
- 1【HiFlow】腾讯云新一代自动化助手,我用它完成了企业疫情提示(无代码)_腾讯云hiflow 收集表提醒企业微信
- 2软件定义的计算_软件定义计算
- 32024美赛数学建模B题思路+代码_美赛b题思路
- 4蓝桥杯第十三届青少年Python组省赛试题_十三届蓝桥杯python组省赛试题
- 5kafka启动_Kafka安装部署——单节点
- 6【大数据平台】——基于Confluent的Kafka Rest API探索(二)_confluent key schema
- 7STM32三种BOOT启动模式详解_stm32 boot
- 8QS世界大学最新排名公布:清华超过耶鲁,MIT仍居榜首,12所中国高校跻身百强...
- 9springmvc--7--数据绑定器WebDataBinder_webdatabinderfactory
- 10win10 bat 命令使用 xcopy 语法_win10复制文件到文件夹bat
爬虫教程( 5 ) --- Selenium、PhantomJS、selenium反检测、cdp ( ichrome )、Playwright、DrissionPage_drissionpage和playwright哪个好
赞
踩
1、Selenium
中式读法:【 瑟林捏幕 】
官方文档:https://selenium-python.readthedocs.io/
中文文档:https://selenium-python-zh.readthedocs.io/en/latest/
Selenium( selenium 中文网:http://www.selenium.org.cn/ )是一个强大的网络数据采集工具,最初是为了网站自动化测试而开发的,被用来测试 Web 应用程序在不同的浏览器和操作系统上运行能力。
浏览器插件:Selenium IDE
Selenium 是什么
Selenium 是什么?一句话,自动化测试工具。简单的说就是一个可以用代码操所浏览器的工具。可以通过selenium进行搜索关键字,点击按钮等等操作。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。换句话说 Selenium 可以自动化操作这些浏览器,但是必须下载并设置不同的浏览器驱动(注:部分浏览器驱动地址需要科学上网)。
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此用于任何支持JavaScript的浏览器上。
selenium 可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
Selenium 支持多种语言开发,比如 Java,C,Ruby、Python 等。
嗯,所以呢?安装一下 Python 的 Selenium 库,再安装好 PhantomJS,不就可以实现 Python+Selenium+PhantomJS 的无缝对接了嘛!PhantomJS 用来渲染解析JS,Selenium 用来驱动以及与 Python 的对接,Python 进行后期的处理,完美的三剑客!
有人问,为什么不直接用浏览器而用一个没界面的 PhantomJS 呢?答案是:效率高!
用python写爬虫的时候,主要用的是selenium的Webdriver,我们可以通过下面的方式先看看Selenium.Webdriver支持哪些浏览器。首先导入 webdriver 模块。然后使用help函数
from selenium import webdriver
help(webdriver)
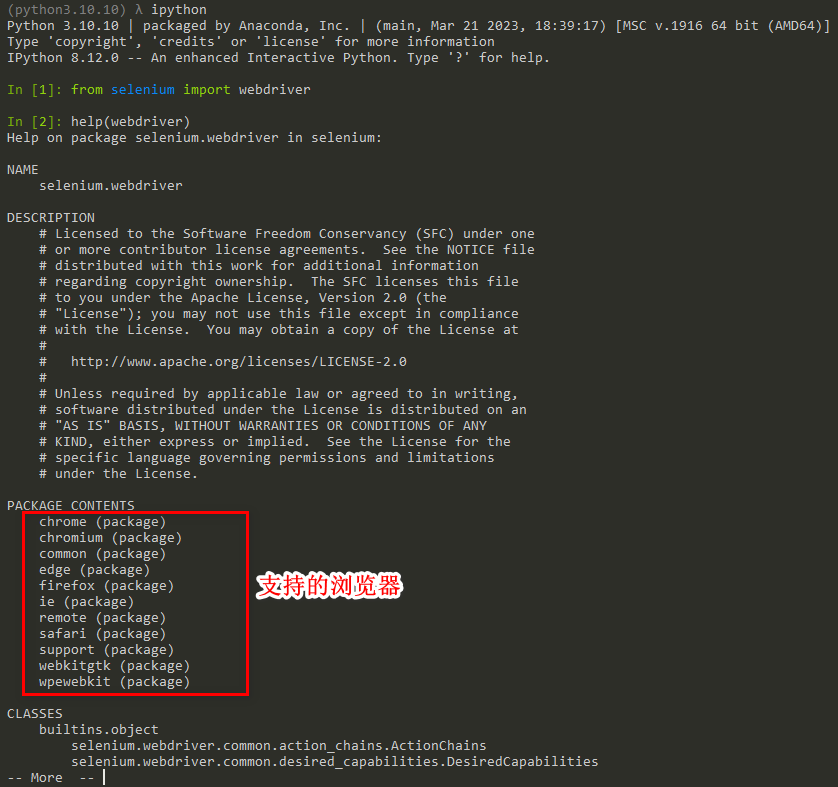
安装、使用
首先安装 Selenium:pip install selenium
安装 浏览器 驱动 webdriver
1. chromedriver 下载地址:http://chromedriver.chromium.org
chromedriver 镜像地址 :CNPM Binaries Mirror
2. Firefox 的驱动 geckodriver 下载地址:Releases · mozilla/geckodriver · GitHub
3. IE 驱动 下载地址:NuGet Gallery | Selenium.WebDriver.IEDriver 4.8.1
注意:下载解压后,将chromedriver.exe , geckodriver.exe , Iedriver.exe 放到 Python 的安装目录,例如 D:\python 。 然后再将 Python 的安装目录添加到系统环境变量的 Path
爬虫 Selenium Chromium 与 Chromedriver对应版本( 注意是 chromium,不是 Chrome ):
淘宝镜像地址在每个文件夹的 notes.txt 中存有 chromium 和 Chromedriver 的版本对应。
from selenium import webdriver
browser = webdriver.Chrome()
# browser = webdriver.Firefox()
# browser = webdriver.Ie()
browser.get('https://www.baidu.com/')
__input = input("暂停, 按任意键继续")
运行这段代码,会自动打开浏览器,然后访问百度。
如果程序执行错误,浏览器没有打开,那么应该是没有装 Chrome 浏览器或者 Chrome 驱动没有配置在环境变量里。下载驱动,然后将驱动文件路径配置在环境变量即可。
模拟提交
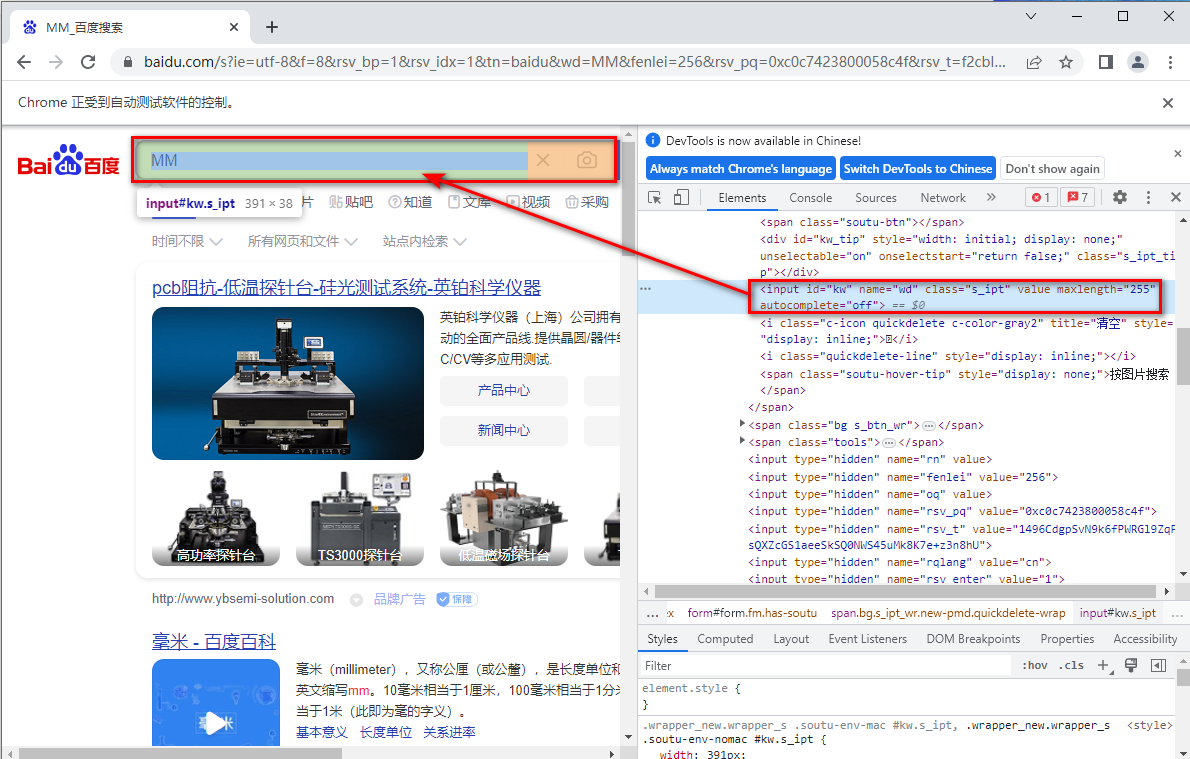
下面的代码实现了“模拟百度提交搜索”的功能。首先等页面加载完成,然后输入关键字到搜索框文本,最后点击提交。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
browser.get("https://www.baidu.com")
print(browser.title)
elem = browser.find_element(By.NAME, value="wd") # 百度首页搜索框 name="wd"
elem.send_keys("MM") # 输入关键字
elem.send_keys(Keys.RETURN) # 模拟 点击 enter键,提交
print(browser.page_source) # 打印 js 渲染后的网页
__input = input("暂停, 按enter键退出")
其中 driver.get 方法会打开请求的 URL,WebDriver 会等待页面完全加载完成之后才会返回,即程序会等待页面的所有内容加载完成,JS渲染完毕之后才继续往下执行。注意:如果这里用到了特别多的 Ajax 的话,程序可能不知道是否已经完全加载完毕。
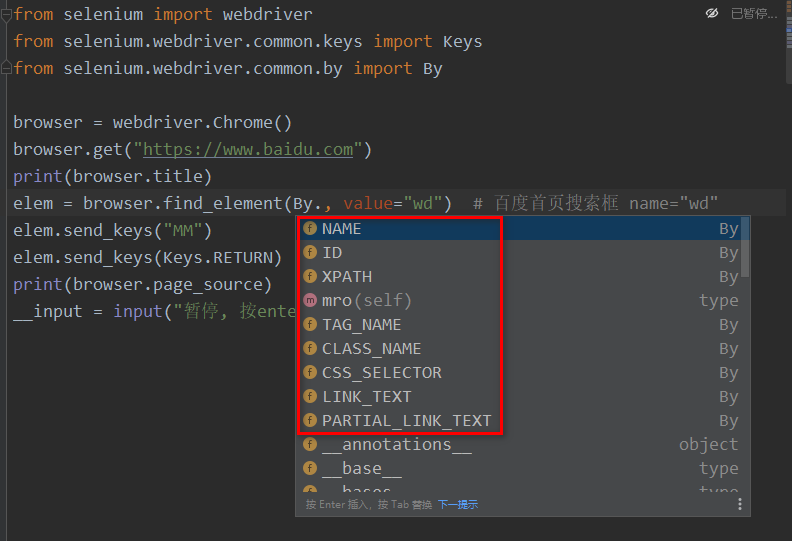
WebDriver 提供了许多寻找网页元素的方法,通过 By 类的方法。
然后,输入文本,模拟点击回车。利用 Keys 这个类来模拟键盘输入。就像敲击键盘一样。
注意:获取网页渲染后的源代码。输出 page_source 属性即可。
通过 dir(browser) 查看,browser 对象有那些方法,
测试用例
import unittest
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
class PythonOrgSearch(unittest.TestCase):def setUp(self):
self.driver = webdriver.Chrome()def test_search_in_python_org(self):
driver = self.driver
driver.get("https://www.python.org")
self.assertIn("Python", driver.title)
elem = driver.find_element(By.NAME, value="q")
elem.send_keys("pycon")
elem.send_keys(Keys.RETURN)
assert "No results found." not in driver.page_sourcedef tearDown(self):
self.driver.close()
if __name__ == "__main__":
unittest.main()
测试用例是继承了 unittest.TestCase 类,继承这个类表明这是一个测试类。setUp方法是初始化的方法,这个方法会在每个测试类中自动调用。每一个测试方法命名都有规范,必须以 test 开头,会自动执行。最后的 tearDown 方法会在每一个测试方法结束之后调用。这相当于最后的析构方法。在这个方法里写的是 close 方法,你还可以写 quit 方法。不过 close 方法相当于关闭了这个 TAB 选项卡,然而 quit 是退出了整个浏览器。当你只开启了一个 TAB 选项卡的时候,关闭的时候也会将整个浏览器关闭。
import time
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
browser.maximize_window() # 最大化浏览器
browser.implicitly_wait(20) # 设置隐式时间等待
url = 'https://www.baidu.com'
browser.get(url)# 网页的登录按钮
btn_login = browser.find_element(By.ID, value='s-top-loginbtn')
btn_login.click() # 点击登录按钮
time.sleep(2) # 显式等待 2s# 查找所有的 a 标签
all_link = browser.find_element(By.TAG_NAME, value='a')
link = all_link[3] # 提取 第四个 a 标签
link.click() # 点击 提取 的 a 标签
input('暂停,按 enter 退出...')
页面操作
访问页面
运行后自动打开Chrome浏览器,并登陆百度打印百度首页的源代码,然后关闭浏览器
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get("https://www.baidu.com")
print(browser.page_source)
browser.close()
执行JavaScript
这是一个非常有用的方法,这里就可以直接调用js方法来实现一些操作,下面的例子是通过登录知乎然后通过js翻到页面底部,并弹框提示
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.zhihu.com/explore")
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
input('暂停,按 enter 退出')
browser.close()
查找 ( 定位 ) 元素
Selenium常见元素定位方法和操作的学习介绍:[python爬虫] Selenium常见元素定位方法和操作的学习介绍_selenium元素定位_Eastmount的博客-CSDN博客
Selenium切换窗口句柄及调用Chrome浏览器:[python爬虫] Selenium切换窗口句柄及调用Chrome浏览器_selenium 窗口句柄_Eastmount的博客-CSDN博客
查找单个元素
import time
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
browser.get("https://www.taobao.com")
input_first = browser.find_element(By.ID, "q")
print(input_first)
input_second = browser.find_element(By.CSS_SELECTOR, "#q")
print(input_second)
input_third = browser.find_element(By.XPATH, '//*[@id="q"]')
print(input_third)
browser.close()
这里通过三种不同的方式获取元素。结果都是相同的。
查找元素的方法
Selenium 提供了8种定位方式:id、name、class name、tag name、link text、partial link text、xpath、css selector。
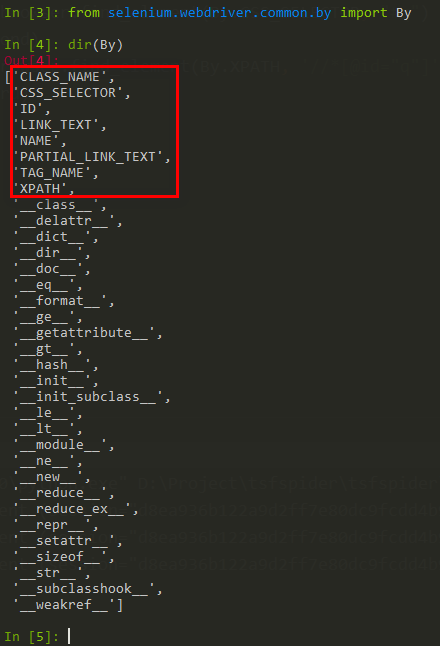
By 类的一些属性如下
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
通过 By 模块 定位元素
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
browser.get("https://www.taobao.com")
input_first = browser.find_element(By.ID, "q")
print(input_first)
browser.close()
多个元素查找
- 单个元素是 find_element,
- 多个元素是 find_elements,结果是获得一个元素列表
示例:lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
页面交互 ( 点击、输入 )
玩转python selenium鼠标键盘操作(ActionChains):https://www.jb51.net/article/92682.htm
Selenium鼠标与键盘事件常用操作方法示例:https://www.jb51.net/article/145502.htm
找到页面元素后,就需要和页面交互,比如:点击,输入等等。
需要导入包:from selenium.webdriver.common.keys import Keys
ele.send_keys("some text") # 文本框输入
ele.send_keys("and some", Keys.ARROW_DOWN)
ele.clear() # 清除 文本框 内容
Selenium 所有的 api 文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
交互动作 --- 动作链 (拖动、移动等)
将动作附加到动作链中串行执行
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()url = "https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable"
browser.get(url)
browser.switch_to.frame('iframeResult')source = browser.find_element(By.CSS_SELECTOR, '#draggable')
target = browser.find_element(By.CSS_SELECTOR, '#droppable')actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()actions.drag_and_drop_by_offset(source, 400, 0).perform()
input('暂停,按 enter 退出')
browser.close()
更多操作参考:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
元素拖拽
要完成元素的拖拽,首先你需要指定被拖动的元素和拖动目标元素,然后利用 ActionChains 类来实现
element = driver.find_element_by_name("source")
target = driver.find_element_by_name("target")from selenium.webdriver import ActionChains
action_chains = ActionChains(driver)
action_chains.drag_and_drop(element, target).perform()
actions.drag_and_drop_by_offset(element, 400, 0).perform()
这样就实现了元素从 source 拖动到 target 的操作
chrome 浏览器打开标签页的快捷键是 ctrl+t,那把 ctrl+t 的按键事件传入即可
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChainsbrowser = webdriver.Chrome()
browser.maximize_window()
url = 'https://www.baidu.com'
browser.get(url)ac = ActionChains(browser)
ac.key_down(Keys.CONTROL).key_down('t').key_up(Keys.CONTROL).key_up('t').perform()
input("暂停,按 enter 退出...")
