
- 1建筑企业在进行数字化转型的过程中的捷径有哪些?
- 2Vue必备知识点(简单+快速上手Vue)_学vue必备哪些基础
- 3A写作软件赋能让AI写作内容创作更高效,多元化文章格式的AI写作生成器推荐
- 4解决npm install总是卡住不动的问题_npm 卡在完成界面
- 5大模型核心技术原理: Transformer架构详解_大模型基于transformer
- 6Swin Transformer 学习笔记_swin transformer迁移学习
- 7关于Android studio里ext中的$rootProject的总结_android 通过rootproject.ext 引用不到
- 8纯CSS3实现圆弧(圆圈)百分比动画进度条_css3实现圆弧百分比动画进度条
- 9原来,这才是开发者打开世界读书日的正确姿势_mlapplication.getinstance().setapikey
- 10实例带你了解GaussDB的索引管理
推荐收藏 | 机器学习的知识点,全在这篇文章里了
赞
踩
导读:作者用超过1.2万字的篇幅,总结了自己学习机器学习过程中遇到知识点。“入门后,才知道机器学习的魅力与可怕。”希望正在阅读本文的你,也能在机器学习上学有所成。
作者:尘恋
来源:大数据(ID:hzdashuju)

00 准备
机器学习是什么,人工智能的子类,深度学习的父类。
机器学习:使计算机改进或是适应他们的行为,从而使他们的行为更加准确。也就是通过数据中学习,从而在某项工作上做的更好。
引用王钰院士在2008年会议的一句话,假定W是给定世界的有限或者无限的所有对象的集合,Q是我们能够或得到的有限数据,Q是W的一个很小的真子集,机器学习就是根据世界的样本集来推算世界的模型,使得模型对于整体世界来说为真。
机器学习的两个驱动:神经网络,数据挖掘。
机器学习的分类:
监督学习:提供了包含正确回答的训练集,并以这个训练集为基础,算法进行泛化,直到对所有的可能输入都给出正确回答,这也称在范例中学习。
无监督学习:没有提供正确回答,算法试图鉴别出输入之间的相似,从而将同样的输入归为一类,这种方法称密度学习。
强化学习:介于监督和无监督之间,当答案不正确时,算法被告知,如何改正则不得而知,算法需要去探索,试验不同情况,直到得到正确答案,强化学习有时称为伴随评论家的学习,因为他只对答案评分,而不给出改进建议。
进化学习:将生物学的进化看成一个学习过程,我们研究如何在计算机中对这一过程进行建模,采用适应度的概念,相当于对当前解答方案好坏程度的评分。(不是所有机器学习书籍都包含进化学习)
优点:泛化,对于未曾碰到的输入也能给出合理的输出。
监督学习:回归、分类。
机器学习过程:
数据的收集和准备
特征选择
算法选择
参数和模型选择
训练
评估
专业术语:
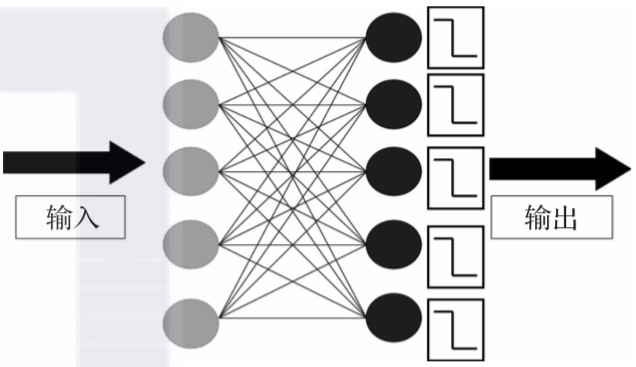
输入:输入向量x作为算法输入给出的数据
突触:wij是节点i和节点j之间的加权连接,类似于大脑中的突触,排列成矩阵W
输出:输出向量y,可以有n个维度
目标:目标向量t,有n个维度,监督学习所需要等待额外数据,提供了算法正在学习的“正确答案”
维度:输入向量的个数
激活函数:对于神经网络,g(·)是一种数学函数,描述神经元的激发和作为对加权输入的响应
误差:E是根据y和t计算网络不准确性的函数
权重空间:当我们的输入数据达到200维时,人类的限制使得我们无法看见,我们最多只能看到三维投影,而对于计算机可以抽象出200个相互正交的轴的超平面进行计算,神经网络的参数是将神经元连接到输入的一组权重值,如将神经元的权重视为一组坐标,即所谓的权重空间
