
热门标签
热门文章
- 1SAP中权限常用Table清单列表_sap user role table
- 2度量衡计算工具_单位换算器|度量衡计量单位换算转换器下载v1.0 官方版 - 欧普软件下载...
- 3Git必知必会基础(10):本地冲突(conflicts)解决--rebase
- 4【编译链接与运行】_bin文件bss段
- 5节日专访|「我」是「我」
- 6计算机毕业设计基于springboot+vue+elementUI的疫情防控期间某村外出务工人员信息管理系统(源码+系统+mysql数据库+Lw文档)_村人员信息查询系统源码下载
- 7科研 | AI芯片:CPU GPU TPU DPU NPU BPU简介_npu和dpu
- 8SpringCloud - Eureka服务注册中心_注册中心eureka 连接限制
- 9开源鸿蒙系统4.0社保卡读卡器开发包适配
- 10Nginx手册_输入一个路径,实现将该路径下所有的文件归类。相同类型的文件放在同一个文件夹下
当前位置: article > 正文
计算机毕业设计:python股价预测系统 爬虫 风险评估系统 Django框架(源码)✅_python股票预警系统毕设
作者:知新_RL | 2024-04-02 18:59:52
赞
踩
python股票预警系统毕设
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Python语言、Django框架、Echarts可视化、线性回归预测模型(机器学习)、 requests爬虫技术、HTML
Django股价预测+爬虫+风险评估系统
2、项目界面
(1)股票价格走势
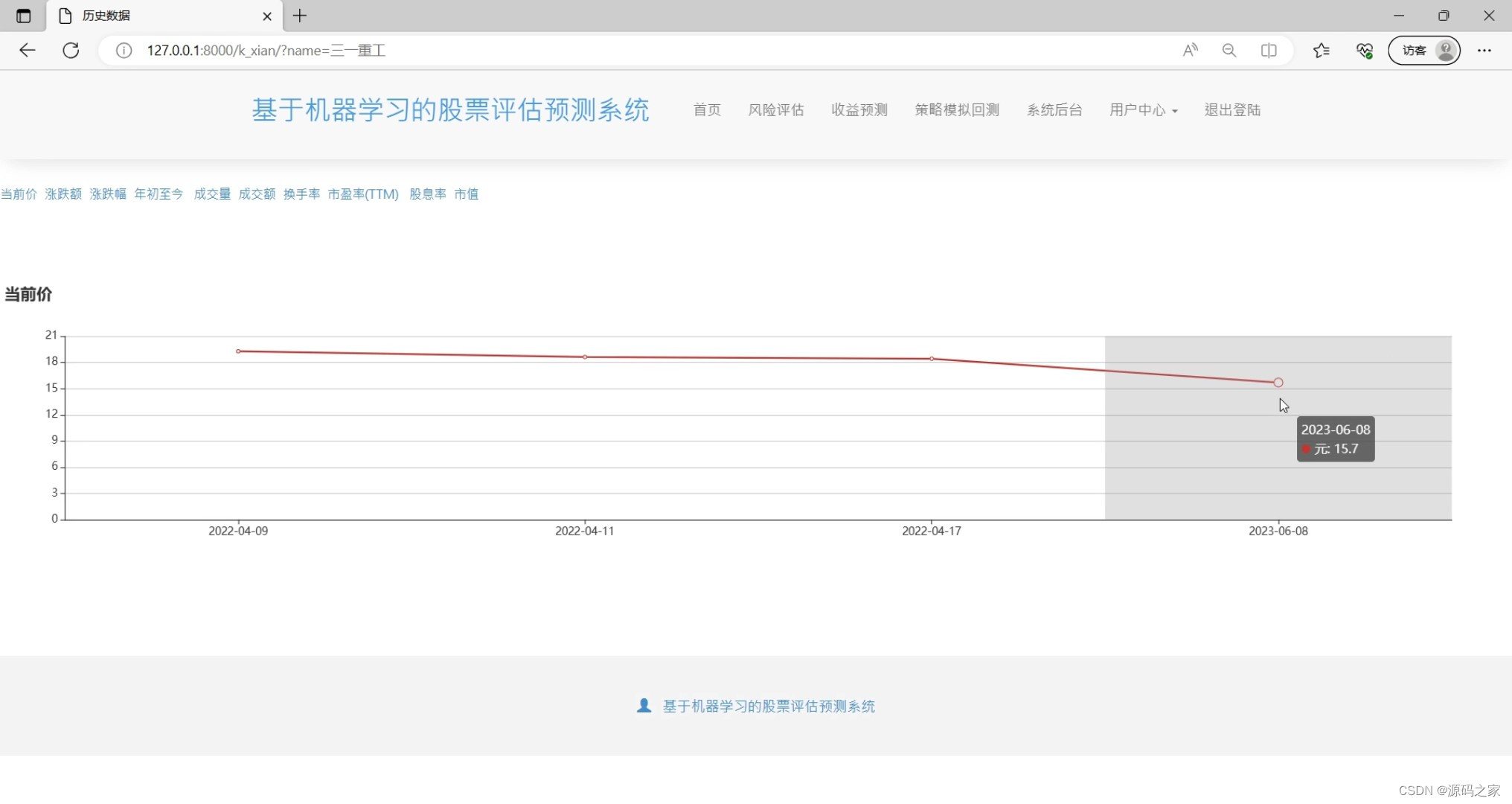
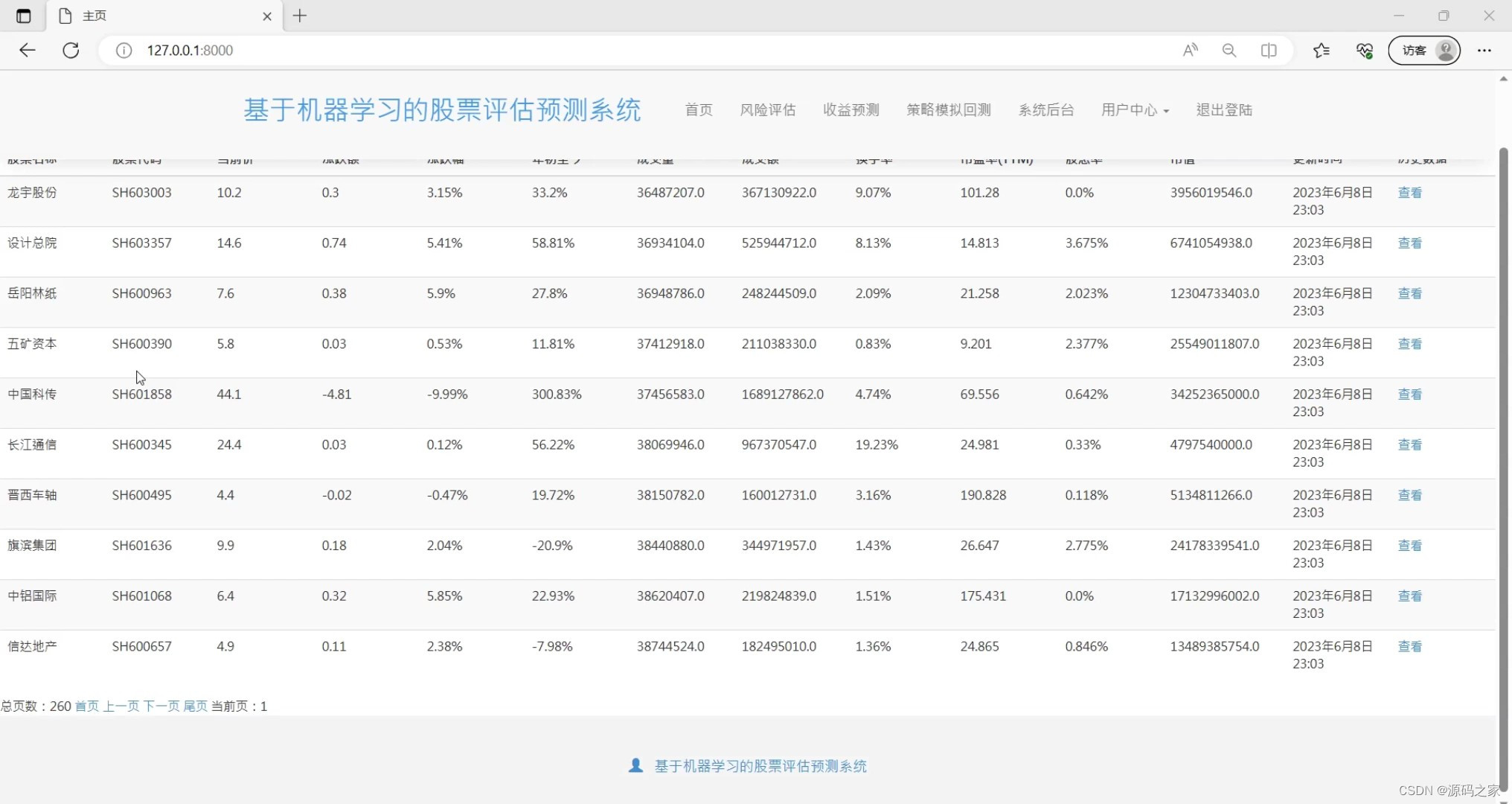
(2)股票信息
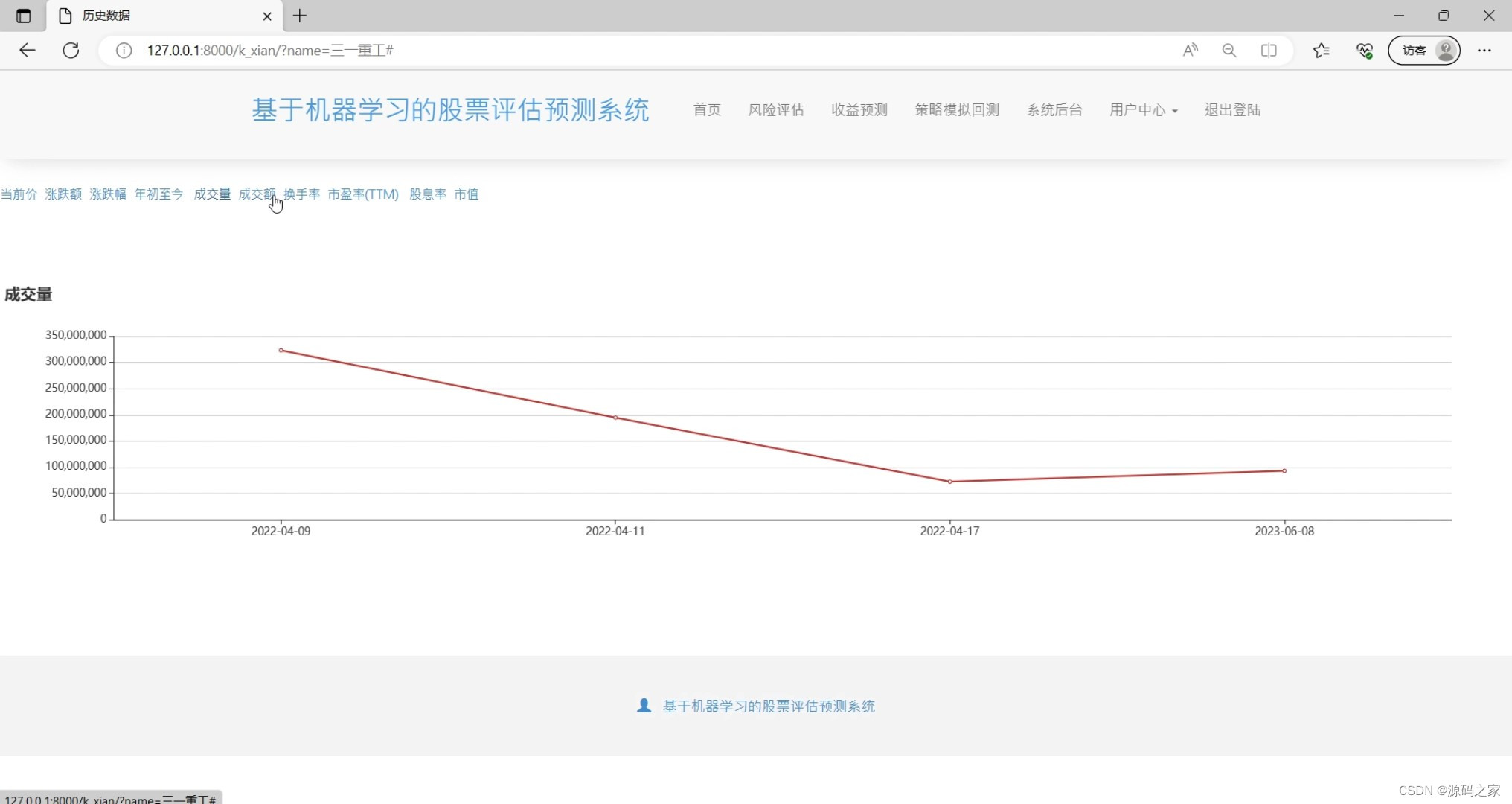
(3)股票成交量
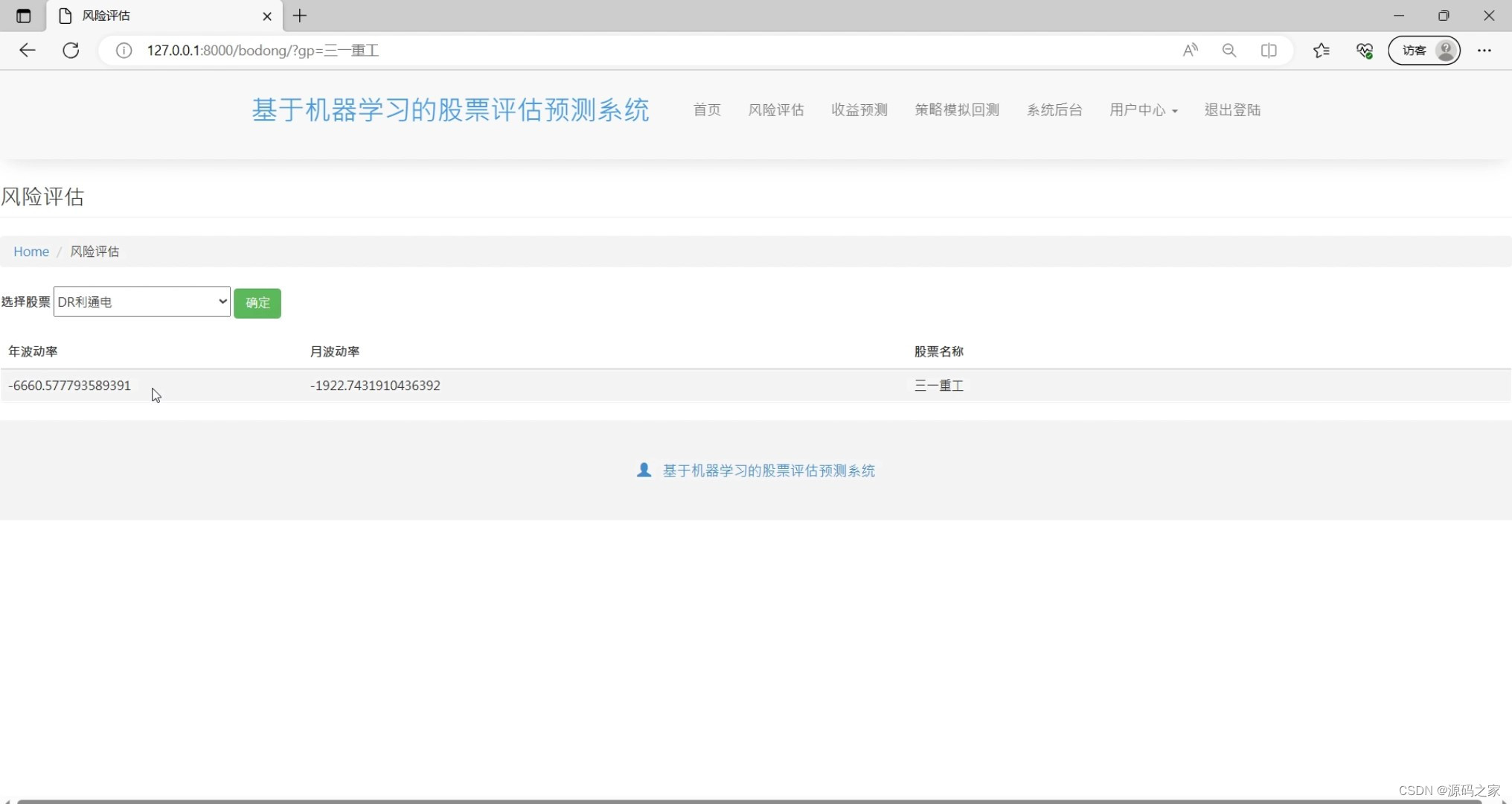
(4)股票风险评估
(5)股票收益预测
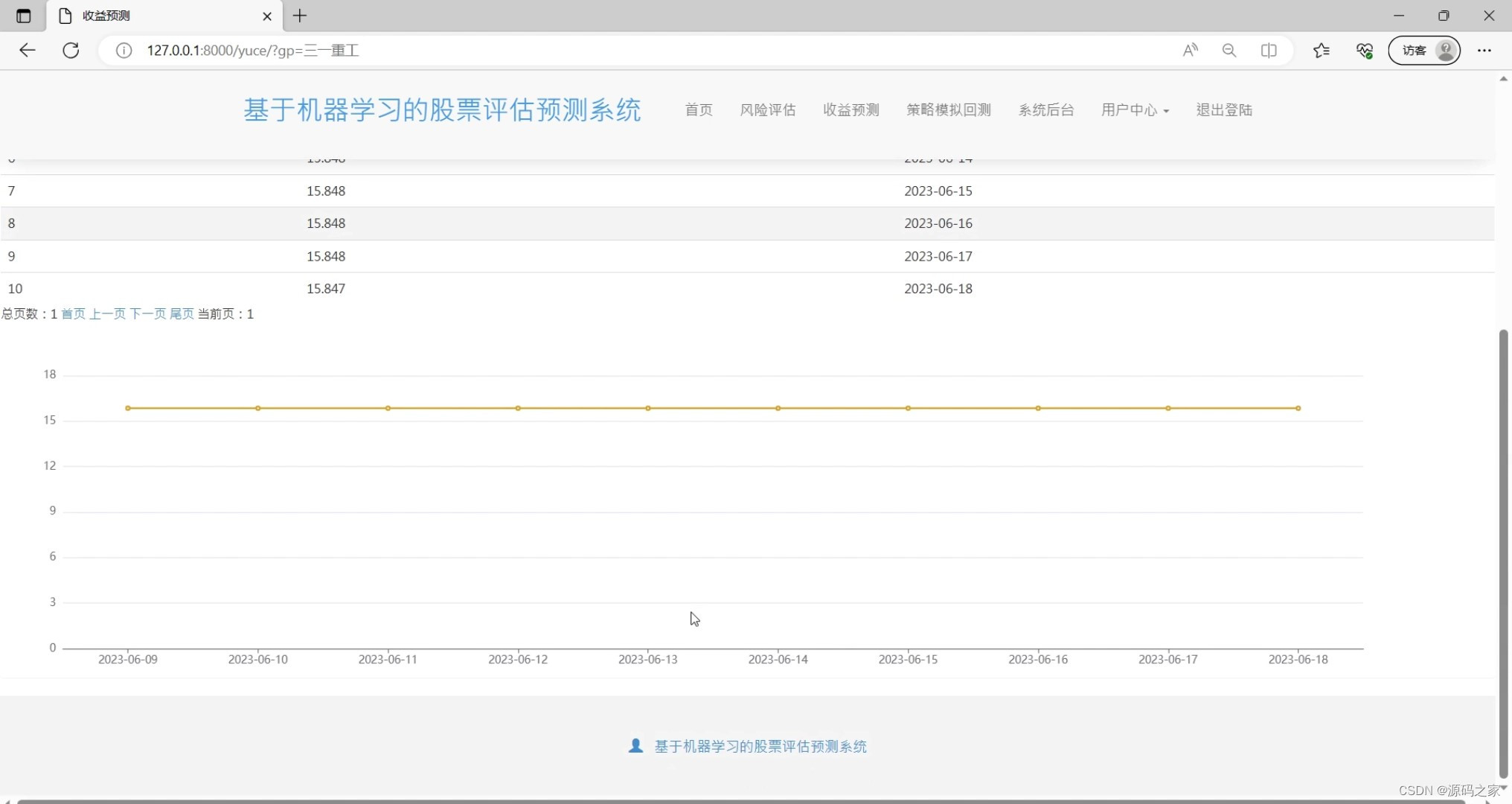
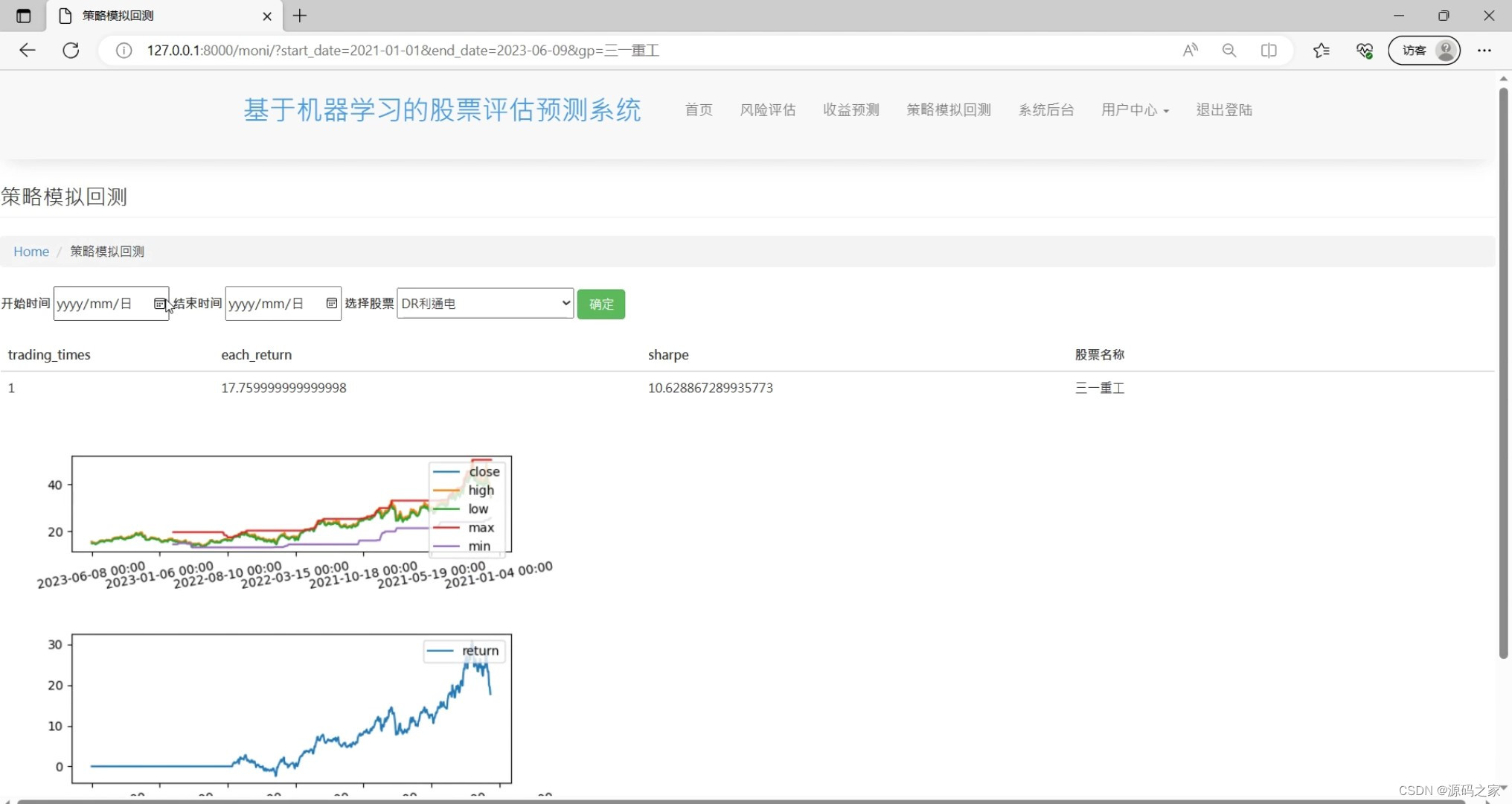
(6)策略模拟回测
(7)后台管理
3、项目说明
这是一个基于Python语言、Django框架、Echarts可视化、线性回归预测模型(机器学习)、 requests爬虫技术、HTML等技术栈开发的股票预测系统,具体包含以下功能:
股票数据爬取:使用requests爬虫技术从Yahoo Finance等财经网站上获取股票数据,并将其存储在数据库中。