browser.close()
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
browser = webdriver.Chrome() # 默认的火狐浏览器
for i in range(5):
# 这句代码相当于在浏览器窗口下按下ctrl+t打开一个新的标签页
browser.find_element(By.TAG_NAME, 'body').send_keys(Keys.CONTROL + 't')
time.sleep(10) # 等待所有窗口完全打开,10秒够用了, 如果不打开得不到所有句柄,只能得到部分。
handles = browser.window_handles
print(len(handles))
print(handles)
input('暂停,按 enter 退出')
browser.close()
通常要确保页面加载完成,可以使用 selenium.webdriver.support.ui.WebDriverWait
打开新窗口示例代码:
from selenium import webdriver
# 打开谷歌浏览器
browser = webdriver.Chrome()
# 打开窗口
browser.get("https://www.baidu.com/")
# 打开新窗口
newwindow_js = 'window.open("https://www.baidu.com");' # js
browser.execute_script(newwindow_js) # 执行 js 打开新的页面
# 切换到新的窗口
handles = browser.window_handles # 得到 所有页面 句柄
browser.switch_to_window(handles[-1]) # 切换焦点到 对应页面
获取元素属性
get_attribute('class')
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
logo = browser.find_element(By.ID, 'zh-top-link-logo')
print(logo)
print(logo.get_attribute('class'))
browser.close()
获取 文本值、ID、位置、标签名
id、location、tag_name、size
from selenium import webdriver
from selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
tag_input = browser.find_element(By.CLASS_NAME, 'zu-top-add-question')
print(tag_input.text)
print(tag_input.id)
print(tag_input.location)
print(tag_input.tag_name)
print(tag_input.size)
下拉 选项卡
下拉选项卡的的处理
tag_select = browser.find_element(By.XPATH, "//select[@name='name']")
all_options = tag_select.find_elements(By.TAG_NAME, "option")
for option in all_options:
print(f'Value is: {option.get_attribute("value")}')
option.click()
首先获取了第一个 select 元素,也就是下拉选项卡。然后轮流设置了 select 选项卡中的每一个 option 选项。你可以看到,这并不是一个非常有效的方法
其实 WebDriver 中提供了一个叫 Select 的方法,可以帮助我们完成这些事情。
from selenium.webdriver.support.ui import Select
select = Select(driver.find_element_by_name('name'))
select.select_by_index(index)
select.select_by_visible_text("text")
select.select_by_value(value)
如你所见,它可以根据索引来选择,可以根据值来选择,可以根据文字来选择。是十分方便的。
全部取消选择怎么办呢?很简单
select = Select(driver.find_element_by_id('id'))
select.deselect_all()
这样便可以取消所有的选择。
另外我们还可以通过下面的方法获取所有的已选选项。
select = Select(driver.find_element_by_xpath("xpath"))
all_selected_options = select.all_selected_options
获取所有可选选项是
options = select.options
如果你把表单都填好了,最后肯定要提交表单对吧。怎吗提交呢?很简单
driver.find_element_by_id("submit").click()
这样就相当于模拟点击了 submit 按钮,做到表单提交。
当然你也可以单独提交某个元素
element.submit()
方法,WebDriver 会在表单中寻找它所在的表单,如果发现这个元素并没有被表单所包围,那么程序会抛出 NoSuchElementException 的异常。
Frame
在很多网页中都是有Frame标签,所以我们爬取数据的时候就涉及到切入到frame中以及切出来的问题,通过下面的例子演示
这里常用的是 switch_to.from() 和 switch_to.parent_frame()
import time
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementExceptionbrowser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
print(source)
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
页面切换 和 打开新窗口
多窗口之间切换 :https://blog.csdn.net/u011541946/article/details/70132672
打开新窗口,多窗口切换:https://blog.csdn.net/DongGeGe214/article/details/52169761
打开新窗口并实现窗口切换: https://blog.csdn.net/zwq912318834/article/details/79206953定位以及切换frame(iframe):https://blog.csdn.net/huilan_same/article/details/52200586
关键字:selenium iframe 切换
如果在一个页面上点击一个链接之后,并不是在当前页面上打开,而是重新打开一个新页面;这种情况下如何跳转到新的页面上操作?首先,需要了解的是每个窗口都有句柄的,可以理解为浏览器窗口的唯一标识符,根据这个标识符来确定新打开的窗口。打开新页面后,selenium 的 focus 还是在 原来的页面上,所以需要使用 switch_to.window 方法把 焦点(focus) 切换到新页面上
如果是新打开的 iframe 就使用 switch_to_frame('xxx')
如果是新打开的 tab 就使用 switch_to_window('')
一个浏览器肯定会有很多窗口,所以我们肯定要有方法来实现窗口的切换。切换窗口的方法如下
driver.switch_to_window("windowName")switch_to_window 方法现在已经废弃,鼠标放在这个方法上提示 使用 switch_to.window 代替

另外你可以使用 window_handles 方法来获取每个窗口的操作对象。例如
- for handle in driver.window_handles:
- driver.switch_to_window(handle)
另外切换 frame 的方法如下
driver.switch_to_frame("frameName.0.child")这样焦点会切换到一个 name 为 child 的 frame 上。
打开新窗口主要使用 JavaScript 实现:
- # 新标签页打开这个url
- js="window.open("url")"
- driver.execute_script(js)
- time.sleep(2)
选项卡 管理
通过执行 js 命令实现新开选项卡 window.open()
不同的选项卡是存在列表里 browser.window_handles
通过 browser.window_handles[0] 就可以操作第一个选项卡
- import time
- from selenium import webdriver
- from selenium.webdriver.common.keys import Keys
- from selenium.webdriver.common.by import By
-
- browser = webdriver.Chrome()
- browser.get('https://www.baidu.com')
- browser.execute_script('window.open()')
- print(browser.window_handles)
- browser.switch_to.window(browser.window_handles[1])
- browser.get('https://www.taobao.com')
- time.sleep(1)
- browser.switch_to.window(browser.window_handles[0])
- browser.get('https://python.org')
- input('暂停, 按enter退出...')
- browser.close()

弹窗处理
页面出现了弹窗
alert = driver.switch_to_alert()通过上述方法可以获取弹窗对象。
历史记录 ( 前进、后退 )
前进 和 后退 针对的是 浏览器浏览的网页 的 历史记录
driver.forward()
driver.back()
Cookies 处理
get_cookies()
delete_all_cookes()
add_cookie()
- from selenium import webdriver
-
- browser = webdriver.Chrome()
- browser.get('https://www.zhihu.com/explore')
- print(browser.get_cookies())
- browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'zhaofan'})
- print(browser.get_cookies())
- browser.delete_all_cookies()
- print(browser.get_cookies())
为页面添加 Cookies,用法如下
- # Go to the correct domain
- driver.get("http://www.example.com")
-
- # Now set the cookie. This one's valid for the entire domain
- cookie = {‘name’ : ‘foo’, ‘value’ : ‘bar’}
- driver.add_cookie(cookie)
获取页面 Cookies,用法如下
- # Go to the correct domain
- driver.get("http://www.example.com")
-
- # And now output all the available cookies for the current URL
- driver.get_cookies()
以上便是 Cookies 的处理,同样是非常简单的。
页面 ( 隐式、显示) 等待
Python selenium 三种等待方式详解(必会):https://www.jb51.net/article/92672.htm
这是非常重要的一部分,现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。这会让元素定位困难而且会提高产生 ElementNotVisibleException 的概率。所以 Selenium 提供了两种等待方式,
- 隐式等待:等待特定的时间。如果 WebDriver没有在 DOM中找到元素,将继续等待,超出设定时间后则抛出找不到元素的异常。默认的时间是0
- 显式等待:首先指定一个等待条件,并且再指定一个最长等待时间,然后在这个时间段内进行判断是否满足等待条件,如果成立就会立即返回,如果不成立,就会一直等待,直到等待你指定的最长等待时间,如果还是不满足,就会抛出异常,如果满足了就会正常返回
- from selenium import webdriver
- from selenium.webdriver.common.by import By
- from selenium.webdriver.support.ui import WebDriverWait
- from selenium.webdriver.support import expected_conditions as EC
-
- driver = webdriver.Chrome()
- driver.get("http://somedomain/url_that_delays_loading")
- try:
- element = WebDriverWait(driver, 10).until(
- EC.presence_of_element_located((By.ID, "myDynamicElement"))
- )
- finally:
- driver.quit()
程序默认会 500ms 调用一次来查看元素是否已经生成,如果本来元素就是存在的,那么会立即返回。
- from selenium import webdriver
- from selenium.webdriver.common.by import By
- from selenium.webdriver.support.ui import WebDriverWait
- from selenium.webdriver.support import expected_conditions as EC
-
-
- browser = webdriver.Chrome()
- browser.get('https://www.taobao.com/')
-
- wait = WebDriverWait(browser, 10)
- tag_input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
- button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
- print(input, button)
上述的例子中的条件:EC.presence_of_element_located()是确认元素是否已经出现了
EC.element_to_be_clickable()是确认元素是否是可点击的
下面是一些内置的等待条件,你可以直接调用这些条件,而不用自己写某些等待条件了。
常用的判断条件:
title_is 标题是某内容
title_contains 标题包含某内容
presence_of_element_located 元素加载出,传入定位元组,如(By.ID, 'p')
visibility_of_element_located 元素可见,传入定位元组
visibility_of 可见,传入元素对象
presence_of_all_elements_located 所有元素加载出
text_to_be_present_in_element 某个元素文本包含某文字
text_to_be_present_in_element_value 某个元素值包含某文字
frame_to_be_available_and_switch_to_it frame 加载并切换
invisibility_of_element_located 元素不可见
element_to_be_clickable 元素可点击
staleness_of 判断一个元素是否仍在DOM,可判断页面是否已经刷新
element_to_be_selected 元素可选择,传元素对象
element_located_to_be_selected 元素可选择,传入定位元组
element_selection_state_to_be 传入元素对象以及状态,相等返回True,否则返回False
element_located_selection_state_to_be 传入定位元组以及状态,相等返回True,否则返回False
alert_is_present 是否出现Alert
更多操作参考:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
隐式等待
隐式等待比较简单,就是简单地设置一个等待时间,单位为秒。到了一定的时间发现元素还没有加载,则继续等待我们指定的时间,如果超过了我们指定的时间还没有加载就会抛出异常,如果没有需要等待的时候就已经加载完毕就会立即执行
- from selenium import webdriver
-
- driver = webdriver.Chrome()
- driver.implicitly_wait(10) # seconds
- driver.get("http://somedomain/url_that_delays_loading")
- myDynamicElement = driver.find_element_by_id("myDynamicElement")
当然如果不设置,默认等待时间为0。
- from selenium import webdriver
-
- browser = webdriver.Chrome()
- browser.implicitly_wait(10)
- browser.get('https://www.zhihu.com/explore')
- input = browser.find_element_by_class_name('zu-top-add-question')
- print(input)
异常处理
这里的异常比较复杂,官网的参考地址:
http://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions
这里只进行简单的演示,查找一个不存在的元素
- from selenium import webdriver
- from selenium.common.exceptions import TimeoutException, NoSuchElementException
-
- browser = webdriver.Chrome()
- try:
- browser.get('https://www.baidu.com')
- except TimeoutException:
- print('Time Out')
- try:
- browser.find_element_by_id('hello')
- except NoSuchElementException:
- print('No Element')
- finally:
- browser.close()
2、PhantomJS
中式读法:【 饭特姆JS 】
************************* PhantomJS 已经停止更新 *************************
PhantomJS(官网: http://phantomjs.org/ )是一个基于 WebKit 内核、无 UI 界面的浏览器,WebKit 是一个开源的浏览器引擎。比如,主流的 Safari、Google Chrome、傲游3、猎豹浏览器、百度浏览器、opera浏览器 都是基于 Webkit 开发。)
PhantomJS 会把网站数据加载到内存中,并执行页面上的 JavaScript,但不会向用户展示图形界面。
PhantomJS 是一个无界面的,可脚本编程的WebKit浏览器引擎。它原生支持多种web 标准:DOM 操作,CSS选择器,JSON,Canvas 以及SVG。
官方网站:http://phantomjs.org/download.html
Examples:http://phantomjs.org/examples/index.html
安装完成之后命令行输入:phantomjs -v
如果正常显示版本号,那么证明安装成功了。如果提示错误,那么请重新安装。
3、pyppeteer:比 selenium 更高效的爬虫利器
pyppeteer API Reference:https://miyakogi.github.io/pyppeteer/reference.html
pyppeteer github 地址:https://github.com/miyakogi/pyppeteer
pyppeteer 英文文档地址:https://miyakogi.github.io/pyppeteer/
puppeteer 快速入门:https://blog.csdn.net/freeking101/article/details/91542887
pyppeteer 进阶技巧:https://www.cnblogs.com/dyfblog/p/10887940.html
爬虫、获取cookie、截屏插件、防爬绕过:https://mohen.blog.csdn.net/article/details/107312709
爬虫神器 Pyppeteer 的使用:https://blog.csdn.net/weixin_38819889/article/details/108684254
Pyppeteer 这个项目是非官方的,是基于谷歌官方puppeteer的python版本。chrome 就问题多多,puppeteer也是各种坑,加上pyppeteer是前两者的python版本,也就是产生了只要前两个有一个有bug,那么pyppeteer就会原封不动的继承下来,本来这没什么,但是现在遇到的问题就是 pyppeteer 这个项目已经停止更新,导致很多 bug 根本没人修复。所以,Pyppeteer 已经停止更新,可以使用 playwright-python 代替。
selenium 作为一款知名的 Web 自动化测试框架,selenium 支持多款主流浏览器,提供了功能丰富的API 接口,经常被我们用作爬虫工具来使用。但是 selenium 的缺点也很明显,比如速度太慢、对版本配置要求严苛,最麻烦是经常要更新对应的驱动。还有些网页是可以检测到是否是使用了selenium 。并且selenium 所谓的保护机制不允许跨域 cookies 保存以及登录的时候必须先打开网页然后后加载 cookies 再刷新的方式很不友好。
介绍 Pyppeteer 之前先说一下 Puppeteer,Puppeteer 是 Google 基于 Node.js 开发的一个工具,主要是用来操纵 Chrome 浏览器的 API,通过 Javascript 代码来操纵 Chrome 浏览器的一些操作,用作网络爬虫完成数据爬取、Web 程序自动测试等任务。其 API 极其完善,功能非常强大。 而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本的实现,但他不是 Google 开发的,是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
Pyppeteer 的两大特点:chromium 浏览器 和 asyncio框架。
Pyppeteer 其实是 Puppeteer 的 Python 版本。pyppeteer 模块看不懂就去看puppeteer文档,pyppeteer 只是在 puppeteer之上稍微包装了下而已 。
安装 pyppeteer 库:pip3 install pyppeteer 至于 chromium 浏览器,只需要一条 pyppeteer-install 命令就会自动下载对应的最新版本 chromium 浏览器到 pyppeteer 的默认位置。
window 下 安装完 pyppeteer ,会在 python 安装目录下的 Scripts 目录下 有 pyppeteer-install.exe 和 pyppeteer-install-script.py 两个文件,执行 任意一个都可以安装 chromium 浏览器到 pyppeteer 的默认位置。
如果不运行 pyppeteer-install 命令,在第一次使用 pyppeteer 的时候也会自动下载并安装 chromium 浏览器,效果是一样的。总的来说,pyppeteer 比起 selenium 省去了 driver 配置的环节。
当然,出于某种原因(需要梯子,或者科学上网),也可能会出现chromium自动安装无法顺利完成的情况,这时可以考虑手动安装:首先,从下列网址中找到自己系统的对应版本,下载chromium压缩包;
'linux': 'https://storage.googleapis.com/chromium-browser-snapshots/Linux_x64/575458/chrome-linux.zip'
'mac': 'https://storage.googleapis.com/chromium-browser-snapshots/Mac/575458/chrome-mac.zip'
'win32': 'https://storage.googleapis.com/chromium-browser-snapshots/Win/575458/chrome-win32.zip'
'win64': 'https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/575458/chrome-win32.zip'
然后,将压缩包放到 pyppeteer 的指定目录下解压缩,windows 系统的默认目录。
其他系统下的默认目录可以参照下面:
- Windows: C:\Users\<username>\AppData\Local\pyppeteer
- OS X: /Users/<username>/Library/Application Support/pyppeteer
- Linux: /home/<username>/.local/share/pyppeteer
or in $XDG_DATA_HOME/pyppeteer if $XDG_DATA_HOME is defined.