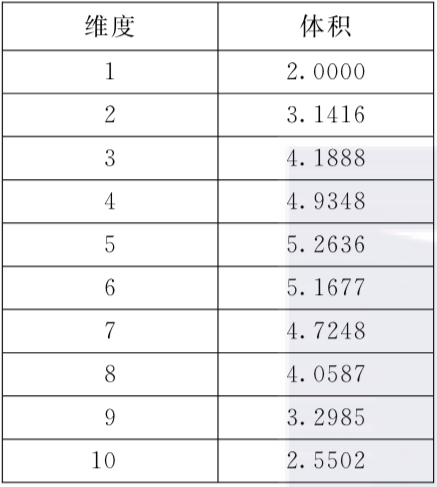
维度灾难:随着维度的增加,单位超球面的体积也在不断增加,2d中,单位超球面为圆,3d中则为求,而更高的维度便称为超球面,Vn = (2π/n)*Vn-2,于是当n>2π时,体积开始缩小,因此可用数据减少,意味着我们需要更多的数据,当数据到达100维以上时,单位数据变得极小,进而需要更多的数据,从而造成维度灾难
真正例(TP) | 假正例(FP) |
假反例(FN) | 真反例(TN) |
-
敏感率=#TP/(#TP+#FN) 特异率=#TN/(#TN+#FP)
-
查准率=#TP/(#TP+#FP) 查全率=#TP/(#TP+#FN)
-
F1 = 2*(查准率*查全率)/(查准率+查全率)
-
权重更新规则
-
感知器学习算法
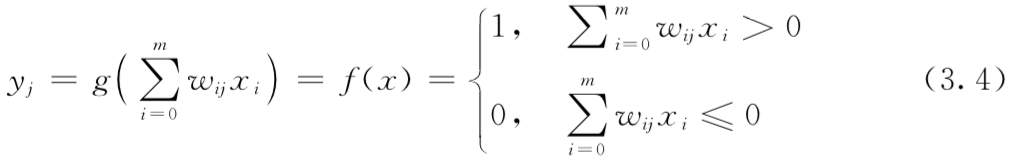
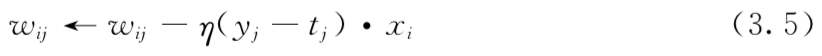
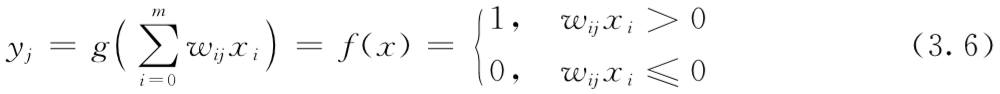
-
特征选择法: 仔细查找可见的并可以利用的特征而无论他们是否有用,把它与输出变量关联起来
-
特征推导法: 通过应用数据迁移,即通过可以用矩阵来描述的平移和旋转来改变图标的坐标系,从而用旧的特征推导出新的特征,因为他允许联合特征,并且坚定哪一个是有用的,哪一个没用
-
聚类法: 把相似的数据点放一起,看能不能有更少的特征
-
主成分分析(PCA)
-
具体算法
写成N个点Xi=(X1i,X2i,... xXi)作为行向量。把这些向量写成一个矩阵X(X将是N*M阶矩阵)。通过减去每列的平均值来把数据中心化,并令变化好的矩阵为B。计算协方差阵C= 1/N *B^TB。计算C的特征向量和特征值,即V^-1CV=D,其中V由C的特征向量组成,D是由特征值组成的M*M阶对角矩阵。把D对角线上元素按降序排列,并对V的列向量做同样的排列。去掉那些小于η的特征值,剩下L维的数据。
选择核并且把它应用于距离矩阵从而得到矩阵K。计算K的特征值和特征向量。通过特征值的平方根标准化特征向量。保留与最大特征值对应的特征向量。
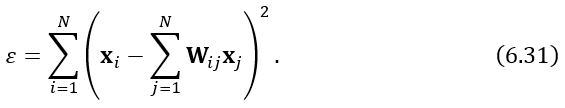
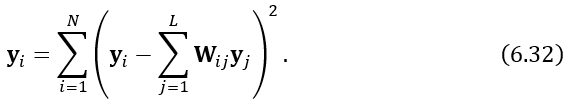
计算由每对点平方相似度组成的矩阵D, Dij=|xi-xj|.计算J=IN – 1/N (IN是N*N单位矩阵,N是数据点个数)。计算B=-1/2JDJ^T.找到B的L个最大的特征值入i,,以及相对应的特征向量ei。用特征值组成对角矩阵V并且用特征向量组成矩阵P的列向量。计算嵌入x=pv^0.5
创建所有点对之间的距离确定每个点的邻近点,并做成一个权重表G通过找最短路径估计测地距离dG把经典MDS算法用于一系列dG
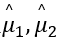 是从数据集中随机选出来的值
是从数据集中随机选出来的值
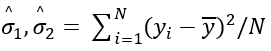 (这里
(这里
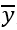 是整个数据集的平均值)
是整个数据集的平均值)
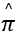 =0.5
=0.5

猜测参数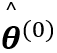
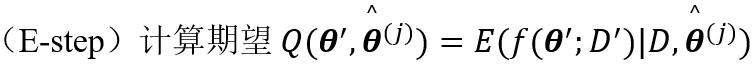
