
- 12021最新版SpringBoot 速记
- 2一个 SpringBoot 项目能处理多少请求?_springboot单线程能处理多少个请求
- 3QueryWrapper的详细使用方法_querywrapper 分页
- 4openGL之API学习(七十五)opengl扩展GL_EXT_gpu_shader4
- 5怎么让linux支持yum,如何安装和使用'yum-utils'来维护Yum并提高其性能
- 6学生信息管理系统(数据库设计)_学生信息管理系统数据库设计
- 7SpringBoot 内置 Tomcat 线程数优化配置_spring boot tomcat配置线程池
- 8centos7查看资源占用情况命令_centos7 根据进程号查询目录的空间使用情况
- 9恶意代码行为_常见恶意代码列举有哪些
- 10Windows搭建Emby媒体库服务器,无公网IP远程访问本地影音文件_emby看电脑资源
Flink项目搭建与使用_建立一个flink项目
赞
踩
Flink项目搭建与使用
前言
本文不会介绍flink的概念与原理,如果对于Flink还不了解,先去看看flink的基础知识吧!
本文使用Java演示,Scala…我不会,这里不再展示。
这里提供几个地址:Flink官方文档 、个人感觉比较好的博客
环境准备
环境依赖
- JDK 1.8 及以上
- Maven 3.0.4 及以上
Flink基础依赖库
<properties> <flink.version>1.10.1</flink.version> </properties> <dependencies> <!--批量计算DataSet API--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <!--流式计算DataStream API--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>${flink.version}</version> </dependency> </dependencies>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
除了上述的Flink项目中必须依赖的基础库之外,如果还要添加其他依赖,例如Flink中内建的Connector,或者其他第三方依赖库,需要在项目中添加相应的Maven Dependences,并将这些Dependence的Scope配置成compile。
如果需要引入Hadoop相关依赖包,需要将Scope注明为provided,应为Flink集群已经将Hadoop依赖包添加在集群环境中(如下图所示),否则容易造成Jar包冲突。
Flink程序结构
DataStream API 主要可分为三个部分:DataSource模块、Transformation模块、DataSink模块。
官网提供的Flink 程序与数据流结构图如下:
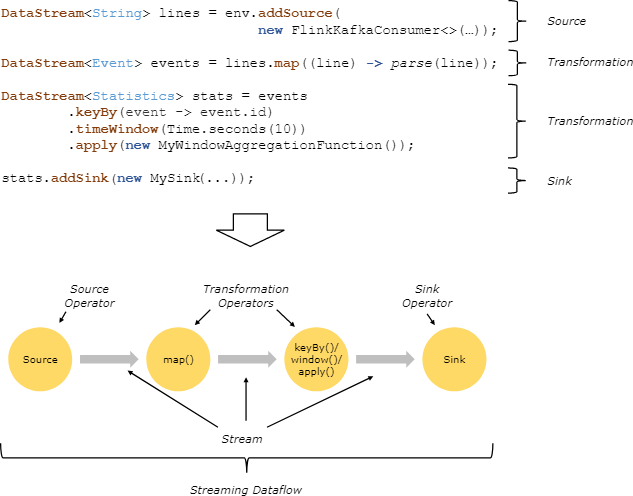
Flink程序一般分为5步,分别为: 设定Flink执行环境、创建和加载数据集、对数据集指定转换操作逻辑、指定计算结果的输出文职、调用execute方法触发程序执行。