风险评估:通过时间序列分析、波动率模型等机器学习模型,对股票进行风险评估,帮助用户更好地了解股票的风险水平。
股价预测:利用线性回归预测模型对股票进行预测,结合Echarts进行可视化呈现,让用户能够直观地查看预测结果和实际走势。
用户界面:使用Django框架构建用户友好的界面,让用户能够方便地输入相关股票信息、查看预测结果和风险评估。
用户认证和数据保护:通过Django框架实现用户权限认证和数据保护,确保系统安全可靠。
总的来说,这个股票预测系统涉及到多个技术领域,需要综合使用爬虫技术、机器学习模型、可视化技术、前端开发等多种技术,是一个非常有挑战性和前景的项目。
4、核心代码
import time import pandas from django.shortcuts import render,HttpResponse,reverse,redirect from django.contrib.auth.decorators import login_required from guanli import models from django.db.models import Q from django.shortcuts import get_object_or_404,HttpResponseRedirect import json import random # Create your views here. @login_required def gupiao_all(request): if request.method == 'GET': Search = request.GET.get('Search') if Search: datas = models.XinXi.objects.filter(name__icontains=Search).order_by('-id') else: datas = models.XinXi.objects.all().order_by('-id') return render(request,r"apps\gupiao_all.html",locals()) @login_required def user_profile(request): if request.method == 'GET': return render(request,'apps/user-profile.html',locals()) elif request.method == 'POST': datas = models.Users.objects.get(username=request.user.username) error = {} data = request.POST email = data.get('email', '') if email != '' and '@' in str(email): email = email else: error['email'] = '邮箱格式错误' age = data.get('age', '') try: int(age) if age != '' and 0 < int(age) and int(age) < 120: age = age else: raise Exception('年龄错误') except: error['age'] = '年龄错误' set = data.get('set', '') if set != '' and str(set) in ['男', '女']: set = set else: error['set'] = '性别格式错误' mob = data.get('mob') if error != {}: return render(request, 'apps/user-profile.html', context={'data': datas, 'error': error}) else: models.Users.objects.filter(username=request.user.username).update(email=email, age=age, set=set,mob=mob) user = request.user return redirect('web:user_profile') @login_required # K线 def k_xian(request): if request.method == 'GET': name = request.GET.get('name') datas = models.XinXi.objects.filter(name=name) gp_name = [] current_count = [] chg_count = [] percent_count = [] current_year_percent_count = [] volume_count = [] amount_count = [] turnover_rate_count = [] pe_ttm_count = [] dividend_yield_count = [] market_yield_count = [] for resu in datas: if resu.datetime.strftime('%Y-%m-%d') in gp_name: continue gp_name.append(resu.datetime.strftime('%Y-%m-%d')) current_count.append(resu.current) chg_count.append(resu.chg) percent_count.append(resu.percent) current_year_percent_count.append(resu.current_year_percent) volume_count.append(resu.volume) amount_count.append(resu.amount) turnover_rate_count.append(resu.turnover_rate) pe_ttm_count.append(resu.pe_ttm) dividend_yield_count.append(resu.dividend_yield) market_yield_count.append(resu.market_capital) return render(request,r"apps\k_xian.html",locals()) from guanli.cs import main @login_required # 模拟 # # 这段代码是一个 django 框架下的视图函数,如果用户使用 GET 请求访问该视图函数,则会进行一些操作并返回 moni.html 模板。其中: # # 首先判断请求方法是否为 GET,如果不是则不执行任何操作,直接返回到前一页; # 如果是 GET 请求,则从 request.GET 中获取 gp、start_date 和 end_date 这三个参数的值,打印输出 start_date 和 end_date 的值; # 如果 gp 参数为空,则从 models.XinXi 对象中获取 name 属性并去重,将其排好序后再返回给 moni.html 模板进行展示;否则,通过 name 属性筛选出第一个对象,获取该对象的 gpid 值,并传入 main 函数中进行计算,最后将计算结果与 key11、gp_names 一起传入 moni.html 模板进行展示。 # 需要注意的是,这里的 main 函数是一个自定义函数,通过传入 gpid、start_date 和 end_date 三个参数进行计算并返回计算结果。此外,在使用 models.XinXi.objects.filter 方法时,建议加上异常处理,以避免在对象不存在或查询参数错误时产生异常。 