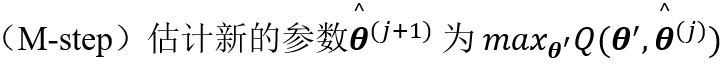
-
艾卡信息准则: AIC = ln(C)-k
-
贝叶斯信息准则: BIC = 2ln(C)-klnN
对于指定的内核和内核参数,计算数据之间距离的内核
这里主要的工作是计算K=XX^T。
对于线性内核,返回K,对于多项式的次数d,返回1/σ 8 K^d。
对于RBF核,计算K=exp(-(x-x')^2/2σ*σ。
训练:
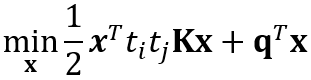 约束于
约束于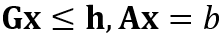
将这些矩阵传递给求解器。
-
采用线性搜索,知道方向,那么久沿着他一直走,直到最小值,这仅是直线的搜索;
-
信赖域,通过二次型建立函数的局部模型并且找到这个局部模型的最小值。由于我们不知道防线,因此可以采用贪婪选择法并且在每个点都沿着下降最快的方向走,这就是所知的最速下降,它意味着pk=-▽f(xk)。最速下降基于函数中的泰勒展开,这是一种根据导数近似函数值的方法。
给定一个初始点X0当J^Tr(x)>公差并且没有超出最大迭代次数:重复:用线性最小二乘法算出(J^TJ+vI)dx=一J^Tr中的dx。令Xnew=x+dx。计算实际减少和预测减少的比例:实际=||f(x)- f(xnew)||预测=▽f^T(x)*xnew-xp=实际/预测如果0<p<0.25:接受:x=Xnew。或者如果p>0.25:接受: x=Xnew。增加信赖城大小(减少v)。或者:拒绝。减少信赖域大小(增加v)。一直到x被更新或超出跌代的最大次数
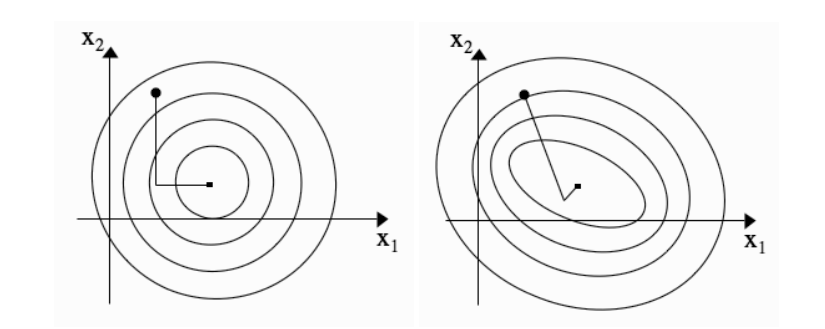
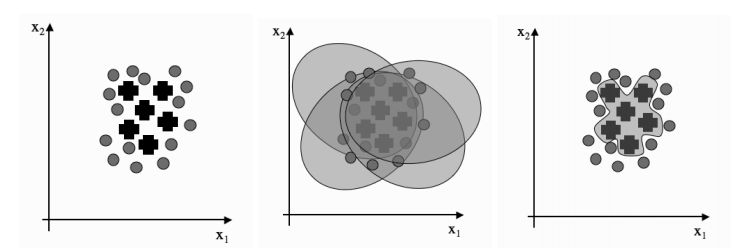
▲左边:如果方向之间是相互正交的并且步长是正确的,每一个维度只需要走一步,这里走了两步。右边:在椭圆上共轭的方向不是相互正交的。
给一个初始点x0和停止参数ε,令p0=-▽f(x)。设置Pnew=P0当Pnew>εεp0时:用牛顿-拉夫森迭代法计算αkP当ααdp>ε2时:α=-(▽f(x)^T p)(p^T H(x)p)x=x+αPdp=P^TP评价▽f(xnew)。计算βn+1-更新p←▽f(xnew)+βk+1p。检查及重新启动。
-
穷举法: 检查所有方法,保证找到全局最优
-
贪婪搜索: 整个系统只找一条路,在每一步都找局部最优解。所以对于TSP,任意选择第-个城市,然后不断重复选择和当前所在城市最近并且没有访问过的城市,直到走完所有城市。它的计算量非常小,只有O(NlogN),但它并不保证能找到最优解,并且我们无法预测它找到的解决方案如何,有可能很糟糕。
-
爬山法: 爬山法的基本想法是通过对当前解决方案的局部搜索,选择任一个选项来改善结果,进行局部搜索时做出的选择来自于一个移动集(moveset)。它描述了当前解决方案如何被改变从而用来产生新的解决方案。所以如果我们想象在2D欧几里得空间中移动,可能的移动就是东、南、西、北。
Exhaustive search
((1, 5, 10, 6, 3, 9, 2, 4, 8, 7, 0), 4.18)
1781.0613
Greedy search
((3, 9, 2, 6, 10, 5, 1, 8, 4, 7, 0]), 4.49)
0.0057
Hill Climbing
((7, 9, 6, 2, 4, 0, 3, 8, 1, 5, 10]), 7.00)
0.4572
Simulated Annealing