Details see appdirs’s user_data_dir.
好了,安装完成之后我们命令行下测试下:
>>> import pyppeteer
如果没有报错,那么就证明安装成功了。
示例:
执行代码后,手动输入用户名和密码,滑动滑块,可以正常跳转到登录后个人页面。
提示:这个手动滑动滑块有一定的失败几率,有时候失败几率还很高。有时一次就可以滑过,有时好多次都过不去。
示例代码:
- import asyncio
- from pyppeteer import launch
-
- width, height = 1366, 768
-
-
- js1 = '''() =>{Object.defineProperties(navigator,{ webdriver:{ get: () => false}})}'''
- js2 = '''() => {alert(window.navigator.webdriver)}'''
- js3 = '''() => {window.navigator.chrome = {runtime: {}, }; }'''
- js4 = '''() =>{Object.defineProperty(navigator, 'languages', {get: () => ['en-US', 'en']});}'''
- js5 = '''() =>{Object.defineProperty(navigator, 'plugins', {get: () => [1, 2, 3, 4, 5,6],});}'''
-
-
- async def page_evaluate(page):
- # 替换淘宝在检测浏览时采集的一些参数
- # 需要注意,在测试的过程中发现登陆成功后页面的该属性又会变成True
- # 所以在每次重新加载页面后要重新设置该属性的值。
- await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
- await page.evaluate('''() =>{ window.navigator.chrome = { runtime: {}, }; }''')
- await page.evaluate('''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }''')
- await page.evaluate('''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }''')
-
-
- async def main():
- browser = await launch(
- headless=False,
- # userDataDir='./userdata',
- args=['--disable-infobars', f'--window-size={width},{height}', '--no-sandbox']
- )
- page = await browser.newPage()
-
- await page.setViewport(
- {
- "width": width,
- "height": height
- }
- )
- # url = 'https://www.taobao.com'
- url = 'https://login.taobao.com/member/login.jhtml'
- await page.goto(url=url)
-
- await page.evaluate(js1)
- await page.evaluate(js3)
- await page.evaluate(js4)
- await page.evaluate(js5)
-
- # await page_evaluate(page)
-
- await asyncio.sleep(100)
- # await browser.close()
-
- asyncio.get_event_loop().run_until_complete(main())
基础用法
抓取内容 可以使用 xpath 表达式
"""
# Pyppeteer 三种解析方式
Page.querySelector() # 选择器
Page.querySelectorAll()
Page.xpath() # xpath 表达式
# 简写方式为:
Page.J(), Page.JJ(), and Page.Jx()
"""
- import asyncio
- from pyppeteer import launch
-
-
- async def main():
- # headless参数设为False,则变成有头模式
- # Pyppeteer支持字典和关键字传参,Puppeteer只支持字典传参
-
- # 指定引擎路径
- # exepath = r'C:\Users\Administrator\AppData\Local\pyppeteer\pyppeteer\local-chromium\575458\chrome-win32/chrome.exe'
- # browser = await launch({'executablePath': exepath, 'headless': False, 'slowMo': 30})
-
- browser = await launch(
- # headless=False,
- {'headless': False}
- )
-
- page = await browser.newPage()
-
- # 设置页面视图大小
- await page.setViewport(viewport={'width': 1280, 'height': 800})
-
- # 是否启用JS,enabled设为False,则无渲染效果
- await page.setJavaScriptEnabled(enabled=True)
- # 超时间见 1000 毫秒
- res = await page.goto('https://www.toutiao.com/', options={'timeout': 1000})
- resp_headers = res.headers # 响应头
- resp_status = res.status # 响应状态
-
- # 等待
- await asyncio.sleep(2)
- # 第二种方法,在while循环里强行查询某元素进行等待
- while not await page.querySelector('.t'):
- pass
- # 滚动到页面底部
- await page.evaluate('window.scrollBy(0, document.body.scrollHeight)')
-
- await asyncio.sleep(2)
- # 截图 保存图片
- await page.screenshot({'path': 'toutiao.png'})
-
- # 打印页面cookies
- print(await page.cookies())
-
- """ 打印页面文本 """
- # 获取所有 html 内容
- print(await page.content())
-
- # 在网页上执行js 脚本
- dimensions = await page.evaluate(pageFunction='''() => {
- return {
- width: document.documentElement.clientWidth, // 页面宽度
- height: document.documentElement.clientHeight, // 页面高度
- deviceScaleFactor: window.devicePixelRatio, // 像素比 1.0000000149011612
- }
- }''', force_expr=False) # force_expr=False 执行的是函数
- print(dimensions)
-
- # 只获取文本 执行 js 脚本 force_expr 为 True 则执行的是表达式
- content = await page.evaluate(pageFunction='document.body.textContent', force_expr=True)
- print(content)
-
- # 打印当前页标题
- print(await page.title())
-
- # 抓取新闻内容 可以使用 xpath 表达式
- """
- # Pyppeteer 三种解析方式
- Page.querySelector() # 选择器
- Page.querySelectorAll()
- Page.xpath() # xpath 表达式
- # 简写方式为:
- Page.J(), Page.JJ(), and Page.Jx()
- """
- element = await page.querySelector(".feed-infinite-wrapper > ul>li") # 纸抓取一个
- print(element)
- # 获取所有文本内容 执行 js
- content = await page.evaluate('(element) => element.textContent', element)
- print(content)
-
- # elements = await page.xpath('//div[@class="title-box"]/a')
- elements = await page.querySelectorAll(".title-box a")
- for item in elements:
- print(await item.getProperty('textContent'))
- # <pyppeteer.execution_context.JSHandle object at 0x000002220E7FE518>
-
- # 获取文本
- title_str = await (await item.getProperty('textContent')).jsonValue()
-
- # 获取链接
- title_link = await (await item.getProperty('href')).jsonValue()
- print(title_str)
- print(title_link)
-
- # 关闭浏览器
- await browser.close()
-
-
- asyncio.get_event_loop().run_until_complete(main())
- import asyncio
- import pyppeteer
- from collections import namedtuple
-
- headers = {
- 'date': 'Sun, 28 Apr 2019 06:50:20 GMT',
- 'server': 'Cmcc',
- 'x-frame-options': 'SAMEORIGIN\nSAMEORIGIN',
- 'last-modified': 'Fri, 26 Apr 2019 09:58:09 GMT',
- 'accept-ranges': 'bytes',
- 'cache-control': 'max-age=43200',
- 'expires': 'Sun, 28 Apr 2019 18:50:20 GMT',
- 'vary': 'Accept-Encoding,User-Agent',
- 'content-encoding': 'gzip',
- 'content-length': '19823',
- 'content-type': 'text/html',
- 'connection': 'Keep-alive',
- 'via': '1.1 ID-0314217270751344 uproxy-17'
- }
-
- Response = namedtuple("rs", "title url html cookies headers history status")
-
-
- async def get_html(url):
- browser = await pyppeteer.launch(headless=True, args=['--no-sandbox'])
- page = await browser.newPage()
- res = await page.goto(url, options={'timeout': 10000})
- data = await page.content()
- title = await page.title()
- resp_cookies = await page.cookies() # cookie
- resp_headers = res.headers # 响应头
- resp_status = res.status # 响应状态
- print(data)
- print(title)
- print(resp_headers)
- print(resp_status)
- return title
-
-
- if __name__ == '__main__':
- url_list = [
- "https://www.toutiao.com",
- "http://jandan.net/ooxx/page-8#comments",
- "https://www.12306.cn/index"
- ]
- task = [get_html(url) for url in url_list]
-
- loop = asyncio.get_event_loop()
- results = loop.run_until_complete(asyncio.gather(*task))
- for res in results:
- print(res)
模拟输入
模拟输入文本:
- # 模拟输入 账号密码 {'delay': rand_int()} 为输入时间
- await page.type('#TPL_username_1', "sadfasdfasdf")
- await page.type('#TPL_password_1', "123456789", )
-
- await page.waitFor(1000)
- await page.click("#J_SubmitStatic")
使用 tkinter 获取页面高度 宽度
- def screen_size():
- """使用tkinter获取屏幕大小"""
- import tkinter
- tk = tkinter.Tk()
- width = tk.winfo_screenwidth()
- height = tk.winfo_screenheight()
- tk.quit()
- return width, height
爬取京东商城
示例代码:
- import requests
- from bs4 import BeautifulSoup
- from pyppeteer import launch
- import asyncio
-
-
- def screen_size():
- """使用tkinter获取屏幕大小"""
- import tkinter
- tk = tkinter.Tk()
- width = tk.winfo_screenwidth()
- height = tk.winfo_screenheight()
- tk.quit()
- return width, height
-
-
- async def main(url):
- # browser = await launch({'headless': False, 'args': ['--no-sandbox'], })
- browser = await launch({'args': ['--no-sandbox'], })
- page = await browser.newPage()
- width, height = screen_size()
- await page.setViewport(viewport={"width": width, "height": height})
- await page.setJavaScriptEnabled(enabled=True)
- await page.setUserAgent(
- 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299'
- )
- await page.goto(url)
-
- # await asyncio.sleep(2)
-
- await page.evaluate('window.scrollBy(0, document.body.scrollHeight)')
-
- await asyncio.sleep(1)
-
- # content = await page.content()
- li_list = await page.xpath('//*[@id="J_goodsList"]/ul/li')
-
- # print(li_list)
- item_list = []
- for li in li_list:
- a = await li.xpath('.//div[@class="p-img"]/a')
- detail_url = await (await a[0].getProperty("href")).jsonValue()
- promo_words = await (await a[0].getProperty("title")).jsonValue()
- a_ = await li.xpath('.//div[@class="p-commit"]/strong/a')
- p_commit = await (await a_[0].getProperty("textContent")).jsonValue()
- i = await li.xpath('./div/div[3]/strong/i')
- price = await (await i[0].getProperty("textContent")).jsonValue()
- em = await li.xpath('./div/div[4]/a/em')
- title = await (await em[0].getProperty("textContent")).jsonValue()
- item = {
- "title": title,
- "detail_url": detail_url,
- "promo_words": promo_words,
- 'p_commit': p_commit,
- 'price': price
- }
- item_list.append(item)
- # print(item)
- # break
- # print(content)
-
- await page_close(browser)
- return item_list
-
-
- async def page_close(browser):
- for _page in await browser.pages():
- await _page.close()
- await browser.close()
-
-
- msg = "手机"
- url = "https://search.jd.com/Search?keyword={}&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq={}&cid2=653&cid3=655&page={}"
-
- task_list = []
- for i in range(1, 6):
- page = i * 2 - 1
- url = url.format(msg, msg, page)
- task_list.append(main(url))
-
- loop = asyncio.get_event_loop()
- results = loop.run_until_complete(asyncio.gather(*task_list))
- # print(results, len(results))
- for i in results:
- print(i, len(i))
-
- print('*' * 100)
- # soup = BeautifulSoup(content, 'lxml')
- # div = soup.find('div', id='J_goodsList')
- # for i, li in enumerate(div.find_all('li', class_='gl-item')):
- # if li.select('.p-img a'):
- # print(li.select('.p-img a')[0]['href'], i)
- # print(li.select('.p-price i')[0].get_text(), i)
- # print(li.select('.p-name em')[0].text, i)
- # else:
- # print("#" * 200)
- # print(li)
抓取淘宝
示例代码:
- # -*- coding: utf-8 -*-
-
- import time
- import random
- import asyncio
- from retrying import retry # 错误自动重试
- from pyppeteer.launcher import launch
-
-
- js1 = '''() =>{Object.defineProperties(navigator,{ webdriver:{ get: () => false}})}'''
- js2 = '''() => {alert(window.navigator.webdriver)}'''
- js3 = '''() => {window.navigator.chrome = {runtime: {}, }; }'''
- js4 = '''() =>{Object.defineProperty(navigator, 'languages', {get: () => ['en-US', 'en']});}'''
- js5 = '''() =>{Object.defineProperty(navigator, 'plugins', {get: () => [1, 2, 3, 4, 5,6],});}'''
-
-
- def retry_if_result_none(result):
- return result is None
-
-
- @retry(retry_on_result=retry_if_result_none, )
- async def mouse_slide(page=None):
- await asyncio.sleep(3)
- try:
- await page.hover('#nc_1_n1z')
- await page.mouse.down()
- await page.mouse.move(2000, 0, {'delay': random.randint(1000, 2000)})
- await page.mouse.up()
-
- except Exception as e:
- print(e, ' :slide login False')
- return None
- else:
- await asyncio.sleep(3)
- slider_again = await page.Jeval('.nc-lang-cnt', 'node => node.textContent')
- if slider_again != '验证通过':
- return None
- else:
- await page.screenshot({'path': './headless-slide-result.png'})
- print('验证通过')
- return 1
-
-
- def input_time_random():
- return random.randint(100, 151)
-
-
- def screen_size():
- """使用tkinter获取屏幕大小"""
- import tkinter
- tk = tkinter.Tk()
- width = tk.winfo_screenwidth()
- height = tk.winfo_screenheight()
- tk.quit()
- return width, height
-
-
- async def main(username, pwd, url):
- browser = await launch(
- {'headless': False, 'args': ['--no-sandbox'], },
- userDataDir='./userdata',
- args=['--window-size=1366,768']
- )
- page = await browser.newPage()
- width, height = screen_size()
- await page.setViewport(viewport={"width": width, "height": height})
- await page.setUserAgent(
- 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299'
- )
-
- await page.goto(url)
- await page.evaluate(js1)
- await page.evaluate(js3)
- await page.evaluate(js4)
- await page.evaluate(js5)
-
- pwd_login = await page.querySelector('.J_Quick2Static')
- # print(await (await pwd_login.getProperty('textContent')).jsonValue())
- await pwd_login.click()
-
- await page.type('#TPL_username_1', username, {'delay': input_time_random() - 50})
- await page.type('#TPL_password_1', pwd, {'delay': input_time_random()})
-
- await page.screenshot({'path': './headless-test-result.png'})
- time.sleep(2)
-
- slider = await page.Jeval('#nocaptcha', 'node => node.style') # 是否有滑块
-
- if slider:
- print('出现滑块情况判定')
- await page.screenshot({'path': './headless-login-slide.png'})
- flag = await mouse_slide(page=page)
- if flag:
- print(page.url)
- await page.keyboard.press('Enter')
- await get_cookie(page)
- else:
- await page.keyboard.press('Enter')
- await page.waitFor(20)
- await page.waitForNavigation()
- try:
- global error
- error = await page.Jeval('.error', 'node => node.textContent')
- except Exception as e:
- error = None
- print(e, "错啦")
- finally:
- if error:
- print('确保账户安全重新入输入')
- else:
- print(page.url)
- # 可继续网页跳转 已经携带 cookie
- # await get_search(page)
- await get_cookie(page)
- await page_close(browser)
-
-
- async def page_close(browser):
- for _page in await browser.pages():
- await _page.close()
- await browser.close()
-
-
- async def get_search(page):
- # https://s.taobao.com/search?q={查询的条件}&p4ppushleft=1%2C48&s={每页 44 条 第一页 0 第二页 44}&sort=sale-desc
- await page.goto("https://s.taobao.com/search?q=气球")
-
- await asyncio.sleep(5)
- # print(await page.content())
-
-
- # 获取登录后cookie
- async def get_cookie(page):
- res = await page.content()
- cookies_list = await page.cookies()
- cookies = ''
- for cookie in cookies_list:
- str_cookie = '{0}={1};'
- str_cookie = str_cookie.format(cookie.get('name'), cookie.get('value'))
- cookies += str_cookie
- print(cookies)
- # 将cookie 放入 cookie 池 以便多次请求 封账号 利用cookie 对搜索内容进行爬取
- return cookies
-
-
- if __name__ == '__main__':
- tb_username = '淘宝用户名'
- tb_pwd = '淘宝密码'
- tb_url = "https://login.taobao.com/member/login.jhtml"
-
- loop = asyncio.get_event_loop()
- loop.run_until_complete(main(tb_username, tb_pwd, tb_url))
利用 上面 获取到的 cookie 爬取搜索内容
示例代码:
- import json
- import requests
- import re
-
- # 设置 cookie 池 随机发送请求 通过 pyppeteer 获取 cookie
- cookie = '_tb_token_=edd7e354dee53;t=fed8f4ca1946ca1e73223cfae04bc589;sg=20f;cna=2uJSFdQGmDMCAbfFWXWAC4Jv;cookie2=1db6cd63ad358170ea13319f7a862c33;_l_g_=Ug%3D%3D;v=0;unb=3150916610;skt=49cbfd5e01d1b550;cookie1=BxVRmD3sh19TaAU6lH88bHw5oq%2BgcAGcRe229Hj5DTA%3D;csg=cf45a9e2;uc3=vt3=F8dByEazRMnQZDe%2F9qI%3D&id2=UNGTqfZ61Z3rsA%3D%3D&nk2=oicxO%2BHX4Pg%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D;existShop=MTU1Njg3MDM3MA%3D%3D;tracknick=%5Cu7433150322;lgc=%5Cu7433150322;_cc_=V32FPkk%2Fhw%3D%3D;mt=ci=86_1;dnk=%5Cu7433150322;_nk_=%5Cu7433150322;cookie17=UNGTqfZ61Z3rsA%3D%3D;tg=0;enc=tThHs6Sn3BAl8v1fu3J4tMpgzA1n%2BLzxjib0vDAtGsXJCb4hqQZ7Z9fHIzsN0WghdcKEsoeKz6mBwPUpyzLOZw%3D%3D;JSESSIONID=B3F383B3467EC60F8CA425935232D395;l=bBMspAhrveV5732DBOCanurza77OSIRYYuPzaNbMi_5pm6T_G4QOlC03xF96VjfRswYBqh6Mygv9-etuZ;hng=CN%7Czh-CN%7CCNY%7C156;isg=BLi41Q8PENDal3xUVsA-aPbfiWaKiRzB6vcTu_IpBPOmDVj3mjHsO86vxUQYW9SD;uc1=cookie16=W5iHLLyFPlMGbLDwA%2BdvAGZqLg%3D%3D&cookie21=W5iHLLyFeYZ1WM9hVnmS&cookie15=UIHiLt3xD8xYTw%3D%3D&existShop=false&pas=0&cookie14=UoTZ4ttqLhxJww%3D%3D&tag=8&lng=zh_CN;thw=cn;x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0;swfstore=34617;'
-
- headers = {
- 'cookie': cookie,
- "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
- }
-
- rep = requests.get('https://s.taobao.com/search?q=手机&p4ppushleft=1%2C48&s=0&sort=sale-desc ', headers=headers)
- rep.encoding = 'utf-8'
- res = rep.text
- print(res)
-
- r = re.compile(r'g_page_config = (.*?)g_srp_loadCss', re.S)
- res = r.findall(res)
-
- data = res[0].strip().rstrip(';')
- dic_data = json.loads(data)
- auctions = dic_data.get('mods')['itemlist']['data']['auctions']
-
- # print(auctions,len(auctions))
- for item in auctions[1:]:
- print(item)
- break
针对 iframe 的操作
- page.frames 获取所有的 iframe 列表 需要判断操作的是哪一个 iframe 跟操作 page 一样操作
- from pyppeteer import launch
- import asyncio
-
-
- async def main(url):
- w = await launch({'headless': False, 'args': ['--no-sandbox'], })
-
- page = await w.newPage()
- await page.setViewport({"width": 1366, 'height': 800})
- await page.goto(url)
- try:
- await asyncio.sleep(1)
-
- frame = page.frames
- print(frame) # 需要找到是哪一个 frame
- title = await frame[1].title()
- print(title)
- await asyncio.sleep(1)
- login = await frame[1].querySelector('#switcher_plogin')
- print(login)
- await login.click()
-
- await asyncio.sleep(20)
- except Exception as e:
- print(e, "EEEEEEEEE")
-
- for _page in await w.pages():
- await _page.close()
- await w.close()
-
-
- asyncio.get_event_loop().run_until_complete(main("https://i.qq.com/?rd=1"))
- # asyncio.get_event_loop().run_until_complete(main("https://www.gushici.com/"))
与 scrapy 的整合
加入downloadmiddleware
- from scrapy import signals
- from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
- import random
- import pyppeteer
- import asyncio
- import os
- from scrapy.http import HtmlResponse
-
- pyppeteer.DEBUG = False
-
- class FundscrapyDownloaderMiddleware(object):
- # Not all methods need to be defined. If a method is not defined,
- # scrapy acts as if the downloader middleware does not modify the
- # passed objects.
