
热门标签
热门文章
- 1[Android开发]镂空的TextView,镂空字体,TextView实现镂空字体效果_textview空心字体
- 2三元环计数(HDU 6104)
- 3Simulink|光伏阵列模拟多类故障(开路/短路/阴影遮挡/老化)
- 4Android —— Activity的四种启动模式_栈顶复用模式
- 5ICCV 2023 | 腾讯优图16篇论文入选!轻量级主干、异常检测和扩散模型等方向
- 6ahri8.php,松鼠症仓库自行更新规则后无法获取正确的title
- 7FPGA硬件架构
- 82V2无人机红蓝对抗仿真
- 9Docker基础:镜像、容器、仓库、镜像的分层、容器数据卷_镜像仓库,镜像层和镜像
- 10python time操作 格式化字符串转时间戳_python time 如何将字符串转换成时间戳
当前位置: article > 正文
Flink基于时间窗口定时输出到ElasticSearch中并做到真正不丢数据_flink sink每隔多久执行一次
作者:代码领袖开发者 | 2024-01-29 17:27:34
赞
踩
flink sink每隔多久执行一次
Flink时间窗口运用
介绍Flink定时输出到外部存储介质,有两种办法实现,在RichSinkFunction中实现SinkFunction的方法,在其中open()方法中引入java的定时任务。
另一种实现,基于Flink window窗口机制,将结果定时sink到ElasticSearch中。
需求:
经过flink清洗后的数据,要求每500毫秒sink一次数据到ES中(该文件内容是String格式,需要进行追加,不属于大家可以用Java实现,具体代码我就不细讲了)。
实现:
1、序列化方法:
- /**
- * 自定义序列化器
- */
- public class CustomDeserialization implements DebeziumDeserializationSchema<String> {
-
- @Override
- public void deserialize(SourceRecord sourceRecord, Collector<String> collector)
- throws Exception {
-
- JSONObject res = new JSONObject();
- // 获取数据库和表名称
- String topic = sourceRecord.topic();
- String[] fields = topic.split("\\.");
- String database = fields[1];
- String tableName = fields[2];
- Struct value = (Struct) sourceRecord.value();
- // 获取before数据
- Struct before = value.getStruct("before");
- JSONObject beforeJson = new JSONObject();
- if (before != null) {
- Schema beforeSchema = before.schema();
- List<Field> beforeFields = beforeSchema.fields();
- for (Field field : beforeFields) {
- Object beforeValue = before.get(field);
- beforeJson.put(field.name(), beforeValue);
- }
- }
- // 获取after数据
- Struct after = value.getStruct("after");
- JSONObject afterJson = new JSONObject();
- if (after != null) {
- Schema afterSchema = after.schema();
- List<Field> afterFields = afterSchema.fields();
- for (Field field : afterFields) {
- Object afterValue = after.get(field);
- afterJson.put(field.name(), afterValue);
- }
- }
- //获取操作类型 READ DELETE UPDATE CREATE
- Envelope.Operation operation = Envelope.operationFor(sourceRecord);
- String type = operation.toString().toLowerCase();
- if ("create".equals(type)) {
- type = "insert";
- }
-
- // 将字段写到json对象中
- res.put("database", database);
- res.put("tableName", tableName);
- res.put("before", beforeJson);
- res.put("after", afterJson);
- res.put("type", type);