((10, 1, 6, 9, 8, 0, 5, 2, 4, 7, 3]), 8.95)
0.0065
-
联赛选择: 反复从种群中挑选四个字符串,替换并将最适合的两个字符串放人交配池中。
-
截断选择: 仅按比例f挑出适应度最好的一-部分并且忽略其他的。比如,f= 0.5经常被使用,所以前50%的字符串被放入交配池,并且被等可能地选择。这很显然是一个非常简单的实施方法,但是它限制了算法探索的数量,使得GA偏向于进化。
-
适应度比例选择: 最好的方法是按概率选择字符串,每个字符串被选择的概率与它们的适应度成比例。通常采用的函数是(对于字符串a):
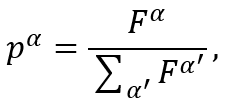
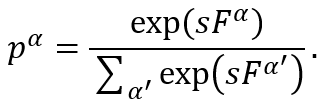
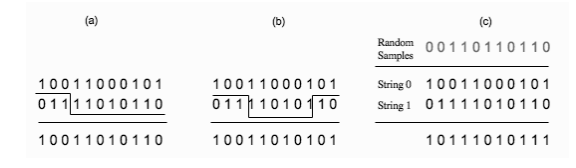
▲交叉算子的不同形式。(a)单点交叉。随机选择字符串中的一个位置,然后用字符串1的第一部分和字符串2的第二部分组成后代。(b)多点交叉。选择多个点,后代的生成方式和前面一样。(c)均匀交叉。每个元素都随机的选自于它的父母。
初始化进过我们选的字母表产生N个长为L的字符事。学习
生成一个(开始是空的)新的种群。
重复:
通过适应度在当前种群中选择两个字符串。重组它们产生两个新的字符串。让后代变异。要么把两个后代加到种群中,要么使用精英法和比赛法保持记录种群中最好的字符串。直到新种群中产生N个字符串
可选性地,使用精英法从父代中挑选最合适的字符串,并替换子代中的一些其他字符串。
追踪新种群中最好的字符串。
用新种群代替当前种群
直到到达停止标准。
初始化对于所有的s和a, 设置Q(s, a)为一个很小的随机數。重复:初始化s。用目前的策略选择动作a。重复:使用ε-greedy或者其他策略来选择动作a。采取动作a并得到奖赏r。采样新的状态s’更新Q(s, a)←Q(s, a)+u(r+γmaxa’ (s', a')-Q(s, a))设置s←s'应用到当前情节的每一步。直到没有更多的情节。
初始化对于所有的s和a,设置Q(s, a)为一个很小的随机数。重复:初始化s。用当前策略选择动作重复:实行动作a并得到奖赏r采样新的状态s'用当前策略选择动作a更新Q(s, a)<-Q(s, a)+u(r+yYQ(s',a')-Q(s,a)).s<-s’,a<-a’应用到当前情节的每一步直到没有更多的情节。
-
两种算法的相同
-
不同
-
具体算法
如果所有的样本都具有同一标记:返回标记为该类标记的叶子节点。否则,如果没有剩余特征用于测试:返回标记为最常见标记的叶子节点,否则:使用公式选择S中具有最大信息增益的特征户作为下一个节点。为每一个特征户的可能取值f增加一个分支。对于每个分支:计算除去F后的每一个特征的Sf,使用Sf递归调用算法,计算目前样本集合的信息增益。
-
决策树复杂度
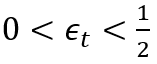 (t<T,最大迭代次数):
(t<T,最大迭代次数):
在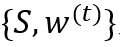 上训练分类器,得到数据点
上训练分类器,得到数据点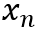 的假设
的假设 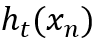
计算训练误差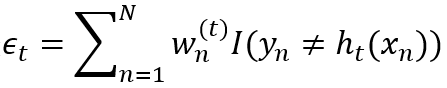
设置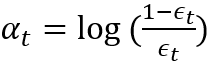