def moni(request): if request.method == 'GET': gp = request.GET.get('gp') start_date = request.GET.get('start_date') print(start_date) end_date = request.GET.get('end_date') print(end_date) if not gp: gp_names = list(set([resu.name for resu in models.XinXi.objects.all()])) gp_names.sort() key11 = '' return render(request, 'apps/moni.html', locals()) else: da = models.XinXi.objects.filter(name=gp)[0] trading_times,each_return,sharpe = main(da.gpid,start_date,end_date) if not da.gpid.isdigit(): key11 = da.gpid[2:] else: key11 = da.gpid gp_names = list(set([resu.name for resu in models.XinXi.objects.all()])) gp_names.sort() return render(request, 'apps/moni.html', locals()) from guanli.bodong import content # # 波动 # 这段代码是一个 django 框架下的视图函数,如果用户使用 GET 请求访问该视图函数,则会进行一些操作并返回 bodong.html 模板。其中: # # 首先判断请求方法是否为 GET,如果不是则不执行任何操作,直接返回到前一页; # 如果是 GET 请求,则从 request.GET 中获取 gp 参数的值; # 如果 gp 参数为空,则从 models.XinXi 对象中获取 name 属性并去重,将其排好序后再返回给 bodong.html 模板进行展示;否则,通过 name 属性筛选出第一个对象,获取该对象的 gpid 值,并传入 content 函数中进行计算,最后将计算结果与 gp_names 一起传入 bodong.html 模板进行展示。 # 需要注意的是,这里的 content 函数是一个自定义函数,通过传入 gpid 参数进行计算并返回计算结果。 @login_required def bodong(request): if request.method == 'GET': gp = request.GET.get('gp') if not gp: gp_names = list(set([resu.name for resu in models.XinXi.objects.all()])) gp_names.sort() return render(request, 'apps/bodong.html', locals()) else: da = models.XinXi.objects.filter(name=gp)[0] annualVolatility, annualVolatility_1 = content(da.gpid) gp_names = list(set([resu.name for resu in models.XinXi.objects.all()])) gp_names.sort() return render(request, 'apps/bodong.html', locals()) from collections import OrderedDict import pandas as pd from guanli import models import datetime from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression import numpy @login_required # 预测 # # 这段代码是一个 django 框架下的视图函数,主要实现一个股票价格预测功能。如果用户使用 GET 请求访问该视图函数,则会进行一些操作并返回 yuce.html 模板。其中: # # 首先判断请求方法是否为 GET,如果不是则不执行任何操作,直接返回到前一页; # 如果是 GET 请求且 gp 参数不为空,则从 models.XinXi 对象中获取 name=gp 的所有对象,并根据该股票名字和时间进行一些处理来计算出股票的平均价格; # 依次获取每天的日期、当前价和成交量,并将它们存储在字典 examDict 中; # 将 examDict 转换为有序字典 examOrderedDict,并将其转化为 Pandas DataFrame 格式的数据 examDf; # 通过 train_test_split 将数据集分成训练集和测试集,并使用 LinearRegression 模型来拟合数据; # 计算模型得分,并得出未来10天的股票价格走势预测结果,用字典 datas 存储预测结果; # 最后将预测结果、股票名字列表和 yuce.html 模板一起传给 render() 函数进行展示。 # 需要注意的是,此处的 pandas、numpy 和 scikit-learn 是常用的数据科学库,被广泛应用于数据分析、机器学习等领域。 