
- 1Http学习:如何写出正确的网址?_正确网址格式怎么写
- 2前端最受欢迎的6个开发工具_前端制作软件
- 3Linux操作系统基础详解,计算机专业必看!_操作系统详解
- 4docker-compose编排参数详解_dockercompose端口映射
- 5关于通过面试后谈薪资问题_两轮面试后聊到薪资方面的问题
- 6idea 使用 Docker 打包镜像的两种方式_07_docker打包方式
- 7Java项目:springboot图书管理系统
- 8ArcGIS Desktop使用入门(二)常用工具条——编辑器_arcgis编辑器
- 9Linux 系统资源监控常用命令_正确地使用 free、ps、cat /proc/meminfo 和 vmstat 等命令报告系统在一
- 10C语言-函数_c语言调用函数调用新参进行运算时会不会改变实参的值
Elasticsearch:聊天机器人教程(一)
赞
踩
在本教程中,你将构建一个大型语言模型 (LLM) 聊天机器人,该机器人使用称为检索增强生成 (RAG) 的模式。

使用 RAG 构建的聊天机器人可以克服 ChatGPT 等通用会话模型所具有的一些限制。 特别是,他们能够讨论和回答以下问题:
- 你的组织私有的信息
- 不属于训练数据集的事件,或者 LLM 完成训练后发生的事件
作为一个额外的好处,RAG 可以帮助 LLM 以事实为 “基础”,使他们不太可能做出回应或 “产生幻觉”。
实现这一目标的秘诀是使用两步过程从 LLM 获得答案:
- 首先在检索阶段,针对用户的查询搜索一个或多个数据源。 检索在此搜索中找到的相关文档。 为此,使用 Elasticsearch 索引是一个很好的选择,使你能够在关键字、密集和稀疏向量搜索方法,甚至它们的混合组合之间进行选择。
- 然后在生成阶段,用户的提示被扩展为包括第一阶段检索到的文档,并添加了对 LLM 的指令,以在检索到的信息中找到用户问题的答案。 扩展提示(包括问题的添加上下文)将代替原始查询发送到 LLM。
教程结构
本教程分为两个主要部分。
- 在第一部分中,您将学习如何运行 Chatbot RAG 应用程序示例,这是一个具有 Python 后端和 React 前端的完整应用程序。
- 一旦你启动并运行了示例应用程序,本教程的第二部分将解释 RAG 实现的不同组件,以便你可以根据自己的需要调整示例代码。
要求
要学习本教程,你需要安装以下组件:
1)Elasticsearch 及 Kibana
有关安装说明,请参阅如下的文章:
在安装的时候,请选择 Elastic Stack 8.x 进行安装。在安装的时候,我们可以看到如下的安装信息:
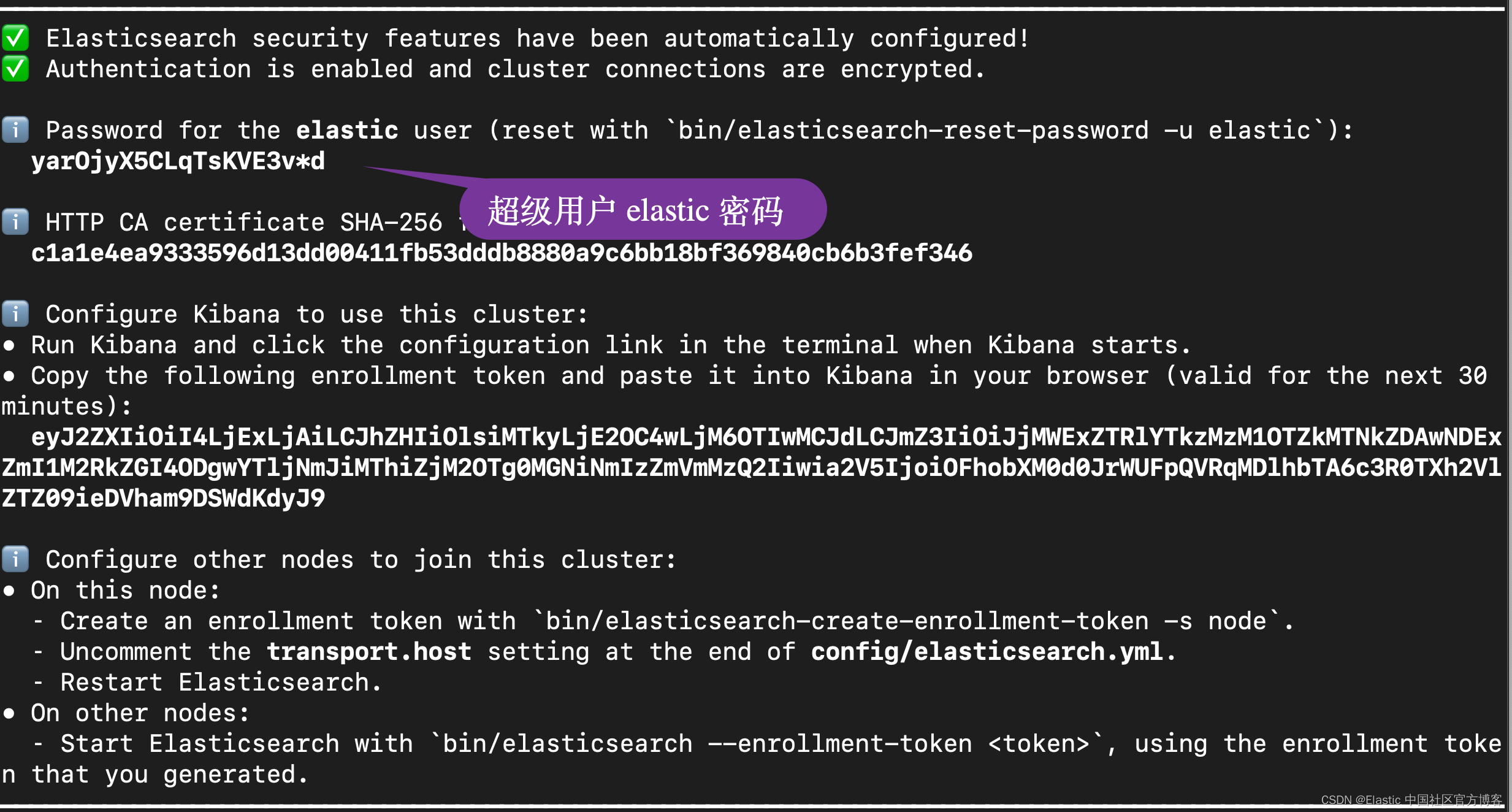
在下面的展示中,我将使用 Elastic Stack 8.11 来进行展示。
2)OpenAI 的 API 密钥。 实际上,你可以使用你喜欢的任何其他 LLM,只要它受到 Langchain 项目的支持即可。
3)Python 解释器。 确保它是最新版本,例如 Python 3.8 或更高版本。
本教程重点介绍 RAG 主题。 为了能够修改示例应用程序,你将需要以下技术的基本知识:
整个项目的完整代码在如下地址可以进行下载:
- git clone https://github.com/liu-xiao-guo/elasticsearch-labs
- cd elasticsearch-labs/example-apps/chatbot-rag-app
聊天机器人示例位于 example-apps/chatbot-rag-app 子目录中。