使用如下公式更新权值:
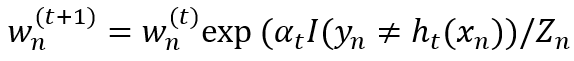
其中Zn为标准化常量
对于每N个树:创建一个训练集的bootstrap样本。使用这个bootstrap样本训练决策树。在决策树的每一个节点,随机选择m个特征,然后只在这些特征集合中计算信息增益(或者基尼不纯度),选择最优的一个。重复过程直到决策树完成。
计算属于每一个可能的类别的输入的概率,通过如下公式计算(其中w_i是对于每个分类器的权重):
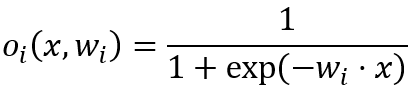
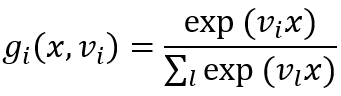
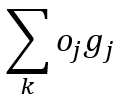
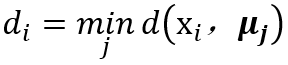
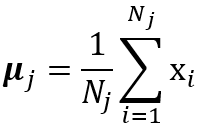
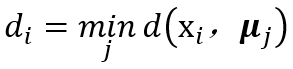
初始化选择一个值k,它与输出节点的数目有关。用小的随机值来初始化权重。学习归一化数据以便所有的点都在单位球上。重复:对每一个数据点:计算所有节点的激活。选出激活最高的那个节点作为胜利者。用公式更新权重。直到迭代的次数超过阈值。使用对于每个测试点:计算所有节点的激活选择激活最高的节点作为胜利者。
选择大小(神经元数目)和映射的维度d
或者
随机选择权重向量的值使得它们都是不同的OR
设置权值来增加数据的前d个主成分的方向
重复
对每一个数据点:
用权重和输入间的欧氏距离的最小值来选择最匹配的神经元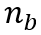 ,
,
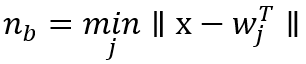
用下面的公式来更新最匹配节点的权重向量:
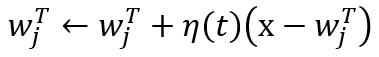
这里η(t)是学习效率
其他的神经元用下面的公式更新权重向量:
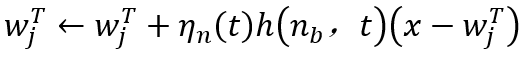
这里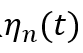 是邻居节点的学习效率,而是邻居函数
是邻居节点的学习效率,而是邻居函数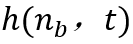 ,它决定是否每个神经元应该是胜利神经元的邻居(所以h=1是邻居,h=0不是邻居)
,它决定是否每个神经元应该是胜利神经元的邻居(所以h=1是邻居,h=0不是邻居)
减少学习效率并且调整邻居函数,一般通过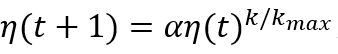 ,这里0≤α≤1决定大小下降的速度,k是算法已经运行的迭代次数,k_max是算法停止的迭代次数。相同的公式被用于学习效率(η,ηn)和邻居函数
,这里0≤α≤1决定大小下降的速度,k是算法已经运行的迭代次数,k_max是算法停止的迭代次数。相同的公式被用于学习效率(η,ηn)和邻居函数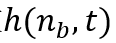
直到映射停止改变或超出了最大迭代的次数
对每个测试点:
用权重和输入间的欧氏距离的最小值来选择最匹配的神经元n_b:
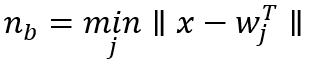
有话要说?
Q: 你在学习机器学习的过程中遇到了哪些问题?
欢迎留言与大家分享

