
热门标签
热门文章
- 1Linux中批量创建用户的方法
- 2Virtualbox安装Windows11教程,提供虚机专用镜像下载。_virtual box镜像下载
- 3获取含有数字和大小字母的随机验证码(python)_python获取数字字母验证码
- 4Spring系列之集成Druid连接池及监控配置_springdriud
- 5jeston nano开发板 在ubuntu18.04环境下搭建的ROS和arduino小车
- 6python入门教程(非常详细),从零基础入门到精通,看完这一篇就够了
- 7nvidia docker安装和驱动安装_docker安装nvidia驱动
- 8【网课平台】Day10.对接第三方:实现微信扫码登录_对接微信扫码登录
- 9分享4个工具,轻松搞定PDF和图像中提取文本_python pdf图片转文字
- 10并发编程(三大特性)-volatile_说一下并发编程的几个特性?
当前位置: article > 正文
【分布式】MIT 6.824 Lab1-MapReduce_mit 6.824 分布式系统: lab1
作者:算法构造者2 | 2024-01-29 10:52:39
赞
踩
mit 6.824 分布式系统: lab1
1. 概述
1.1 总览
- 首先,我们要清楚MapReduce的论文内容,有哪些部分,每部分干什么。这里放一张总览图,来自论文里面。

- 工作流程总览
- 输入文件进行分片;
- 由Master分配任务(Map或Reduce)给worker;
- 运行Map任务的worker读取分片内容解析为键值对,并将内容交给Map函数得到中间key/value输出缓存到内存中;(论文还会将数据写到本地磁盘持久化)
- Master会记录上述数据的位置,然后每隔一段时间分配任务给Reduce的worker,然后worker通过RPC从磁盘读取中间key/value,并根据key进行排序,得到key对应的value集合,再交给Reduce函数并输出对应的文件,每个Reduce对应着输出一个文件。
1.2 要完成的工作
- 实验要求如下

要写两个程序,一个coordinator进程(其实就是Master)和多个并行执行的worker进程;
一些细节:
1.worker通过RPC和coordinator进行交流;
2.worker通过coordinator索要任务(读取输入文件,执行任务,输出结果到文件中);
3.coordinator会记录worker完成任务的时间,若超过10s,将会把任务分配给其他worker; - 编写程序的要求

程序写在coordinator.go,worker.go和rpc.go中,不要动mrcoordinator.go,mrworker.go这两个文件。
2. 设计

2.1 分析
- 要求
- nReduce对应的Reduce数及输出的文件数,也要作为MakeCoordinator()方法的参数;
- Reduce任务的输出文件的命名为mr-out-X,这个X就是来自nReduce;
- mr-out-X的输出有个格式要求,参照main/mrsequential.go,"%v %v" 格式;
- Map输出的中间值要放到当前目录的文件中,Reduce任务从这些文件来读取;
- 当Coordinator.go的Done()方法返回true,MapReduce的任务就完成了;
- 当一个任务完成,对应的worker就应该终止,这个终止的标志可以来自于call()方法,若它去给Master发送请求,得到终止的回应,那么对应的worker进程就可以结束了。
- 提示
- 修改mr/worker.go的Worker(),发送RPC请求给coordinator要任务。然后修改Coordinator将还没有被Map执行的文件作为响应返回给worker。然后worker读取文件并执行Map方法函数,就如示例文件 mrsequential.go;
- Map和Reduce函数加载来自插件wc.go,如果改了这些东西需要使用命令重新编译生成新的.so文件,尽量不要动这些东西;
- 中间文件的命名方式推荐为mr-X-Y,X对应Map任务Id,Y对应的Reduce任务Id;
- 为顺利存储中间数据,采用json,以便读取;
- worker 的 map 部分可以使用ihash(key)函数(在worker.go 中)为给定的键选择 reduce 任务;
- Coordinator作为一个 RPC 服务器,将是并发的;不要忘记锁定共享数据;
- 在所有Map任务完成后,Reduce任务才会开始,所以对应的worker可能会需要等待,那么可以使用time.sleep()或其他方法;
- worker可能挂掉或其他原因崩了,Coordinator在这个实验中等待10s,超过时间将会分配给其他的worker;
- 您可以使用 ioutil.TempFile 创建一个临时文件,并使用 os.Rename 对其进行原子重命名;
- test-mr.sh 运行子目录 mr-tmp 中的所有进程,因此如果出现问题并且您想查看中间文件或输出文件,请查看那里。您可以修改 test-mr.sh 以在测试失败后退出,这样脚本就不会继续测试(并覆盖输出文件)。
2.2 工作顺序
- 定义相关数据结构
- Map、Reduce任务的数据结构;
- Coordinator的数据结构;
- RPC通信的数据包;
(对于数据结构的定义,先做一个设计,可能有没有考虑到的,在实际编码中可以设计添加)
- 数据结构定义完了我们就开始具体的任务编写(我们按照MapReduce的业务顺序来)
- (worker.go)worker.go中的Worker()方法,给Master发送任务请求,得到对应的响应标志并完成对应的响应;
- (worker.go)完成获取Master响应标志后worker的响应方法,命名为doMapTask,doReduceTask;
- (worker.go)doMapTask()方法的参数、返回值、任务逻辑等确定,并编写(参考mrsequential.go程序);
- (worker.go)doReduceTask()方法的参数、返回值、任务逻辑等确定,并编写(参考mrsequential.go程序);
- (coordinator.go)MakeCoordinator方法,创建一个Master;
- (coordinator.go)响应worker请求并分配任务的方法,命名为GetTask;
- (coordinator.go) 接收worker完成工作的通知方法,并将对应的任务做完成标记等,命名为TaskDone;
- (coordinator.go)collectTimeOutTasks(),监控超时;
- (coordinator.go)Done(),mrcoordinator.go中需要使用,判断程序是否完成;
3. 编码
详见GitHub仓库
4. 运行结果
4.1 执行代码
- 运行实例程序分析