- $ pwd
- /Users/liuxg/python/elasticsearch-labs
- $ ls
- CONTRIBUTING.md bin supporting-blog-content
- LICENSE datasets test
- Makefile example-apps
- README.md notebooks
- $ cd example-apps
- $ ls
- README.md openai-embeddings workplace-search
- chatbot-rag-app relevance-workbench
- internal-knowledge-search search-tutorial
- $ cd chatbot-rag-app/
- $ ls
- Dockerfile api data frontend requirements.txt
- README.md app-demo.gif env.example requirements.in

Python 后端
在本节中,我们将设置和配置项目的后端部分。
安装 Python 依赖项
为了遵循 Python 最佳实践,你现在将创建一个虚拟环境,这是专用于该项目的私有 Python 安装,可以在其中安装所有依赖项。 使用以下命令执行此操作:
python3 -m venv .venv- $ pwd
- /Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
- $ python3 -m venv .venv
此命令在 .venv (dot-venv) 目录中创建 Python 虚拟环境。 你可以将此命令中的 .venv 替换为你喜欢的任何其他名称。 请注意,在某些 Python 安装中,你可能需要使用 python 而不是 python3 来调用 Python 解释器。
下一步是激活虚拟环境,这是使该虚拟环境成为你所在终端会话的活动 Python 环境的一种方法。如果你使用的是基于 UNIX 的操作系统(例如 Linux 或 macOS),请激活 虚拟环境如下:
source .venv/bin/activate- $ pwd
- /Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
- $ python3 -m venv .venv
- $ source .venv/bin/activate
- (.venv) $
如果你在 Microsoft Windows 计算机上的 WSL 环境中工作,上述激活命令也适用。 但如果你使用的是 Windows 命令提示符或 PowerShell,激活命令会有所不同:
.venv\Scripts\activate激活虚拟环境后,命令行提示符将更改为显示环境名称:
(.venv) $ _配置 Python 环境的最后一步是安装入门应用程序所需的一些包。 确保上一步中已激活虚拟环境,然后运行以下命令安装这些依赖项:
pip install -r requirements.txt 
编写配置文件
在上一节中下载的代码的主目录中有一个名为 env.example 的文件。 该文件包含应用程序支持的所有配置变量。
复制该文件,并将其命名为 .env:
cp env.example .env- (.venv) $ ls -al
- total 920
- drwxr-xr-x 14 liuxg staff 448 Jan 15 09:25 .
- drwxr-xr-x 9 liuxg staff 288 Jan 15 09:21 ..
