
热门标签
热门文章
- 13.26总结
- 2你真的会使用logcat吗_can't create wucai.log: read-only file system logc
- 3uni-app开发---4.首页
- 4Java中创建线程的多种方式实例
- 5Android中kernel内核模块编译执行_安卓kernel编译
- 6flutter-无法运行到模拟器_flutter run 运行模拟器报错 could not resolve all files fo
- 7Python123 期末题库_2.表达式求值(2)成绩5开启时间2023年09月28日 星期四 10:00折扣0.8折扣时间
- 8AI基础知识扫盲
- 9神经网络:正则化 范数 Droupout BN 方差 偏差 距离 损失 梯度 指标 学习率 超参数 归一化 标准化 激活 过拟合抑制 数据增强 标签平滑_dropout 批标准化 神经网络
- 10CentOS升级版本及内核_centos最新版本
当前位置: article > 正文
Win10+PyCharm利用MMSegmentation训练自己的数据集_from mmengine.config import config, dictaction
作者:菜鸟追梦旅行 | 2024-04-01 04:27:16
赞
踩
from mmengine.config import config, dictaction
系统版本:Windows 10 企业版
依赖环境:Anaconda3
运行软件:PyCharm
MMSegmentation版本:V1.1.1
前提:运行环境已经配置好,环境的配置可以参考:Win10系统下MMSegmentation的环境配置-CSDN博客
目录
1. 从官网下载相应的MMSegmentation
从官网下载对应的版本: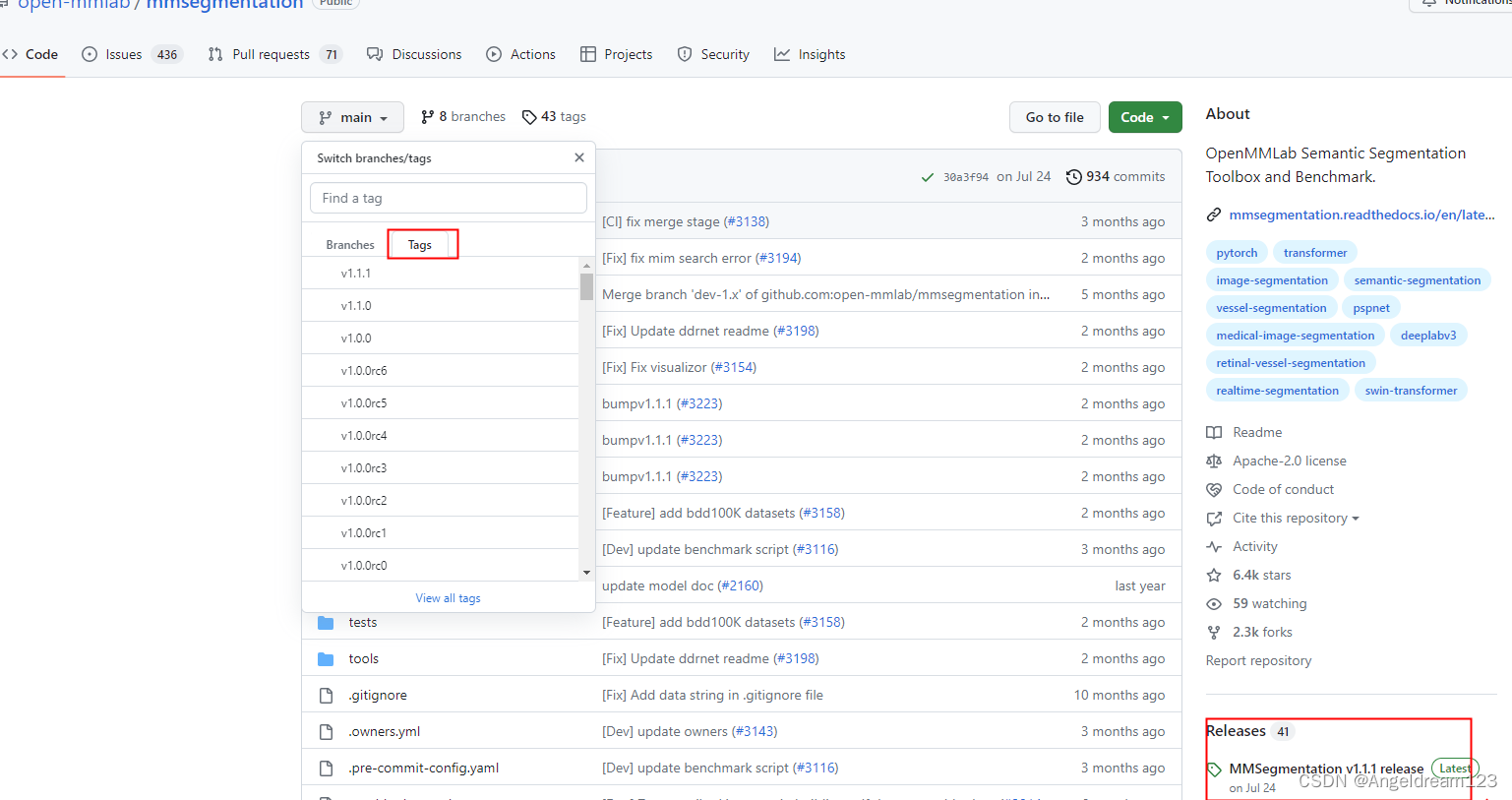
这里可以看到不同的版本。本教程使用的是最新的V1.1.1版本。
把下载好的版本当成一个工程项目,直接在Pycharm中打开。
2. 定义数据集类
在mmseg/datasets中新建一个以自己的数据集命名的py文件,例如,我新建了一个名为cag.py的文件。
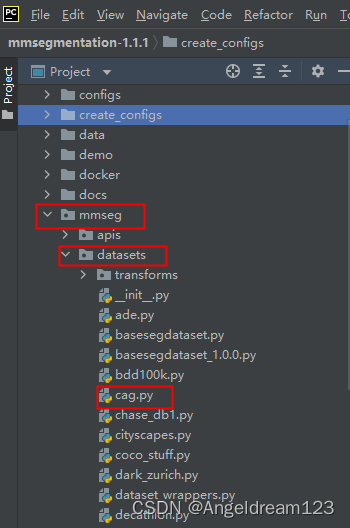
在cag.py中为自己的数据集创建一个新的类:
- # Copyright (c) Lisa. All rights reserved.
- """
- @Title: 创建一个自己的数据集
- @Author: Lisa
- @Date: 2023/09/13
- """
- import mmengine.fileio as fileio
-
- from mmseg.registry import DATASETS
- from .basesegdataset import BaseSegDataset
-
- @DATASETS.register_module()
- class CAGDataset(BaseSegDataset):
- """CAG dataset.
- In segmentation map annotation for CAG, 0 stands for background, which is
- included in 2 categories. ``reduce_zero_label`` is fixed to False. The
- ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
- '.png'.
- """
- # 类别和对应的RGB配色
- METAINFO = dict(
- classes=('background', 'vessel'), # 类别标签名称
- palette=[[0, 0, 0], [255, 255, 255]]) # 类别标签上色的RGB颜色