批处理代码示例如下
// 批处理word count public class WordCount { public static void main(String[] args) throws Exception { // 第一步:创建执行环境 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); // 第二步:指定数据源地址,读取输入数据,这里读取本地文件的文本数据 DataSet<String> inputDataSet = env.readTextFile("D:\\project\\flinkLearn\\src\\main\\resources\\hello.txt"); // 第三步:对数据集指定转换操作逻辑, 按照空格分词展开转换成(word, 1)二元组进行统计 DataSet<Tuple2<String, Integer>> resultSet = inputDataSet.flatMap(new MyFlatMapper()) .groupBy(0) // 按照第一个位置的word分组 .sum(1); // 将第二个位置上的数据求和 // 第四步:指定就按结果输出位置,这里只做标准输出 resultSet.print(); // 批处理情况下print不需要execute // env.execute("Streaming WordCount"); } // 自定义类,实现FlatMapFunction接口 public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception { // 按空格分词 String[] words = value.split(" "); // 便利所有words包成二元组输出 for (String word : words) { out.collect(new Tuple2<>(word, 1)); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
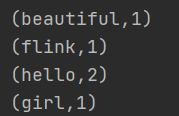
hello.txt:
hello beautiful girl
hello flink
- 1
- 2
结果如下:
流处理代码示例如下
public class StreamWordCount { public static void main(String[] args) throws Exception { // 第一步:创建流处理执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 用flink自带的parameter tool 工具从程序启动参数中提取配置项 ParameterTool parameterTool = ParameterTool.fromArgs(args); String hostname = parameterTool.get("host"); int port = parameterTool.getInt("port"); // 第二步:指定数据源地址,读取输入数据,这里从socket文本流读取数据 