- -rw-r--r-- 1 liuxg staff 55 Jan 15 09:21 .flaskenv
- -rw-r--r-- 1 liuxg staff 82 Jan 15 09:21 .gitignore
- drwxr-xr-x 6 liuxg staff 192 Jan 15 09:25 .venv
- -rw-r--r-- 1 liuxg staff 807 Jan 15 09:21 Dockerfile
- -rw-r--r-- 1 liuxg staff 6085 Jan 15 09:21 README.md
- drwxr-xr-x 7 liuxg staff 224 Jan 15 09:21 api
- -rw-r--r-- 1 liuxg staff 430277 Jan 15 09:21 app-demo.gif
- drwxr-xr-x 4 liuxg staff 128 Jan 15 09:21 data
- -rw-r--r-- 1 liuxg staff 860 Jan 15 09:21 env.example
- drwxr-xr-x 9 liuxg staff 288 Jan 15 09:21 frontend
- -rw-r--r-- 1 liuxg staff 315 Jan 15 09:21 requirements.in
- -rw-r--r-- 1 liuxg staff 5259 Jan 15 09:21 requirements.txt
- (.venv) $ cp env.example .env
- (.venv) $ ls .env
- .env
如果您在 Windows 上学习本教程,请在上面的命令中使用 copy 而不是 cp。
在你喜欢的文本编辑器中打开 .env 以查看应用程序配置,并查看以下小节以获取有关如何配置应用程序的指导。
Elasticsearch 设置
我们在 .env 中设置如下的变量:
.env
- ELASTICSEARCH_URL=https://elastic:yarOjyX5CLqTsKVE3v*d@192.168.0.3:9200
- ES_INDEX=workplace-app-docs
- ES_INDEX_CHAT_HISTORY=workplace-app-docs-chat-history
- LLM_TYPE=openai
- OPENAI_API_KEY=YourOpenAiKey
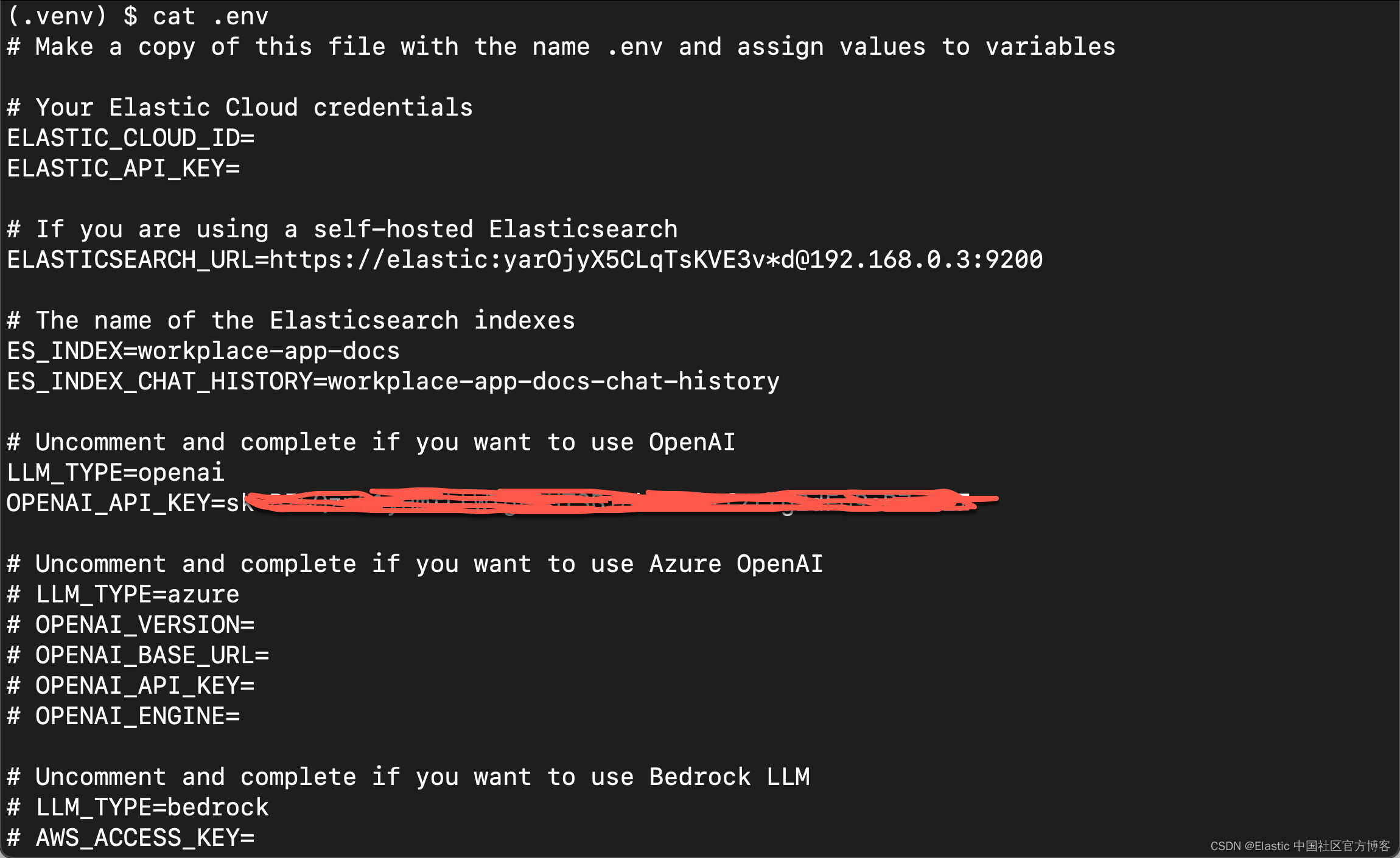
在上面,你必须根据自己的 Elasticsearch 安装修改上面的 ELASTICSEARCH_URL 值。你还需要修改上面的 OPENAI_API_KEY 值。你需要在 OpenAI 的网站中申请开发者 key。你可以在地址 https://platform.openai.com/api-keys 进行申请。
为了能够让 Python 连接到 Elasticsearch,我们必须把 Elasticsearch 的证书拷贝到当前的目录下:
- (.venv) $ pwd
- /Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app/api
- (.venv) $ cp ~/elastic/elasticsearch-8.11.0/config/certs/http_ca.crt .