-
- # 指定图像扩展名,标注扩展名
- def __init__(self,
- img_suffix='.png', # 输入image的后缀名为’.png‘
- seg_map_suffix='.png', # 输入mask/label的后缀名为’.png‘
- reduce_zero_label=False,
- **kwargs) -> None:
- super().__init__(
- img_suffix=img_suffix,
- seg_map_suffix=seg_map_suffix,
- reduce_zero_label=reduce_zero_label,
- **kwargs)
3. 注册数据集类
打开mmseg/datasets/__init__.py文件
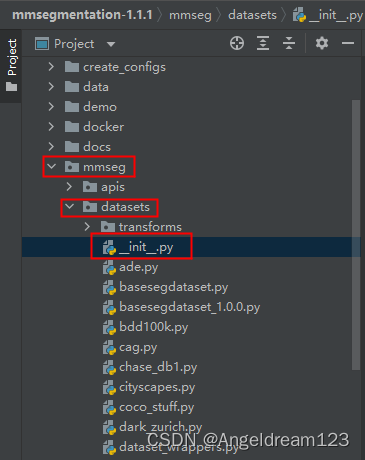
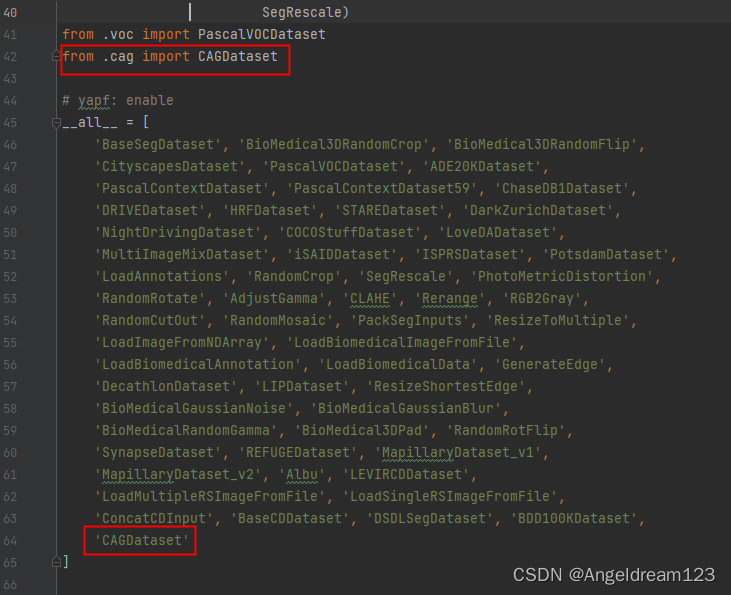
导入定义好的CAGDataset类,然后添加到__all__中。
4. 配置数据处理pipeline文件
在configs/_base_/datasets中创建一个数据处理pipeline的py文件。
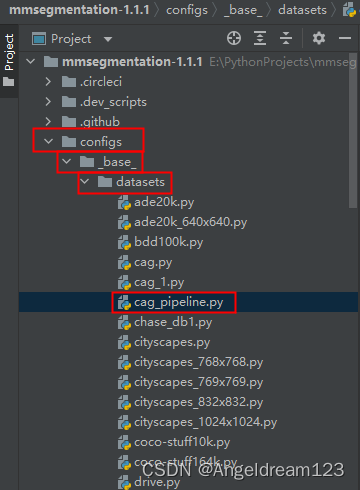
cag_pipeline.py中数据处理pipeline如下:
- # 数据处理pipeline
- # 参照同济张子豪
- # dataset settings 设置数据集路径
- dataset_type = 'CAGDataset' # must be the same name of custom dataset. 必须和自定义数据集名称完全一致。
- data_root = '../data/CAG' # 数据集根目录, 后续所有的pipeline使用的目录都会在此目录下的子目录读取
- # img_scale = (2336, 3504)
- # img_scale = (512, 512)
- # crop_size = (256, 256)
- # 输入模型的图像裁剪尺寸,一般是128的倍数。
- crop_size = (512, 512)
-
- # 训练预处理
- train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadAnnotations'),
- dict(
- type='RandomResize',
- scale=(2048, 1024),
- ratio_range=(0.5, 2.0),
- keep_ratio=True),
- # dict(type='Resize', img_scale=img_scale),
- dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
- dict(type='RandomFlip', prob=0.5),
- dict(type='PhotoMetricDistortion'),
- dict(type='PackSegInputs')
- ]
-
- # 测试 预处理
- test_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='Resize', scale=(2048, 1024), keep_ratio=True),
- # add loading annotation after ``Resize`` because ground truth
- # does not need to do resize data transform
- dict(type='LoadAnnotations'),
- dict(type='PackSegInputs')
- ]
-