DataStreamSource<String> inputDataStream = env.socketTextStream(hostname, port); // 第三步:对数据集指定转换操作逻辑, 按照空格分词展开转换成(word, 1)二元组进行统计 SingleOutputStreamOperator<Tuple2<String, Integer>> resultStream = inputDataStream.flatMap(new WordCount.MyFlatMapper()) .keyBy(0) .sum(1); // 第四步:指定就按结果输出位置,这里只做标准输出 resultStream.print(); // 第五步:指定名称并触发流式任务 env.execute("Streaming WordCount"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
测试流处理,使用Liunx中的nc -lk <端口号>模拟数据流

结果:
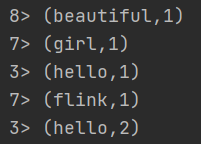
如上图所示,因为电脑cpu是8线程,所以这边没有设置的情况下,默认的slot会在1~8之间
Flink项目发布运行
Linux启动Flink
为了运行Flink,Linux只需提前安装好 Java 8 或者 Java 11。你可以通过以下命令来检查 Java 是否已经安装正确。
java -version
- 1
下载 release 1.12.0 并解压。
$ tar -xzf flink-1.12.0-bin-scala_2.11.tgz
$ cd flink-1.12.0-bin-scala_2.11
- 1
- 2
启动集群
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
- 1
- 2
- 3
- 4
提交作业(Job)
Flink 的 Releases 附带了许多的示例作业。你可以任意选择一个,快速部署到已运行的集群上。
# 这里使用Linux自带的示例jar,如果要运行自己的项目,路径指定为自己的项目路径即可
$ ./bin/flink run examples/streaming/WordCount.jar
$ tail log/flink-*-taskexecutor-*.out
(to,1)
(be,1)
(or,1)
(not,1)
(to,2)
(be,2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
另外,你可以通过 Flink 的 Web UI(http://localhost:8081) 来监视集群的状态和正在运行的作业。如下图所示
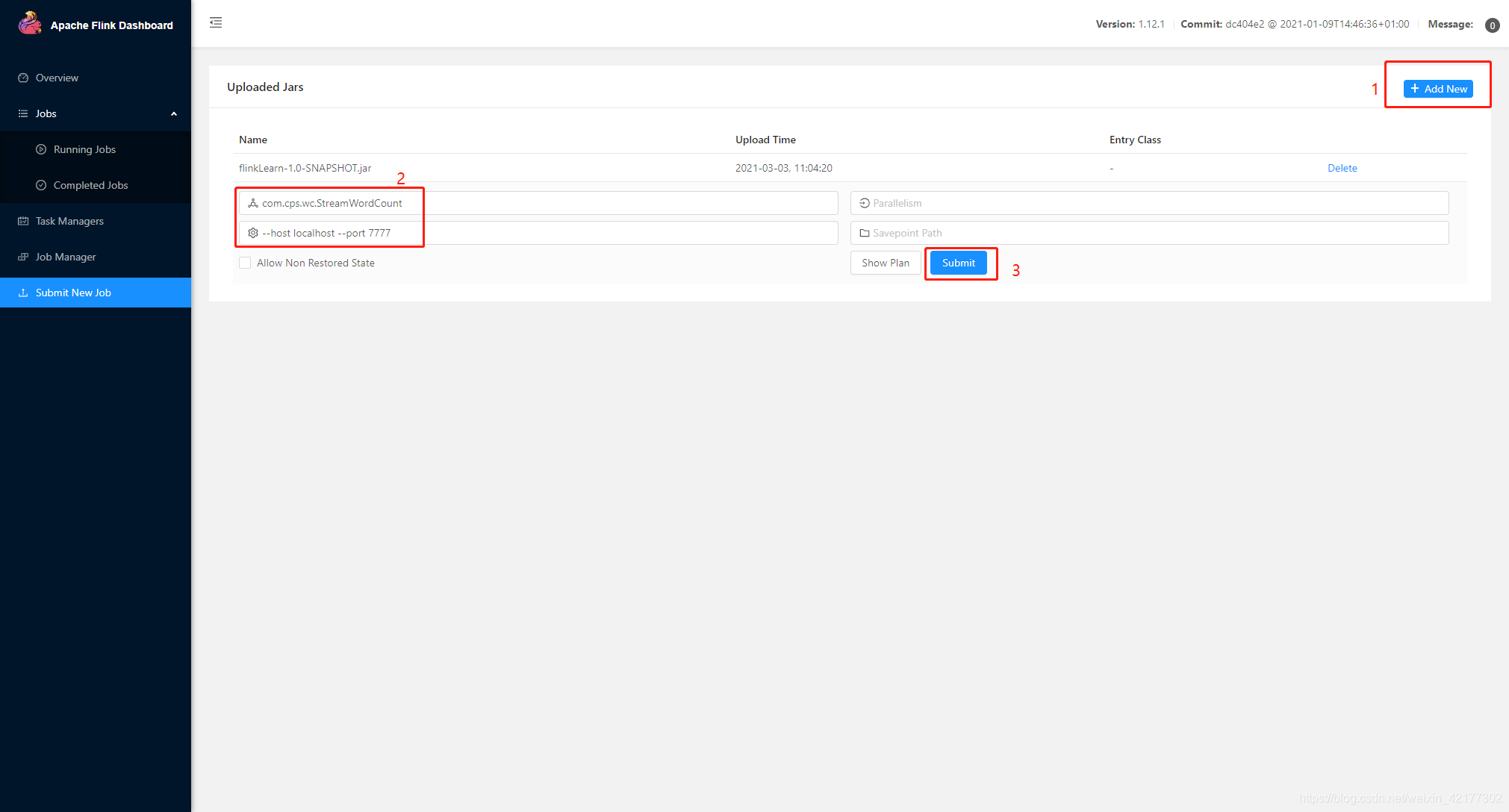
下图所示的地方可以查看输出结果
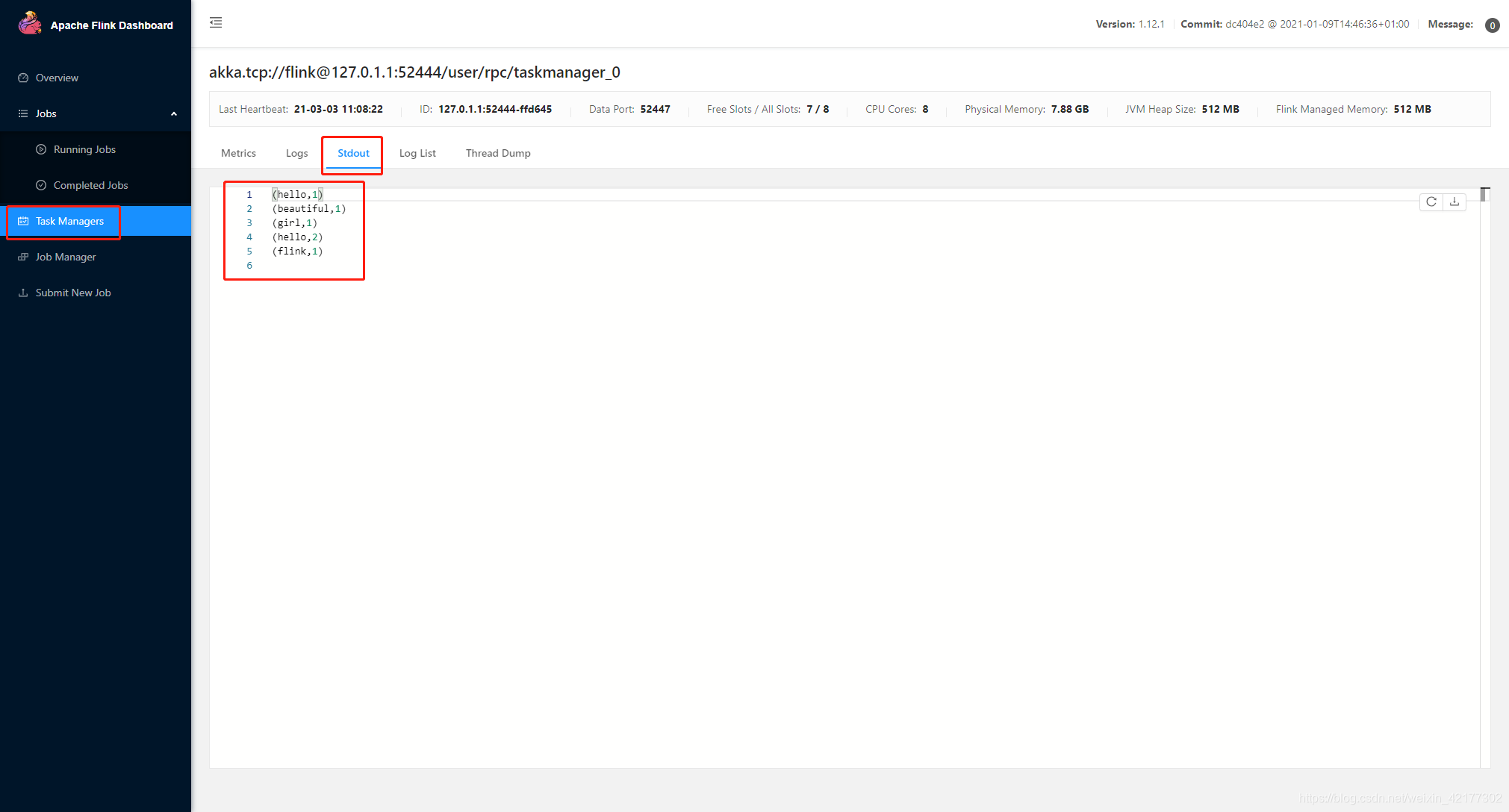
小结
这里介绍了基本的项目的搭建、发布运行的流程。其他的相关概念,比如具体的API的使用、Time、Watermark、Window、State、Checkpoint、Savepoint、集群部署、性能优化等相关内容,以后有机会再总结。