- (.venv) $ ls http_ca.crt
- http_ca.crt
另外,在 github 上的代码是为在 docker 的环境下运行二准备的,我们必须修改其中的一个部分以使得它正常运行:
api/elasticsearch_client.py
- if ELASTICSEARCH_URL:
- elasticsearch_client = Elasticsearch(
- hosts=[ELASTICSEARCH_URL],
- ca_certs = ./http_ca.crt,
- verify_certs = True
- )
data/index_data.py
- if ELASTICSEARCH_URL:
- elasticsearch_client = Elasticsearch(
- hosts=[ELASTICSEARCH_URL],
- ca_certs = "./http_ca.crt",
- verify_certs = True
- )
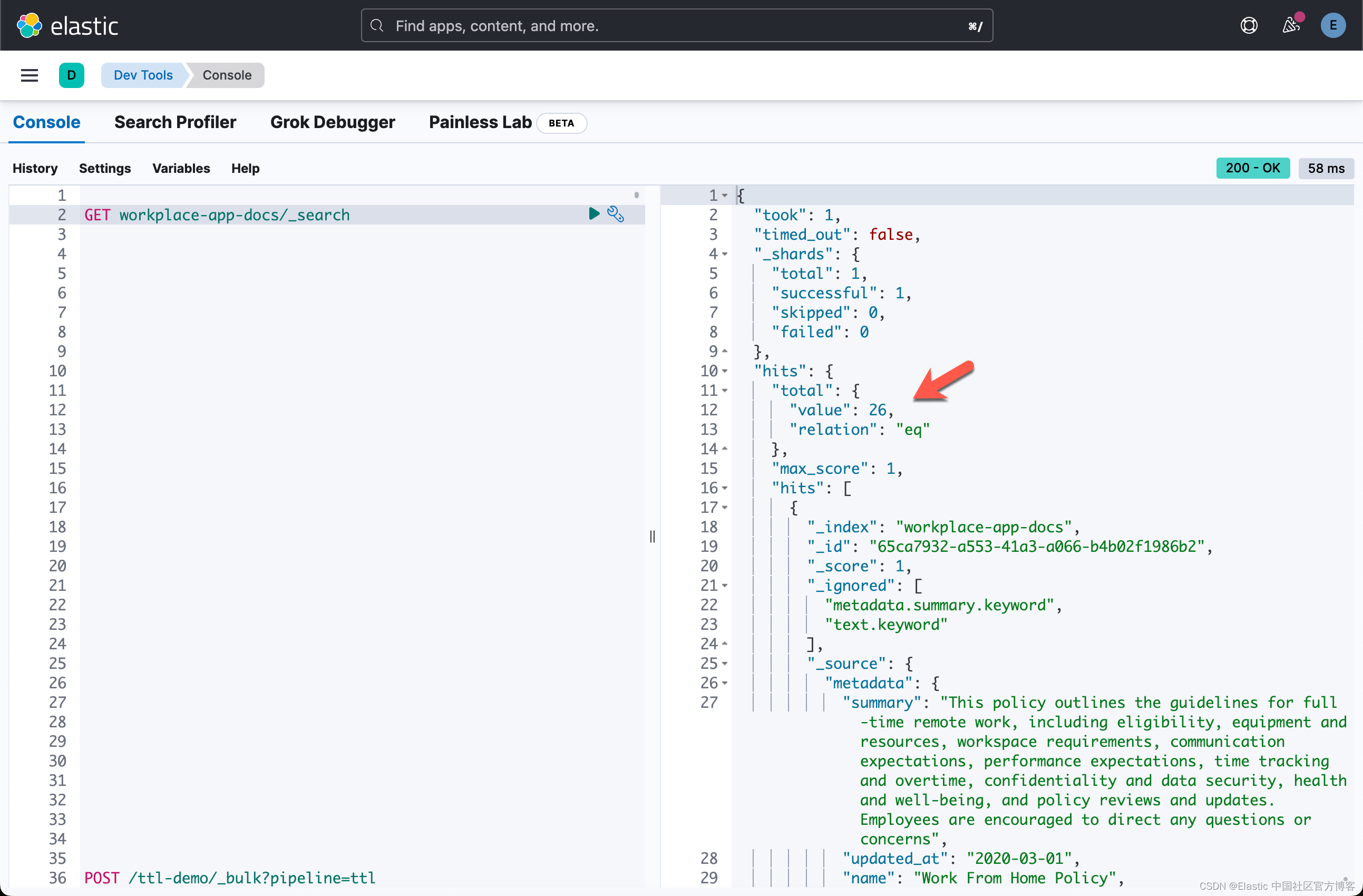
写入示例数据集
该应用程序附带一个示例数据集,存储在 data/data.json 文件中。 请随意在文本编辑器中打开此文件,以熟悉其中包含的文档。
使用以下命令将数据集导入应用程序:
flask create-index- (.venv) $ pwd
- /Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
- (.venv) $ flask create-index
- ".elser_model_2" model is available