- # TTA 后处理
- img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75]
- tta_pipeline = [
- # dict(type='LoadImageFromFile', backend_args=None),
- dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),
- dict(
- type='TestTimeAug',
- transforms=[
- [
- dict(type='Resize', scale_factor=r, keep_ratio=True)
- for r in img_ratios
- ],
- [
- dict(type='RandomFlip', prob=0., direction='horizontal'),
- dict(type='RandomFlip', prob=1., direction='horizontal')
- ], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]
- ])
- ]
-
- # 训练 Dataloader
- train_dataloader = dict(
- batch_size=4, # 4
- num_workers=2, # 4 dataloader的线程数目,一般设为2, 4, 8,根据CPU核数确定,或使用os.cpu_count()函数代替,一般num_workers>=4速度提升就不再明显。
- persistent_workers=True, # 一种加速图片加载的操作
- sampler=dict(type='InfiniteSampler', shuffle=True), # shuffle=True是打乱图片
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_prefix=dict(
- img_path='images/training',
- seg_map_path='annotations/training'),
- # ann_file='splits/train.txt',
- pipeline=train_pipeline
- )
- )
-
- # 测试DataLoader
- val_dataloader = dict(
- batch_size=1,
- num_workers=4, # 4
- persistent_workers=True,
- sampler=dict(type='DefaultSampler', shuffle=False),
- dataset=dict(
- type=dataset_type,
- data_root=data_root,
- data_prefix=dict(
- img_path='images/validation',
- seg_map_path='annotations/validation'),
- # ann_file='splits/val.txt',
- pipeline=test_pipeline
- ))
-
- # 验证DataLoader
- test_dataloader = val_dataloader
-
- # 验证 Evaluator
- val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice', 'mFscore']) # 分割指标评估器
- test_evaluator = val_evaluator
5. 配置Config文件
以UNet为例,配置Config文件
- """
- create_Unet_config.py
- 配置Unet的Config文件
- """
