
- 1搞懂JDK8与Java1.8的区别_jdk18就是jdk1.8吗
- 2网络安全的基本知识_csdn 网络安全
- 3如何正确地配置Gradle版本_gradle已有为什么还要下载
- 4IDEA 2023.2 配置 JavaWeb 工程_idea2023.2配置
- 5C++:在“替代”中迎来“转机”的 2022 年!_c++23发布时间
- 6Git教程使用系列(一):认识工作区,暂存区,本地仓库,远程仓库_工作区和本地仓库的区别
- 7数学建模学习(1)遗传算法
- 8wireshark抓包分析聊天程序聊天记录_抓包能抓到聊天记录吗
- 9Git如何将pre-commit也提交到仓库_git pre-commit如何提交
- 10Linux ----用户管理_5、以root身份登录,在根目录下,创建一个目录newtest,并在该目录下新建一个文件及
与数字人对话--LLM与数字人结合案例(续)
赞
踩
上篇文章(与数字人对话--LLM与数字人结合案例)讲了与数字人对话项目的前四步是如何实现的,本文继续讲第五步:从语音转换成数字人的Blendshape,实现让数字人说话。
先把整个流程图再次附上,对这个项目有个整体的了解。
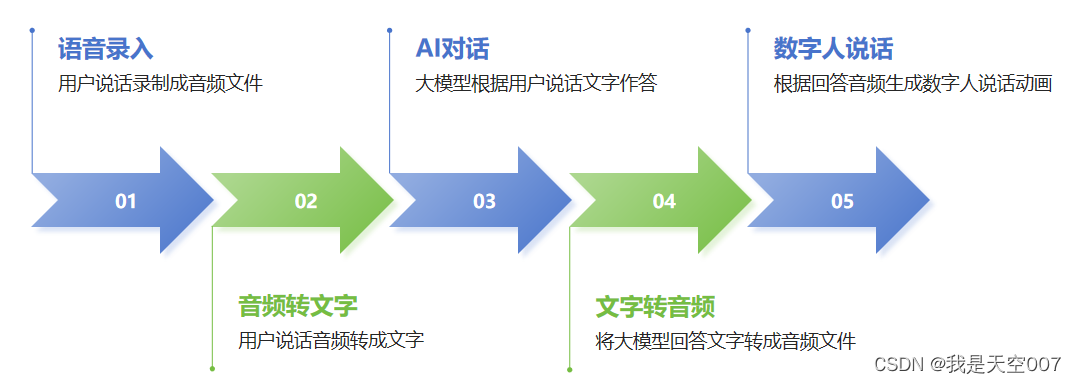
图1 数字人对话项目图
1. 语音转数字人Blendshape
大家都知道,数字人表情是通过多个基础的Blendshape线性组合而成的(可以参考另一篇文章:BlendShape-数字人表情生成机制),那么有了语音,只要转换成一系列的Blendshape权重值,然后控制数字人表情动画,就可以让数字人表情动起来,再配合语音播放,就可以实现数字人说话的效果。
语音转Blendshape采用了SAiD模型实现,SAiD模型讲输入wav文件转换成包含了Blendshape数据的csv文件,这些Blendshape是与Apple ARKit Blendshape兼容的。所以只要数字人按ARKit Blendshape标准制作了Blendshape,就可以直接使用csv中的数据。
SAiD模型的Github地址:GitHub - yunik1004/SAiD: SAiD: Blendshape-based Audio-Driven Speech Animation with Diffusion
SAiD推理生成Blendshape数据的代码如下:
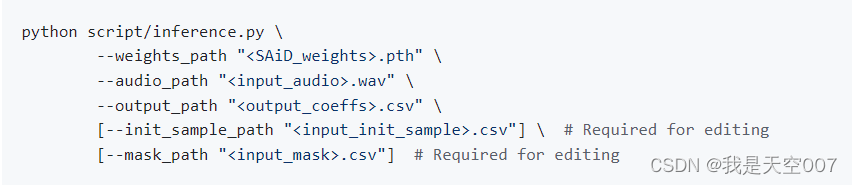
图2 SAiD推理生成Blendshape命令
生成的Blendshape数据还是通过Fast Api传回项目中。
2. 总结
到这里数据人对话的所有步骤都已经实现,其中Whisper采用的Huggingface接口,LLama 2、Bark、SAiD模型都是本地部署,功能整体跑通了,但性能还需要提高。后续要继续提高性能,并应用到具体的业务场景中。
3. 效果演示
最后看下整体的效果。
对话数字人Show

