
热门标签
热门文章
- 1MAC地址分类
- 2Python程序打包exe可执行软件教程_python打包exe还需要环境吗
- 3路由器接口及静态路由配置_接口路由
- 4云计算基础架构介绍_新it架构-云计算,请从大数据、云计算、移动技术、社交业务方面阐述云计算的带
- 5React 中 State 与 props 区别_react 区分状态和props
- 6Jetsonnano的环境配置--ros环境_tf2_sensor_msgs 没有那个文件或目录
- 7一款超好用的企业级URL采集软件(Msray-plus)
- 8axios 中使用请求响应拦截器_axios响应拦截
- 9若依框架---权限控制角色设计_若依权限字符
- 10北京邮电大学校园网自动登录脚本 Ubuntu18.04 Python systemd 开机自启_北邮网关自动连接
当前位置: article > 正文
2022-ECCV-Explaining Deepfake Detection by Analysing Image Matching
作者:数据可视化灵魂 | 2024-01-17 14:24:38
赞
踩
2022-ECCV-Explaining Deepfake Detection by Analysing Image Matching
一、研究背景
1.大量工作将深度伪造检测作为一个二分类任务并取得了良好的性能。
2.理解模型如何在二分类标签的监督下学习伪造相关特征仍难是个艰巨的任务。
3.视觉概念:具有语义的人脸区域,如嘴、鼻子、眼睛。
二、研究目标
1.验证假设,并从图像匹配的角度评估视觉概念的关系,以此解释检测模型的预测结果。
2.解释深度伪造检测模型如何在二分类标签的监督下学习伪影特征。
3.习得更好的检测模型,提高在压缩视频上的伪造检测性能。
三、研究动机(3种假设)

1.检测模型将既不与原图相关也不与目标图相关的视觉概念看作是与伪造相关的视觉概念,性能良好的检测模型应该基于源/目标-无关的视觉概念来判断真伪。
2.在标签的监督下,伪造-原图-目标图匹配可以帮助丢弃伪造无关视觉特征,隐式学习伪造相关的视觉概念。
3.利用原始训练集进行图片匹配习得的视觉概念容易受到视频压缩的影响。
四、技术路线
假设1:
- 设计源编码器 v s v_s vs和目标编码器 v t v_t vt区分图片中的视觉概念。
- 令伪造图片与相应源/目标图片具有相同属性标签,以此训练编码器。
- 用Shapley value评估视觉概念的区域贡献。例如:
对输入图片做 L × L L\times L L×L区域划分,得到 G = { g 11 , … , g L L } G=\{g_{11},\dots,g_{LL}\} G={g11,…,gLL}。
当 ϕ v d ( g i j ∣ G ) > 0 \phi_{v_{d}}(g_{ij}\mid G)>0 ϕvd(gij∣G)>0时,证明区域 g i j g_{ij} gij与伪造相关。 - 评估视觉概念间的关系:
利用掩膜操作定位源/目标相关区域:
M τ = I ( m a x ( ϕ v s , ϕ v s ) ) > τ M_{\tau}=I(max(\phi_{v{s}},\phi_{v{s}}))>\tau Mτ=I(max(ϕvs,ϕvs))>τ
评估视觉概念间的交叉强度,第一项为无关区域的相关强度,第二项为相关区域的相关强度:
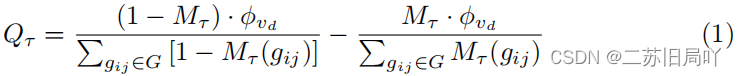
假设2:
设置两种训练集:
第一种:真实图片仅包含和伪造图片相关的原图/目标图
第二种:真实图片与伪造图片不相关
假设3:
评估稳定性:
对于压缩图片,由源/目标编码器习得的视觉概念更加稳定。
![]()
FST-Matching Deepfake Detection Model:
直接将源/目标无关特征从源/目标视觉概念中分离出来去进行真伪检测可以提升在压缩视频上的性能。

- 习得源特征 f s f_s fs和目标特征 f t f_t ft
- 利用通道注意力自动解纠缠源/目标无关特征
f
s
i
r
f_s^{ir}
fsir、
f
t
i
r
f_t^{ir}
ftir和源/目标相关特征
f
s
r
f_s^{r}
fsr、
f
t
r
f_t^{r}
ftr
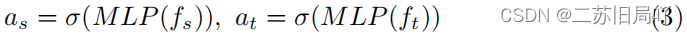
- 设置 Fake-Source/Target Pair Verification module验证解纠缠的有效性,令源/目标图片的
f
r
f^{r}
fr具有和原始图片相同的属性标签,并进行属性预测
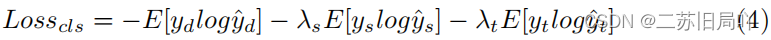
- 增强
[
f
s
i
r
,
f
t
i
r
]
[f_s^{ir}, f_t^{ir}]
[fsir,ftir]的交互,
h
h
h为预测模块,令联合预测损失小,单一预测损失大,0输入的影响小。
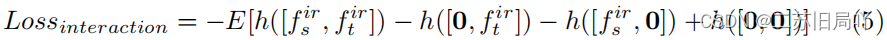
- 总损失

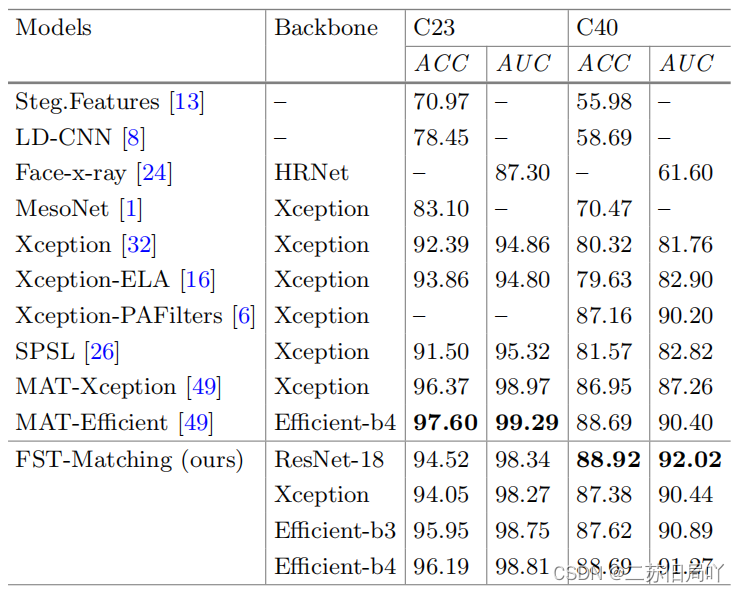
五、实验结果
六、思考
- 解纠缠:伪造无关特征包含身份属性,伪造相关特征联合区分真假
- 图匹配:在匹配中去除相同属性的干扰
- 输入:上下支路均有源、目标、伪造图片
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/41017
推荐阅读
相关标签