- Loading data from $/Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app/api/../data/data.json
- Loaded 15 documents
- Split 15 documents into 26 chunks
- Creating Elasticsearch sparse vector store in Elastic Cloud:
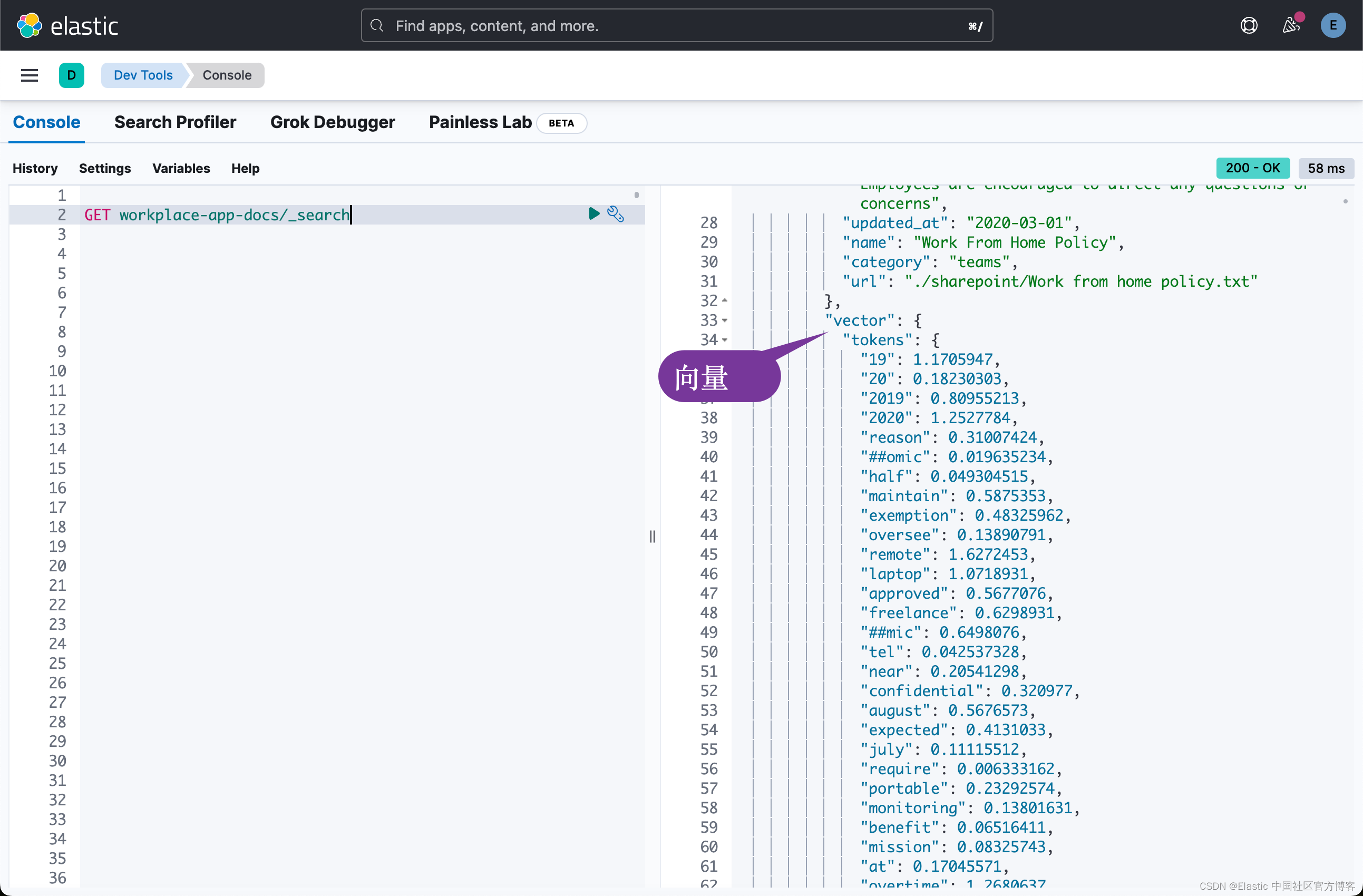
等上面的命令运行完毕后,我们到 Kibana 中进行查看:
启动后端
完成上述所有步骤后,你应该能够使用以下命令启动 Python 后端:
flask run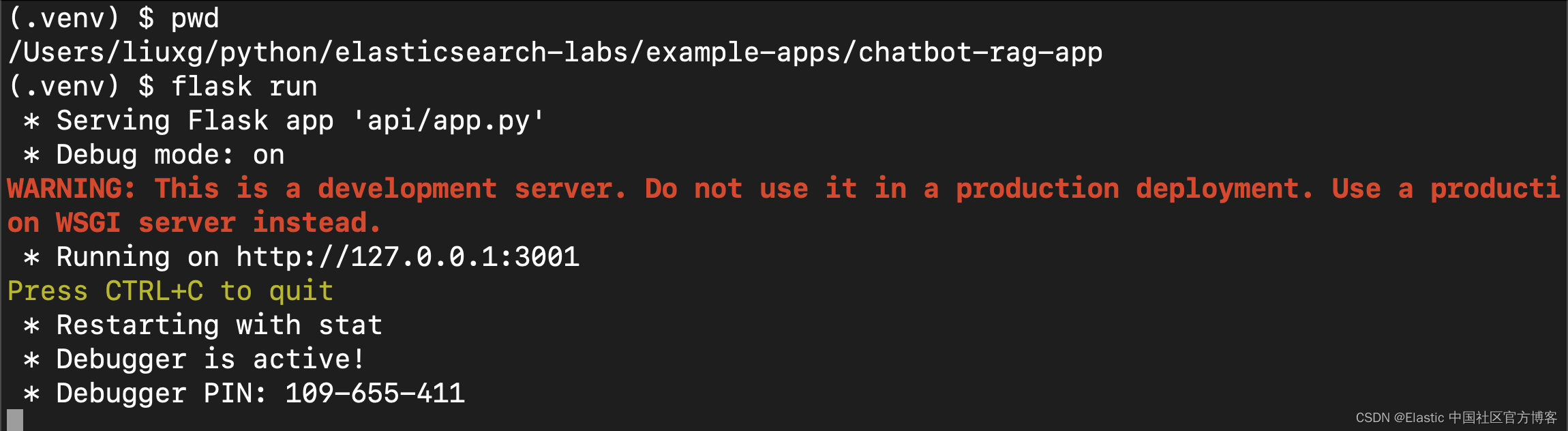