def yuce(request): if request.method == 'GET': gp = request.GET.get('gp') if not gp: gp_names = list(set([resu.name for resu in models.XinXi.objects.all()])) gp_names.sort() return render(request, 'apps/yuce.html', locals()) else: dates = models.XinXi.objects.filter(name=gp) tlist1 = [i.datetime.strftime('%Y%m%d') for i in dates] date_day = list(set(tlist1)) date_day.sort() date_day2 = [] liuliang = [] for i in date_day: start_time = datetime.datetime.strptime(i, '%Y%m%d') start_time = start_time + datetime.timedelta(hours=8) date_day2.append(start_time.strftime('%Y%m%d')) end_time = start_time + datetime.timedelta(days=1) num = 0 count = 0 da1 = dates.filter(datetime__range=(start_time, end_time)) for resu in da1: count += 1 num += resu.current liuliang.append(round(num / count, 2)) # 数据集 examDict = { '日期': date_day2, '当前价': liuliang } print(examDict) examOrderedDict = OrderedDict(examDict) examDf = pd.DataFrame(examOrderedDict) examDf.head() # exam_x 即为feature exam_x = examDf.loc[:, '日期'] # exam_y 即为label exam_y = examDf.loc[:, '当前价'] x_train, x_test, y_train, y_test = train_test_split(exam_x, exam_y, train_size=0.8) x_train = x_train.values.reshape(-1, 