- from mmengine import Config
-
- cfg = Config.fromfile('../configs/unet/unet-s5-d16_fcn_4xb4-160k_cityscapes-512x1024.py ')
- dataset_cfg = Config.fromfile('../configs/_base_/datasets/cag_pipeline.py')
- cfg.merge_from_dict(dataset_cfg)
-
- # 修改Config配置文件
- # 类别个数
- NUM_CLASS = 2
-
- cfg.crop_size = (512, 512)
- cfg.model.data_preprocessor.size = cfg.crop_size
- cfg.model.data_preprocessor.test_cfg = dict(size_divisor=128)
-
- # 单卡训练时,需要把SyncBN改为BN
- cfg.norm_cfg = dict(type='BN', requires_grad=True)
- cfg.model.backbone.norm_cfg = cfg.norm_cfg
- cfg.model.decode_head.norm_cfg = cfg.norm_cfg
- cfg.model.auxiliary_head.norm_cfg = cfg.norm_cfg
-
- # 模型decode/auxiliary输出头,指定为类别个数
- cfg.model.decode_head.num_classes = NUM_CLASS
- cfg.model.auxiliary_head.num_classes = NUM_CLASS
-
- # 训练Batch Size
- cfg.train_dataloader.batch_size = 4
-
- # 结果保存目录
- cfg.work_dir = '../work_dirs/my_Unet'
-
- # 模型保存与日志记录
- cfg.train_cfg.max_iters = 60000 # 训练迭代次数
- cfg.train_cfg.val_interval = 500 # 评估模型间隔 500
- cfg.default_hooks.logger.interval = 100 # 日志记录间隔
- cfg.default_hooks.checkpoint.interval = 500 # 模型权重保存间隔 2500
- cfg.default_hooks.checkpoint.max_keep_ckpts = 2 # 最多保留几个模型权重 1, 2
- cfg.default_hooks.checkpoint.save_best = 'mIoU' # 保留指标最高的模型权重
-
- # 随机数种子
- cfg['randomness'] = dict(seed=0)
-
- # 查看完整的Config配置文件
- print(cfg.pretty_text)
-
- # 保存最终的config配置文件
- cfg.dump('../my_Configs/my_Unet_20230913.py')
-
6. 训练模型
在PyCharm中运行my_train.py主要有两种方式,
方式一:在右上方的my_train处单击“Edit Configurations...”
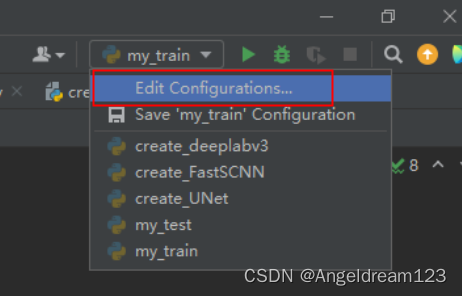
在Parameters:一栏中输入命令“ ../my_Configs/my_PSPNet_20230906.py ../work_dirs/my_PSPNet”,然后点击“运行”。
方式二: 改写超参数
- # Copyright (c) OpenMMLab. All rights reserved.