保持后端运行并打开一个新的终端会话以继续本教程的其余部分。
React 前端
在本部分中,你将启动聊天机器人的前端。
安装依赖项
前端位于项目的 frontend 子目录中,因此请继续更改为:
cd frontend- $ pwd
- /Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
- $ cd frontend/
运行 yarn 命令安装所有前端依赖项:
yarn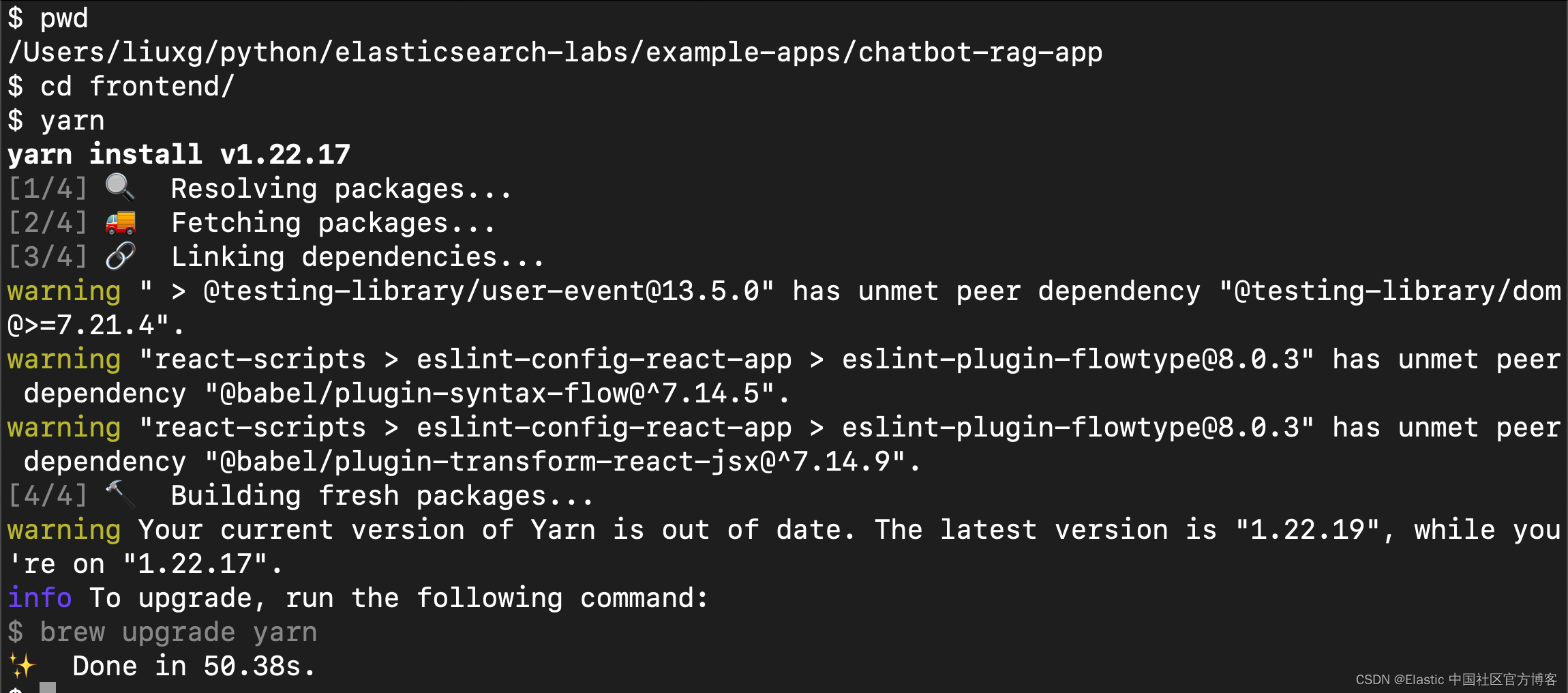
运行前端
使用以下命令启动前端:
yarn start几秒钟后,你的浏览器应该打开该应用程序。
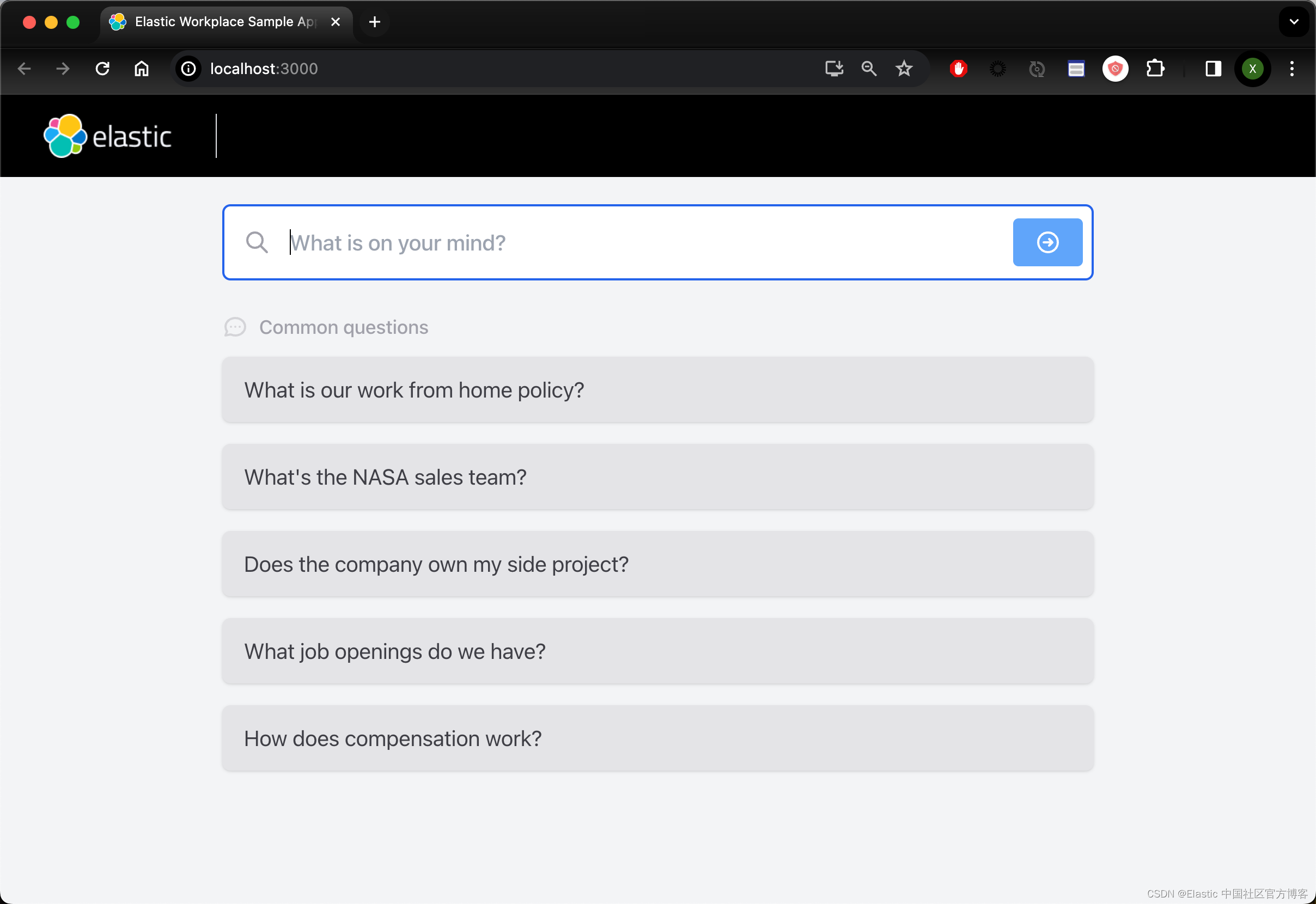