- def __init__(self) :
- print("Init downloaderMiddleware use pypputeer.")
- os.environ['PYPPETEER_CHROMIUM_REVISION'] ='588429'
- # pyppeteer.DEBUG = False
- print(os.environ.get('PYPPETEER_CHROMIUM_REVISION'))
- loop = asyncio.get_event_loop()
- task = asyncio.ensure_future(self.getbrowser())
- loop.run_until_complete(task)
-
- #self.browser = task.result()
- print(self.browser)
- print(self.page)
- # self.page = await browser.newPage()
- async def getbrowser(self):
- self.browser = await pyppeteer.launch()
- self.page = await self.browser.newPage()
- # return await pyppeteer.launch()
- async def getnewpage(self):
- return await self.browser.newPage()
-
- @classmethod
- def from_crawler(cls, crawler):
- # This method is used by Scrapy to create your spiders.
- s = cls()
- crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
- return s
-
- def process_request(self, request, spider):
- # Called for each request that goes through the downloader
- # middleware.
-
- # Must either:
- # - return None: continue processing this request
- # - or return a Response object
- # - or return a Request object
- # - or raise IgnoreRequest: process_exception() methods of
- # installed downloader middleware will be called
- loop = asyncio.get_event_loop()
- task = asyncio.ensure_future(self.usePypuppeteer(request))
- loop.run_until_complete(task)
- # return task.result()
- return HtmlResponse(url=request.url, body=task.result(), encoding="utf-8",request=request)
-
- async def usePypuppeteer(self, request):
- print(request.url)
- # page = await self.browser.newPage()
- await self.page.goto(request.url)
- content = await self.page.content()
- return content
-
- def process_response(self, request, response, spider):
- # Called with the response returned from the downloader.
-
- # Must either;
- # - return a Response object
- # - return a Request object
- # - or raise IgnoreRequest
- return response
-
- def process_exception(self, request, exception, spider):
- # Called when a download handler or a process_request()
- # (from other downloader middleware) raises an exception.
-
- # Must either:
- # - return None: continue processing this exception
- # - return a Response object: stops process_exception() chain
- # - return a Request object: stops process_exception() chain
- pass
-
- def spider_opened(self, spider):
- spider.logger.info('Spider opened: %s' % spider.name)
实战 异步爬取
示例 1 :快速上手
接下来我们测试下基本的页面渲染操作,这里我们选用的网址为:http://quotes.toscrape.com/js/,这个页面是 JavaScript 渲染而成的,用基本的 requests 库请求得到的 HTML 结果里面是不包含页面中所见的条目内容的。
为了证明 requests 无法完成正常的抓取,我们可以先用如下代码来测试一下:
- import requests
- from pyquery import PyQuery as pq
-
- url = 'http://quotes.toscrape.com/js/'
- response = requests.get(url=url)
- doc = pq(response.text)
- print('Quotes : {0}'.format(doc('.quote').length))
-
- # 结果
- # Quotes : 0
这里首先使用 requests 来请求网页内容,然后使用 pyquery 来解析页面中的每一个条目。观察源码之后我们发现每个条目的 class 名为 quote,所以这里选用了 .quote 这个 CSS 选择器来选择,最后输出条目数量。
运行结果:Quotes: 0
结果是 0,这就证明使用 requests 是无法正常抓取到相关数据的。
为什么?
因为这个页面是 JavaScript 渲染而成的,我们所看到的内容都是网页加载后又执行了 JavaScript 之后才呈现出来的,因此这些条目数据并不存在于原始 HTML 代码中,而 requests 仅仅抓取的是原始 HTML 代码。
好的,所以遇到这种类型的网站我们应该怎么办呢?
其实答案有很多:
- 分析网页源代码数据,如果数据是隐藏在 HTML 中的其他地方,以 JavaScript 变量的形式存在,直接提取就好了。
- 分析 Ajax,很多数据可能是经过 Ajax 请求时候获取的,所以可以分析其接口。
- 模拟 JavaScript 渲染过程,直接抓取渲染后的结果。
而 Pyppeteer 和 Selenium 就是用的第三种方法,下面我们再用 Pyppeteer 来试试,如果用 Pyppeteer 实现如上页面的抓取的话,代码就可以写为如下形式:
- import asyncio
- from pyppeteer import launch
- from pyquery import PyQuery as pq
-
-
- async def main():
- browser = await launch()
- page = await browser.newPage()
- url = 'http://quotes.toscrape.com/js/'
- await page.goto(url=url)
- doc = pq(await page.content())
- print('Quotes : {0}'.format(doc('.quote').length))
- await browser.close()
-
- asyncio.get_event_loop().run_until_complete(main())
运行结果:Quotes: 10
看运行结果,这说明我们就成功匹配出来了 class 为 quote 的条目,总数为 10 条,具体的内容可以进一步使用 pyquery 解析查看。
那么这里面的过程发生了什么?
实际上,Pyppeteer 整个流程就完成了浏览器的开启、新建页面、页面加载等操作。另外 Pyppeteer 里面进行了异步操作,所以需要配合 async/await 关键词来实现。首先, launch 方法会新建一个 Browser 对象,然后赋值给 browser,然后调用 newPage 方法相当于浏览器中新建了一个选项卡,同时新建了一个 Page 对象。然后 Page 对象调用了 goto 方法就相当于在浏览器中输入了这个 URL,浏览器跳转到了对应的页面进行加载,加载完成之后再调用 content 方法,返回当前浏览器页面的源代码。然后进一步地,我们用 pyquery 进行同样地解析,就可以得到 JavaScript 渲染的结果了。另外其他的一些方法如调用 asyncio 的 get_event_loop 等方法的相关操作则属于 Python 异步 async 相关的内容了,大家如果不熟悉可以了解下 Python 的 async/await 的相关知识。好,通过上面的代码,我们就可以完成 JavaScript 渲染页面的爬取了。
模拟网页截图,保存 PDF,执行自定义的 JavaScript 获得特定的内容
接下来我们再看看另外一个例子,这个例子可以模拟网页截图,保存 PDF,另外还可以执行自定义的 JavaScript 获得特定的内容,代码如下:
- import asyncio
- from pyppeteer import launch
-
-
- async def main():
- browser = await launch()
- page = await browser.newPage()
- url = 'http://quotes.toscrape.com/js/'
- await page.goto(url=url)
- await page.screenshot(path='test_screenshot.png')
- await page.pdf(path='test_pdf.pdf')
-
- # 在网页上执行js 脚本
- dimensions = await page.evaluate(pageFunction='''() => {
- return {
- width: document.documentElement.clientWidth, // 页面宽度
- height: document.documentElement.clientHeight, // 页面高度
- deviceScaleFactor: window.devicePixelRatio, // 像素比 1.0000000149011612
- }
- }''', force_expr=False) # force_expr=False 执行的是函数
-
- print(dimensions)
- await browser.close()
-
-
- asyncio.get_event_loop().run_until_complete(main())
-
- # 结果
- # {'width': 800, 'height': 600, 'deviceScaleFactor': 1}
这里我们又用到了几个新的 API,完成了网页截图保存、网页导出 PDF 保存、执行 JavaScript 并返回对应数据。
evaluate 方法执行了一些 JavaScript,JavaScript 传入的是一个函数,使用 return 方法返回了网页的宽高、像素大小比率三个值,最后得到的是一个 JSON 格式的对象。
总之利用 Pyppeteer 我们可以控制浏览器执行几乎所有动作,想要的操作和功能基本都可以实现,用它来自由地控制爬虫当然就不在话下了。
了解了基本的实例之后,我们再来梳理一下 Pyppeteer 的一些基本和常用操作。Pyppeteer 的几乎所有功能都能在其官方文档的 API Reference 里面找到,链接为:API Reference — Pyppeteer 0.0.25 documentation,用到哪个方法就来这里查询就好了,参数不必死记硬背,即用即查就好。
登录淘宝 (打开网页后,手动输入用户名和密码,可以看到正常跳转到登录后的页面):
- import asyncio
- from pyppeteer import launch
-
- width, height = 1366, 768
-
-
- js1 = '''() =>{Object.defineProperties(navigator,{ webdriver:{ get: () => false}})}'''
- js2 = '''() => {alert(window.navigator.webdriver)}'''
- js3 = '''() => {window.navigator.chrome = {runtime: {}, }; }'''
- js4 = '''() =>{Object.defineProperty(navigator, 'languages', {get: () => ['en-US', 'en']});}'''
- js5 = '''() =>{Object.defineProperty(navigator, 'plugins', {get: () => [1, 2, 3, 4, 5,6],});}'''
-
-
- async def page_evaluate(page):
- # 替换淘宝在检测浏览时采集的一些参数
- # 需要注意,在测试的过程中发现登陆成功后页面的该属性又会变成True
- # 所以在每次重新加载页面后要重新设置该属性的值。
- await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
- await page.evaluate('''() =>{ window.navigator.chrome = { runtime: {}, }; }''')
- await page.evaluate('''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }''')
- await page.evaluate('''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }''')
-
-
- async def main():
- browser = await launch(
- headless=False,
- # userDataDir='./userdata',
- args=['--disable-infobars', f'--window-size={width},{height}', '--no-sandbox']
- )
- page = await browser.newPage()
-
- await page.setViewport(
- {
- "width": width,
- "height": height
- }
- )
- url = 'https://www.taobao.com'
- await page.goto(url=url)
-
- # await page.evaluate(js1)
- # await page.evaluate(js3)
- # await page.evaluate(js4)
- # await page.evaluate(js5)
-
- await page_evaluate(page)
-
- await asyncio.sleep(100)
- # await browser.close()
-
- asyncio.get_event_loop().run_until_complete(main())
如果把上面 js 去掉,发现淘宝可以检测出来, 跳转不到登录后的页面。
window.navigator 对象包含有关访问者浏览器的信息:https://www.runoob.com/js/js-window-navigator.html
js 主要需要修改浏览器的 window.navigator.webdriver、window.navigator.languages等值。
打开正常的浏览器可以看到:
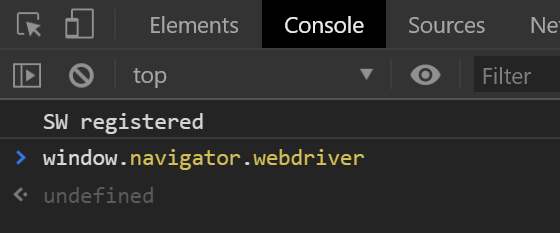
window.navigator.webdriver的值为undefined,而通过pyppeteer控制打开的浏览器该值为True,当被检测到该值为True的时候,则滑动会一直失败,所以我们需要修改该属性。需要注意,在测试的过程中发现登陆成功后页面的该属性又会变成True,所以在每次重新加载页面后要重新设置该属性的值。
- async def page_evaluate(page):
- # 替换淘宝在检测浏览时采集的一些参数
- await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')
- await page.evaluate('''() =>{ window.navigator.chrome = { runtime: {}, }; }''')
- await page.evaluate('''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }''')
- await page.evaluate('''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }''')
另一种方法可以进一步免去淘宝登录的烦恼,那就是设置用户目录。
平时我们已经注意到,当我们登录淘宝之后,如果下次再次打开浏览器发现还是登录的状态。这是因为淘宝的一些关键 Cookies 已经保存到本地了,下次登录的时候可以直接读取并保持登录状态。
那么这些信息保存在哪里了呢?其实就是保存在用户目录下了,里面不仅包含了浏览器的基本配置信息,还有一些 Cache、Cookies 等各种信息都在里面,如果我们能在浏览器启动的时候读取这些信息,那么启动的时候就可以恢复一些历史记录甚至一些登录状态信息了。
这也就解决了一个问题:很多朋友在每次启动 Selenium 或 Pyppeteer 的时候总是是一个全新的浏览器,那就是没有设置用户目录,如果设置了它,每次打开就不再是一个全新的浏览器了,它可以恢复之前的历史记录,也可以恢复很多网站的登录信息。
当然可能时间太久了,Cookies 都过期了,那还是需要登录的。
那么这个怎么来做呢?很简单,在启动的时候设置 userDataDir 就好了,示例如下:
- browser = await launch(
- headless=False,
- userDataDir='./userdata',
- args=['--disable-infobars', f'--window-size={width},{height}']
- )
用户文件夹
具体的介绍可以看官方的一些说明,如:https://chromium.googlesource.com/chromium/src/+/master/docs/user_data_dir.md 这里面介绍了 userdatadir 的相关内容。
命令行启动 chrome 并进入指定的 URL:chrome.exe --disable-infobars --user-data-dir="./userdatadir" --new-window https://login.taobao.com/member/login.jhtml
执行完后会打开 淘宝的登录页面,登录淘宝,然后保存用户名密码,这样登录信息就保存在 userdatadir 目录下了
在执行 chrome.exe --disable-infobars --user-data-dir="./userdatadir" --new-window https://www.taobao.com
可以看到已经时登录状态了。
爬取今日头条
- # -*- coding: utf-8 -*-
- # @Author :
- # @File : toutiao.py
- # @Software: PyCharm
- # @description : XXX
-
-
- import asyncio
- from pyppeteer import launch
- from pyquery import PyQuery as pq
-
-
- def screen_size():
- """使用tkinter获取屏幕大小"""
- import tkinter
- tk = tkinter.Tk()
- width = tk.winfo_screenwidth()
- height = tk.winfo_screenheight()
- tk.quit()
- return width, height
-
-
- async def main():
- width, height = screen_size()
- print(f'screen : [ width:{width} , height:{height} ]')
-
- browser = await launch(headless=False, args=[f'--window-size={width},{height}'])
- page = await browser.newPage()
- await page.setViewport({'width': width, 'height': height})
-
- # 是否启用JS,enabled设为False,则无渲染效果
- await page.setJavaScriptEnabled(enabled=True)
-
- await page.goto('https://www.toutiao.com')
- await asyncio.sleep(5)
-
- print(await page.cookies()) # 打印页面cookies
- print(await page.content()) # 打印页面文本
- print(await page.title()) # 打印当前页标题
-
- # 抓取新闻标题
- title_elements = await page.xpath('//div[@class="title-box"]/a')
- for item in title_elements:
- # 获取文本
- title_str = await (await item.getProperty('textContent')).jsonValue()
- print(await item.getProperty('textContent'))
- # 获取链接
- title_link = await (await item.getProperty('href')).jsonValue()
- print(title_str)
- print(title_link)
-
- # 在搜索框中输入python
- await page.type('input.tt-input__inner', 'python')
-
- # 点击搜索按钮
- await page.click('button.tt-button')
- await asyncio.sleep(5)
-
- # print(page.url)
- # 今日头条点击后新开一个页面, 通过打印url可以看出page还停留在原页面
- # 以下用于切换至新页面
- pages = await browser.pages()
- page = pages[-1]
- # print(page.url)
-
- page_source = await page.content()
- text = pq(page_source)
- await page.goto(
- url="https://www.toutiao.com/api/search/content/?"