- """
- 参考train.py改写
- """
- import argparse
- import logging
- import os
- import os.path as osp
-
- import torch.backends.cudnn
- from mmengine.config import Config, DictAction
- from mmengine.logging import print_log
- from mmengine.runner import Runner
-
- from mmseg.registry import RUNNERS
-
- os.environ['CUDA_LAUNCH_BLOCKING'] = '1' #(上面报错的最后一行的提示信息)
- # torch.backends.cudnn.benchmark = True
- # 用于解决报错:RuntimeError: CUDA error: an illegal memory access was encountered
- # CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
- # For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
-
- def parse_args():
- parser = argparse.ArgumentParser(description='Train a segmentor')
- parser.add_argument('--config', default='../my_Configs/my_PSPNet_20230906.py', help='train config file path') # 不加--号是表示该参数是必须的
- # parser.add_argument('--config', default='../configs/deeplabv3plus/deeplabv3plus_r50-d8_4xb4-80k_cag-512x512_my.py',
- # help='train config file path') # 不加--号是表示该参数是必须的
- # parser.add_argument('--config', default='../my_Configs/my_KNet_20230830.py',
- # help='train config file path') # 不加--号是表示该参数是必须的
- # parser.add_argument('--work-dir', default='work_dir', help='the dir to save logs and models')
- parser.add_argument('--work-dir', default='../work_dirs/my_PSPNet', help='the dir to save logs and models')
- parser.add_argument(
- '--resume',
- action='store_true',
- default=True,
- help='resume from the latest checkpoint in the work_dir automatically')
- parser.add_argument(
- '--amp',
- action='store_true',
- default=False,
- help='enable automatic-mixed-precision training')
- parser.add_argument(
- '--cfg-options',
- nargs='+',
- action=DictAction,
- help='override some settings in the used config, the key-value pair '
- 'in xxx=yyy format will be merged into config file. If the value to '
- 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
- 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
- 'Note that the quotation marks are necessary and that no white space '
- 'is allowed.')
- parser.add_argument(
- '--launcher',
- choices=['none', 'pytorch', 'slurm', 'mpi'],
- default='none',
- help='job launcher')
- # When using PyTorch version >= 2.0.0, the `torch.distributed.launch`
- # will pass the `--local-rank` parameter to `tools/train.py` instead
- # of `--local_rank`.
- parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
- args = parser.parse_args()
- if 'LOCAL_RANK' not in os.environ:
- os.environ['LOCAL_RANK'] = str(args.local_rank)
-
- return args
-
-
- def main():
- args = parse_args()
-
- # load config
- cfg = Config.fromfile(args.config)
- cfg.launcher = args.launcher
- if args.cfg_options is not None:
- cfg.merge_from_dict(args.cfg_options)
-
- # work_dir is determined in this priority: CLI > segment in file > filename
- if args.work_dir is not None:
- # update configs according to CLI args if args.work_dir is not None
- cfg.work_dir = args.work_dir
- elif cfg.get('work_dir', None) is None:
- # use config filename as default work_dir if cfg.work_dir is None
- cfg.work_dir = osp.join('./work_dirs',
- osp.splitext(osp.basename(args.config))[0])
-
- # enable automatic-mixed-precision training
- if args.amp is True:
- optim_wrapper = cfg.optim_wrapper.type
- if optim_wrapper == 'AmpOptimWrapper':
- print_log(
- 'AMP training is already enabled in your config.',
- logger='current',
- level=logging.WARNING)
- else:
- assert optim_wrapper == 'OptimWrapper', (
- '`--amp` is only supported when the optimizer wrapper type is '
- f'`OptimWrapper` but got {optim_wrapper}.')