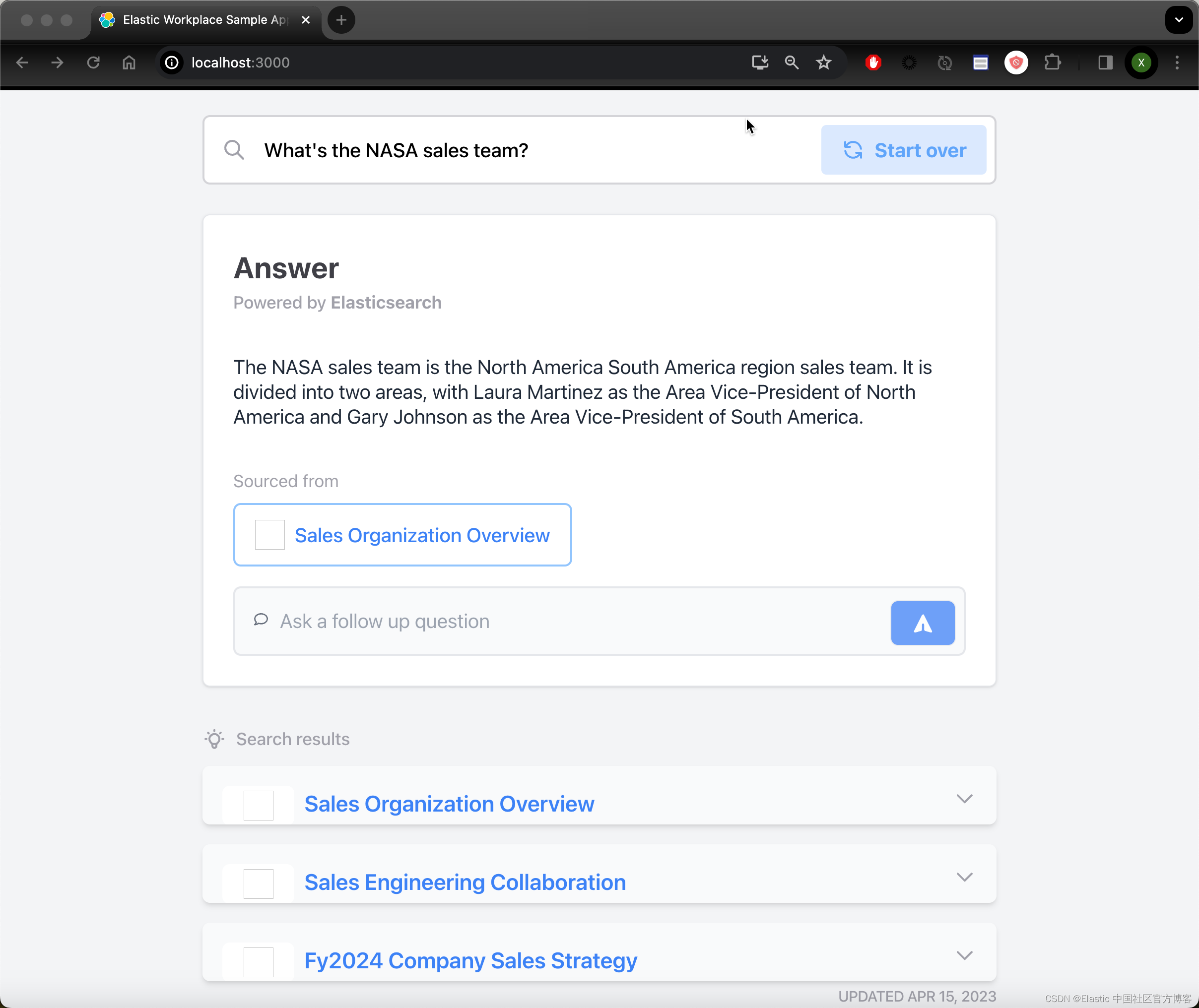
使用应用程序
现在,你可以通过单击 common questions 中的一个或输入你自己的问题来向聊天机器人询问任何问题。
聊天机器人的响应将来自导入的数据集,每个响应将引用检索到的文档以及使用特定文档的文档。
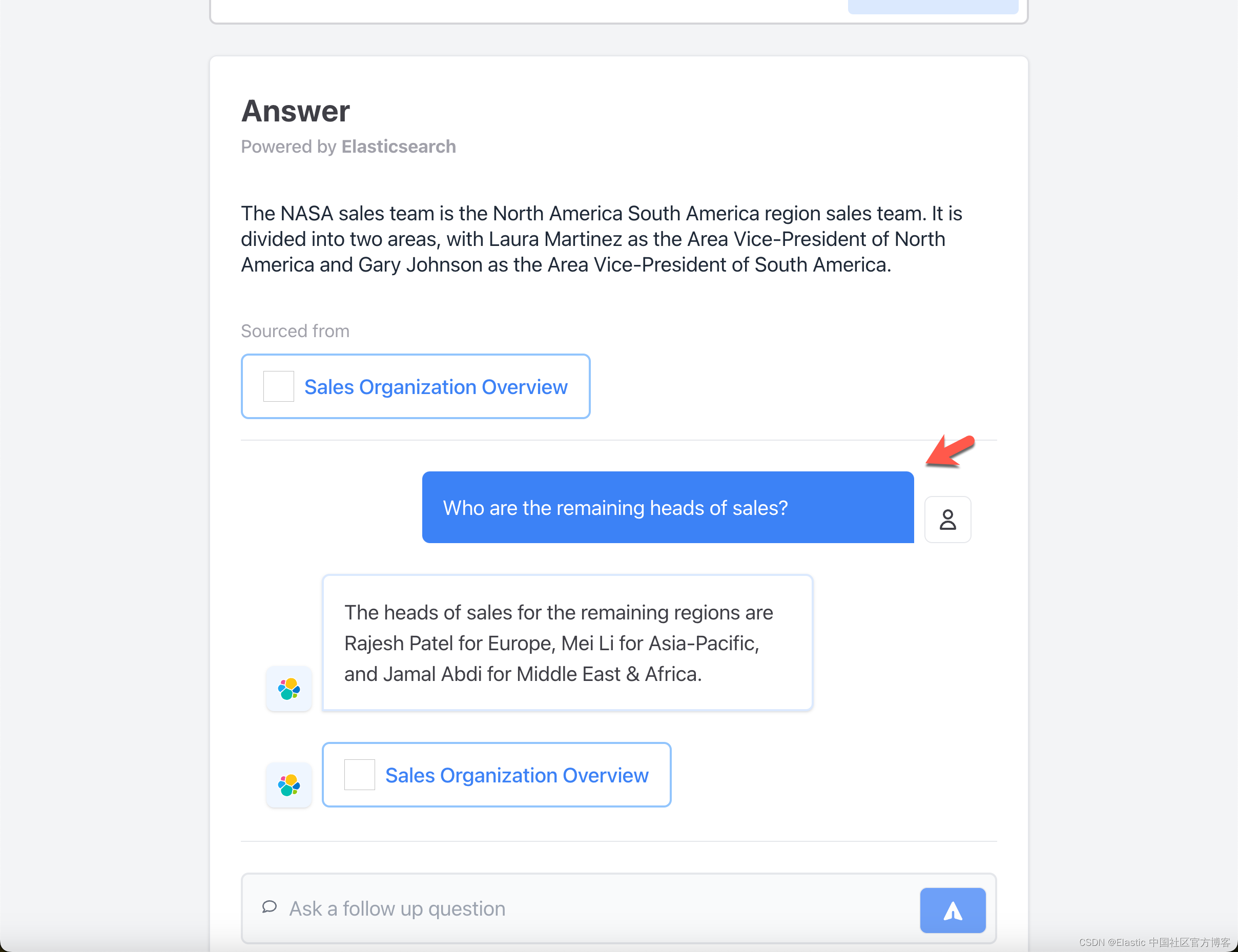
一定要尝试提出后续问题,这些问题应该 “记住” 会话之前讨论的内容。
本教程的其余部分将讨论该应用程序的一些实现细节,以便你可以根据需要进行更改、试验和调整代码。请关注我们的下一个部分!请详细阅读文章 “Elasticsearch:聊天机器人教程(二)”。
更多阅读,请参阅 “Elasticsearch:使用 Elasticsearch 向量搜索及 RAG 来实现 Chatbot”。





