates a {@link SourceFunction} instance. */
- SourceFunction<RowData> createSourceFunction();
- }

添加scan.parallelism参数
在o.a.f.table.factories.FactoryUtil中添加:
- public static final ConfigOption<Integer> SCAN_PARALLELISM =
- ConfigOptions.key("scan.parallelism")
- .intType()
- .noDefaultValue()
- .withDescription(
- "Defines a custom parallelism for the scan source. "
- + "By default, if this option is not defined, the planner will derive the parallelism "
- + "for each statement individually by also considering the global configuration.");
修改Kafka Connector
首先修改KafkaDynamicSource:
- 在构造方法中添加
@Nullable Integer parallelism及相关的代码; -
getScanRuntimeProvider()方法的最后:
return SourceFunctionProvider.of(kafkaConsumer, false, parallelism);- 在
copy()/equals()/hashCode()方法内加上parallelism。
然后修改KafkaDynamicTableFactory,加入SCAN_PARALLELISM参数,以及使用带并行度的KafkaDynamicSource构造方法,不再赘述。
修改Source物理执行节点
负责使ScanTableSource发挥作用的物理执行节点为CommonExecTableSourceScan,注意到它的translateToPlanInternal()方法中,对不同类型的ScanRuntimeProvider分别做了处理。我们找到SourceFunctionProvider对应的那个判断分支,加上与并行度相关的代码。
- if (provider instanceof SourceFunctionProvider) {
- SourceFunction<RowData> sourceFunction =
- ((SourceFunctionProvider) provider).createSourceFunction();
- DataStreamSource<RowData> streamSource = env.addSource(
- sourceFunction, operatorName, outputTypeInfo);
-
- final int confParallelism = streamSource.getParallelism();
- final int sourceParallelism = deriveSourceParallelism(
- (ParallelismProvider) provider, confParallelism);
-
- Transformation<RowData> transformation = streamSource.getTransformation();
- transformation.setParallelism(sourceParallelism);
- return transformation;
- }
-
- private int deriveSourceParallelism(
- ParallelismProvider parallelismProvider, int confParallelism) {
- final Optional<Integer> parallelismOptional = parallelismProvider.getParallelism();
- if (parallelismOptional.isPresent()) {
- int sourceParallelism = parallelismOptional.get();
- if (sourceParallelism <= 0) {
- throw new TableException(
- String.format(
- "Table: %s configured source parallelism: "
- + "%s should not be less than zero or equal to zero",
- tableSourceSpec.getObjectIdentifier().asSummaryString(),
- sourceParallelism));
- }
- return sourceParallelism;
- } else {
- return confParallelism;
- }
- }
大功告成?
将全局并行度设为10,用一条简单的SQL语句测试一下:
- SELECT siteId, COUNT(orderId)
- FROM rtdw_dwd.kafka_order_done_log /*+ OPTIONS('scan.parallelism'='5') */
- WHERE mainSiteId = 10029
- GROUP BY siteId;

emm,看起来似乎不太对,为什么Source后面的Calc节点并行度也变成了5?这是因为Calc的并行度默认以输入流的并行度决定,所以我们还要提供强制打断算子链的选项,让Calc能够恢复全局并行度。
在ExecutionConfigOptions中加入一个参数table.exec.source.force-break-chain:
- @Documentation.TableOption(execMode = Documentation.ExecMode.STREAMING)
- public static final ConfigOption<Boolean> TABLE_EXEC_SOURCE_FORCE_BREAK_CHAIN =
- key("table.exec.source.force-break-chain")
- .booleanType()
- .defaultValue(false)
- .withDescription(
- "Indicates whether to forcefully break the operator chain after the source.");
然后在上面改过的CommonExecTableSourceScan代码中,加入对此参数的判断,如果为true,则调用disableChaining()方法断链。
- final Configuration config = planner.getTableConfig().getConfiguration();
- if (config.get(ExecutionConfigOptions.TABLE_EXEC_SOURCE_FORCE_BREAK_CHAIN)) {
- streamSource.disableChaining();
- }
最后不要忘了修改CommonExecCalc。如果它的输入是CommonExecTableSourceScan且上述参数生效,那么就将它的并行度直接置为PARALLELISM_DEFAULT,即全局并行度。
- @Override
- protected Transformation<RowData> translateToPlanInternal(PlannerBase planner) {
- final ExecEdge inputEdge = getInputEdges().get(0);
- final Transformation<RowData> inputTransform =
- (Transformation<RowData>) inputEdge.translateToPlan(planner);
- final CodeGeneratorContext ctx = /* ... */;
- final CodeGenOperatorFactory<RowData> substituteStreamOperator = /* ... */;
-
- int parallelism = inputTransform.getParallelism();
- if (inputEdge.getSource() instanceof CommonExecTableSourceScan) {
- final Configuration config = planner.getTableConfig().getConfiguration();
- if (config.get(ExecutionConfigOptions.TABLE_EXEC_SOURCE_FORCE_BREAK_CHAIN)) {
- parallelism = ExecutionConfig.PARALLELISM_DEFAULT;
- }
- }
- return new OneInputTransformation<>(
- inputTransform,
- getDescription(),
- substituteStreamOperator,
- InternalTypeInfo.of(getOutputType()),
- parallelism);
- }
再试一试,结果符合预期:
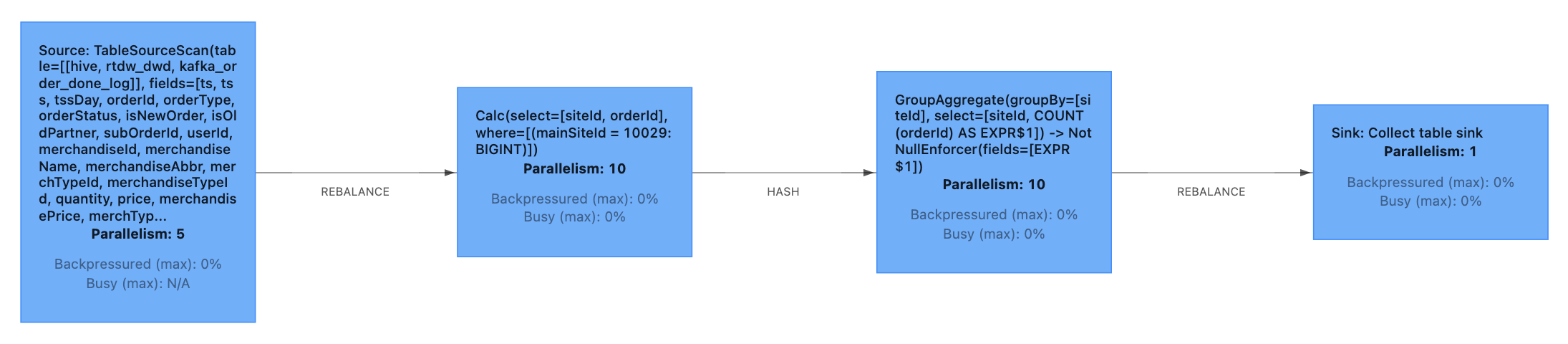
提供强制断链的参数还有一重好处,即能够在SQL作业并行度变化时安全地恢复现场。举个例子,若Source并行度和全局并行度起初都是5,但是在作业运行过程中发现下游处理速度不够,而将全局并行度提升到10的话,那么原有的checkpoint将无法使用——因为并行度的变化导致了作业拓扑变化。如果我们在一开始就将table.exec.source.force-break-chain设为true,那么上面所述的情况将不会造成困扰。
The End
民那晚安晚安。