- "aid=24&app_name=web_search&offset=60&format=json"
- "&keyword=python&autoload=true&count=20&en_qc=1"
- "&cur_tab=1&from=search_tab&pd=synthesis×tamp=1555589585193"
- )
- for i in range(1, 10):
- print(text("#J_section_{} > div > div > div.normal.rbox > div > div.title-box > a > span".format(i)).text())
-
- # 关闭浏览器
- await browser.close()
-
- asyncio.get_event_loop().run_until_complete(main())
4、selenium 反检测
利用 Chrome DevTools 协议
Chrome DevTools Protocol (协议详细内容):https://chromedevtools.github.io/devtools-protocol/
之前淘宝对于 selenium 还是很友好的,后来 selenium 被检测了 window.navigator.webdriver 等参数,出滑动验证码什么的,selenium 已经很难用了,
利用 Chrome DevTools 协议。它允许客户 检查 和 调试 Chrome 浏览器。
在 系统环境变量 PATH 里将 chrome的路径 添加进去。
打开cmd,在命令行中输入命令:chrome.exe --remote-debugging-port=9999 --user-data-dir="C:\selenum\AutomationProfile"
对于-remote-debugging-port 值,可以指定任何打开的端口。
对于-user-data-dir 标记,指定创建新 Chrome 配置文件的目录。它是为了确保在单独的配置文件中启动 chrome,不会污染你的默认配置文件。
执行完命令后,会打开一个浏览器页面,我们输入淘宝网址(https://login.taobao.com/member/login.jhtml),输入用户名和密码,登录淘宝后用户信息就保存在 --user-data-dir="C:\selenum\AutomationProfile" 所指定的文件夹中。
执行 js window.open() 打不开窗口时,是因为 chrome 默认不允许弹出窗口,改下 chrome 设置就可以了
在 chrome 浏览器地址栏输入:chrome://settings/content/popups,把 已阻止(推荐) 改成 允许 即可。
或者 chrome -》设置 -》高级 -》隐私设置和安全性 -》网站设置 -》弹出式窗口和重定向,也可以设置。
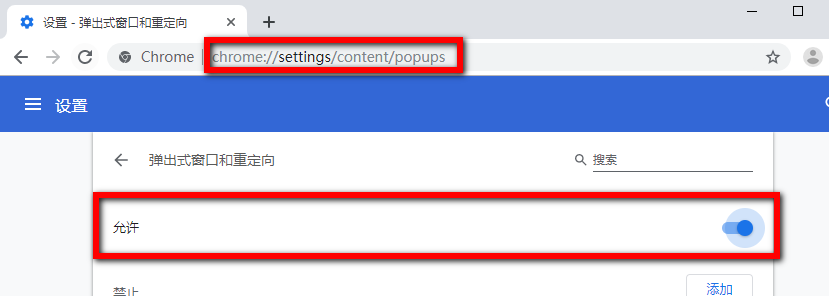
不要关闭上面浏览器,然后执行 python 代码。在淘宝搜索 "电脑" 关键字,并打印前 5 页 所有 搜索内容
- import os
- import time
- import random
- from selenium import webdriver
- from selenium.webdriver.chrome.options import Options
- from selenium.webdriver.support.ui import WebDriverWait
- from selenium.webdriver.common.by import By
- from selenium.webdriver.support import expected_conditions as EC
-
- # from selenium.webdriver.common.action_chains import ActionChains
-
-
- def main():
- # os.system(r'C:\Users\Administrator\AppData\Local\Google\Chrome\Application/chrome.exe --remote-debugging-port=9999 --user-data-dir="C:\selenum\AutomationProfile"')
- chrome_debug_port = 9999
- chrome_options = Options()
- # chrome_options.add_argument('--headless')
- chrome_options.add_experimental_option("debuggerAddress", f"127.0.0.1:{chrome_debug_port}")
-
- browser = webdriver.Chrome(chrome_options=chrome_options)
- wait = WebDriverWait(browser, 5)
- print(browser.title)
-
- # 当前句柄
- current_handle = browser.current_window_handle
-
- # browser.execute_script('window.open("https://login.taobao.com/member/login.jhtml")')
- browser.execute_script('window.open("http://www.baidu.com")')
-
- # 所有句柄
- all_handle = browser.window_handles
- second_handle = all_handle[-1]
-
- # 切回first
- browser.switch_to.window(current_handle)
-
- url = 'https://s.taobao.com/search?q=电脑'
- browser.get(url)
-
- produce_info_xpath = '//div[contains(@class, "J_MouserOnverReq")]//div[@class="row row-2 title"]/a'
- produce_info = browser.find_elements_by_xpath(produce_info_xpath)
- for produce in produce_info:
- print(produce.text.replace(' ', ''))
-
- # 这里是演示,所以只爬了前 5 页
- for page_num in range(2, 6):
- next_page_xpath = '//li[@class="item next"]'
- next_page = browser.find_element_by_xpath(next_page_xpath)
- next_page_enable = False if 'disabled' in next_page.get_attribute('class') else True
- if next_page_enable:
- print('*' * 100)
- print(f'第 {page_num} 页')
- next_page.click()
- # browser.refresh()
- produce_info_xpath = '//div[contains(@class, "J_MouserOnverReq")]//div[@class="row row-2 title"]/a'
-
- wait.until(EC.presence_of_all_elements_located((By.XPATH, produce_info_xpath)))
- time.sleep(random.randint(3, 5))
- produce_info = browser.find_elements_by_xpath(produce_info_xpath)
- for produce in produce_info:
- print(produce.text.replace(' ', ''))
- else:
- break
-
-
- if __name__ == '__main__':
- main()
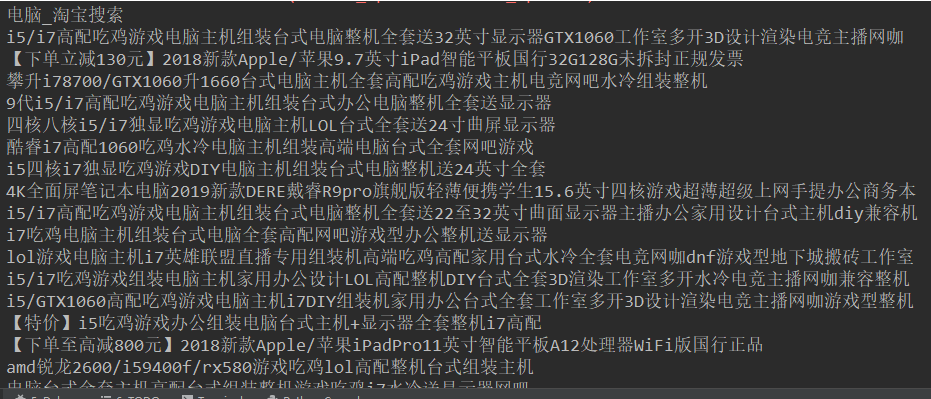
代码 2(根据关键字搜索,然后抓取 店铺名,店铺地址,店铺电话,):
- # -*- coding: utf-8 -*-
-
-
- import time
- import random
- import parsel
- import re
- from selenium import webdriver
- from selenium.webdriver.chrome.options import Options
- from selenium.webdriver.support.ui import WebDriverWait
- from selenium.webdriver.common.by import By
- from selenium.webdriver.support import expected_conditions as EC
-
-
- # from selenium.webdriver.common.action_chains import ActionChains
-
- class TaoBaoSearch(object):
- def __init__(self):
- super(TaoBaoSearch, self).__init__()
- self.browser = None
- self.wait = None
- self.master_handler = None
- self.slaver_handler = None
- self.temp = None
- self.browser_init()
-
- def browser_init(self):
- chrome_debug_port = 9999
- chrome_options = Options()
- chrome_options.add_experimental_option("debuggerAddress", f"127.0.0.1:{chrome_debug_port}")
- # chrome_options.add_argument('--headless')
-
- self.browser = webdriver.Chrome(chrome_options=chrome_options)
- self.wait = WebDriverWait(self.browser, 5)
-
- all_handler = self.browser.window_handles
- if len(all_handler) >= 1:
- for index in all_handler[1:]:
- self.browser.switch_to.window(index)
- self.browser.close()
-
- # self.master_handler = self.browser.current_window_handle
- self.master_handler = self.browser.window_handles[0]
-
- self.browser.switch_to.window(self.master_handler)
- self.browser.execute_script('window.open()')
- # self.browser.execute_script('window.open("_blank")')
- handlers = self.browser.window_handles
- self.slaver_handler = handlers[-1]
- # print(self.browser.title)
-
- def get_detail_info(self, shop_url=None):
- # 切换到 从 窗口
- self.browser.switch_to.window(self.slaver_handler)
- self.browser.get(shop_url)
- html = self.browser.page_source
- html = html.replace('<', '<').replace('>', '>')
- # print(html)
- s_html = parsel.Selector(text=html)
- shop_keeper_xpath = '//div[@class="extend"]//li[@class="shopkeeper"]//a/text()'
- shop_keeper = s_html.xpath(shop_keeper_xpath).extract_first()
-
- phone_reg = '联系电话:(\d+-?\d+)|联系手机:(\d+)'
- phone = re.findall(phone_reg, html)
- # 处理完后 一定要切换到 主 窗口
- self.browser.switch_to.window(self.master_handler)
- return shop_keeper, phone
-
- def process_item(self, item):
- self.temp = None
- shop_xpath = './/div[@class="shop"]//a'
- local_xpath = './/div[@class="location"]'
- shop = item.find_element_by_xpath(shop_xpath).text
- shop_url = item.find_element_by_xpath(shop_xpath).get_attribute('href')
- local = item.find_element_by_xpath(local_xpath).text
- shop_keeper, phone = self.get_detail_info(shop_url)
- if phone:
- print(f'shop : {shop}')
- print(f'local : {local}')
- print(f'shop_url : {shop_url}')
- print(f'shop_keeper : {shop_keeper}')
- print(f'phone : {phone}')
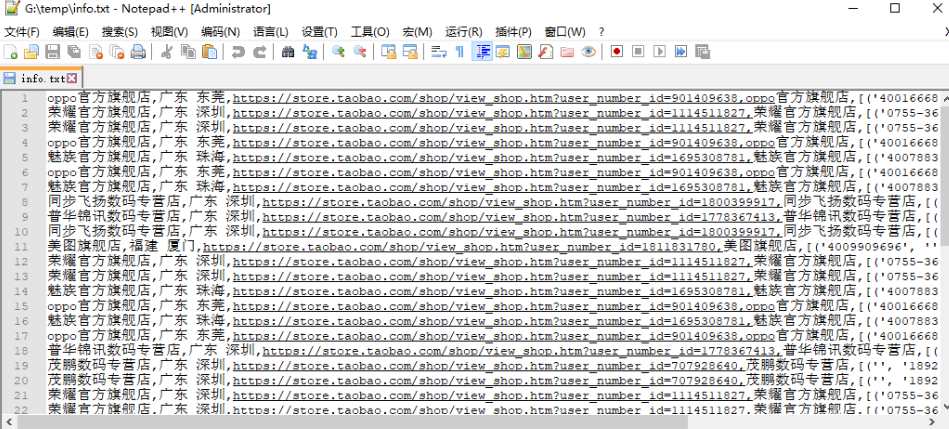
- with open('./info.txt', 'a+') as f:
- f.write(shop + ',')
- f.write(local + ',')
- f.write(shop_url + ',')
- f.write(shop_keeper + ',')
- f.write(f'{phone}')
- f.write('\n')
-
- def main(self):
- # 切回 主 窗口
- self.browser.switch_to.window(self.master_handler)
- key_word = input('输入淘宝搜索关键字:')
- if not key_word:
- print('没有输入关键字。默认搜索 “手机”')
- key_word = '手机'
- url = f'https://s.taobao.com/search?q={key_word}'
- self.browser.get(url)
- shop_and_local_xpath = '//div[contains(@class, "J_MouserOnverReq")]//div[@class="row row-3 g-clearfix"]'
- shop_and_local = self.browser.find_elements_by_xpath(shop_and_local_xpath)
- for item in shop_and_local:
- self.process_item(item)
-
- # 这里是演示,所以只爬了前 5 页
- for page_num in range(2, 6):
- next_page_xpath = '//li[@class="item next"]'
- next_page = self.browser.find_element_by_xpath(next_page_xpath)
- next_page_enable = False if 'disabled' in next_page.get_attribute('class') else True
- if next_page_enable:
- print('*' * 100)
- print(f'第 {page_num} 页')
- next_page.click()
- # self.browser.refresh()
- self.wait.until(EC.presence_of_all_elements_located((By.XPATH, shop_and_local_xpath)))
- time.sleep(random.randint(3, 5))
- shop_and_local = self.browser.find_elements_by_xpath(shop_and_local_xpath)
- for item in shop_and_local:
- self.process_item(item)
- else:
- break
-
-
- if __name__ == '__main__':
- tb = TaoBaoSearch()
- tb.main()
headless 模式
上面是一直有浏览器窗口的,没法使用 无头模式,可以使用 --user-data-dir 参数,然后设置无头模式。如果想改变 Chrome 位置,可以设置 chrome_options.binary_location 为 chrome.exe 路径即可。
- from selenium import webdriver
- from selenium.webdriver.chrome.options import Options
-
- if __name__ == '__main__':
-
- chrome_options = Options()
-
- # 不使用默认的Chrome安装版本时,可以设置binary_location 指定 Chrome 路径 。
- # chrome 和 Chromium 对应 chromedriver.exe 版本不一样
- chrome_options.binary_location = r'D:\chrome\chrome.exe'
- # chrome_options.binary_location = r'D:\Chromium\chrome.exe'
-
- # chrome_options.add_argument('--headless')
- chrome_options.add_argument("--no-sandbox")
- chrome_options.add_argument('disable-infobars')
- chrome_options.add_argument(r'--user-data-dir=D:\chrome\userdatadir')
- # chrome_options.add_argument(r'--user-data-dir=D:\Chromium\userdatadir')
-
- browser = webdriver.Chrome(
- chrome_options=chrome_options,
- executable_path=r'D:\chrome\chromedriver.exe'
- # executable_path=r'D:\Chromium\chromedriver.exe'
- )
-
- browser.get('https://www.taobao.com/')
- user_name_xpath = '//div[@class="site-nav-user"]/a'
- user_name = browser.find_element_by_xpath(user_name_xpath).text
- print(user_name)
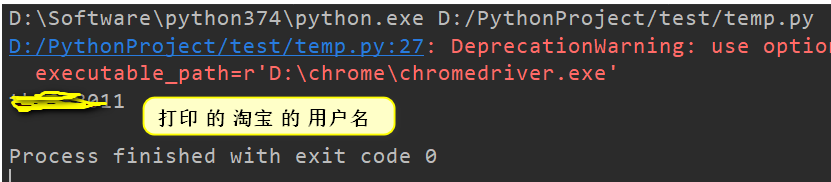
可以看到 无头模式下,使用 --user-data-dir 参数,可以登录淘宝。前提需要先手动登录淘宝,拿到登录信息的文件夹。
ichrome
github 地址:https://github.com/ClericPy/ichrome
这里就不放天猫、淘宝的代码了,贴一个药监局的:
( 流程:药品 ---> 药品查询 ---> 国产药品 ,然后就一直翻页)
- import asyncio
- from lxml import etree
- from ichrome import AsyncChromeDaemon
-
-
- async def main():
- async with AsyncChromeDaemon(headless=0, disable_image=False) as cd:
- async with cd.connect_tab(index=0, auto_close=True) as tab:
- url = 'https://www.nmpa.gov.cn/yaopin/index.html'
- wait_timeout = 5
- await tab.goto(url, timeout=wait_timeout)
- await asyncio.sleep(2)
-
- data_query_css_string = '#layer3 > div > a:nth-child(9)'
- await tab.wait_tag(data_query_css_string, max_wait_time=wait_timeout)
- await tab.click(data_query_css_string, timeout=wait_timeout)
- await asyncio.sleep(2)
-
- yao_query_css_string = '[title="国家局批准的药品批准文号信息"]'
- await tab.wait_tag(yao_query_css_string, max_wait_time=wait_timeout)
- await tab.click(yao_query_css_string, timeout=wait_timeout)
- await asyncio.sleep(2)
-
- while True:
- data_link_css_string = '#content table:nth-child(2) > tbody > tr:nth-child(1) > td > p > a'
- await tab.wait_tag(data_link_css_string, timeout=wait_timeout)
-
- html = await tab.get_html(timeout=wait_timeout)
- s_html = etree.HTML(text=html)
- s_table = s_html.xpath('//div[@id="content"]//table')[2]
- s_tr_list = s_table.xpath('.//tr')
- for s_tr in s_tr_list:
- tag_a = s_tr.xpath('string(.)').strip()
- print(tag_a)
- # tag_a_href = s_tr.xpath('.//a/@href')
- # print(tag_a_href)
-
- btn_next = '[src="images/dataanniu_07.gif"]'
- await tab.click(btn_next, timeout=wait_timeout)
- await asyncio.sleep(2)
-
-
- if __name__ == "__main__":
- asyncio.run(main())
chrome 多开:设置不同的 debug_port 和 user_data_dir 可以达到多开 Chrome
- import json
- import asyncio
