
- 1ubuntu22.04安装Ros2(每步都有图)(20221124)
- 2用kithara驱动控制IS620N伺服电机简单实例_kithara不支持千兆网卡
- 3机器学习各大模型原理的深度剖析!进来学习!!_机器学习模型
- 4ESLint 的一些理解_eslint explicit
- 5ThreadPoolExecutor和ThreadPoolTaskExecutor区别_executorthreadpool 和 executorthreadtaskpool
- 6腾讯云函数 python_腾讯云函数SCF使用心得
- 7linux mysql8离线升级_mysql 8.0升级8.4
- 8人工智能 | 通俗讲解AI基础概念_人工智能 通俗讲义
- 9计算机常用英语词汇_s expected. if you encounter any issues, please re
- 10Django | 从中间件的角度来认识Django发送邮件功能
python爬虫在线测试_Python爬虫的初步测试:在B站评论区爬虫,python,初试,取
赞
踩
本次爬取目标是最近看的一个很喜欢的描改手书的评论区,链接:
【幸运星】永远都想对战游戏的泉此方【永遠にゲームで対戦したいコナタン】
首先通过网页中f12使用网页开发工具找到评论区对应的html代码段:
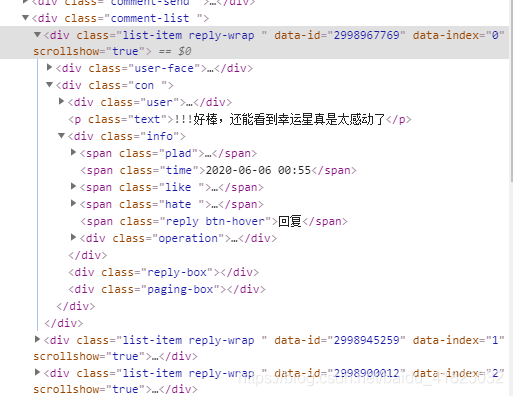
目标爬取内容为每一个list-item reply-wrap下的con中的用户评论内容,用户名,回复时间,点赞数(暂定)。
首先检测能否获取html文件,简单对该网页的url:https://www.bilibili.com/video/BV1N5411x7rZ 使用request库的get方法,调用bs4库soup的lxml分析格式化,结果如下略

这时没发现有什么问题,继续根据标签属性讲需要的信息提取出来:
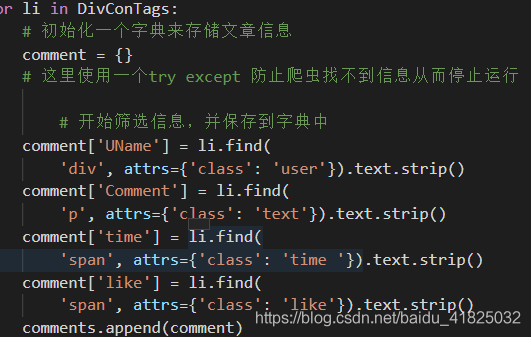
结果发现无论怎么样comment始终为空!!??返回回去debug,找到在
DivConTags = soup.find_all('div', attrs={'class': ' list-item reply-wrap'})
这步的时候就为空,没有找到标签div,class属性为list-item reply-wrap的元素。思考了许久回去发现再更之前的soup,甚至最开始的html中都没评论栏的元素。
查阅资料也没有得到明确的答案,个人猜测评论栏是额外加载的另一个域,没有直接保存在html文件中,需要每次打开的时候网页再次向服务器申请得到元素。
如何找到评论栏对应的html文件呢,可以由点击下一页的时候监测网页发出的请求找到类似的目标。
点击评论区下一页,发现网页url没有发生变化,说明b站评论区并不是通过url改变评论页数的。这里通过监视点击下一页按钮的时候网页对服务器发出的请求以及服务器的回答进行分析:
点击f12开发工具上方network栏

点击红点停止记录,再点击开始,待下方列表清空后点击下一页按钮,找到下方刷新出来的script文件:

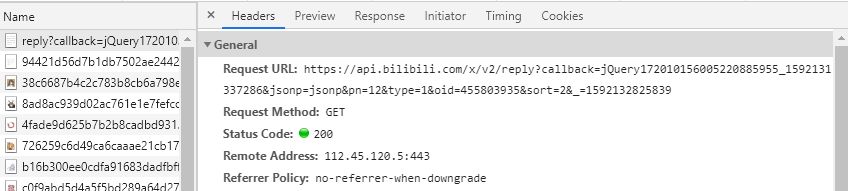
可见在点击下一页后网页向服务器发出了Request URL这样的请求。
转到preview栏,分析服务器返回的内容:

这样,可以直观的看到评论栏中的内容。
但是,实际上https://api.bilibili.com/x/v2/reply?callback=jQuery17206650614708586977_1592139923724&jsonp=jsonp&pn=2&type=1&oid=455803935&sort=2&_=1592139955967,这个url我们并不能进入
服务器也拒绝我们的请求。
查询资料后,得知只需要删除该url一些额外的部分,就可以正常访问。最后得到的url如下:
https://api.bilibili.com/x/v2/reply?pn=2&type=1&oid=455803935&sort=2
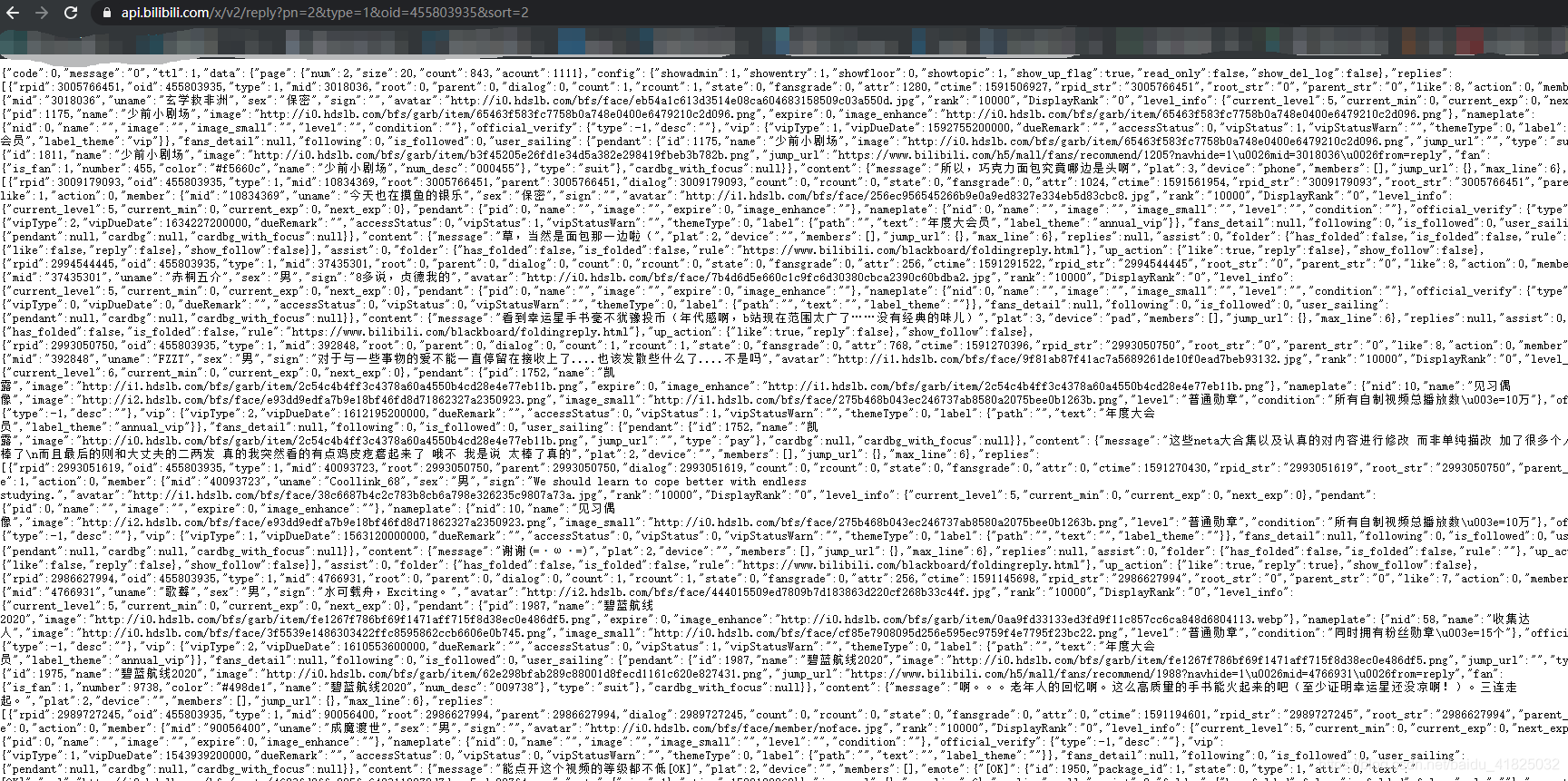
其中pn=2代表评论的页数。这样我们就能很方便的进行爬取了。
接下来需要做的就是解析并获取需要的内容。这里选择尝试使用json库进行解析。
def get_html(url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}# 爬虫模拟访问信息
r = requests.get(url, timeout=30,headers=headers)
r.raise_for_status()
r.endcodding = 'utf-8'
return r.text
定义get_html函数获取html
将得到的html数据导入json在线解析工具,可以很清晰的看见其中数据的结构,方便之后解析获取:
json在线解析
解析结果如下:

可以很明显的看到想要找到的数据,接下来就是将数据取出,保存到列表中
def get_content(url):
'''
分析网页文件,整理信息,保存在列表变量中
'''
comments = []
# 首先,我们把需要爬取信息的网页下载到本地
html = get_html(url)
try:
s=json.loads(html)
except:
print("jsonload error")
num=len(s['data']['replies']) # 获取每页评论栏的数量
# print(num)
i=0
while i
comment=s['data']['replies'][i]# 获取每栏评论
InfoDict={} # 存储每组信息字典
InfoDict['Uname']=comment['member']['uname'] # 用户名
InfoDict['Like']=comment['like'] #点赞数
InfoDict['Content']=comment['content']['message'] # 评论内容
InfoDict['Time']=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment['ctime'])) # ctime格式的特殊处理?不太清楚具体原理
comments.append(InfoDict)
i=i+1
# print(comments)
return comments
检查一下结果是否是预期,打印出得到的comments:
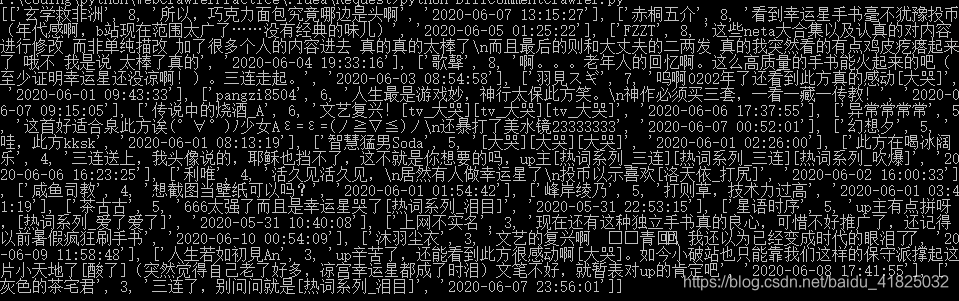
正确。接下来只需要进行功能完善:数据格式输出、保存本地、翻页爬取。
完整代码如下:
'''
爬取B站评论区内容
'''
import requests
import time
from bs4 import BeautifulSoup
import json
# 首先我们写好抓取网页的函数
def get_html(url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}# 爬虫模拟访问信息
r = requests.get(url, timeout=30,headers=headers)
r.raise_for_status()
r.endcodding = 'utf-8'
#print(r.text)
return r.text
def get_content(url):
'''
分析网页文件,整理信息,保存在列表变量中
'''
comments = []
# 首先,我们把需要爬取信息的网页下载到本地
html = get_html(url)
try:
s=json.loads(html)
except:
print("jsonload error")
num=len(s['data']['replies']) # 获取每页评论栏的数量
# print(num)
i=0
while i
comment=s['data']['replies'][i]# 获取每栏评论
InfoDict={} # 存储每组信息字典
InfoDict['Uname']=comment['member']['uname'] # 用户名
InfoDict['Like']=comment['like'] #点赞数
InfoDict['Content']=comment['content']['message'] # 评论内容
InfoDict['Time']=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment['ctime'])) # ctime格式的特殊处理?不太清楚具体原理
comments.append(InfoDict)
i=i+1
# print(comments)
return comments
def Out2File(dict):
'''
将爬取到的文件写入到本地
保存到当前目录的 BiliBiliComments.txt文件中。
'''
with open('BiliBiliComments.txt', 'a+') as f:
i=0
for comment in dict:
i=i+1
try:
f.write('姓名:{}\t 点赞数:{}\t \n 评论内容:{}\t 评论时间:{}\t \n '.format(
comment['Uname'], comment['Like'], comment['Content'], comment['Time']))
f.write("-----------------\n")
except:
print("out2File error")
print('当前页面保存完成')
if __name__ == '__main__':
e=0
page=1
while e == 0 :
url = "https://api.bilibili.com/x/v2/reply?pn="+ str(page)+"&type=1&oid=455803935&sort=2"
try:
print()
# print(url)
content=get_content(url)
print("page:",page)
Out2File(content)
page=page+1
# 为了降低被封ip的风险,每爬20页便歇5秒。
if page%10 == 0:
time.sleep(5)
except:
e=1
一些需要注意的地方:
在编写的时候,发现在保存到本地的时候,总是会不报错直接退出,只写到第一页的第5个就停了。因此加了一个try/except抓取错误从而能进行下去(这点在爬取的时候也很重要,当因为一些什么意外爬虫被停下的时候需要它跳过这个错误继续进行,try/except块经常被使用)。
但是这样看下来有不少评论都因为写错误被过滤掉了,不够完善。
继续检查发现,在comments中,第5个出错的内容是:
{'Uname': '-狗眠-', 'Like': 99, 'Content': '精 准 推 送 。\n\n记得起来内容来源:\n幸运星 (主体内容)\n军曹keroro(宝可梦的形象)\n凉宫春日(团长臂章以及对话的头像)\n东方绯想天(加载界面以及ko之后的人物对话)\n\n何等,高技术力,修改也契合了作品的内容(´ε` )♡\n有老bili的味道了,呜', 'Time': '2020-06-01 12:41:00'}
编写一个额外的写程序尝试找到出错原因:
str="{'Uname': '-狗眠-', 'Like': 99, 'Content': '精 准 推 送 。\n\n记得起来内容来源:\n幸运星 (主体内容)\n军曹keroro(宝可梦的形象)\n凉宫春日(团长臂章以及对话的头像)\n东方绯想天(加载界面以及ko之后的人物对话)\n\n何等,高技术力,修改也契合了作品的内容(´ε` )♡\n有老bili的味道了,呜', 'Time': '2020-06-01 12:41:00'}"
with open("test.txt",'a+') as f:
f.write(str)
发现报错如下:

经过查阅资料得知,这大概是python默认编码的问题,需要打开文件的时候额外设置编码方式,修改代码为:
str="{'Uname': '-狗眠-', 'Like': 99, 'Content': '精 准 推 送 。\n\n记得起来内容来源:\n幸运星 (主体内容)\n军曹keroro(宝可梦的形象)\n凉宫春日(团长臂章以及对话的头像)\n东方绯想天(加载界面以及ko之后的人物对话)\n\n何等,高技术力,修改也契合了作品的内容(´ε` )♡\n有老bili的味道了,呜', 'Time': '2020-06-01 12:41:00'}"
with open("test.txt",'a+',encoding='utf-8') as f:
f.write(str)
将同样的修改应用到上面的代码,最终完整代码如下:
'''
爬取B站评论区内容
'''
import requests
import time
from bs4 import BeautifulSoup
import json
# 首先我们写好抓取网页的函数
def get_html(url):
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}# 爬虫模拟访问信息
r = requests.get(url, timeout=30,headers=headers)
r.raise_for_status()
r.endcodding = 'utf-8'
#print(r.text)
return r.text
def get_content(url):
'''
分析网页文件,整理信息,保存在列表变量中
'''
comments = []
# 首先,我们把需要爬取信息的网页下载到本地
html = get_html(url)
try:
s=json.loads(html)
except:
print("jsonload error")
num=len(s['data']['replies']) # 获取每页评论栏的数量
# print(num)
i=0
while i
comment=s['data']['replies'][i]# 获取每栏评论
InfoDict={} # 存储每组信息字典
InfoDict['Uname']=comment['member']['uname'] # 用户名
InfoDict['Like']=comment['like'] #点赞数
InfoDict['Content']=comment['content']['message'] # 评论内容
InfoDict['Time']=time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(comment['ctime'])) # ctime格式的特殊处理?不太清楚具体原理
comments.append(InfoDict)
i=i+1
# print(comments)
return comments
def Out2File(dict):
'''
将爬取到的文件写入到本地
保存到当前目录的 BiliBiliComments.txt文件中。
'''
with open('BiliBiliComments.txt', 'a+',encoding='utf-8') as f:
i=0
for comment in dict:
i=i+1
try:
f.write('姓名:{}\t 点赞数:{}\t \n 评论内容:{}\t 评论时间:{}\t \n '.format(
comment['Uname'], comment['Like'], comment['Content'], comment['Time']))
f.write("-----------------\n")
except:
print("out2File error")
print('当前页面保存完成')
if __name__ == '__main__':
e=0
page=1
while e == 0 :
url = "https://api.bilibili.com/x/v2/reply?pn="+ str(page)+"&type=1&oid=455803935&sort=2"
try:
print()
# print(url)
content=get_content(url)
print("page:",page)
Out2File(content)
page=page+1
# 为了降低被封ip的风险,每爬20页便歇5秒。
if page%10 == 0:
time.sleep(5)
except:
e=1
运行结果:

没有在存储为文件时报错,正确
后续待添加的功能:添加交互,输入BV号得到目标评论区数据。
观察上面爬取的url。oid后的数字就是B站改版前的AV号:
https://api.bilibili.com/x/v2/reply?pn=2&type=1&
oid=455803935
&sort=2
BV号相当于只是加了个函数转换。
因此需要工具:
BV号转AV号