- 运行自己的程序

4.2 运行结果
- 我是将其输出到一个txt文件中,各部分截图如下

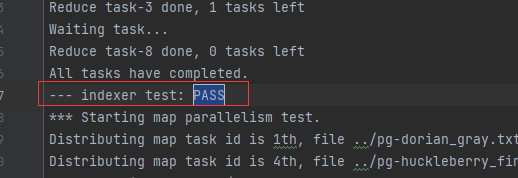
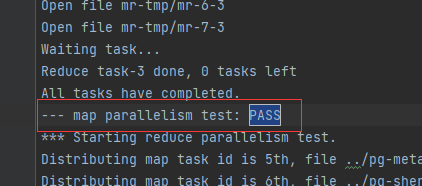
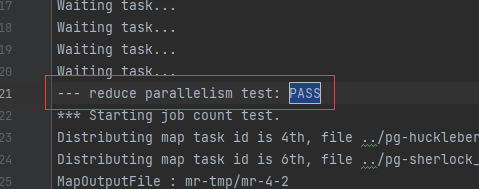
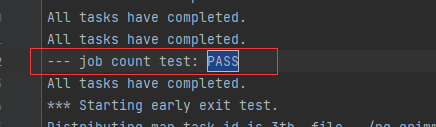
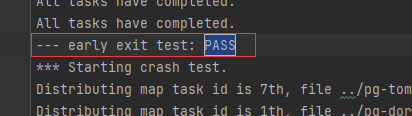
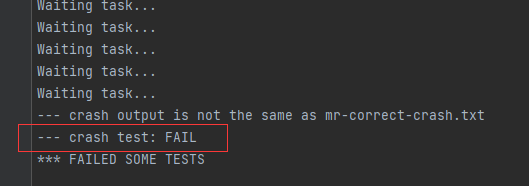
- 要测试崩溃恢复,您可以使用 mrapps/crash.go 应用程序插件。它在 Map 和 Reduce 函数中随机退出。
这里测试crash出问题,我看到的是一个Worker它一直在Waiting task…状态;
原因已经找到了,就是没有进入监控时间的程序。还没有好的解决方法。
5. 总结
- 遇到的问题
- 遇到一个天坑,真的惨,go是按照命名的首字母大小写区分public和private,我刚开始一直按照Java开发手册的规则命名,首字母都是小写,改了2个小时都没搞清楚是什么错,结果是程序相互直接方法和字段访问不到。
- 锁的设计是一个问题。由于第一次写go,我本来想的是一个监控时间的进程一直运行,然后它自己更新时间从而去判断哪些超时(详见代码),但是不知什么原因,反正运行久了这个进程就会终止,然后我只有参照【2】的代码,把这个线程改到分配任务时判断。
- 思考与总结
- 整体任务的框架其实已经在项目中搭建好了,开始着手做这个东西的时候,首先要明白MapReduce的原理,其次先看看lab的说明(在课程中有),然后把项目搞下来看看整个项目的构成框架,自己要写哪些东西,缺什么,要定义什么;
- 最难的东西是设计数据结构与对应的方法,因为这才是真正的核心流程与思想的体现,先把要写哪些数据结构设计好,可能刚开始字段有遗漏,但是后面实际编码中可以补充必要的字段。然后,要把有哪些方法想好,方法直接的逻辑,哪些方法之间有交互,然后他们的方法参数与返回值是什么。先把整个逻辑写下来再编码,否则可能东拼西凑代码到最后写得很乱。
- 最后就是优化,我认为有两点,一是对于任务分配的策略,有队列,有这里用的Map等等,可能不一样的方法的效果是不一样的,我使用Map是参照【2】,这样对于Task的增删改查都很方便,但是Map会以Key排序,会打乱请求的顺序;二是****并发访问,加锁的问题,这也是一个优化的点,对于并发的线程如监控时间我就只是采用了【2】的办法,因为我刚开始设想的实现出了问题,主要还是对go不熟,第一次用,有一些背后的逻辑不清楚,而且运行go一旦出错,相关资料网上真的是比较少。
参考
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/42766
推荐阅读

相关标签