- import aiomultiprocess
- from loguru import logger
- from ichrome import AsyncChromeDaemon
- from ichrome.async_utils import Chrome
-
-
- async def startup_chrome(dp_port=None):
- """
- 设置 chrome 参数,然后启动 chrome
- :param dp_port: 自定义 debug port
- :return:
- """
- logger.info(f'dp_port ---> {dp_port}')
- timeout = 5
- # 也可以给 Chrome 添加代理
- proxy = '127.0.0.1:8080'
- udd= f'c:/chrome_user_data_dir_{dp_port}'
- async with AsyncChromeDaemon(port=dp_port, proxy=proxy, user_data_dir=udd) as cd:
- async with cd.connect_tab(index=0) as tab:
- url = 'https://space.bilibili.com/1904149/'
- await tab.set_url(url, timeout=timeout)
- await asyncio.sleep(5)
- cookie = await tab.get_cookies(url, timeout=timeout)
- cookie_string = json.dumps(cookie, ensure_ascii=False)
- logger.info(f'cookie_string ---> {cookie_string}')
-
-
- async def main():
- db_list = [9301 + offset for offset in range(5)]
- async with aiomultiprocess.Pool() as aio_pool:
- await aio_pool.map(startup_chrome, db_list)
- await aio_pool.join()
-
-
- if __name__ == "__main__":
- asyncio.run(main())
- pass
深入浅出 CDP (Chrome DevTools Protocol)
:https://www.cnblogs.com/bigben0123/p/15241062.html
常用的几个领域
- Page
- 简单地理解, 可以把一个 Page 看成一个 Page 类型的 Tab
- 对 Tab 的刷新, 跳转, 停止, 激活, 截图等功能都可以找到
- 也会有很多有用的事件需要 enable Page 以后才能监听到, 比如 loadEventFired
- 多个网站的任务, 可以在同一个浏览器里打开多个 Tab 进行操作, 通过不同的 Websocket 地址进行连接, 相对隔离, 并且托异步模型的福, Chrome 多个标签操作的抗压能力还不错
- 然而并发操作多个 Tab 的时候, 可能会出现一点小问题需要注意: 同一个浏览器实例, 对一个域名只能建立 6 个连接, 这个不太好改; 过快生成大量 Tab, 可能会导致有的 Tab 无法正常关闭(zombie tabs)
- Network
- 和产生网络流量有关系的大都在这个 Domain
- 比如 setExtraHTTPHeaders / setUserAgentOverride 对当前标签页的所有请求修改原是参数
- 比如对 cookie 的各种操作
- 通过 responseReceived + getResponseBody 来监听流量, 只用前者就能嗅探到 mp4 这种特殊类型的 url 了, 而后者可以把流量里已经 base64 化的数据进行其他操作, 比如验证码图片的处理
- 其他功能也基本和 devtools 一致
常规姿势
- 和某个 Tab 建立连接
- 通过 send 发送你想使用的 methods
- 通过 recv 监听你发送 methods 产生的事件, 或者其他 enable 的事件, 并执行对应回调
示例代码
- from ichrome import AsyncChrome
- import asyncio
-
-
- async def async_operate_tab():
- chrome = AsyncChrome(host='127.0.0.1', port=9222)
- if not await chrome.connect():
- raise RuntimeError
- tab = (await chrome.tabs)[0]
- async with tab():
- # 跳转到 httpbin, 3 秒 loading 超时的话则 stop loading
- await tab.set_url('http://httpbin.org', timeout=3)
- # 注入 js, 并查看返回结果
- result = await tab.js("document.title")
- title = result['result']['result']['value']
- # 打印 title
- print(title)
- # httpbin.org
- # 通过 js 修改 title
- await tab.js("document.title = 'New Title'")
- # click 一个 css 选择器的位置, 跳转到了 Github
- await tab.click('body > a:first-child')
- # 等待加载完成
- await tab.wait_loading(3)
-
- async def callback_function(request):
- if request:
- # 监听到经过过滤的流量, 等待它加载一会比较保险
- for _ in range(3):
- result = await tab.get_response(request)
- if result.get('error'):
- await tab.wait_loading(1)
- continue
- # 拿到整个 html
- body = result['result']['body']
- print(body)
-
- def filter_func(r):
- url = r['params']['response']['url']
- print('received:', url)
- return url == 'https://github.com/'
-
- # 监听流量, 需要异步处理, 则使用 asyncio.ensure_future 即可
- # 监听 10 秒
- task = asyncio.ensure_future(
- tab.wait_response(
- filter_function=filter_func,
- callback_function=callback_function,
- timeout=10),
- loop=tab.loop)
- # 点击一下左上角的小章鱼则会触发流量
- await tab.click('[href="https://github.com/"]')
- # 等待监听流量
- await task
-
-
- if __name__ == "__main__":
- asyncio.run(async_operate_tab())
-
undetected_chromedrive
github:https://github.com/search?q=undetected-chromedriver
github 搜索 selenium,看看还有没有其他的
pip install git+https://github.com/ultrafunkamsterdam/undetected-chromedriver.git
反检测 js:https://github.com/berstend/puppeteer-extra/tree/master/packages/extract-stealth-evasions
懂车帝 示例
懂车帝对 selenium 反爬挺厉害,通过undetected_chromedriver可轻松搞定。
- import ssl
- import time
- import undetected_chromedriver as uc
- from selenium.webdriver.remote.webdriver import By
-
- # ssl._create_unverified_context() 函数创建了一个未经验证的 SSL 上下文
- # 禁用 SSL 证书验证
- ssl._create_default_https_context = ssl._create_unverified_context
- uc.TARGET_VERSION = 91
-
-
- def main():
- driver = uc.Chrome()
- driver.get('https://www.dongchedi.com/user/53334173333')
- time.sleep(3)
- driver.find_element(By.XPATH, '//input[contains(@class, "search-form")]').send_keys('法拉利')
- time.sleep(3)
- driver.find_element(By.XPATH, '//button[contains(@class, "tw-w-64")]').click()
- time.sleep(50)
- driver.close()
-
-
- if __name__ == '__main__':
- main()
- pass
github 示例
示例 1:
- import time
- import selenium.webdriver.support.expected_conditions as EC # noqa
- from selenium.common.exceptions import WebDriverException
- from selenium.webdriver.remote.webdriver import By
- from selenium.webdriver.support.wait import WebDriverWait
-
- import undetected_chromedriver as uc
-
-
- def main():
- driver = uc.Chrome()
- driver.get("https://www.google.com")
-
- # accept the terms
- driver.find_elements(By.XPATH, '//*[contains(text(), "Reject all")]')[-1].click()
- inp_search = driver.find_element(By.XPATH, '//input[@title="Search"]')
- inp_search.send_keys("site:stackoverflow.com undetected chromedriver\n")
- results_container = WebDriverWait(driver, timeout=3).until(
- EC.presence_of_element_located((By.ID, "rso"))
- )
-
- driver.execute_script(
- """
- let container = document.querySelector('#rso');
- let el = document.createElement('div');
- el.style = 'width:500px;display:block;background:red;color:white;z-index:999;transition:all 2s ease;padding:1em;font-size:1.5em';
- el.textContent = "Excluded from support...!";
- container.insertAdjacentElement('afterBegin', el);
- setTimeout(() => {
- el.textContent = "<<< OH , CHECK YOUR CONSOLE! >>>"}, 2500)
-
- """
- )
- time.sleep(2)
- for item in results_container.children("a", recursive=True):
- print(item)
-
- # switching default WebElement for uc.WebElement and do it again
- driver._web_element_cls = uc.UCWebElement
-
- print("switched to use uc.WebElement. which is more descriptive")
- results_container = driver.find_element(By.ID, "rso")
-
- # gets only direct children of results_container
- # children is a method unique for undetected chromedriver. it is
- # incompatible when you use regular chromedriver
- for item in results_container.children():
- print(item.tag_name)
- for grandchild in item.children(recursive=True):
- print("\t\t", grandchild.tag_name, "\n\t\t\t", grandchild.text)
-
- print("lets go to image search")
- inp_search = driver.find_element(By.XPATH, '//input[@name="q"]')
- inp_search.clear()
- inp_search.send_keys("hot girls\n") # \n as equivalent of ENTER
-
- body = driver.find_element(By.TAG_NAME, "body")
- body.find_elements(By.XPATH, '//a[contains(text(), "Images")]')[0].click_safe()
-
- # you can't reuse the body from above, because we are on another page right now
- # so the body above is not attached anymore
- image_search_body = WebDriverWait(driver, 5).until(
- EC.presence_of_element_located((By.TAG_NAME, "body"))
- )
-
- # gets all images and prints the src
- print("getting image sources data, hold on...")
-
- for item in image_search_body.children("img", recursive=True):
- print(item.attrs.get("src", item.attrs.get("data-src")), "\n\n")
-
- USELESS_SITES = [
- "https://www.trumpdonald.org",
- "https://www.isitchristmas.com",
- "https://isnickelbacktheworstbandever.tumblr.com",
- "https://www.isthatcherdeadyet.co.uk",
- "https://whitehouse.gov",
- "https://www.nsa.gov",
- "https://kimjongillookingatthings.tumblr.com",
- "https://instantrimshot.com",
- "https://www.nyan.cat",
- "https://twitter.com",
- ]
-
- print("opening 9 additinal windows and control them")
- time.sleep(2) # never use this. this is for demonstration purposes only
- for _ in range(9):
- driver.window_new()
-
- print("now we got 10 windows")
- time.sleep(2)
- print("using the new windows to open 9 other useless sites")
- time.sleep(2) # never use this. this is for demonstration purposes only
-
- for idx in range(1, 10):
- # skip the first handle which is our original window
- print("opening ", USELESS_SITES[idx])
- driver.switch_to.window(driver.window_handles[idx])
-
- # because of geographical location, (corporate) firewalls and 1001
- # other reasons why a connection could be dropped we will use a try/except clause here.
- try:
- driver.get(USELESS_SITES[idx])
- except WebDriverException as e:
- print(
- (
- "webdriver exception. this is not an issue in chromedriver, but rather "
- "an issue specific to your current connection. message:",
- e.args,
- )
- )
- continue
-
- for handle in driver.window_handles[1:]:
- driver.switch_to.window(handle)
- print("look. %s is working" % driver.current_url)
- time.sleep(2) # never use this. it is here only so you can follow along
-
- print(
- "close windows (including the initial one!), but keep the last new opened window"
- )
- time.sleep(4) # never use this. wait until nowsecure passed the bot checks
-
- for handle in driver.window_handles[:-1]:
- driver.switch_to.window(handle)
- print("look. %s is closing" % driver.current_url)
- time.sleep(1)
- driver.close()
-
- # attach to the last open window
- driver.switch_to.window(driver.window_handles[0])
- print("now we only got ", driver.current_url, "left")
-
- time.sleep(1)
-
- driver.get("https://www.nowsecure.nl")
-
- time.sleep(5)
-
- print("lets go to UC project page")
- driver.get("https://www.github.com/ultrafunkamsterdam/undetected-chromedriver")
-
- time.sleep(2)
- driver.quit()
-
-
- if __name__ == "__main__":
- main()
- pass
示例 2:
- import os
- import time
- from selenium.webdriver.support.wait import WebDriverWait
- import selenium.webdriver.support.expected_conditions as EC
- from selenium.common.exceptions import TimeoutException
- import undetected_chromedriver as uc
- from loguru import logger
-
-
- def main():
- driver = uc.Chrome(
- headless=False,
- browser_executable_path=r'C:\Program Files\Google\Chrome\Application\Chrome.exe'
- )
- driver.get('chrome://version')
- driver.save_screenshot('/home/runner/work/_temp/versioninfo.png')
- driver.get('chrome://settings/help')
- driver.save_screenshot('/home/runner/work/_temp/helpinfo.png')
- driver.get('https://www.google.com')
- driver.save_screenshot('/home/runner/work/_temp/google.com.png')
- driver.get('https://bot.incolumitas.com/#botChallenge')
- pdfdata = driver.execute_cdp_cmd('Page.printToPDF', {})
- if pdfdata:
- if 'data' in pdfdata:
- data = pdfdata['data']
- import base64
- buffer = base64.b64decode(data)
- with open('/home/runner/work/_temp/report.pdf', 'w+b') as f:
- f.write(buffer)
- driver.get('https://www.nowsecure.nl')
- logger.info('current url %s' % driver.current_url)
- try:
- WebDriverWait(driver, 15).until(EC.title_contains('moment'))
- except TimeoutException:
- pass
- logger.info('current page source:\n%s' % driver.page_source)
- logger.info('current url %s' % driver.current_url)
- try:
- WebDriverWait(driver, 15).until(EC.title_contains('nowSecure'))
- logger.info('PASSED CLOUDFLARE!')