- cfg.optim_wrapper.type = 'AmpOptimWrapper'
- cfg.optim_wrapper.loss_scale = 'dynamic'
-
- # resume training
- cfg.resume = args.resume
-
- # build the runner from config
- if 'runner_type' not in cfg:
- # build the default runner
- runner = Runner.from_cfg(cfg)
- else:
- # build customized runner from the registry
- # if 'runner_type' is set in the cfg
- runner = RUNNERS.build(cfg)
-
- # start training
- runner.train()
-
-
- if __name__ == '__main__':
- main()
7. 测试模型
单张测试的话,可以参考以下代码:
- """
- single_image_predict.py
- 用训练得到的模型进行预测-单张图像
- """
- import numpy as np
- import matplotlib.pyplot as plt
- from mmseg.apis import init_model, inference_model, show_result_pyplot
- import cv2
-
- # 载入模型 KNet
- # 模型 config 配置文件
- config_file = '../work_dirs/my_FastSCNN/my_FastSCNN_20230911.py'
-
- # 模型checkpoint权重文件
- checkpoint_file = '../work_dirs/my_FastSCNN/best_mIoU_iter_50500.pth'
-
- device = 'cuda:0'
-
- model = init_model(config_file, checkpoint_file, device=device)
-
- # 载入测试集图像或新图像
- img_path = '../data/.../xxx.png'
-
- img_bgr = cv2.imread(img_path)
-
- # 显示原图
- plt.figure(figsize=(8, 8))
- plt.imshow(img_bgr[:, :, ::-1])
- plt.show()
-
- # 语义分割预测
- result = inference_model(model, img_bgr)
- print(result.keys())
-
- pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
- print(pred_mask.shape)
- print(np.unique(pred_mask))
-
- # #****** 可视化语义分割预测结果——方法一(直接显示分割结果)******#
- # 定性
- plt.figure(figsize=(8, 8))
- plt.imshow(pred_mask)
- plt.savefig('test_result/k1-0.jpg')
- plt.show()
-
- # 定量
- print(result.seg_logits.data.shape)
-
- # #****** 可视化语义分割预测结果--方法二(叠加在原因上进行显示)******#
- # 显示语义分割结果
- plt.figure(figsize=(10, 8))
- plt.imshow(img_bgr[:, :, ::-1])
- plt.imshow(pred_mask, alpha=0.55)
- plt.axis('off')
- plt.savefig('test_result/k1-1.jpg')
- plt.show()
-
- # #****** 可视化语义分割预测结果--方法三(和原图并排显示) ******#
- plt.figure(figsize=(14, 8))
- plt.subplot(1, 2, 1)
- plt.imshow(img_bgr[:, :, ::-1])
- plt.axis('off')
-
- plt.subplot(1, 2, 2)
- plt.imshow(img_bgr[:, :, ::-1])
- plt.imshow(pred_mask, alpha=0.6)
- plt.axis('off')
- plt.savefig('test_result/k1-2.jpg')
- plt.show()
-
- # #****** 可视化语义分割预测结果-方法四(按配色方案叠加在原图上显示) ******#
- # 各类别的配色方案(BGR)
- palette = [
- ['background', [127, 127, 127]],
- ['vessel', [0, 0, 200]]
- ]
-
- palette_dict = {}
- for idx, each in enumerate(palette):
- palette_dict[idx] = each[1]
-
- print('palette_dict:', palette_dict)
-
- opacity = 0.3 # 透明度,越大越接近原图
-
- # 将预测的整数ID,映射为对应类别的颜色
- pred_mask_bgr = np.zeros((pred_mask.shape[0], pred_mask.shape[1], 3))
- for idx in palette_dict.keys():
- pred_mask_bgr[np.where(pred_mask == idx)] = palette_dict[idx]
- pred_mask_bgr = pred_mask_bgr.astype('uint8')
-
- # 将语义分割预测图和原图叠加显示
- pred_viz = cv2.addWeighted(img_bgr, opacity, pred_mask_bgr, 1-opacity, 0)
-
- cv2.imwrite('test_result/k1-3.jpg', pred_viz)
-
- plt.figure(figsize=(8, 8))
- plt.imshow(pred_viz[:, :, ::-1])
- plt.show()
-
- # #***** 可视化语义分割预测结果-方法五(按mmseg/datasets/cag.py里定义的类别颜色可视化) ***** #
- img_viz = show_result_pyplot(model, img_path, result, opacity=0.8, title='MMSeg', out_file='test_result/k1-4.jpg')
-
- print('the shape of img_viz:', img_viz.shape)
- plt.figure(figsize=(14, 8))
- plt.imshow(img_viz)
- plt.show()
-
- # #***** 可视化语义分割预测结果--方法六(加图例) ***** #
- from mmseg.datasets import CAGDataset
- import numpy as np
- import mmcv
- from PIL import Image
-
- # 获取类别名和调色板
- classes = CAGDataset.METAINFO['classes']
