
热门标签
热门文章
- 1RABC权限控制(二级菜单实现)
- 2bootstrapmodel确认操作框_Bootstrap使用模态框modal实现表单提交弹出框
- 3C++调用StartService启动服务失败1053分析与解决_startservice 1053
- 4Fix signatures do not match the previously installed version
- 5Java Web第十章(数据库连接池与DBUtils工具)_"queryrunner runner=new queryrunner(c3p0utils.getd
- 6docker 命令(总结和图解)_docker 命令图解
- 7《操作系统——精髓与设计原理(第八版)》复习题抄录_操作系统精髓与设计原理第八版答案
- 8spring源码解析之AbstractApplicationContext#refresh()方法刷新上下文过程_abstractwebapplicationrefreshcontext 未onapplicatio
- 9Bootstrap 中: data-toggle 与 data-target 的作用_buttondata-toggle
- 10Python解线性方程组的迭代法(1)————雅克比(Jacobi)迭代法_python中jacobi迭代法求解线性方程组
当前位置: article > 正文
Flink从入门到真香(17、使用flink table api 输出到文件和kafka)
作者:itrstu | 2024-01-29 17:43:10
赞
踩
flink写出到文件
对于流式查询,需要声明如何在表和外部连接器之间进行转换
与外部系统交换的消息类型,由更新模式(update model)指定,下面3种,能使用那种模式取决于输出的目标,比如如果输出到文件你就没法用更新和撤回模式,因为不知道,只能追加,但是如果换成mysql就都可以用
- 追加模式(Append)--文件系统只支持追加模式
表只做插入操作,和外部连接器只交换插入(insert)消息 - 撤回模式(Retract)--先删除再插入,实现更新操作
表和外部连接器交换添加(Add)和撤回(Retract)消息
插入操作(insert)编码为add消息;删除(delete)编码为retract消息;更新(update)编码为上一条的retract和下一条的add消息 - 更新插入模式(upsert)
更新和插入都被编码为upsert消息;删除编码为delete消息
栗子1-从一个文件读出来,做一波操作写到另一个文件
- /**
- *
- * @author mafei
- * @date 2020/11/22
- */
- package com.mafei.apitest.tabletest
-
- import org.apache.flink.streaming.api.scala._
- import org.apache.flink.table.api.DataTypes
- import org.apache.flink.table.api.scala._
- import org.apache.flink.table.descriptors.{Csv, FileSystem, Schema}
-
- object FileOutputTest {
- def main(args: Array[String]): Unit = {
- //1 、创建环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- env.setParallelism(1)
-
- val tableEnv = StreamTableEnvironment.create(env)
- //2、读取文件
- val filePath = "/opt/java2020_study/maven/flink1/src/main/resources/sensor.txt"
- tableEnv.connect(new FileSystem().path(filePath))
- .withFormat(new Csv()) //因为txt里头是以,分割的跟csv一样,所以可以用oldCsv
- .withSchema(new Schema() //这个表结构要跟你txt中的内容对的上
- .field("id", DataTypes.STRING())
- .field("timestamp", DataTypes.BIGINT())
- .field("temper", DataTypes.DOUBLE())
- ).createTemporaryTable("inputTable")
-
- val sensorTable = tableEnv.from("inputTable")
-
- //做简单转换
- val simpleTramsformTable = sensorTable
- .select("id,temper")
- .filter("id='sensor1'")
-
- //聚合转换
-
- val aggTable = sensorTable
- .groupBy('id)
- .select('id, 'id.count as 'count)
-
- //直接打印输出效果:
- simpleTramsformTable.toAppendStream[(String, Double)].print("simpleTramsformTable: ")
-
- //聚合的结果就不能用toAppendStream 因为他实现的是后面再来一条数据,表中就会增加一条,但是聚合的不是,是要更新之前的结果
- aggTable.toRetractStream[(String, Long)].print("aggTable")
- /**
- * 输出的效果:
- * aggTable> (true,(sensor1,1))
- * simpleTramsformTable: > (sensor1,1.0)