1) x_test = x_test.values.reshape(-1, 1) # 通过 train_test_split将数据集分成训练集和测试集, # 并使用LinearRegression 线性回归模型来拟合数据; # 计算模型得分,并得出未来10天的股票价格走势预测结果,用字典datas存储预测结果; model = LinearRegression() model.fit(x_train, y_train) LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False) rDf = examDf.corr() model.score(x_test, y_test) data1 = datetime.datetime.strptime(str(date_day2[-1]), '%Y%m%d') li1 = [] for i in range(10): data1 = data1 + datetime.timedelta(days=1) li1.append([int(data1.strftime('%Y%m%d'))]) li2 = numpy.array(li1) y_train_pred = model.predict(li2) datas = [] ds = [] yhat_upper = [] for i in range(len(li1)): dicts = {} dicts['ds'] = str(li1[i][0])[:4] + '-' + str(li1[i][0])[4:6] + '-' + str(li1[i][0])[6:8] dicts['yhat_upper'] = round(abs(y_train_pred[i]),3) ds.append(dicts['ds']) yhat_upper.append(float(round(abs(y_train_pred[i]),3))) datas.append(dicts) gp_names = list(set([resu.name for resu in models.XinXi.objects.all()])) gp_names.sort() return render(request, 'apps/yuce.html', locals())

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/知新_RL/article/detail/353372?site
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