- palette = CAGDataset.METAINFO['palette']
- opacity = 0.15
-
- # 将分割图按调色板染色
- seg_map = pred_mask.astype('uint8')
- seg_img = Image.fromarray(seg_map).convert('P')
- seg_img.putpalette(np.array(palette, dtype=np.uint8))
-
- from matplotlib import pyplot as plt
- import matplotlib.patches as mpatches
- plt.figure(figsize=(14, 8))
- img_plot = ((np.array(seg_img.convert('RGB')))*(1-opacity) + mmcv.imread(img_path)*opacity) / 255
- im = plt.imshow(img_plot)
-
- # 为每一种颜色创建一个图例
- patches = [mpatches.Patch(color=np.array(palette[i])/255, label=classes[i]) for i in range(len(classes))]
- plt.legend(handles=patches, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0., fontsize='large')
-
- plt.savefig('test_result/k1-6.jpg')
- plt.show()
-
-
单张测试或批量测试,也可以参考以下代码:
- """
- @title: 根据配置(Config)文件和已训练好的参数(pth)进行推理
- @Date: 2023/09/14
- """
- # 导入必要的库
- import os
- import numpy as np
- import cv2
- from tqdm import tqdm
- from mmseg.apis import init_model, inference_model, show_result_pyplot
- import matplotlib.pyplot as plt
- import matplotlib.patches as mpatches
- from mmseg.datasets import CAGDataset
- import numpy as np
- import mmcv
- from PIL import Image
-
- def predict_single_img(img_path, model, save=False, save_path=None, save_model=1, show=False, show_model=1):
-
- # 读取图像
- img_bgr = cv2.imread(img_path)
-
- # 语义分割预测
- result = inference_model(model, img_bgr)
- pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
- # print(pred_mask.shape)
- # print(np.unique(pred_mask))
-
- # 将预测的整数ID, 映射为对应类别的颜色
- pred_mask_bgr = np.zeros((pred_mask.shape[0], pred_mask.shape[1], 3))
- for idx in palette_dict.keys():
- pred_mask_bgr[np.where(pred_mask == idx)] = palette_dict[idx]
- pred_mask_bgr = pred_mask_bgr.astype('uint8')
-
- # 保存分割结果
- if save:
- # 保存方式一: 直接保存\显示分割(预测)结果
- if save_model == 1:
- save_image_path = os.path.join(save_path, 'pred-' + img_path.split('\\')[-1])
- cv2.imwrite(save_image_path, pred_mask_bgr)
- # 保存方式二: 将分割(预测)结果和原图叠加保存
- elif save_model == 2:
- opacity = 0.7 # 透明度,取值范围(0,1),越大越接近原图
- pred_add = cv2.addWeighted(img_bgr, opacity, pred_mask_bgr, 1-opacity, 0)
- save_image_path = os.path.join(save_path, 'pred-' + img_path.split('/')[-1])
- cv2.imwrite(save_image_path, pred_add)
- # 保存方式三:检测分割结果的边界轮廓,然后叠加到原图上
- elif save_model == 3:
- # 预测图转为灰度图
- binary = np.where(0.5 < pred_mask, 1, 0).astype(dtype=np.uint8)
- binary = binary * 255
- # 检测mask的边界
- contours, hierarchy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
- # 绘制边界轮廓
- # cv2.drawContours(image, contours, -1, (255, 0, 0), 1) # 蓝色 # (255, 0, 0) 蓝色; (0, 255, 0)绿色; (0, 0, 255)蓝色
- cv2.drawContours(img_bgr, contours, -1, (0, 255, 0), 1) # 绿色
- # 保存
- # save_image_path = os.path.join(save_path, 'pred-' + img_path.split('\\')[-1])
- save_image_path = os.path.join(save_path, img_path.split('\\')[-1])
- cv2.imwrite(save_image_path, img_bgr)
- # cv2.imencode(".png", img_bgr)[1].tofile(save_image_path)
-
- # 显示分割结果
- if show:
- # #****** 可视化语义分割预测结果——方法一(直接显示分割结果)******#
- if show_model == 1:
- plt.figure(figsize=(8, 8))
- plt.imshow(pred_mask)
- plt.savefig('test_result/k1-0.jpg')
- plt.show()
- print(result.seg_logits.data.shape) # 定量
-
- # #****** 可视化语义分割预测结果--方法二(叠加在原因上进行显示)******#
- elif show_model == 2:
- # 显示语义分割结果
- plt.figure(figsize=(10, 8))
- plt.imshow(img_bgr[:, :, ::-1])
- plt.imshow(pred_mask, alpha=0.55)
- plt.axis('off')
- plt.savefig('test_result/k1-1.jpg')