- except TimeoutException:
- logger.info('timeout')
- print(driver.current_url)
- logger.info('current page source:\n%s\n' % driver.page_source)
- driver.save_screenshot('/home/runner/work/_temp/nowsecure.png')
- # driver.get('https://imgur.com/upload')
- # driver.find_element('css selector', 'input').send_keys('/home/runner/work/_temp/nowsecure.png')
- # logger.info('current url %s' % driver.current_url)
- # time.sleep(5)
- driver.quit()
-
-
- if __name__ == "__main__":
- main()
小红书 示例
- import re
- import json
- import time
- import requests
- from jsonpath import jsonpath
- from concurrent.futures import ThreadPoolExecutor
- import undetected_chromedriver as uc
-
-
- def main_1():
- def handle_response(event):
- try:
- req_url = event['params']['response']['url']
- if 'xiaohongshu.com/api/sns/web/v1/search/notes' in req_url:
- print(req_url)
- request_id = event['params']['requestId']
- data_dict = browser.execute_cdp_cmd('Network.getResponseBody', {'requestId': request_id})
- resp_string = data_dict['body']
- resp_dict = json.loads(resp_string)
- # print(f'resp_dict ---> {resp_dict}')
- # https://www.xiaohongshu.com/explore/633296f2000000001703f491
- item_list = resp_dict['data']['items']
- with open('./note_id_list.txt', 'a', encoding='utf-8') as f:
- for temp in item_list:
- if 24 == len(temp["id"]):
- f.write(f'{temp["id"]}\n')
- pass
- except BaseException as be:
- print(be)
- pass
-
- browser = uc.Chrome(
- headless=False,
- use_subprocess=False,
- user_data_dir='./user_data_dir',
- enable_cdp_events=True
- )
- browser.add_cdp_listener(
- # event_name='Network.dataReceived', # 数据块接收完成后触发事件
- event_name='Network.responseReceived', # response 接收完成后触发事件
- callback=handle_response # 触发事件后, 处理事件的函数
- )
-
- kw_list = ['美女']
- for index in range(len(kw_list)):
- kw = kw_list[index]
- url = f'https://www.xiaohongshu.com/search_result?keyword={kw}&source=web_explore_feed'
- browser.get(url)
- while True:
- # js_code = "() => window.scrollTo(0,document.body.scrollHeight)"
- js_code = "window.scrollTo(0, document.body.scrollHeight);"
- browser.execute_script(js_code)
- time.sleep(1)
- pass
-
- browser.close()
- browser.quit()
-
-
- def main_2():
- def handle_response(event):
- try:
- req_url = event['params']['response']['url']
- if 'www.xiaohongshu.com/explore' in req_url:
- print(req_url)
- request_id = event['params']['requestId']
- data_dict = browser.execute_cdp_cmd('Network.getResponseBody', {'requestId': request_id})
- resp_string = data_dict['body']
- extract_string = re.findall(r'__INITIAL_STATE__=([\s\S]*?)</script>', resp_string)[0]
- temp = re.sub(':undefined', ':null', extract_string)
- extract_dict = json.loads(temp)
- query_list = jsonpath(extract_dict, '$..imageList')
- if query_list and len(query_list):
- image_list = query_list[0]
- with open('./image_list.txt', 'a', encoding='utf-8') as f:
- for temp in image_list:
- f.write(f'{temp["url"]}\n')
- pass
- except BaseException as be:
- print(be)
- pass
-
- browser = uc.Chrome(
- headless=False,
- use_subprocess=False,
- user_data_dir='./user_data_dir',
- enable_cdp_events=True
- )
- browser.add_cdp_listener(
- # event_name='Network.dataReceived', # 数据块接收完成后触发事件
- event_name='Network.responseReceived', # response 接收完成后触发事件
- callback=handle_response # 触发事件后, 处理事件的函数
- )
-
- line_list = []
- with open('./note_id_list.txt', encoding='utf-8') as f1:
- line_list = f1.readlines()
- note_id_list = [x.strip() for x in line_list]
- note_count = len(note_id_list)
-
- for index in range(note_count):
- note_id = note_id_list[index]
- url = f'https://www.xiaohongshu.com/explore/{note_id}'
- browser.get(url)
- time.sleep(2)
- pass
- browser.close()
- browser.quit()
-
-
- def download_img():
- line_list = []
- with open('./image_list.txt', encoding='utf-8') as f1:
- line_list = f1.readlines()
- img_url_list = [x.strip() for x in line_list]
- img_url_count = len(img_url_list)
- for index in range(img_url_count):
- if index <= 474:
- continue
- img_url = img_url_list[index]
- img_id = img_url.split('com/')[-1]
- resp = requests.get(img_url)
- if 200 == resp.status_code:
- print(f'[{index}][{img_url_count}] success ---> {img_url}')
- with open(f'./img_list/{img_id}.jpg', 'wb') as f:
- f.write(resp.content)
- else:
- print(f'[{index}][{img_url_count}] fail ---> {img_url}')
-
-
- if __name__ == '__main__':
- # main_1()
- # main_2()
- download_img()
- pass
面向对象 示例:
- import json
- import time
- import datetime
- from loguru import logger
- from selenium import webdriver
- import undetected_chromedriver as uc
- import concurrent
- from concurrent.futures import ThreadPoolExecutor
-
-
- class BrowserSpider(object):
-
- def __init__(self, *args, **kwargs):
- self.temp = None
- self.browser = self.__generate_webdriver(enable_cdp_events=True)
- self.browser.add_cdp_listener(
- event_name='Network.responseReceived', # 监听的事件
- callback=self.handle_response # 当监听到事件发生时,调用函数进行处理
- )
- pass
-
- def __del__(self):
- try:
- self.browser.close()
- self.browser.quit()
- except BaseException as be:
- pass
-
- def __generate_webdriver(self, headless=False, proxies=False, enable_cdp_events=False):
- self.temp = None
- chrome_options = webdriver.ChromeOptions() # Create driver options object
- # chrome_options.add_argument('-incognito') # 隐身模式
- # chrome_options.add_argument("--disable-geolocation") # 禁用自动地理定位
- chrome_options.add_argument("--disable-extensions") # 禁用其他扩展
- chrome_options.add_argument("--lang=en-US") # 更改Chrome语言
- if headless:
- chrome_options.add_argument("--headless")
- if proxies:
- proxy = proxies['https']
- chrome_options.add_argument(f'--proxy-server={proxy}--timeout=120')
- browser = uc.Chrome(
- options=chrome_options,
- enable_cdp_events=enable_cdp_events,
- use_subprocess=False
- )
- return browser
-
- def handle_response(self, event):
- try:
- # print(f'event ---> {event}')
- request_id = event['params']['requestId']
- cdp_data_dict = self.browser.execute_cdp_cmd('Network.getResponseBody', {'requestId': request_id})
- resp_body = json.loads(cdp_data_dict['body'])
- logger.info(f'resp_body ---> {resp_body}')
- except BaseException as be:
- # logger.error(be)
- pass
-
- def crawl_data_1(self):
- kw_list = ['藏族']
- for kw in kw_list:
- url = f'https://www.xiaohongshu.com/search_result?keyword={kw}&source=web_explore_feed'
- self.browser.get(url)
- js_code = "window.scrollTo(0, document.body.scrollHeight);"
- start_time = datetime.datetime.now()
- while True:
- self.browser.execute_script(js_code)
- end_time = datetime.datetime.now()
- if (end_time - start_time).seconds > 10:
- break
- pass
-
- def crawl_data_2(self, url=None):
- logger.info(f'url ---> {url}')
- self.browser.get(url)
- time.sleep(10)
- pass
-
-
- def main():
- bs = BrowserSpider()
- bs.crawl_data_1()
-
-
- if __name__ == '__main__':
- main()
- pass
5、Playwright
要使用 Playwright,需要 Python 3.7 版本及以上,请确保 Python 的版本符合要求。
要安装 Playwright,可以直接使用 pip3,命令:pip3 install playwright
安装完成之后需要进行一些初始化操作(相关浏览器驱动):playwright install
这时候 Playwrigth 会安装 Chromium, Firefox and WebKit 浏览器并配置一些驱动,我们不必关心中间配置的过程,Playwright 会为我们配置好。
具体的安装说明可以参考:https://setup.scrape.center/playwright
安装完成之后,我们便可以使用 Playwright 启动 Chromium 或 Firefox 或 WebKit 浏览器来进行自动化操作了
5.1 示例:同步、异步
基于 playwright 和 pytest 单元测试框架的自动化项目
:https://github.com/defnngj/playwright-pro
使用框架图
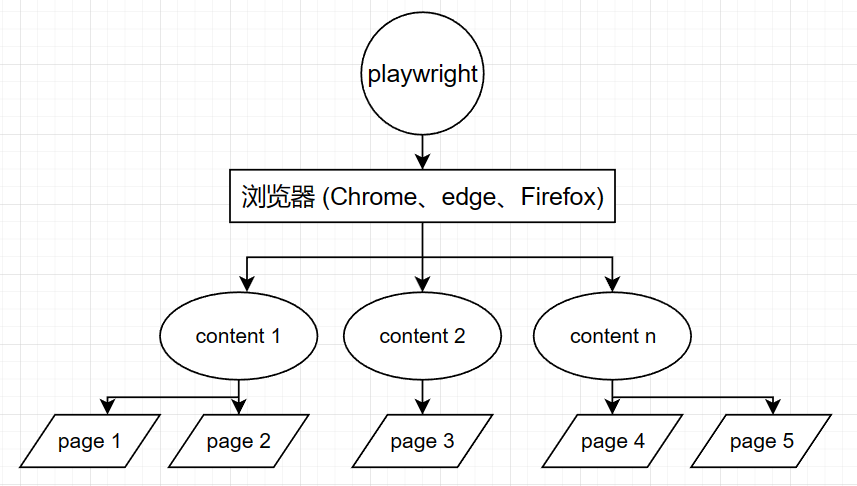
同步 代码
- from playwright.sync_api import sync_playwright
-
- def run(playwright):
- firefox = playwright.firefox
- browser = firefox.launch()
- page = browser.new_page()
- page.goto("https://example.com")
- browser.close()
-
- with sync_playwright() as playwright:
- run(playwright)
playwright 支持创建多个Browser contexts,相当于是打开浏览器后,可以创建多个页面上下文,每个上下文做的操作可以不同
- from playwright.sync_api import sync_playwright
-
- # 打开两个浏览器上下文
- with sync_playwright() as p:
- browser = p.chromium.launch(headless=False, slow_mo=100) # 打开浏览器
- context1 = browser.new_context() # 创建浏览器上下文,支持创建多个上下文
- page1 = context1.new_page() # 新打开一个浏览器标签页
- page1.goto("https://www.baidu.com")
- context2 = browser.new_context() # 创建浏览器上下文,支持创建多个上下文
- page2 = context2.new_page() # 新打开一个浏览器标签页
- page2.goto("https://www.bilibili.com")
- browser.close()
运行效果如图。打开两个浏览器实例,
一个浏览器上下文就相当于一个 浏览器 实例,浏览器和上下文都可以使用 new_page() 方法打开一个新的浏览器标签页(选项卡)
- browser = p.chromium.launch(headless=False)
- page = browser.new_page()
当我们通过点击某些按钮/超链接打开一个新的浏览器标签页时,还需要继续在这个浏览器标签页上继续操作时,那么可以使用以下方式
- from playwright.sync_api import sync_playwright
-
- with sync_playwright() as p:
- browser = p.chromium.launch(headless=False, slow_mo=100) # 打开浏览器
- context1 = browser.new_context() # 创建浏览器上下文,支持创建多个上下文
- page1 = context1.new_page()
- page1.goto("https://www.baidu.com")
- with context1.expect_page() as new_page_info:
- page1.click('//a[contains(@href, "https://www.hao123.com")]') # 在百度首页点击hao123后会打开一个新的选项卡
- new_page = new_page_info.value
- new_page.click('//a[contains(text(), "hao123推荐")]') # 在hao123点击hao123推荐
- pass
参考:https://playwright.dev/python/docs/multi-pages
异步 代码
- import asyncio
- from playwright.async_api import async_playwright
-
- async def run(playwright):
- firefox = playwright.firefox
- browser = await firefox.launch()
- page = await browser.new_page()
- await page.goto("https://example.com")
- await browser.close()
-
- async def main():
- async with async_playwright() as playwright:
- await run(playwright)
- asyncio.run(main())
5.2 Playwright 官网文档
github 搜索:https://github.com/search?q=Playwright
Playwright
scrapy-playwright
scrapy-playwright:https://github.com/scrapy-plugins/scrapy-playwright
playwright-python
官网文档 ( docs、API ):https://playwright.dev/python/docs/intro
特点
- 支持所有浏览器。Playwright 可以在所有浏览器中实现快速、可靠和强大的自动化测
- 快速可靠的执行
- 强大的自动化功能
- 与你的工作流集成
5.3 为什么选择 Playwright
为什么选择 Playwright:https://www.cnblogs.com/fnng/p/14274960.html
支持所有浏览器
const { chromium, webkit, firefox } = require('playwright');
(async () => {
const browser = await chromium.launch();
// const browser = await webkit.launch();
// const browser = await firefox.launch();const page = await browser.newPage();
await page.goto('http://www.baidu.com/');
await page.screenshot({ path: `example.png` });
await browser.close();
})();
测试移动端:通过设置驱动模式可以模拟移动浏览器的效果。
const { webkit, devices } = require('playwright');
const iPhone11 = devices['iPhone 11 Pro'];(async () => {
const browser = await webkit.launch();
const context = await browser.newContext({
...iPhone11,
locale: 'en-US',
geolocation: { longitude: 12.492507, latitude: 41.889938 },
permissions: ['geolocation']
});
const page = await context.newPage();
await page.goto('https://m.baidu.com');
await page.screenshot({ path: 'colosseum-iphone.png' });
await browser.close();
})();
Headless 和 headful: Playwright支持所有平台和浏览器上使用Headless模式和Headful模式。Headful非常适合调试。Headless运行更快,也可以更方便的在CI/云平台上运行。
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({headless: false});
// ...
})();
headless 默认开启,设置为false,即为 headful模式,可以看到自动化的过程。
快速可靠的执行
- 自动等待: Playwright 可以自动等待元素,这将会提高自动化的稳定性,简化测试的编写。
- 浏览器上下文并行:对具有浏览器上下文的多个并行、隔离的执行环境,重用单个浏览器实例。
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({headless: false, slowMo: 50 });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('http://www.testpub.cn/login');
await page.fill("#inputUsername", 'admin');
await page.fill("#inputPassword", 'admin123456');
await page.click('"Sign in"');
await page.close();const page2 = await context.newPage();
await page2.goto("http://www.testpub.cn/guest_manage/")
await browser.close();
})();
非常方便的 选择元素:Palywright可以依赖面向用户的字符串,如文本内容和可访问性标签来选择元素。这些字符串比与DOM结构紧密耦合的选择器更有弹性。
<button class="btn btn-lg btn-primary btn-block" type="submit">Sign in</button>
例如上面的元素一看就不太好定位,用户到的是一个按钮,名字叫Sign in,那么可以用这个定位方式:await page.click('"Sign in"');
强大的自动化能力
- 支持多个域、页面和表单: Palywright是一个 进程外(out-of-process) 自动化驱动程序,它不受页内JavaScript执行范围的限制,可以自动处理多个页面的场景。
// Create two pages
const pageOne = await context.newPage();
const pageTwo = await context.newPage();// Get pages of a brower context
const allPages = context.pages();
- 强大的网络控制: Palywright引入上下文范围的网络拦截存根和模拟网络请求。
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({headless: false, slowMo: 50 });
const context = await browser.newContext({ acceptDownloads: true });
const page = await context.newPage();
await page.goto('https://pypi.org/project/selenium/#files');
const [ download ] = await Promise.all([
page.waitForEvent('download'),
page.click('#files > table > tbody > tr:nth-child(2) > th > a')
]);
const path = await download.path();
console.log("path", path);
await browser.close();
})();
在 HTTP 认证,文件下载、网络请求响应方面都有很强的控制能力。
- 覆盖所有场景的功能:支持文件下载、上传,进程外表单,输入、点击,甚至是手机上流行的暗黑模式。
// Create context with dark mode
const context = await browser.newContext({
colorScheme: 'dark' // or 'light'
});
- 行命令安装:运行
npm i playwright自动下载浏览器依赖,让你的团队快速上手。 - 支持TypeScript:Playwright 附带内置的自动完成类型和其他收益。
- 调试工具:通过 VS Code 完成自动化的调试。
- 语言绑定:Playwright 支持多种编程语言,这个前面的文章有介绍。
- 在CI上部署测试:你要可以使用Docker镜像,Playwright默认也是headless模式,你可以在任何环境上执行。
5.4 爬虫利器 Playwright 的基本用法
爬虫利器 Playwright 的基本用法:https://cuiqingcai.com/36045.html
playwright 教程:https://blog.csdn.net/m0_51156601/article/details/126886040
Playwright 网络爬虫中文教程:https://sql.wang/playwright/scrool-page/
playwright最详细使用教程:https://blog.csdn.net/m0_51156601/article/details/126886040
Playwright 支持两种编写模式,一种是类似 Pyppetter 一样的异步模式,另一种是像 Selenium 的同步模式,我们可以根据实际需要选择使用不同的模式。
同步 示例:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