- * aggTable> (true,(sensor2,1))
- * aggTable> (true,(sensor3,1))
- * aggTable> (true,(sensor4,1))
- * aggTable> (false,(sensor4,1)) //false代表重新计算了
- * aggTable> (true,(sensor4,2))
- * aggTable> (false,(sensor4,2))
- * aggTable> (true,(sensor4,3))
- */
- // 输出到文件中
- val outputPath = "/opt/java2020_study/maven/flink1/src/main/resources/output.txt"
-
- tableEnv.connect(new FileSystem().path(outputPath))
- .withFormat(new Csv())
- .withSchema(
- new Schema()
- .field("id", DataTypes.STRING())
- .field("temper", DataTypes.DOUBLE())
- )
- .createTemporaryTable("outputTable")
- simpleTramsformTable.insertInto("outputTable")
- env.execute("file ouput")
- }
- }

代码结构及运行效果
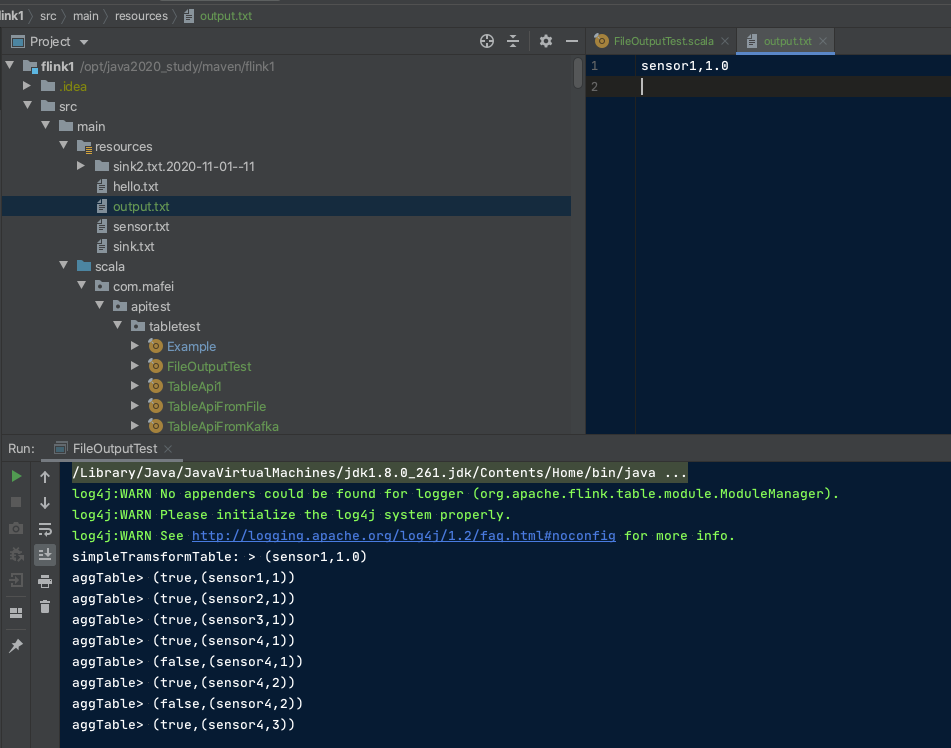
第二个栗子, 从kakfa的一个topic读出来,写到另一个topic里头
- /**
- *
- * @author mafei
- * @date 2020/11/23
- */
- package com.mafei.apitest.tabletest
-
- import org.apache.flink.streaming.api.scala._
- import org.apache.flink.table.api.DataTypes
- import org.apache.flink.table.api.scala._
- import org.apache.flink.table.descriptors.{Csv, Kafka, Schema}
-
- object KafkaOutputTest {
- def main(args: Array[String]): Unit = {
- //1 、创建环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- env.setParallelism(1)
-
- val tableEnv = StreamTableEnvironment.create(env)
-
- //2、从kafka中读取数据
- tableEnv.connect(
- new Kafka()
- .version("0.11")
- .topic("sourceTopic")
- .startFromLatest()
- .property("zookeeper.connect", "localhost:2181")
- .property("bootstrap.servers", "localhost:9092")
- ).withFormat(new Csv())
- .withSchema(new Schema() // 这个表结构要跟你kafka中的内容对的上
- .field("id", DataTypes.STRING())
- .field("timestamp", DataTypes.BIGINT())
- .field("temperature", DataTypes.DOUBLE())
- )
- .createTemporaryTable("kafkaInputTable")
-
- val sensorTable = tableEnv.from("kafkaInputTable")
-
- //做简单转换
- val simpleTramsformTable = sensorTable
- .select("id,temperature")
- .filter("id='sensor1'")
-
- tableEnv.connect(
- new Kafka()
- .version("0.11")
- .topic("sinkTopic")
- .startFromLatest()
- .property("zookeeper.connect", "localhost:2181")
- .property("bootstrap.servers", "localhost:9092")
- ).withFormat(new Csv())
- .withSchema(new Schema() //这个表结构要跟你kafka中的内容对的上
- .field("id", DataTypes.STRING())
- .field("temper", DataTypes.DOUBLE())
- )
- .createTemporaryTable("kafkaOutputTable")
-
- simpleTramsformTable.insertInto("kafkaOutputTable")
- env.execute("kafka sink test by table api")
- }
- }
这时候就可以起2个窗口,一个窗口往"sourceTopic" 这个topic里面写,Flink程序会从这个topic里面读出来写到"sinkTopic" 这个topic里面,再起一个consumer的命令行去消费这个topic就可以看到效果了
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/43904
推荐阅读



相关标签