- plt.show()
-
- # #****** 可视化语义分割预测结果--方法三(和原图并排显示) ******#
- elif show_model == 3:
- plt.figure(figsize=(14, 8))
- plt.subplot(1, 2, 1)
- plt.imshow(img_bgr[:, :, ::-1])
- plt.axis('off')
-
- plt.subplot(1, 2, 2)
- plt.imshow(img_bgr[:, :, ::-1])
- plt.imshow(pred_mask, alpha=0.6)
- plt.axis('off')
- plt.savefig('test_result/k1-2.jpg')
- plt.show()
-
- # #****** 可视化语义分割预测结果-方法四(按配色方案叠加在原图上显示) ******#
- elif show_model == 4:
- opacity = 0.3 # 透明度,越大越接近原图
-
- # 将预测的整数ID,映射为对应类别的颜色
- pred_mask_bgr = np.zeros((pred_mask.shape[0], pred_mask.shape[1], 3))
- for idx in palette_dict.keys():
- pred_mask_bgr[np.where(pred_mask == idx)] = palette_dict[idx]
- pred_mask_bgr = pred_mask_bgr.astype('uint8')
-
- # 将语义分割预测图和原图叠加显示
- pred_viz = cv2.addWeighted(img_bgr, opacity, pred_mask_bgr, 1 - opacity, 0)
-
- cv2.imwrite('test_result/k1-3.jpg', pred_viz)
-
- plt.figure(figsize=(8, 8))
- plt.imshow(pred_viz[:, :, ::-1])
- plt.show()
-
- # #***** 可视化语义分割预测结果-方法五(按mmseg/datasets/cag.py里定义的类别颜色可视化) ***** #
- elif show_model == 5:
- img_viz = show_result_pyplot(model, img_path, result, opacity=0.8, title='MMSeg',
- out_file='test_result/k1-4.jpg')
- print('the shape of img_viz:', img_viz.shape)
- plt.figure(figsize=(14, 8))
- plt.imshow(img_viz)
- plt.show()
-
- # #***** 可视化语义分割预测结果--方法六(加图例) ***** #
- elif show_model == 6:
- # 获取类别名和调色板
- classes = CAGDataset.METAINFO['classes']
- palette = CAGDataset.METAINFO['palette']
- opacity = 0.15
-
- # 将分割图按调色板染色
- seg_map = pred_mask.astype('uint8')
- seg_img = Image.fromarray(seg_map).convert('P')
- seg_img.putpalette(np.array(palette, dtype=np.uint8))
-
- # from matplotlib import pyplot as plt
- # import matplotlib.patches as mpatches
- plt.figure(figsize=(14, 8))
- img_plot = ((np.array(seg_img.convert('RGB'))) * (1 - opacity) + mmcv.imread(img_path) * opacity) / 255
- im = plt.imshow(img_plot)
-
- # 为每一种颜色创建一个图例
- patches = [mpatches.Patch(color=np.array(palette[i]) / 255, label=classes[i]) for i in range(len(classes))]
- plt.legend(handles=patches, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0., fontsize='large')
-
- plt.savefig('test_result/k1-6.jpg')
- plt.show()
-
-
- if __name__ == '__main__':
- # 指定测试集路径
- test_images_path = '../data/XXX/images/test'
- # 指定测试集结果存放路径
- result_save_path = '../data/XXX/predict_result/Segformer_model3'
-
- # 检测结果存放的目录是否存在.不存在的话,创建空文件夹
- if not os.path.exists(result_save_path):
- os.mkdir(result_save_path)
-
- # 载入模型
- # 模型config配置文件
- config_file = '../my_Configs/my_Segformer_20230907.py'
- # 模型checkpoint权重文件
- checkpoint_file = '../work_dirs/my_Segformer/best_mIoU_iter_50000.pth'
-
- # 计算硬件
- device = 'cuda:0'
-
- # 指定各个类别的BGR配色
- palette = [
- ['background', [0, 0, 0]],
- ['vessel', [255, 255, 255]]
- ]
- palette_dict = {}
- for idx, each in enumerate(palette):
- palette_dict[idx] = each[1]
- print(palette_dict)
-
- # 加载模型
- model = init_model(config_file, checkpoint_file, device=device)
-
- # 单张图像预测函数
- opacity = 0.7
-
- # 测试集批量预测
- for each in tqdm(os.listdir(test_images_path)):
- print(each)
- image_path = os.path.join(test_images_path, each)
- # predict_single_img(image_path, model, save=True, save_path=result_save_path, save_model=3, show=False)
- predict_single_img(image_path, model, save=False, save_path=result_save_path, save_model=3, show=True, show_model=2)
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/347432?site=
推荐阅读
相关标签