page.screenshot(path=f'screenshot-{browser_type.name}.png')
print(page.title())
browser.close()
launch 方法返回的是一个 Browser 对象,我们将其赋值为 browser 变量。然后调用 browser 的 new_page 方法,相当于新建了一个选项卡,返回的是一个 Page 对象,将其赋值为 page,这整个过程其实和 Pyppeteer 非常类似。接着我们就可以调用 page 的一系列 API 来进行各种自动化操作了,比如调用 goto,就是加载某个页面,这里我们访问的是百度的首页。接着我们调用了 page 的 screenshot 方法,参数传一个文件名称,这样截图就会自动保存为该图片名称,这里名称中我们加入了 browser_type 的 name 属性,代表浏览器的类型,结果分别就是 chromium, firefox, webkit。另外我们还调用了 title 方法,该方法会返回页面的标题,即 HTML 中 title 节点中的文字,也就是选项卡上的文字,我们将该结果打印输出到控制台。最后操作完毕,调用 browser 的 close 方法关闭整个浏览器,运行结束。
运行一下,这时候我们可以看到有三个浏览器依次启动并加载了百度这个页面,分别是 Chromium、Firefox 和 Webkit 三个浏览器,页面加载完成之后,生成截图、控制台打印结果就退出了。
异步 示例:
import asyncio
from playwright.async_api import async_playwrightasync def main():
async with async_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = await browser_type.launch()
page = await browser.new_page()
await page.goto('https://www.baidu.com')
await page.screenshot(path=f'screenshot-{browser_type.name}.png')
print(await page.title())
await browser.close()asyncio.run(main())
写法和同步模式基本类似,导入的时候使用的是 async_playwright 方法,而不再是 sync_playwright 方法。写法上添加了 async/await 关键字的使用,最后的运行效果是一样的。
另外我们注意到,这例子中使用了 with as 语句,with 用于上下文对象的管理,它可以返回一个上下文管理器,也就对应一个 PlaywrightContextManager 对象,无论运行期间是否抛出异常,它能够帮助我们自动分配并且释放 Playwright 的资源。
代码生成 ( 录制操作 )
Playwright 还有一个强大的功能,那就是可以录制我们在浏览器中的操作并将代码自动生成出来,有了这个功能,我们甚至都不用写任何一行代码,这个功能可以通过 playwright 命令行调用 codegen 来实现,我们先来看看 codegen 命令都有什么参数,输入如下命令:playwright codegen --help
Usage: npx playwright codegen [options] [url]
open page and generate code for user actions
Options:
-o, --output <file name> saves the generated script to a file
--target <language> language to use, one of javascript, python, python-async, csharp (default: "python")
-b, --browser <browserType> browser to use, one of cr, chromium, ff, firefox, wk, webkit (default: "chromium")
--channel <channel> Chromium distribution channel, "chrome", "chrome-beta", "msedge-dev", etc
--color-scheme <scheme> emulate preferred color scheme, "light" or "dark"
--device <deviceName> emulate device, for example "iPhone 11"
--geolocation <coordinates> specify geolocation coordinates, for example "37.819722,-122.478611"
--load-storage <filename> load context storage state from the file, previously saved with --save-storage
--lang <language> specify language / locale, for example "en-GB"
--proxy-server <proxy> specify proxy server, for example "http://myproxy:3128" or "socks5://myproxy:8080"
--save-storage <filename> save context storage state at the end, for later use with --load-storage
--timezone <time zone> time zone to emulate, for example "Europe/Rome"
--timeout <timeout> timeout for Playwright actions in milliseconds (default: "10000")
--user-agent <ua string> specify user agent string
--viewport-size <size> specify browser viewport size in pixels, for example "1280, 720"
-h, --help display help for commandExamples:
$ codegen
$ codegen --target=python
$ codegen -b webkit https://example.com
这里有几个选项,比如 -o 代表输出的代码文件的名称;—target 代表使用的语言,默认是 python,即会生成同步模式的操作代码,如果传入 python-async 就会生成异步模式的代码;-b 代表的是使用的浏览器,默认是 Chromium,其他还有很多设置,比如 —device 可以模拟使用手机浏览器,比如 iPhone 11,—lang 代表设置浏览器的语言,—timeout 可以设置页面加载超时时间。
示例:playwright codegen -o script.py -b firefox
这时候就弹出了一个 Firefox 浏览器,同时右侧会输出一个脚本窗口,实时显示当前操作对应的代码。可以在浏览器中做任何操作,比如打开百度,然后点击输入框并输入 mm,然后再点击搜索按钮。
在操作过程中,该窗口中的代码就实时变化,可以看到这里生成了我们一系列操作的对应代码,比如在搜索框中输入 nba,就对应如下代码:page.fill("input[name=\"wd\"]", "nba")
操作完毕之后,关闭浏览器,Playwright 会生成一个 script.py 文件。
所以,有了这个功能,我们甚至都不用编写任何代码
context 变量对应的是一个 BrowserContext 对象,BrowserContext 是一个类似隐身模式的独立上下文环境,其运行资源是单独隔离的,在做一些自动化测试过程中,每个测试用例我们都可以单独创建一个 BrowserContext 对象,这样可以保证每个测试用例之间互不干扰,具体的 API 可以参考 https://playwright.dev/python/docs/api/class-browsercontext。
移动端浏览器支持
Playwright 另外一个特色功能就是可以支持移动端浏览器的模拟,比如模拟打开 iPhone 12 Pro Max 上的 Safari 浏览器,然后手动设置定位,并打开百度地图并截图。首先我们可以选定一个经纬度,比如故宫的经纬度是 39.913904, 116.39014,我们可以通过 geolocation 参数传递给 Webkit 浏览器并初始化。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
iphone_12_pro_max = p.devices['iPhone 12 Pro Max']
browser = p.webkit.launch(headless=False)
context = browser.new_context(
**iphone_12_pro_max,
locale='zh-CN',
geolocation={'longitude': 116.39014, 'latitude': 39.913904},
permissions=['geolocation']
)
page = context.new_page()
page.goto('https://amap.com')
page.wait_for_load_state(state='networkidle')
page.screenshot(path='location-iphone.png')
browser.close()
先用 PlaywrightContextManager 对象的 devices 属性指定了一台移动设备,这里传入的是手机的型号,比如 iPhone 12 Pro Max,当然也可以传其他名称,比如 iPhone 8,Pixel 2 等。
现在用 BrowserContext 对象来新建一个页面,还是调用 new_page 方法创建一个新的选项卡,然后跳转到高德地图,并调用了 wait_for_load_state 方法等待页面某个状态完成,这里我们传入的 state 是 networkidle,也就是网络空闲状态。因为在页面初始化和加载过程中,肯定是伴随有网络请求的,所以加载过程中肯定不算 networkidle 状态,所以这里我们传入 networkidle 就可以标识当前页面和数据加载完成的状态。加载完成之后,我们再调用 screenshot 方法获取当前页面截图,最后关闭浏览器。
运行下代码,可以发现这里就弹出了一个移动版浏览器,然后加载了高德地图
选择器 ( 文本、CSS、XPath、节点 )
前面用到了 click 和 fill 等方法都传入了一个字符串,这些字符串有的符合 CSS 选择器的语法,有的又是 text= 开头的,感觉似乎没太有规律的样子,它到底支持怎样的匹配规则呢?下面我们来了解下。
传入的这个字符串,我们可以称之为 Element Selector,它不仅仅支持 CSS 选择器、XPath,Playwright 还扩展了一些方便好用的规则,比如直接根据文本内容筛选,根据节点层级结构筛选等等。
文本选择
文本选择支持直接使用
text=这样的语法进行筛选,示例:page.click("text=Log in")这就代表选择文本是 Log in 的节点,并点击。
CSS 选择器
CSS 选择器之前也介绍过了,比如根据 id 或者 class 筛选:
page.click("button")
page.click("#nav-bar .contact-us-item")根据特定的节点属性筛选:
page.click("[data-test=login-button]")
page.click("[aria-label='Sign in']")
CSS 选择器 + 文本
还可以使用 CSS 选择器结合文本值进行海选,比较常用的就是 has-text 和 text,前者代表包含指定的字符串,后者代表字符串完全匹配,示例如下:
page.click("article:has-text('Playwright')")
page.click("#nav-bar :text('Contact us')")第一个就是选择文本中包含 Playwright 的 article 节点,第二个就是选择 id 为 nav-bar 节点中文本值等于 Contact us 的节点。
CSS 选择器 + 节点关系
还可以结合节点关系来筛选节点,比如使用 has 来指定另外一个选择器,示例如下:
page.click(".item-description:has(.item-promo-banner)")
比如这里选择的就是选择 class 为 item-description 的节点,且该节点还要包含 class 为 item-promo-banner 的子节点。
另外还有一些相对位置关系,比如 right-of 可以指定位于某个节点右侧的节点,
示例:page.click("input:right-of(:text('Username'))")这里选择的就是一个 input 节点,并且该 input 节点要位于文本值为 Username 的节点的右侧。
XPath
当然 XPath 也是支持的,不过 xpath 这个关键字需要我们自行制定,
示例:page.click("xpath=//button")
需要在开头指定
xpath=字符串,代表后面是一个 XPath 表达式。关于更多选择器的用法和最佳实践,可以参考官方文档:https://playwright.dev/python/docs/locators
用户数据目录
launch_persistent_context:https://playwright.dev/python/docs/api/class-browsertype
- import asyncio
- from playwright.async_api import async_playwright
-
- # import sys
- # sys.path.append('D:\\Project\\my_spiders')
- # print(sys.path)
-
- from my_spiders.tools.mongodb_operate import MongoDB
-
- continue_next = False
- mongo_url = 'mongodb://admin:admin@172.16.30.180:27017'
- mongo_db = MongoDB(url=mongo_url, db='admin')
-
- comment_max = 0
-
-
- def handle_req(req):
- # mth = req.method
- # url = req.url
- # print(mth)
- pass
-
-
- async def handle_resp(resp):
- status = resp.status
- url = resp.url
- if 'buildComments' in url:
- try:
- # resp_body = await resp.body()
- # print(f'{url} ---> {resp_body.decode("utf-8")}')
- resp_json = await resp.json()
- # print(f'{url} ---> {resp_json}')
- except BaseException as be:
- return
- comment_list = resp_json.get('data', [])
- global comment_max
- if len(comment_list):
- # mongo_db.add_batch('weibo_comment_test', comment_list)
- comment_max += len(comment_list)
- print(f'comment count ---> {len(comment_list)}')
- if 0 == resp_json.get('max_id', -1):
- print(f'comment_max ---> {comment_max}')
- comment_max = 0
- pass
-
-
- async def setup_browser(playwright):
- chromium = playwright.chromium
- # browser = await chromium.launch(headless=False, slow_mo=100)
- browser = await chromium.launch_persistent_context(
- headless=False, slow_mo=100,
- user_data_dir='./user_dir'
- )
- page = await browser.new_page()
- # Subscribe to "request" and "response" events.
- page.on("request", handle_req)
- page.on("response", handle_resp)
- # await page.goto("https://m.weibo.cn/detail/4573642094806773")
- await page.goto("https://weibo.com/7418063007/JuTLzkasB#comment")
- while True:
- await page.evaluate("() => window.scrollTo(0,document.body.scrollHeight)")
- await asyncio.sleep(5)
- # await browser.close()
-
-
- async def main():
- async with async_playwright() as playwright:
- await setup_browser(playwright)
-
-
- if __name__ == '__main__':
- asyncio.run(main())
- pass
常用操作方法 ( click,输入fill )
常见的一些 API 如点击 click,输入 fill 等操作,这些方法都是属于 Page 对象的,所以所有的方法都从 Page 对象的 API 文档查找就好了,文档地址:https://playwright.dev/python/docs/api/class-page。
事件监听 ( 拦截 )
Page 对象提供了一个 on 方法,它可以用来监听页面中发生的各个事件,比如 close、console、load、request、response 等等。
示例:监听 response 事件,response 事件可以在每次网络请求得到响应的时候触发,我们可以设置对应的回调方法获取到对应 Response 的全部信息,示例如下:
from playwright.sync_api import sync_playwright
def on_response(response):
print(f'Statue {response.status}: {response.url}')with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
这里我们在创建 Page 对象之后,就开始监听 response 事件,同时将回调方法设置为 on_response,on_response 对象接收一个参数,然后把 Response 的状态码和链接都输出出来了。输出结果其实正好对应浏览器 Network 面板中所有的请求和响应内容
如果数据都是 Ajax 加载的,同时 Ajax 请求中还带有加密参数,不好轻易获取。有了这个方法,这里如果我们想要截获 Ajax 请求,岂不是就非常容易了?
改写一下判定条件,输出对应的 JSON 结果,改写如下:
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie/' in response.url and response.status == 200:
print(response.json())with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
获取页面源码
要获取页面的 HTML 代码其实很简单,我们直接通过 content 方法获取即可,用法如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
html = page.content()
print(html)
browser.close()
页面点击
页面点击的 API 定义如下:page.click(selector, **kwargs)
这里可以看到必传的参数是 selector,其他的参数都是可选的。第一个 selector 就代表选择器,可以用来匹配想要点击的节点,如果传入的选择器匹配了多个节点,那么只会用第一个节点。
这个方法的内部执行逻辑如下:
- 根据 selector 找到匹配的节点,如果没有找到,那就一直等待直到超时,超时时间可以由额外的 timeout 参数设置,默认是 30 秒。
- 等待对该节点的可操作性检查的结果,比如说如果某个按钮设置了不可点击,那它会等待该按钮变成了可点击的时候才去点击,除非通过 force 参数设置跳过可操作性检查步骤强制点击。
- 如果需要的话,就滚动下页面,将需要被点击的节点呈现出来。
- 调用 page 对象的 mouse 方法,点击节点中心的位置,如果指定了 position 参数,那就点击指定的位置。
click 方法的一些比较重要的参数如下:
- click_count:点击次数,默认为 1。
- timeout:等待要点击的节点的超时时间,默认是 30 秒。
- position:需要传入一个字典,带有 x 和 y 属性,代表点击位置相对节点左上角的偏移位置。
- force:即使不可点击,那也强制点击。默认是 False。
具体的 API 设置参数可以参考官方文档:https://playwright.dev/python/docs/api/class-page#page-click
文本输入
文本输入对应的方法是 fill,API 定义如下:page.fill(selector, value, **kwargs)
这个方法有两个必传参数,第一个参数也是 selector,第二个参数是 value,代表输入的内容,另外还可以通过 timeout 参数指定对应节点的最长等待时间。
获取节点属性
除了对节点进行操作,我们还可以获取节点的属性,方法就是 get_attribute,API 定义如下:
page.get_attribute(selector, name, **kwargs)
这个方法有两个必传参数,第一个参数也是 selector,第二个参数是 name,代表要获取的属性名称,另外还可以通过 timeout 参数指定对应节点的最长等待时间。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
href = page.get_attribute('a.name', 'href')
print(href)
browser.close()
这里我们调用了 get_attribute 方法,传入的 selector 是 a.name,选定了 class 为 name 的 a 节点,然后第二个参数传入了 href,获取超链接的内容,
可以看到对应 href 属性就获取出来了,但这里只有一条结果,因为这里有个条件,那就是如果传入的选择器匹配了多个节点,那么只会用第一个节点。
那怎么获取所有的节点呢?
获取多个节点
获取所有节点可以使用 query_selector_all 方法,它可以返回节点列表,通过遍历获取到单个节点之后,我们可以接着调用单个节点的方法来进行一些操作和属性获取,示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
elements = page.query_selector_all('a.name')
for element in elements:
print(element.get_attribute('href'))
print(element.text_content())
browser.close()
这里我们通过 query_selector_all 方法获取了所有匹配到的节点,每个节点对应的是一个 ElementHandle 对象,然后 ElementHandle 对象也有 get_attribute 方法来获取节点属性,另外还可以通过 text_content 方法获取节点文本。
获取单个节点
获取单个节点也有特定的方法,就是 query_selector,如果传入的选择器匹配到多个节点,那它只会返回第一个节点,示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
element = page.query_selector('a.name')
print(element.get_attribute('href'))
print(element.text_content())
browser.close()
网络劫持
最后再介绍一个实用的方法 route,利用 route 方法,我们可以实现一些网络劫持和修改操作,比如修改 request 的属性,修改 response 响应结果等。
from playwright.sync_api import sync_playwright
import rewith sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()def cancel_request(route, request):
route.abort()page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
page.goto("https://spa6.scrape.center/")
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
browser.close()
这里我们调用了 route 方法,第一个参数通过正则表达式传入了匹配的 URL 路径,这里代表的是任何包含 .png 或 .jpg 的链接,遇到这样的请求,会回调 cancel_request 方法处理,cancel_request 方法可以接收两个参数,一个是 route,代表一个 CallableRoute 对象,另外一个是 request,代表 Request 对象。这里我们直接调用了 route 的 abort 方法,取消了这次请求,所以最终导致的结果就是图片的加载全部取消了。
这个设置有什么用呢?其实是有用的,因为图片资源都是二进制文件,而我们在做爬取过程中可能并不想关心其具体的二进制文件的内容,可能只关心图片的 URL 是什么,所以在浏览器中是否把图片加载出来就不重要了。所以如此设置之后,我们可以提高整个页面的加载速度,提高爬取效率。
另外,利用这个功能,我们还可以将一些响应内容进行修改,比如直接修改 Response 的结果为自定义的文本文件内容。
首先这里定义一个 HTML 文本文件,命名为 custom_response.html,内容如下:
<!DOCTYPE html>
<html>
<head>
<title>Hack Response</title>
</head>
<body>
<h1>Hack Response</h1>
</body>
</html>
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()def modify_response(route, request):
route.fulfill(path="./custom_response.html")page.route('/', modify_response)
page.goto("https://spa6.scrape.center/")
browser.close()
这里我们使用 route 的 fulfill 方法指定了一个本地文件,就是上面定义的 HTML 文件
执行程序可以看到,Response 的运行结果就被我们修改了,URL 还是不变的,但是结果已经成了我们修改的 HTML 代码。所以通过 route 方法,我们可以灵活地控制请求和响应的内容,从而在某些场景下达成某些目的。
DrissionPage
github:https://github.com/g1879/DrissionPage
官网:http://g1879.gitee.io/drissionpagedocs/
基于 python 的网页自动化工具。既能控制浏览器,也能收发数据包。可兼顾浏览器自动化的便利性和requests的高效率。功能强大,内置无数人性化设计和便捷功能。语法简洁而优雅,代码量少。
背景
用 requests 做数据采集面对要登录的网站时,要分析数据包、JS 源码,构造复杂的请求,往往还要应付验证码、JS 混淆、签名参数等反爬手段,门槛较高,开发效率不高。 使用浏览器,可以很大程度上绕过这些坑,但浏览器运行效率不高。
因此,这个库设计初衷,是将它们合而为一,同时实现“写得快”和“跑得快”。能够在不同须要时切换相应模式,并提供一种人性化的使用方法,提高开发和运行效率。
除了合并两者,本库还以网页为单位封装了常用功能,提供非常简便的操作和语句,使用户可减少考虑细节,专注功能实现。 以简单的方式实现强大的功能,使代码更优雅。
入门指南
:http://g1879.gitee.io/drissionpagedocs/get_start/installation_and_import/
使用文档
:http://g1879.gitee.io/drissionpagedocs/usage_introduction/