- //输出数据
- collector.collect(res.toString());
- }
-
- @Override
- public TypeInformation<String> getProducedType() {
- return BasicTypeInfo.STRING_TYPE_INFO;
- }
- }

以上时序列号方法,大家可以随意定义因为我这块用了 Flink CDC
2、时间窗口的启用:
- /**
- * 按时间开窗收集更新全量不会丢数
- */
- DataStream<List<String>> streamList = streamSource
- .windowAll(TumblingProcessingTimeWindows.of(Time.milliseconds(100)))
- .process(new ProcessAllWindowFunction<String, List<String>, TimeWindow>() {
- @Override
- public void process(Context context, Iterable<String> iterable, Collector<List<String>> collector) throws Exception {
- List<String> arrayList = new ArrayList<String>();
- iterable.forEach(single -> {
- arrayList.add(single);
- });
- if (arrayList.size() > 0) {
- collector.collect(arrayList);
- }
- }
- });
3、Sink下层处理
- @Override
- public void invoke(List<String> values, Context context) throws Exception {
-
- try {
-
- List<Map<String, Object>> list = new ArrayList<>();
- String tName = "";
-
- for (String value : values) {
-
- JSONObject jsonObject = JSON.parseObject(value.toString());
- // String arrayslist = Arrays.asList(pgConnection.getTableList()).toString();
- String schemaName = jsonObject.get("database").toString();
- String tableName = jsonObject.get("tableName").toString();
-
- //多表流需要判断处理,不一样流写入到ES索引也是不一样的
- //if (Arrays.asList(pgConnection.getTableList()).contains(schemaName + "." + tableName)) {
- tName = schemaName + "_" + tableName;
- JSONObject jsonAfter = JSON.parseObject(jsonObject.get("after").toString());
-
- //System.out.println(esLogAppendServer.getFields());
- if (jsonObject != null) {
- Map<String, Object> map = new HashMap<String, Object>();
- for (Map.Entry<String, Object> entry : jsonAfter.entrySet()) {
- //这里处理一下日期变成时间戳问题,以下进行遍历执行
- map.put(entry.getKey(), entry.getValue());
- }
- list.add(map);
- }
-
- }
-
- saveElasticSearch(tName, list);
-
- } catch (Exception ex) {
- log.info(DateUtils.getDate() + "---" + ex.toString());
- }
-
- }
测试:
方便测试,先将时间改为每100毫秒执行,Time.milliseconds(100),通过开窗获取100毫秒的数据:
第1个时间窗口到达:Iterable中集合了这100毫秒接收的所有实时数据,统一处理
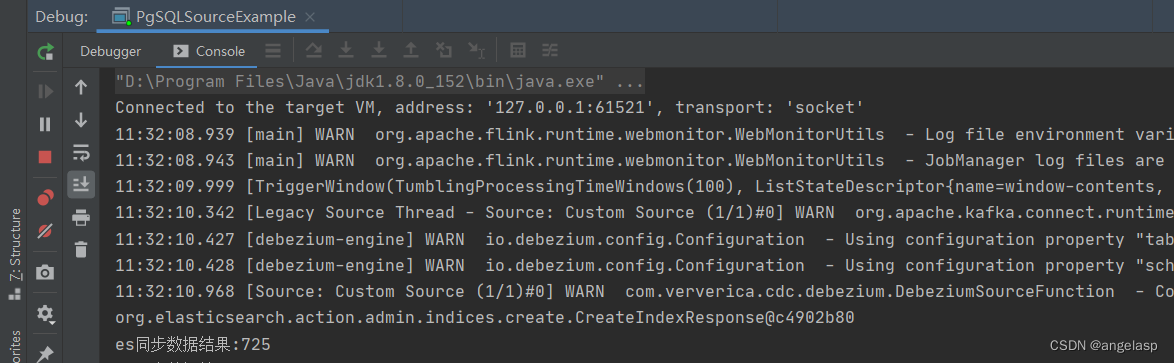
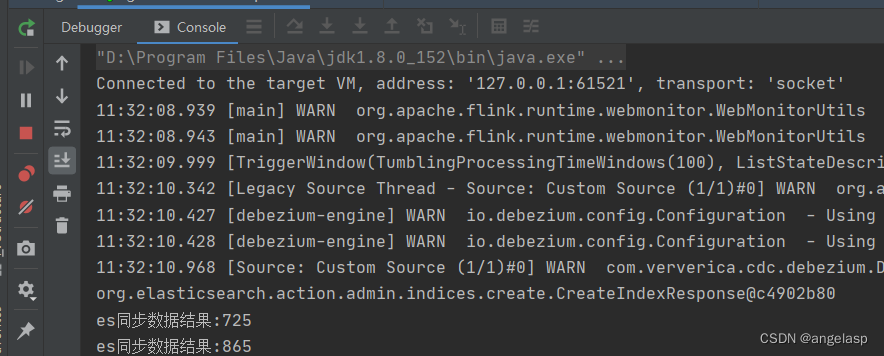
总结:
Flink是实时处理,window机制可以认为是flink的批处理实现,因为需要等待水位线对齐触发timer。一般还基于时间窗口做一些批量处理不会丢数据,所以比较适合数据表全量更新。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/43788
推荐阅读





相关标签

